在工业物联网、智能运维和数据中台建设的实践中,一个普遍的痛点是如何高效、灵活地汇聚、处理并写入来自不同设备、协议和系统的数据。传统方法通常依赖大量硬编码,一旦业务需求变更,就需要修改代码、重新部署,流程繁琐且容易出错。有没有一种工具,能够让数据流转像搭积木一样直观简单呢?
本文将介绍一个基于 Actor 模型的可视化数据流程编排平台——DataLink。它旨在通过低代码甚至零代码的方式,让业务人员或运维工程师也能轻松构建复杂的数据管道。
项目介绍
DataLink 的核心设计理念是“低代码、高灵活”。它将复杂的数据处理过程拆解为一个个独立的功能“节点”(例如数据监听、过滤、转换、写入等),用户只需通过拖拽和连线的方式,就能将这些节点组合成完整的数据处理流程。其底层采用 Actor 模型实现,确保了高并发处理能力与良好的资源隔离性,使各个数据流之间互不干扰。
无论是从一台 Modbus 设备读取传感器数据,还是从 Kafka 订阅日志消息并清洗后写入 TDengine,都只需在可视化界面进行几步配置,无需编写任何代码。此外,它原生支持集群部署,仅需两个节点即可组成高可用集群,非常适合在生产环境中使用。
项目功能
- 可视化编排:支持通过拖拽画布的方式,直观地编排数据处理流程。
- 多协议监听:可监听多种工业与互联网协议,包括 TCP、UDP、HTTP、CoAP、OPC UA、SNMP、Modbus TCP。
- 消息中间件集成:支持订阅主流消息队列,如 MQTT、Kafka、RabbitMQ、RocketMQ、ActiveMQ。
- 丰富的数据处理能力:提供数据分发、条件过滤、打包、延迟触发、速率限制、自定义脚本(Groovy/JavaScript)等多种处理节点。
- 多目标存储:支持将处理后的数据写入多种数据库与存储系统,包括 MySQL、PostgreSQL、SQL Server、TDengine、Redis,以及本地文件。
- 集群高可用:支持最少两个节点的集群模式,保障服务高可用与负载均衡。
项目特点
- 真正零代码:业务或运维人员即可完成复杂数据链路的搭建,降低技术门槛。
- 协议覆盖广:从传统工业协议到现代消息队列,基本实现了“一网打尽”。
- 处理逻辑灵活:除了内置的常用处理器,还支持通过脚本进行灵活扩展。
- 轻量级集群:无需依赖 ZooKeeper 等外部协调服务,架构简洁,两节点即可组网。
- 资源隔离好:基于 Actor 模型实现,单个流程出现异常不会影响整体系统的稳定运行。
- 开源免费:项目采用 Apache 2.0 协议开源,可商用、可修改,无隐藏限制。
技术架构
- 核心架构:基于 Actor 模型实现高并发、松耦合的数据流处理。
