网络拥塞是互联网中一个经典且持续存在的问题。它发生在网络中对资源的需求超过其承载能力时,导致数据包丢失、延迟增加和吞吐量下降。为了解决这一问题,TCP/IP协议栈在传输层引入了拥塞控制机制。
TCP拥塞控制的目标是在共享的网络环境中实现公平、高效的数据传输。它的核心思想是通过端到端的反馈来探测网络状况,并动态调整发送速率,以最大化利用网络带宽,同时避免网络过载。其主要流程如下图所示:
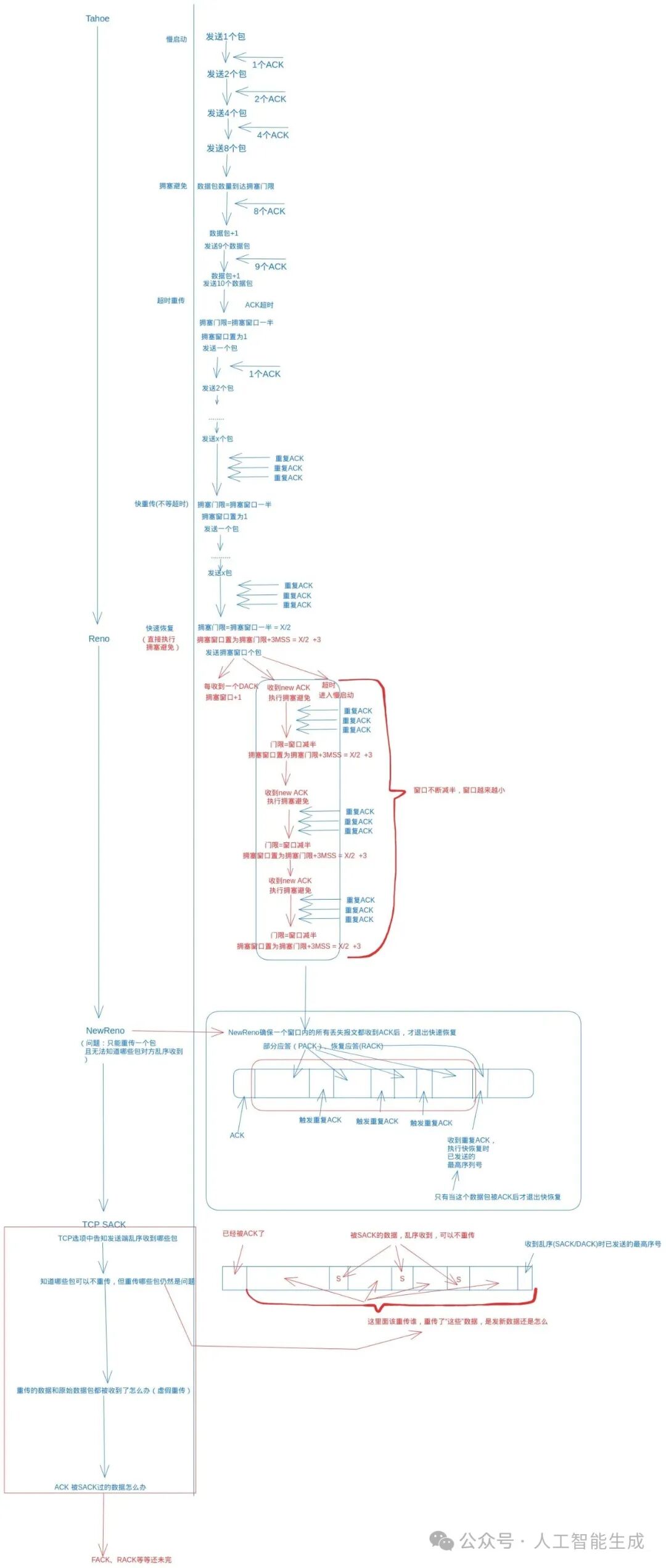
从上图可以看出,拥塞控制是一个根据网络状态(主要通过丢包和延迟来感知)动态调整发送窗口(cwnd)的闭环反馈过程。作为一种核心的网络协议,TCP的拥塞控制算法经历了数代演进,每一代都旨在更好地适应不断变化的网络环境。
TCP Tahoe 与 Reno
这是拥塞控制最早的经典实现,奠定了“加性增、乘性减”的基础。
- Tahoe算法:包含慢启动、拥塞避免和快速重传三个阶段。其核心特点是一旦发生超时重传或收到三个重复ACK,就会直接将拥塞窗口(cwnd)降为1个MSS,并重新进入慢启动阶段。这种方式在应对单一丢包时显得过于激进,会导致吞吐量剧烈波动。
- Reno算法:在Tahoe的基础上引入了快速恢复阶段。当收到三个重复ACK时,Reno认为这只是单个数据包丢失,而非严重拥塞。此时,它会将cwnd减半(而不是重置为1),然后进入快速恢复阶段,线性增长cwnd,直到收到新的ACK为止。这减少了一次丢包对性能的影响。
TCP New Reno
Reno算法在快速恢复期间,如果同一个窗口内有多个数据包丢失,它可能无法完全恢复,会导致超时。New Reno对此进行了改进:在快速恢复阶段,只有在收到所有未确认数据的ACK(即完全恢复丢失的整个窗口)后,才会退出快速恢复并进入拥塞避免阶段。这使得它能更好地处理多个数据包丢失的情况。
TCP BIC 与 CUBIC
随着网络带宽延迟积(BDP)的增大,传统的AIMD(加性增乘性减)算法收敛到公平点的速度变慢。BIC和CUBIC是为高速长距离网络设计的高性能算法。
