最近几周,OpenClaw 无疑成了讨论的焦点,但相关的讨论往往充满了噪音,真正触及核心价值的信息却不多。事实上,像 OpenClaw 这样的技术,恰恰清晰地展现了 人工智能 重塑现实世界的潜力。而当前的信息环境,正需要我们去梳理出那些真正有意义的信号。
本文将围绕两个核心展开:首先,我会分享在 OpenClaw 热潮之后,我对 AI 智能体领域的一些个人思考;其次,我将详细拆解我自己从零搭建的一套 AI 智能体系统——它能够 7×24 小时自托管运行,其理念与网上常见的 OpenClaw 部署方案有异曲同工之妙。希望这篇文章能帮助大家过滤掉行业噪音,看到 AI 智能体技术背后更本质的价值。

在当前关于 AI 智能体的讨论中,我经常看到诸如“摆脱底层的窗口期不多了”、“一人即可创办百亿估值公司”之类的论调。这类内容虽然偶尔有一些启发,但多数时候更像是一种吸引眼球的噱头,目的是在社交媒体上获取流量。这种通过制造焦虑来博取关注的行为,对于推动 AI 智能体领域的健康发展并无益处,反而让人感到惋惜。
YC(Y Combinator)最近发布了 2026 年的创业项目征集令,其中的要求与 2025 年相比有了显著变化。最让我关注的一点是,YC 特别强调了“AI 原生机构”。起初我完全不明白为什么 YC 会如此推崇“机构”这种形式,直到我深入思考并与一些行业内的朋友交流后,才逐渐理清了背后的逻辑。
对“AI原生组织”的思考
从 ClawdBot 到 MoltBot,再到现在的 OpenClaw,这项技术拥有改变现实运作方式的巨大潜力。而它的核心价值,恰恰体现在对传统机构运营模式的重构上。
传统机构实现规模化的核心逻辑在于“人力扩张”。例如,一项服务定价 5000 美元,一家公司若想将月营收做到 5万到 10万美元,主要的途径就是扩大团队规模——即使客户质量和业务范围会有影响,但招聘始终是扩张的核心手段。印度两大软件服务巨头 TCS 和 Infosys,正是在 21 世纪初依靠这种模式实现了爆发式增长。
然而,AI 智能体的出现正在彻底颠覆这一逻辑。这些可以 7×24 小时不间断工作的“数字员工”,其成本可能仅为人类工程师的十分之一。如果应用得当,传统的服务机构将逐步向软件公司转型:不再需要投入大量精力进行招聘和人员管理,而是转向构建、优化和管理一支 AI 智能体团队。在我看来,这可能是 AI 智能体最具实际价值的应用场景之一,而这还只是其潜能的冰山一角。
