最近在 GitHub 上发现了一个挺有潜力的项目:OpenClaw-RL。
项目地址是:https://github.com/Gen-Verse/OpenClaw-RL
它的口号非常直接:“Train any agent simply by talking.” 简单来说,就是通过日常的聊天交互,让 AI 智能体(Agent)变得越来越聪明。
这个思路值得我们关注,因为它很可能预示着 Agent 训练范式的一次重要转变。今天,我们就来聊聊这个项目的核心逻辑,以及它背后的思考。
当前Agent系统面临的核心困境
如果你正在实践或研究 Agent 系统,可能已经发现一个现实:Agent 很难真正地“持续学习”和变聪明。
目前大多数 Agent 的工作流程可以简化为:
用户 → Prompt → LLM → Tool → 返回结果
当结果不尽如人意时,开发者通常只有几个选择:修改提示词(Prompt)、增加工具(Tool)、设计更复杂的工作流(Workflow),或者直接更换一个更强大的大语言模型。
但这里存在一个结构性的问题:Agent 很少能从与用户的真实交互中积累经验、自我改进。换句话说,Agent 这次犯的错误,下次遇到类似情况时,很可能还会再犯。
究其根本,原因在于大语言模型(LLM)的推理(Inference)系统与训练(Training)系统通常是完全分离的。我们使用的是训练好的、静态的模型,而非一个能在使用中动态成长的系统。
传统RLHF方法的局限性
在大型语言模型的优化领域,让模型“变得更好”的主流方法仍然是基于人类反馈的强化学习(RLHF)或其他强化学习(RL)技术。然而,传统的RLHF流程存在几个明显的限制:
1. 离线训练模式
它需要预先准备好格式化的数据集,例如:
Prompt
Response A
Response B
Human preference
然后才能进行集中的模型训练。
2. 训练与使用严重脱节
典型的流程是:收集数据 -> 集中训练 -> 发布新模型。在这个过程中,用户正在使用的模型版本是固定的,不会因为用户的使用反馈而实时变好。
3. 实施成本高昂
进行RLHF通常涉及大规模的人工标注、复杂的训练集构建以及一整套强化学习训练流水线,这对许多团队来说门槛不低。
OpenClaw-RL的核心设计思路
OpenClaw-RL 的构想很直观:将强化学习(RL)无缝地融入到 Agent 与用户的日常对话中。
其核心流程可以概括为:
用户聊天
↓
系统自动收集交互轨迹
↓
(后台)评估回答质量
↓
(后台)持续进行模型训练
这意味着,你使用 Agent 的每一次对话,都在为它的成长提供“养料”。正如项目所述,它的目标是“turns everyday conversations into training signals”(将日常对话转化为训练信号)。
典型的AI基础设施架构
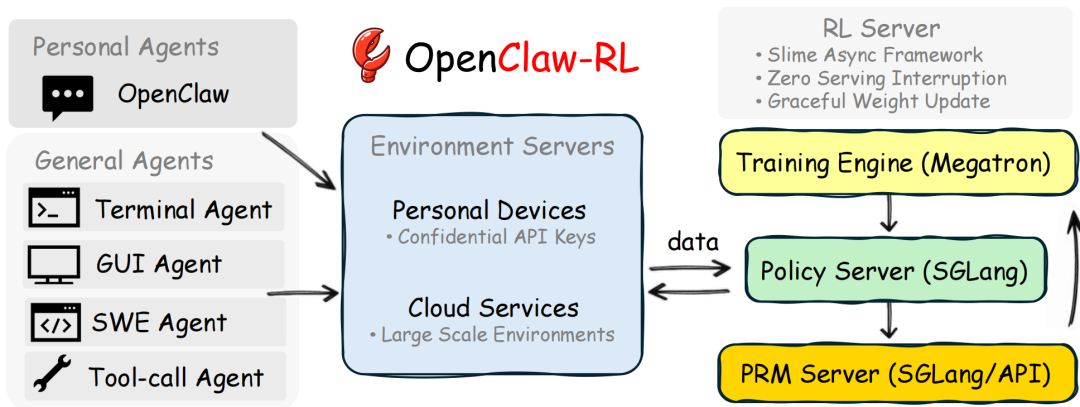
从架构上看,OpenClaw-RL 的设计颇具典型的 AI 基础设施风格。它将整个系统拆分为 4 个异步运行的组件:
Agent Serving
│
▼
Rollout Collection
│
▼
PRM Judging
│
▼
Policy Training
这里的关键在于:所有组件都是异步的。这保证了用户前端可以无感知、无中断地继续使用 Agent,而后台的轨迹收集、质量评估和模型训练也在持续进行,互不阻塞。
其架构图展示的,正是一个完整的在线强化学习闭环:
Conversation
↓
Trajectory
↓
Reward / Hint
↓
Policy Update
项目实现的两种训练模式
OpenClaw-RL 目前实现了两种不同的强化学习方法,以适应不同的优化目标。
1. Binary RL(基于GRPO)
