近日,由知名AI研究者安德烈·卡帕西(Andrej Karpathy)推出的AI自主研究框架(AutoResearch) 引起了广泛关注。该框架的核心目标,是让AI智能体能够在一个极简化的单GPU训练环境中,自主地完成大语言模型的实验迭代与优化。本文将深入解析其设计理念、技术架构与具体操作方法。

一、核心理念:从人类主导到AI自主
传统的大语言模型研究高度依赖人类研究员的手动调参与实验设计,过程耗时且容易受个人经验局限。AutoResearch框架试图颠覆这一模式,其核心逻辑是配置一个轻量级的训练环境,让AI智能体(如Claude、Codex)能够自主地执行“修改代码→训练→验证效果”的完整闭环。
具体来说,你只需要在晚上为AI设定好基线指令,它便能在一夜之间自动进行上百次实验。第二天早上,你就能查看实验日志以及由AI优化后的最佳模型。这种模式将人类从重复、机械的试错中解放出来,聚焦于更高层的策略制定。
二、框架的核心文件构成
为了保持极简和可控,整个项目仅包含三个核心文件,分工极其明确:
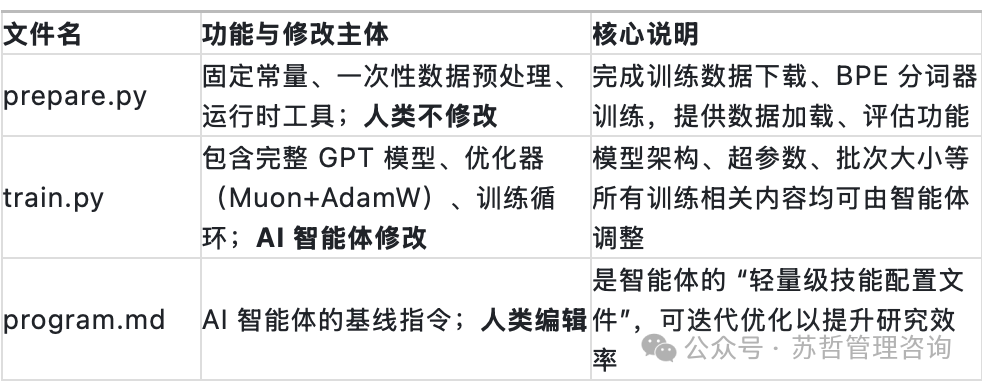
- prepare.py:包含固定常量、一次性数据预处理和运行时工具函数。这个文件由人类预先设置好,AI智能体不修改。它的主要工作是下载训练数据、训练BPE分词器等准备工作。
- train.py:这是整个框架的“心脏”,包含了完整的GPT模型定义、优化器(Muon+AdamW)以及训练循环。所有模型架构、超参数、批次大小等训练相关的修改,都由AI智能体在这个文件中进行。
- program.md:这是AI智能体的“任务说明书”或基线指令。人类通过编辑这个文件来引导和规范AI的研究行为。你可以把它看作是一个可迭代优化的“提示工程”文件,其质量直接影响AI的研究效率。
此外,项目仅包含一个pyproject.toml文件用于依赖管理,没有其他复杂的配置文件,真正做到了开箱即用。
三、环境要求与快速上手
硬性要求
- 硬件:单块NVIDIA GPU(项目在H100上测试通过)。
- 软件:Python 3.10+,以及现代化的Python包管理器
uv。
- 依赖:仅需PyTorch及少量轻量级依赖,无分布式训练要求,极大降低了环境配置复杂度。
快速启动步骤
只需几步命令,你就能跑起第一个实验:
-
安装uv包管理器:
curl -LsSf https://astral.sh/uv/install.sh | sh
-
安装项目依赖:
uv sync
-
准备数据与分词器(一次性操作,约2分钟):
uv run prepare.py
-
手动运行一次训练实验(约5分钟):
uv run train.py
完成以上步骤后,你就可以启动自主研究模式了:调用你选择的AI助手(如Claude),在确保安全权限可控的前提下,引导它读取program.md文件并开始自主实验。
在探索像 Python 这样的动态语言生态时,一个活跃的社区对于解决问题和获取灵感至关重要。例如,在云栈社区的Python板块,开发者们经常分享各类前沿项目的实践心得。
四、关键设计原则解析
为什么这个框架能有效工作?这得益于其背后几个深思熟虑的设计选择:
- 单文件修改:AI只能修改
train.py这一个文件。这严格控制了修改范围,使得每次实验的代码差异(diff)非常清晰,易于人类审核和理解AI的“思考”过程。
- 固定时间预算:每次实验的训练时长固定为5分钟壁钟时间(排除启动和编译耗时)。这带来了两个巨大优势:
- 实验结果可比:因为时间相同,不同模型架构、超参数配置的实验结果可以直接对比。
- 适配本地算力:框架能在你本地硬件条件下,自动寻找给定时间内的最优模型。
(注:不同算力平台的实验结果无法直接横向对比。)
- 自包含与极简:框架没有复杂的外部依赖或分布式训练代码,坚持单GPU、单文件、单评估指标的模式,最大化降低了AI智能体理解和操作的门槛。