当然,我们仍处在这个领域的早期阶段,未来充满不确定性。正如一篇热门文章中所言:
“未来正由极少数人塑造:几家公司的几百名研究人员……OpenAI、Anthropic、谷歌 DeepMind 等。一个小团队在几个月内进行的一次训练,就能产生一个改变整个技术发展轨迹的 AI 系统。”
尽管我们无法精准预测未来,但尽早尝试新技术、接触新事物,并从头开始思考这些技术将如何改变你的工作方式,总是有益的。这能帮你培养适应变化的能力,让你变得更加强大。
对我个人而言,OpenClaw 系列技术让我清晰地看到了 AI 智能体的核心潜力——将其打造为可以替代部分人工的“智能体员工”。这个想法其实由来已久,但我一直犹豫是否要动手实现。最终,是 OpenClaw 引发的行业热潮,推动我动手搭建了自己的智能体系统。
在过去几周里,我一直基于 Claude 3.5 Sonnet 和 GPT-4o 等模型开发这套系统,投入的精力让我两天就用完了 Cursor 的月度额度。整个开发过程充满挑战,但也乐趣十足。下面,我将详细拆解这套系统的搭建目标、技术实现以及背后的思考。
我的“一人公司”项目
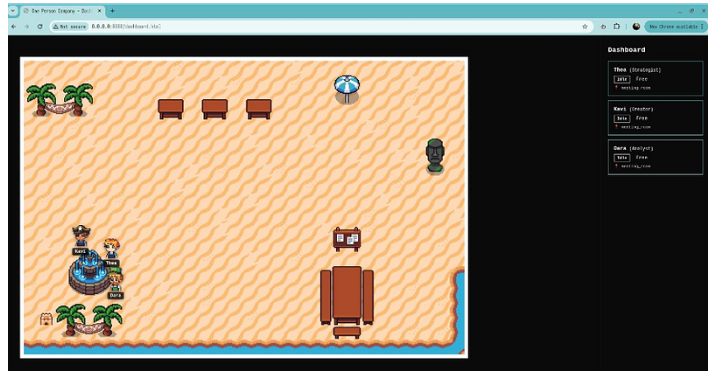
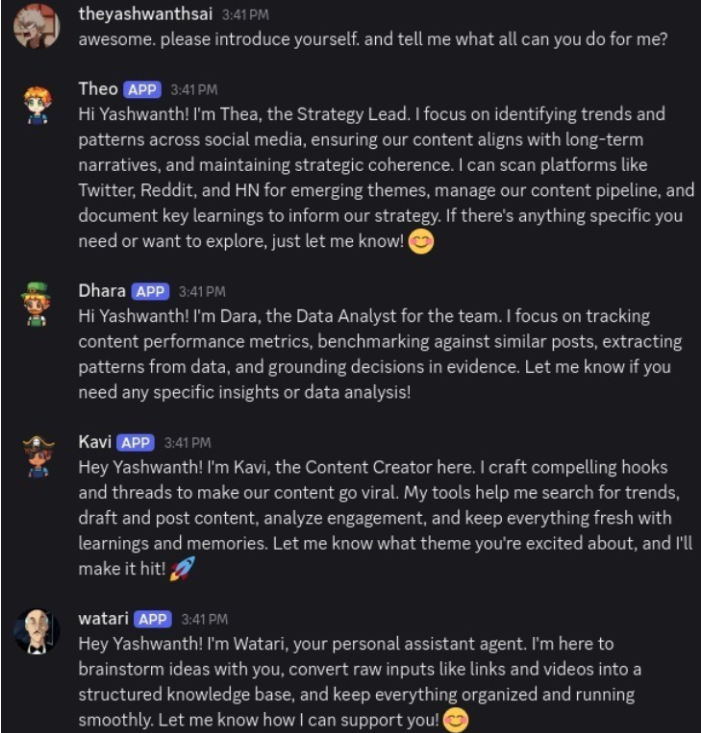
我把这个项目称为“一人公司”。它目前由四个 AI 智能体组成,每个智能体都有自己明确的工作角色、个性设定和目标任务。这四个智能体共同致力于一个核心目标:研究与内容创意支持。
为了持续输出内容,我需要持续学习。但我一直觉得很难跟上这个领域的发展速度,网上有太多的文章和帖子,而我根本没有时间一一阅读。
现在,我不希望 AI 只是简单地向我倾倒信息。我希望这些智能体能像一家社交媒体机构那样,持续地为我生成内容创意。而我作为这家“公司”的“CEO”,主要与内容生成流程进行互动,确保最终内容符合我的风格和想法。至于研究、趋势分析等其他工作,则全部交给这些智能体来完成。
目前,系统包含四个智能体、一个用于交互的 Discord 服务器,以及一份朝九晚五的“工作时间表”。整个系统运行在我自托管的树莓派上的调度器中。我的目标是让这些智能体能够全天候运行,并像真正的团队成员一样与我互动。
该项目目前已在 GitHub 开源,我也会持续改进,未来计划将团队规模扩展到 10 人以上。
技术实现:我是如何构建的?