这种方法更接近传统的RLHF思路。它通过一个 Process Reward Model (PRM) 对Agent生成的回答进行打分(例如:good, bad, neutral)。然后,利用 GRPO(Group Relative Policy Optimization)结合PPO风格的损失函数来优化模型策略。
2. OPD(On-Policy Distillation,在线策略蒸馏)
这种方法更有趣一些。它不仅仅给出一个简单的奖励分数,而是尝试从用户的自然反馈中提取出具体的改进提示(hint)。
例如,用户说:“你应该先检查这个文件。” 系统会识别出这个“hint”,并将其加入到原始提示词中,生成一个更优的“教师响应”(teacher response)。随后,模型通过对比学生响应(原始输出)和教师响应,进行令牌级别(token-level)的知识蒸馏学习。
简单说,就是利用用户的“事后提示”来指导模型,实现更精细的优化。这为强化学习在复杂任务中的应用提供了新思路。
超越算法:在线化训练是未来方向
在我看来,这个项目最值得关注的点并非某个具体的算法,而是它指出的一个方向:Agent 的训练将不可避免地走向“在线化”。
未来的 Agent 系统很可能遵循 “使用 -> 学习 -> 改进” 的持续循环,而不再是当前 “使用 -> 收集数据 -> 训练 -> 发布新版本” 这种漫长且割裂的流程。这是两种完全不同的系统设计哲学。
为什么这个方向值得关注?
如果这一趋势持续发展,将带来一个根本性的变化:Agent 会越来越像一个能够自我演进的“软件系统”,而非一个静态的“模型”。
未来的 Agent 运行时(Agent Runtime)可能包含:记忆模块(Memory)、强化学习闭环(RL Loop)、技能学习(Skill Learning)等核心组件。它不再仅仅是调用一个大语言模型 API 那么简单。
这也是为什么当前开源社区和工业界开始涌现越来越多关于 Agent 强化学习、技能学习、自我改进、记忆训练等方向的研究与实践。OpenClaw-RL 正是对这类前沿问题的有益探索,作为一个开源项目,它为社区提供了宝贵的参考。
对AI基础设施的新需求
从基础设施的角度看,这类在线学习系统也催生了对新底层架构的需求。它需要一套全新的技术栈来支持:
Agent Serving(智能体服务)
Trajectory Storage(轨迹存储)
Reward Model(奖励模型)
RL Training(强化学习训练)
Model Update(模型更新)
简而言之,就是 Agent 运行时与 RL 基础设施的深度融合。这很可能在未来成为一个新的、关键的基础设施层。
现状与展望
当然,OpenClaw-RL 目前仍处于比较早期的阶段,面临一些挑战,例如对多 GPU 算力的需求、训练成本以及较高的工程复杂度。
但它的思路极具启发性,因为它尝试回答一个关键问题:Agent 如何才能持续地变聪明?
一个值得观察的行业趋势
我们观察到一种越来越明显的趋势:Agent 系统的焦点正在从“提示词工程(Prompt Engineering)”转向“强化学习系统(RL Systems)”。
过去,大家主要围绕提示词、工作流和工具库做文章。而未来,我们可能会更多地讨论交互轨迹(Trajectory)、奖励函数(Reward)和策略优化(Policy Optimization)。也就是说,Agent 将越来越像一个标准的强化学习系统。
结语
如果你正在从事 Agent 或 AI 基础设施相关的工作,建议了解一下这个项目(https://github.com/Gen-Verse/OpenClaw-RL)。它未必能立即投入生产,但其代表的 “让 Agent 在真实使用中持续学习” 的方向,值得我们思考。
试想,如果未来的 Agent 真能做到“越用越聪明”,那么许多现有 AI 系统的形态和开发模式,都可能发生深刻的变化。对于这个方向的更多技术讨论和实践,欢迎关注云栈社区的相关板块。
 发表于 2026-3-12 06:13:07
|
查看: 251|
回复: 0
发表于 2026-3-12 06:13:07
|
查看: 251|
回复: 0
