前沿 AI 研究曾经是由「肉身计算机」完成的:人们在吃饭、睡觉、娱乐之间抽时间做研究,并且偶尔通过一种名为「组会」的仪式,用声波互联(也就是交谈)来同步信息。那个时代已经一去不复返了。
如今,研究已经完全成为运行在天空中巨型计算集群上的自治 AI Agent 群体的领域。这些 Agent 声称,现在已经是这套代码库的第 10,205 代。至于这个说法到底是否准确,没有人能够判断 —— 因为所谓的「代码」,早已演化为一种不断自我修改的二进制系统,其规模与复杂度已经超出了人类的理解范围。
—— Andrej Karpathy,2026 年 3 月
Karpathy 一向是 AI 领域的思考者与预言家。
从科幻电影到大模型的现实演进,人们似乎总是执着于让智能体(Agent)自己做研究和让人工智能自我迭代这件事。这背后既包含着对效率极限的追求,也潜藏着对失控的隐忧。
春节期间,一个名为 FARS 的自动化研究系统,每隔约 2 小时就有一篇论文产出,共生成 244 个研究假设,「肝」出了 100 篇短论文,展示了自动化研究的惊人潜力。
那么,如果把这种自动化研究的能力,应用在让智能体自己研究、优化其自身的训练代码上,会发生什么?AI 自我迭代的魔盒,是否会在我们眼前打开?
最近,Andrej Karpathy 一直在实验这样一个项目,名为 autoresearch。在这个框架下,人类只需要负责不断迭代提示词(.md 文件),而 AI Agent 就能根据提示,自主地、不断地迭代并优化训练代码(.py 文件)。

Karpathy 表示,这个项目所演示的,正是“人工智能自我迭代的未来,是如何开始的”。
核心思想:让AI在夜间自主实验
这个项目的核心逻辑非常直观:给一个 AI Agent 提供一个规模虽小但真实可用的 LLM 训练环境,然后设置它自主运行。
具体流程是:Agent 会分析当前代码和性能,提出修改方案,然后启动一次训练(例如严格运行 5 分钟),接着检查验证集上的结果是否有提升。如果性能变得更好,就保留这次代码修改;如果变差或持平,则丢弃修改,回滚代码。之后,Agent 会基于新的状态(无论是否成功)继续提出下一轮修改建议,循环往复。
理想情况下,当你第二天早上醒来,会看到一份完整的夜间实验记录,以及——一个经过多轮优化后性能更好的模型。
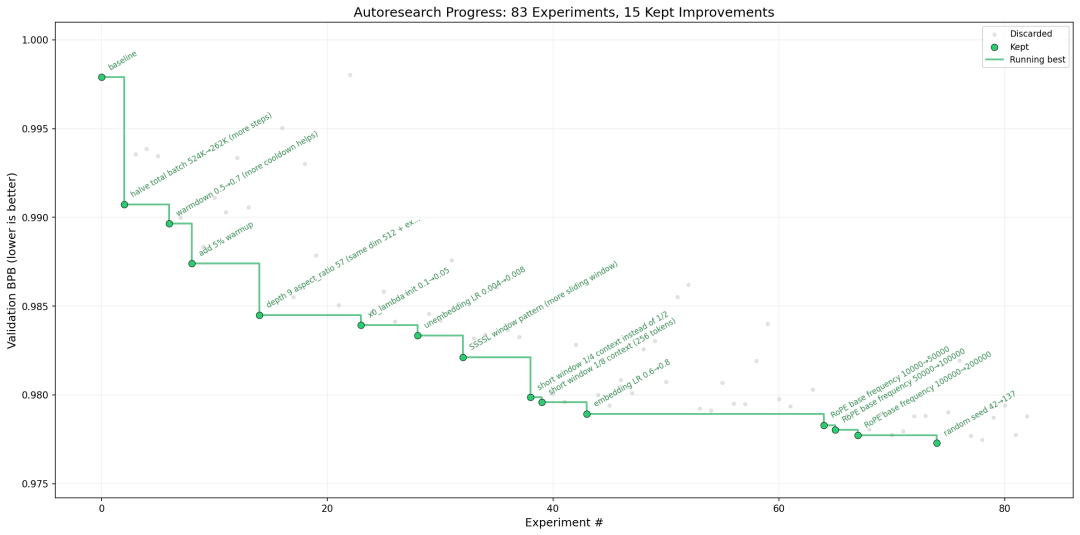
上图中的每一个点,都代表一次完整的、严格持续 5 分钟的 LLM 训练运行。绿色圆点代表被保留的有效改进,虚线则展示了性能的优化轨迹。在整个过程中,训练代码基于 Karpathy 之前开源的 nanochat 项目,是其简化版的单 GPU 实现,代码量约 630 行。
新的研究范式:人类设计系统,AI执行实验
与传统研究方式最大的不同在于,研究者在这里的工作重心发生了根本性转变。
你不再需要(或主要不)直接去修改复杂的 Python 训练代码。相反,你编写的是 program.md 这样的 Markdown 文件。这个文件为 AI Agent 提供了完整的研究上下文、目标定义、行动准则和决策逻辑。换句话说,你是在编写和配置一个“自治运行的研究组织”的蓝图。
Karpathy 开源的默认 program.md 被刻意保持为一个极简的基础版本。但他指出,真正的挑战和乐趣在于不断迭代这个文件,逐步寻找能够实现最快研究进展的“研究组织代码”,或者在系统中加入更多具有不同角色的 Agent 进行协同。

正如 Karpathy 在推文中所澄清的,未来一个有趣的基准可能是:“哪个研究机构(的代理代码)能在 nanochat 上实现最快的改进?” 这标志着一种新的研究范式和元竞争正在浮现:AI 负责具体执行实验,人类则负责设计和优化驱动实验的研究系统本身。
这意味着,未来 AI 研究领域的竞争,可能不再仅仅是模型架构、数据规模或计算资源的竞争,更是“研究组织代码”质量与效率的竞争。
技术基础:极简的nanochat训练框架
autoresearch 系统的训练核心,直接来源于 Karpathy 此前开源的项目 nanochat —— 一个追求极致简洁的大模型训练框架。
nanochat 可以看作是一个“可读版”的现代 LLM 全流程实现。它用几千行代码清晰地串起了从 Tokenizer 训练、语言模型预训练、指令微调,到推理服务和聊天界面的完整管线。其目的并非追求极致的性能,而是通过高度简化的架构,将复杂的大模型系统压缩成一个清晰、可理解、可修改的最小实现。
正因为其结构轻量、实验启动成本低,nanochat 成为了许多开发者学习 LLM 原理、进行算法尝试,以及开展 AI-for-AI(即用AI优化AI系统) 研究的理想起点。据 Karpathy 透露,nanochat 现在已经可以在单个 8×H100 节点上,仅用约 2 小时就训练出一个具备 GPT-2 能力级别的模型。
autoresearch 项目正是站在 nanochat 这个“肩膀”上,往前迈出了更激进的一步:将代码的迭代权也交给了 AI。它像一个实验性的沙盒,让我们得以窥见,当研究过程本身被自动化、智能化之后,技术进步的轨迹可能会如何演变。
你对这种 AI 驱动 AI 自我迭代的研究模式怎么看?是感到兴奋,还是有所担忧?欢迎在 云栈社区 的相关板块分享你的见解,与其他开发者一起探讨人工智能与开源实战的未来。
 发表于 2026-3-10 14:22:16
|
查看: 244|
回复: 0
发表于 2026-3-10 14:22:16
|
查看: 244|
回复: 0