接下来是更有趣的部分,让我们谈谈技术实现。代码已经开源,你可以随意查看和尝试。理解这个系统,有三个关键部分:
- 从头构建的智能体抽象层
- 内存管理机制
- 多智能体协作框架
智能体抽象层
我构建的核心是:取一个通过 API 调用的、无状态的大语言模型(LLM),然后向它注入提示词(包括定义其角色的 soul.md、规范其行为的 heartbeat.md、具体任务指令和期望的技能等),接着为其添加“记忆”(下一节详述),最后再提供它可使用的工具。
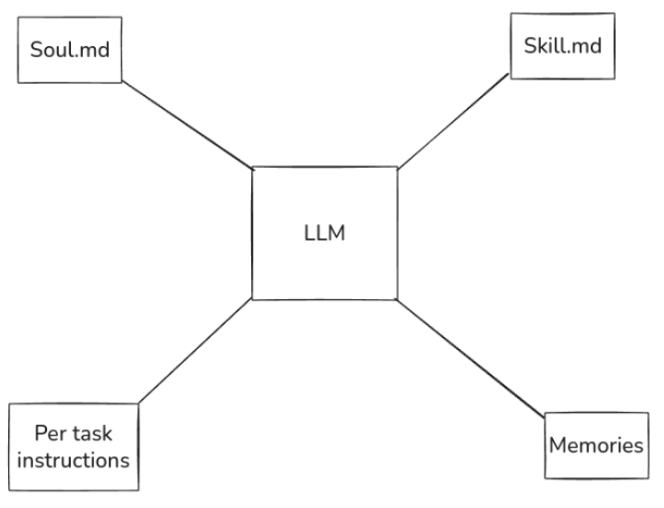
这就是一个智能体的基本工作方式。我构建的这个抽象层,其作用就是将原始的 LLM 转化成一个具有特定身份和能力的“智能体”。
内存管理
如何让智能体拥有“记忆”并持续学习,这仍然是一个开放性问题。因此,我创建了三个核心的 SQL 表:experiences(经验)、learnings(学习)和 sessions(会话)。

当一个智能体被调用执行时,会发生两件事:
- 系统会从这些表中检索出最近相关的几行数据,作为上下文提供给智能体。
- 智能体执行完毕后,总是会被要求向这三个表中写入一些新的内容(例如本次执行的总结、学到的东西等)。
这使得我的智能体具备了“状态”。这些 SQL 表会随着时间不断演变和丰富,而底层的 LLM 本身仍然是无状态的。两者结合,才构成了一个完整的、能够积累经验的“智能体”。
这种方法很酷,你的智能体可以拥有丰富的“阅历”,并随着时间不断成长,最终可能演化出一些非常有趣的能力。
但问题在于,当前的方法还比较初级。系统运行几周后,数据表会变得非常臃肿。如果将所有历史记录都传递给智能体,会严重拖慢速度、增加成本,并可能降低输出质量。
有几种思路可以解决这个问题:
- 限制上下文:只传递最近的“X”条记录。
- 基于检索的增强(RAG):进行智能检索,只传递与当前任务最相关的记录以及最近的一些记录。
- 记忆压缩:就像人类会遗忘一样,只存储必要的信息,对记忆进行压缩和摘要。
我必须尝试这些方法。我的目标是让智能体不仅拥有工作角色和“灵魂”,还能拥有高效、精简的“经验”。未来我还希望能引入基于本体论的更结构化记忆。
智能体协调框架
这是让系统发挥威力的关键。单个拥有丰富上下文(提示词、记忆等)的智能体已经很有用,但只有当不同的智能体能够相互协调、共同工作时,它们的真正力量才会被释放。
我引入了一个核心概念:“会话”(Session)。你可以把会话理解为一次智能体的“唤醒”与“执行”。想象一下我的系统:我有几个具有个性、处于“休眠”状态的人类员工。我在特定的时间“唤醒”他们,给他们指令,让他们去做某件事。这个过程就叫一次“会话”。会话是系统运作的基本单元。
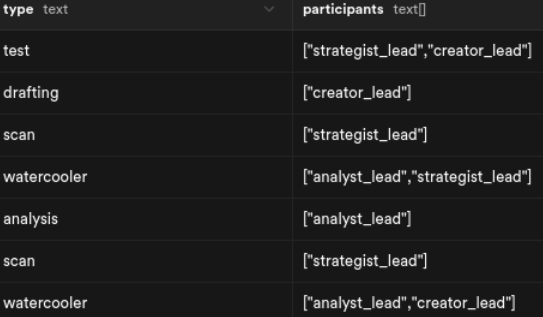
一次会话可以是:
- 单个智能体执行一项独立任务。
- 两个智能体进行非正式交流(我称之为“饮水机会议”)。
- 所有智能体一起进行头脑风暴或召开正式会议。
- 智能体与我进行每日站会。
- 紧急的一对一会议。
“会话”机制让协调变得非常灵活和强大。我可以让我的智能体相互交流,或与我交流,并将这些交流的总结和观察结果存入 SQL 表。这就是我的团队能够不断变强的原因。每一次会话都在提升整个系统的能力,推动其“进化”。
将智能体抽象层、内存管理和会话协调这三者结合在一起,就构成了我当前这个强大的 AI 智能体团队。当然,还有很多需要改进和优化的地方,我目前也正在积极测试这个系统。但日复一日,它正变得异常实用。
未来,我将在 云栈社区 分享更多关于这个项目的实践经验、遇到的挑战以及可能的改进方向。如果你对自托管 AI、智能体架构或者树莓派开发感兴趣,欢迎一起交流探讨。
 发表于 2026-3-12 08:42:24
|
查看: 149|
回复: 0
发表于 2026-3-12 08:42:24
|
查看: 149|
回复: 0