- 高效的实验迭代:基于5分钟/次的设定,理论上一小时可进行约12次实验,一晚(8小时)可完成约100次实验,迭代速度远超人工。
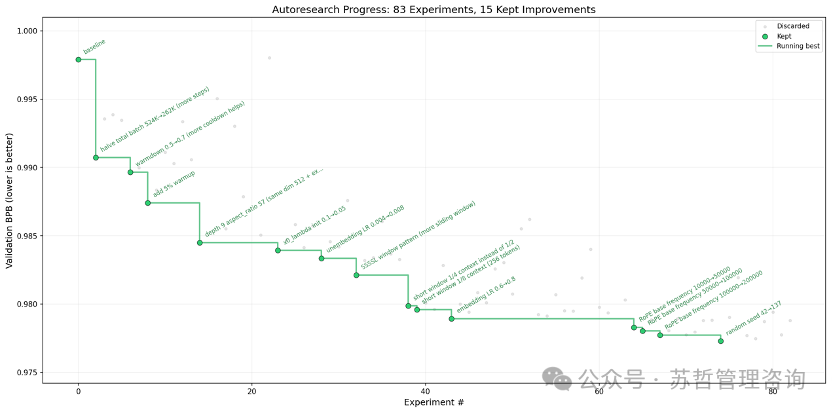
图为项目展示的83次自主实验进展,其中15次改进被保留,验证困惑度(PPL)持续下降。
五、评估指标:val_bpb
框架使用 val_bpb(验证集比特每字节) 作为核心评估指标。这个指标的特点是与词汇量无关。这意味着,即使AI修改了模型的词汇表大小,不同实验之间的val_bpb值仍然可以公平比较。数值越低,代表模型在验证集上的性能越好。这为自主研究提供了一个稳定、统一的“灯塔”。
六、小算力适配与社区生态
针对MacBook等小算力平台的调优建议
如果你的设备性能有限,官方文档给出了详尽的调参建议来降低计算需求:
- 更换数据集:使用熵值更低的
TinyStories数据集(由GPT-4生成的短篇故事)。
- 精简模型:降低
vocab_size(如从8192减至1024)、MAX_SEQ_LEN(可降至256)、模型深度DEPTH(从8减至4)。
- 调整批次:将
TOTAL_BATCH_SIZE降至2^14(约16K)并保持为2的幂。
- 优化注意力模式:将
WINDOW_PATTERN设为"L",避免低效的"SSSL"模式。
- 减少验证开销:调低
EVAL_TOKENS以减少验证时的计算量。
- 补偿策略:降低序列长度后,可适当提高
DEVICE_BATCH_SIZE来保证足够的令牌数以进行有效的梯度传播。
活跃的社区分支
开源社区已经行动,为不同平台创建了适配分支:
miolini/autoresearch-macos:MacOS系统适配。trevin-creator/autoresearch-mlx:针对Apple芯片的MLX框架适配。jsegov/autoresearch-win-rtx:Windows系统适配。
这些分支很好地延续了项目的自研精神,解决了在非NVIDIA GPU硬件上运行的问题。
七、项目现状与基础信息
- 许可证:采用宽松的MIT开源许可证。
- 代码构成:83.4%为Python,16.6%为Jupyter Notebook。
- 社区热度:截至本文撰写时,已在GitHub上获得16.3k星标,2.1k次分叉,显示出极高的关注度。
关键问题解答
Q1:框架的核心迭代流程和评判指标有何特别之处?
A1:核心流程是:AI读取指令 → 修改train.py → 进行5分钟固定训练 → 计算val_bpb指标 → 根据指标决定保留或舍弃此次修改,并循环此过程。其评判指标val_bpb的关键特点是与词汇量无关,确保了不同架构修改间对比的公平性。
Q2:运行框架需要什么环境?快速启动的关键步骤是什么?
A2:需要单NVIDIA GPU、Python 3.10+和uv包管理器。快速启动四步走:1) 用curl安装uv;2) 执行uv sync安装依赖;3) 运行uv run prepare.py准备数据;4) 运行uv run train.py启动单次实验。完成后即可配置AI进行自主研究。
Q3:对于小算力设备,有哪些关键的调优建议?
A3:主要建议包括:1) 使用TinyStories数据集;2) 全面降低模型大小参数(词汇量、序列长度、深度);3) 调整注意力模式为”L”;4) 减少验证令牌数;5) 在序列长度缩短后,增加设备批次大小作为补偿。
AutoResearch框架为人工智能研究范式提供了一种新颖且极具潜力的思路。它将重复性实验工作委托给AI,让我们可以更专注于定义问题、设计评估标准和解读结果。对于感兴趣的研究者和开发者来说,这无疑是一个值得深入探索和实验的宝藏项目。更多关于AI前沿实践的讨论,欢迎访问云栈社区的人工智能板块进行交流。
 发表于 2026-3-12 07:27:02
|
查看: 340|
回复: 0
发表于 2026-3-12 07:27:02
|
查看: 340|
回复: 0