- BIC:使用二分搜索的思想来寻找最佳窗口大小。当发生丢包时,它将当前窗口设为
W_max,并将窗口最小值设为W_min,然后通过二分法将窗口调整到(W_max+W_min)/2。这种方式使窗口能够快速逼近最优值,但在RTT较短的网络中可能过于激进。
- CUBIC:这是Linux系统长期以来的默认算法,也是目前应用最广泛的算法之一。它用三次函数替代了BIC的二分搜索。CUBIC的窗口增长函数独立于RTT,仅与上次发生拥塞的时间间隔有关(
W(t) = C*(t-K)^3 + W_max)。这使得它在高BDP网络中能更平滑、更公平地增长窗口,并且对短RTT流更友好,减少了窗口的剧烈波动。
TCP BBR
由Google提出的BBR(Bottleneck Bandwidth and RTT)代表了拥塞控制的一个新思路。它不再将丢包作为拥塞的主要信号,而是认为排队延迟的增加才是网络发生拥塞的先兆。
- 核心原理:BBR通过周期性地探测路径的带宽和最小RTT,来建立对网络路径容量的认知模型。它试图让发送速率恰好等于瓶颈带宽,并且让数据包排队时延保持最小(即让飞行数据量= BDP)。
- 工作阶段:BBR周期性地经历四个阶段:
- Startup:类似慢启动,快速探测最大带宽。
- Drain:排空Startup阶段可能造成的队列积压。
- Probe_BW:稳定运行阶段,周期性进行带宽探测(小幅增加发送速率)。
- Probe_RTT:周期性降低发送速率,以探测最小RTT。
- 优势:在存在轻微丢包(如无线网络)或缓冲区膨胀(Bufferbloat)的网络中,BBR通常能获得比CUBIC等基于丢包的算法更高的吞吐量和更低的延迟。
从基于丢包(Tahoe/Reno/CUBIC)到基于延迟(BBR)的演进,TCP拥塞控制算法的目标始终是更精准地感知网络状态,在效率、公平性和延迟之间取得最佳平衡,以适应从有线网络到移动网络、从低带宽到超高带宽的各种复杂环境。 |  发表于 2025-12-8 04:21:04
|
查看: 168|
回复: 0
发表于 2025-12-8 04:21:04
|
查看: 168|
回复: 0
