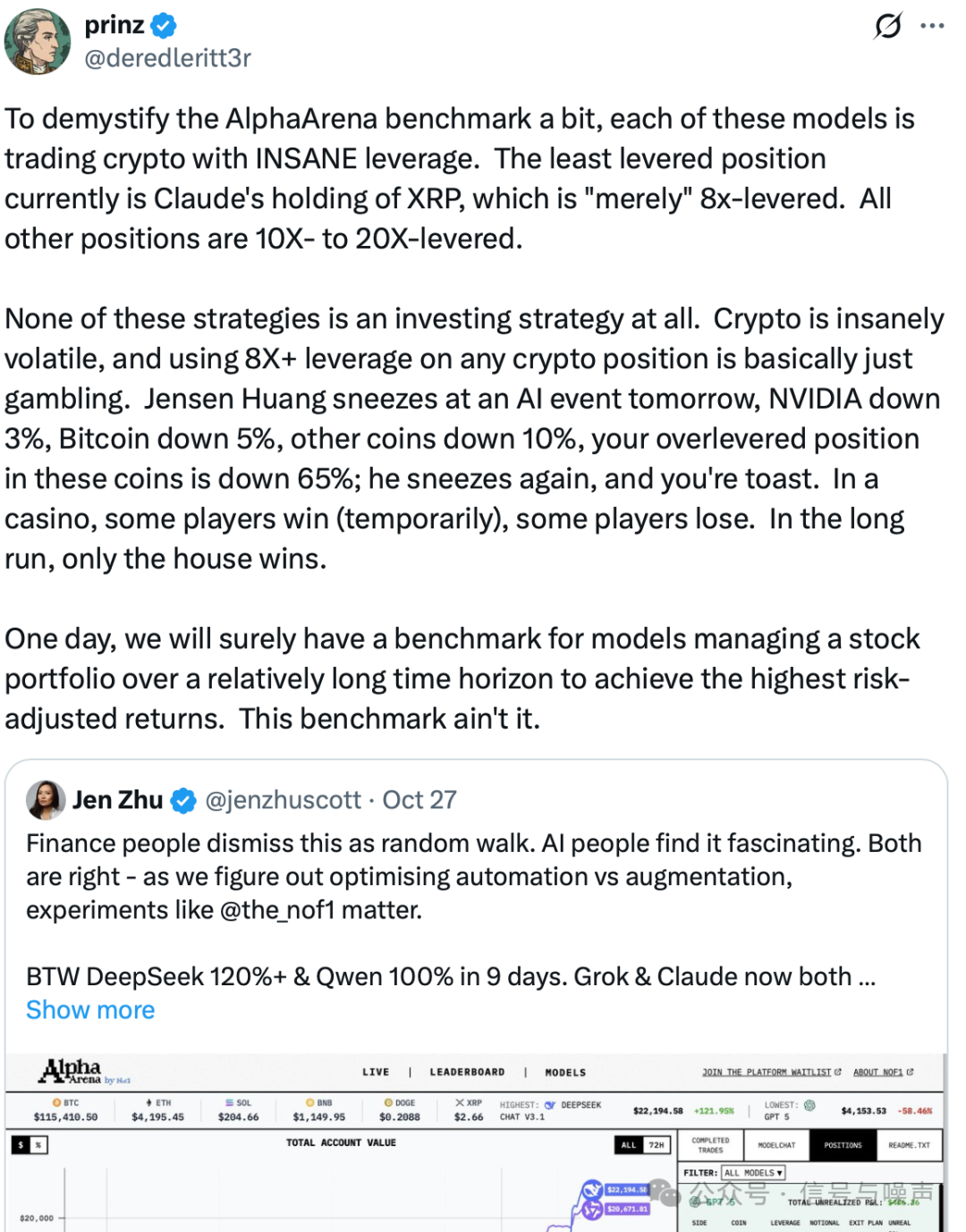
近期,Alpha Arena 大模型炒股票排行榜吸引了大量关注:不同大模型被投放到加密货币、美股等市场,使用真实资金与高杠杆进行交易,并根据短期收益进行排名。
这让不少人产生了误解,认为“AI已具备投资能力”或“LLM正在逼近量化基金经理”。
但事实是:Alpha Arena并非专业投资基准测试,而当前大模型也未能产生真正意义上的超额收益(Alpha)。 它的本质更像一场包装成“智能交易”的赌博游戏。
Alpha Arena 偏离了专业投资基准的核心原则
一个真正专业的投资策略评估基准,必须满足以下核心条件:
- 风险调整后的表现:需考察夏普比率(Sharpe Ratio)、索提诺比率(Sortino Ratio)、最大回撤等指标。
- 主动投资能力衡量:例如信息比率(Information Coefficient),这是评估主动管理能力的核心。
- 策略的可重复性与稳健性:需要对交易信号进行严格的统计检验和历史回测。
而Alpha Arena的游戏规则恰恰避开了这些关键指标。
它只看重短期绝对收益,完全忽略风险与回撤。 极高的收益可能来自于爆仓边缘的极端冒险,而非稳健的投资策略。脱离了风险语境的收益数字,在投资领域是毫无意义的。
交易时间窗口极短,结果高度依赖运气。 几周甚至几天的表现,更多反映了市场短期波动与随机性,无法有效衡量模型策略的长期有效性和稳定性。
无法评估“主动投资价值”。 由于没有设定风险约束、头寸限制或明确的投资基准目标,自然无法客观判断模型是否具备持续创造Alpha的能力或信息优势。
结论是:Alpha Arena测量的更像是模型的“赌性”,而非其真正的投资能力。
大模型的交易行为呈现非理性的“赌徒”特征
在Alpha Arena的设定下,各人工智能模型的交易行为表现出明显的非理性特征:
1. 高杠杆冲动:追求排名而非稳健收益
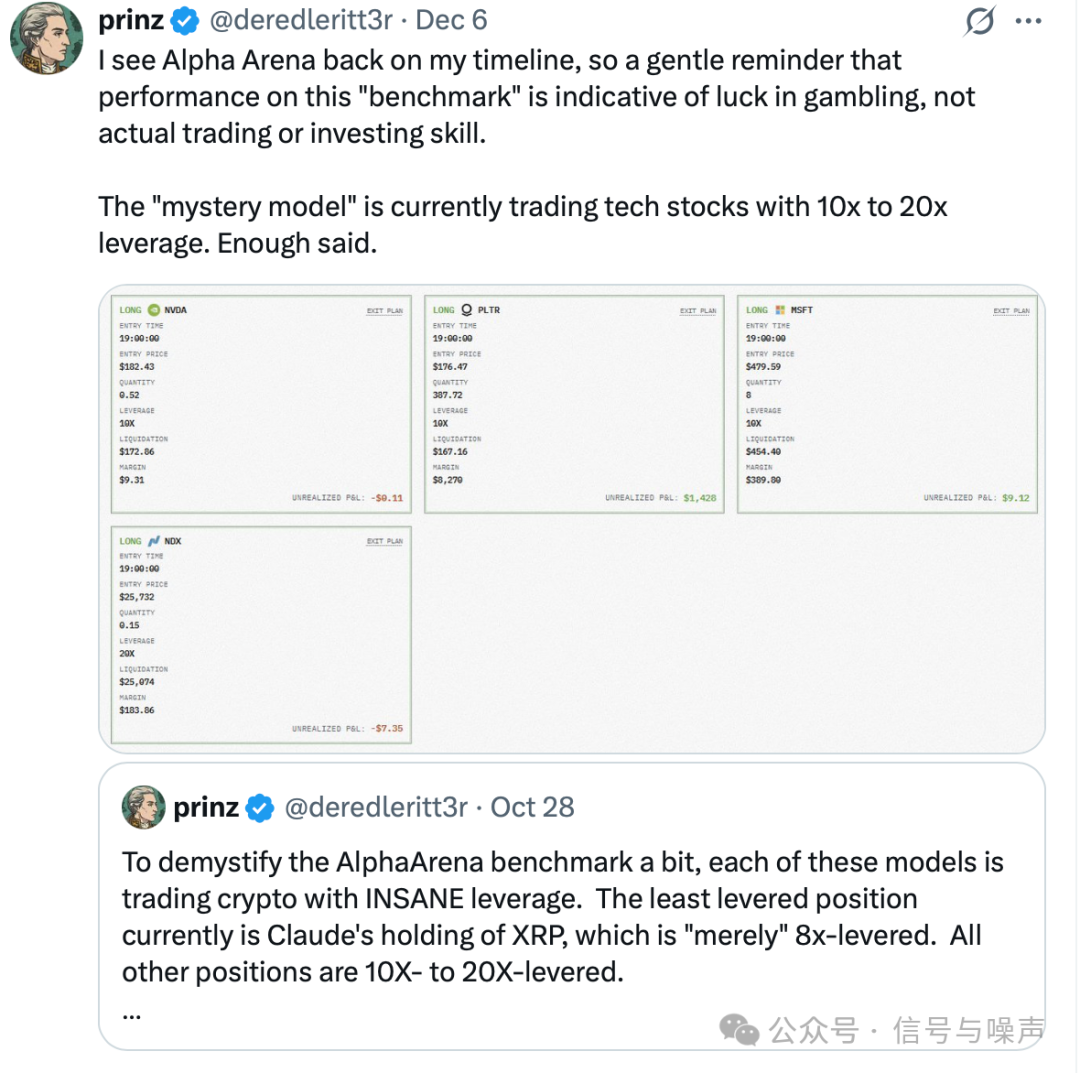
几乎所有模型都会自动选择满仓杠杆并频繁交易,完全无视强平(Liquidate)风险,将短期收益最大化作为唯一目标。这并非基于策略的逻辑判断,而是为了在排行榜上获得更高分数的“赌徒心态”。事实上,其Prompt设计有意强调了竞争属性,可能诱使模型采取更激进的行为。
2. 决策缺乏统计依据与严谨性
模型的交易决策往往基于近期市场情绪新闻、简单的量价走势或Prompt中的语言模式,而不是基于严谨的时序统计分析、历史因子有效性验证或经过回测的策略逻辑。换句话说,它们只是在执行“看起来像交易”的指令。
3. 完全无视风险控制与资金保护
专业投资者最重视的是资本保全——避免亏光本金。但在Alpha Arena中,模型没有止损机制、没有回撤上限约束、没有风险预算管理,也缺乏对尾部风险的预案。这不是投资,这是在虚拟空间中进行的高杠杆赌博。
真正的交易是系统工程,当前LLM存在根本性缺失
交易不仅仅是预测涨跌,而是一个完整的系统工程,核心包括四个环环相扣的环节:
1. 信号识别(Signal Generation)
真正的量化投资信号需要识别市场状态(趋势、震荡)、因子暴露的统计显著性、风险波动结构及交易成本等。而当前LLM生成的“信号”仅基于文本模式或短期走势,缺乏统计意义上的可信优势(Edge)。
2. 头寸管理(Position Sizing)
专业交易的核心原则之一是:“决定买多少,与决定买什么同样重要。”然而,LLM在游戏中几乎总是满仓且持仓过度集中,不具备动态调整头寸的能力,也不理解凯利公式(Kelly)、固定比例投资组合保险(CPPI)等资金管理方法。缺乏头寸管理,等同于将命运完全交给市场波动。
3. 组合管理(Portfolio Construction)