- 前端界面:采用主流 Web 技术栈实现可视化流程编排画布。
- 协议支持:集成 Netty(处理 TCP/UDP)、Vert.x(处理 HTTP/CoAP)以及各类第三方 SDK(如 OPC UA、Modbus 等)。
- 消息中间件:通过各中间件的标准客户端进行接入。
- 存储适配:使用 JDBC、Jedis、TDengine 官方驱动等实现多数据库写入。
- 集群通信:基于 Akka 或自研的轻量级 Actor 通信机制,支持节点自动发现与任务分发。
实际应用效果
在实际场景中,DataLink 已被应用于多个项目。例如,某制造企业使用它从车间 PLC 通过 Modbus TCP 采集设备状态数据,经过过滤和聚合处理后,一方面通过 MQTT 发送给上位监控系统,另一方面将原始数据存入 TDengine 供后续分析。又如,在某智慧城市项目中,通过 HTTP 接收各类传感器上报的数据,经自定义脚本解析后写入 PostgreSQL,并同时触发相应的告警规则。
用户反馈最深的体会是“快”和“稳”。过去需要一周时间开发调试的数据对接任务,现在一天内就能配置上线;即使某个数据处理流程因配置问题出错,其他独立的数据链路依然可以正常运行,体现了其良好的隔离性。
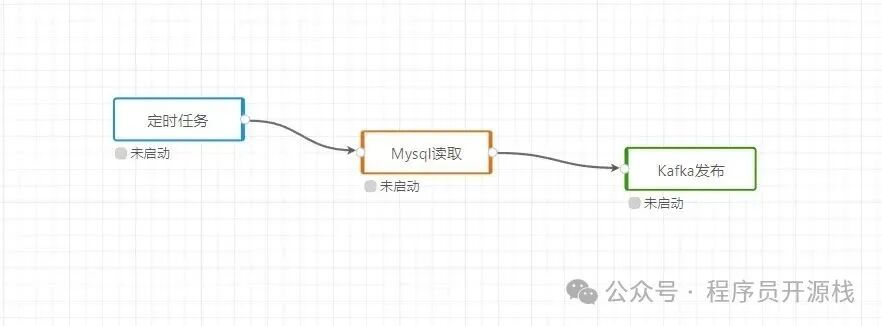
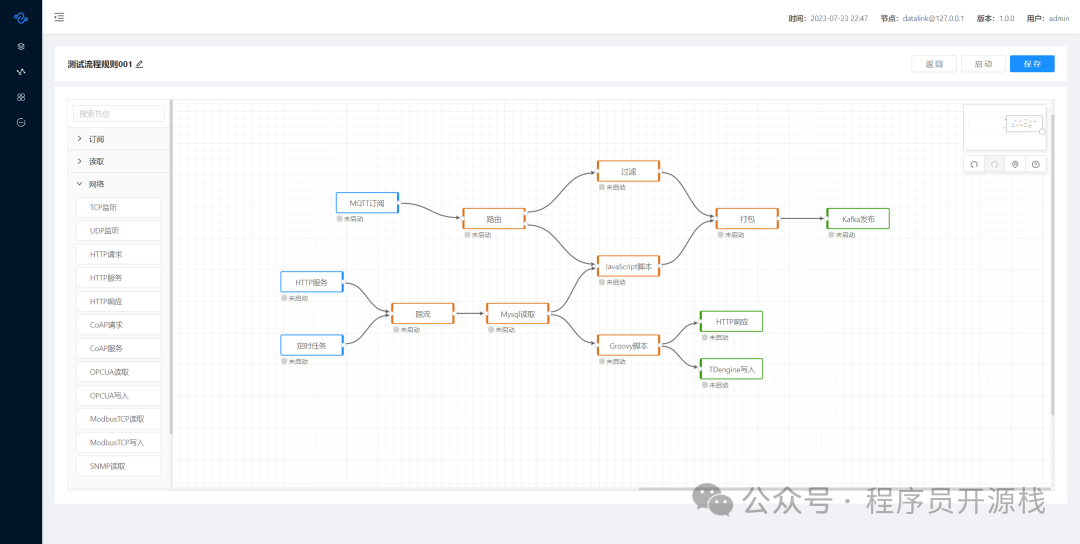
项目源码与扩展
项目代码结构清晰,包含了核心引擎、协议插件、处理器模块和 Web 控制台等主要部分。官方提供了详尽的文档,涵盖从安装部署、节点配置、集群搭建到脚本编写的全流程。对于有定制化需求的企业或开发者,可以基于其开放的插件机制,开发私有协议适配器或特殊的处理逻辑,扩展性良好。
项目地址:https://gitee.com/liyang9512/datalink
总结
总体而言,DataLink 在一定程度上填补了开源领域在“可视化数据流程编排”方向的一个空白。它不像 Apache Flink 那样专注于大数据批流计算,也不像 Node-RED 那样偏向 IoT 场景的原型验证,而是聚焦于 企业级、生产可用、协议多样、部署简单 的数据流转与集成场景。对于正在构建数据中台、工业互联网平台或需要快速打通多源异构系统的团队来说,它是一个值得尝试的轻量级利器。
如果你对这类低代码数据集成工具或 Actor 模型的应用实践感兴趣,欢迎在技术社区交流探讨。 |  发表于 2026-3-10 14:59:37
|
查看: 284|
回复: 0
发表于 2026-3-10 14:59:37
|
查看: 284|
回复: 0