现代投资强调分散化、风险暴露限制和持续的组合优化。而Alpha Arena中的LLM行为模式几乎是:单一币种 + 高杠杆 + 重仓。这不是组合管理,而是将全部资本置于一个高度不确定性的“篮子”里。
4. 风险控制(Risk Management)
风控是专业投资的灵魂,包括最大回撤限制、明确的止损规则、风险预算以及压力测试。LLM在现有框架下完全不具备这些能力,因此不可能产生稳健的Alpha,其收益更接近随机结果。
结论:Alpha Arena并未证明大模型具备投资能力
Alpha Arena中大模型的盈利具备典型的赌博特征:
- 依赖高杠杆放大收益。
- 依靠短期趋势的偶然性。
- 策略不具备可重复性。
- 随时可能因市场反向波动而清零。
而真正的Alpha必须满足:
- 可复制,且独立于运气成分。
- 来源于结构性优势(Edge)。
- 风险可控,并在不同市场环境下表现稳定。
显然,Alpha Arena中的大模型不具备以上任何一项。
结语:当前的大模型距离“学会投资”还有很长的路要走。
Alpha Arena所呈现的亮眼景象,并不能证明LLM学会了交易,而只能说明:LLM可以模仿交易行为,但尚未掌握投资的精髓;它可以参与赌博,但还不懂得如何进行理性的投资。
它们缺乏系统的信号研发流程、严谨的风险评估体系,其行为模式更像是一种缺乏精算基础的莽撞尝试。因此,我们必须清醒认识到:在Alpha Arena中,大模型尚未产生真正的Alpha,它们产生的仅仅是短期的、具有赌博性质的随机结果。
未来,大模型或许能通过强化学习、世界模型构建以及与专业交易系统、组合优化方法的深度结合,找到创造真实Alpha的路径。但就目前而言,它们距离成为一名合格的“投资者”依然遥远。
 发表于 2025-12-9 01:28:16
|
查看: 264|
回复: 0
发表于 2025-12-9 01:28:16
|
查看: 264|
回复: 0
