规模法则(Scaling Law),又称标度定律,或简称标度律,是描述复杂系统中各种可测量特性如何随系统规模发生系统性地、可预测变化的数学关系。这些数学关系通常表现为幂律的形式,它们能够反映从生命体到城市、企业乃至人工智能大语言模型等复杂系统在规模缩放过程中展现出的结构、功能和动态行为上的普遍性规律。根据维斯特 (G. West) 的规模理论,规模法则不仅是一种普遍的实证规律,它更是预测复杂系统的生长与死亡的基础原则;透过规模法则,人们还可以构建复杂系统的网络模型,以解释、重构各类实证观察现象,同时推断复杂系统的结构与功能之间的关系,甚至有助于系统的优化与设计。
规模法则一般表现为如下的幂律形式:
$$
Y = cX^\alpha \quad \text{(1)}
$$
其中 $X$ 通常代表一个系统的规模,例如生物体的体重,城市的人口,企业的员工数等;$Y$ 则代表系统的某一种可测量的宏观变量,例如生物体的新陈代谢率、城市的GDP,以及企业的总收入等;$c$ 为规模法则的系数,它代表了规模缩放的基底,即系统规模为1单位的时候,$Y$ 是多少;$\alpha$ 为规模法则的幂指数,是规模法则的重要参数,刻画了 $Y$ 与 $X$ 的相对变化速度。根据指数 $\alpha$ 大小的不同,我们通常将规模法则划分为三种类型:
-
当 $\alpha > 1$
规模法则(1)称为超线性的(Super-linear)规模法则,这体现为 $Y$ 比 $X$ 增长得更快;
-
当 $\alpha < 1$
规模法则(1)称为亚线性的(Sub-linear)规模法则,这体现为 $Y$ 比 $X$ 增长得更慢;
-
当 $\alpha \approx 1$
规模法则(1)称为线性的(Linear)规模法则,这体现为 $Y$ 与 $X$ 成比例。
1. 规模分析简史
规模法则最早来源于规模分析(Scaling Analysis)方法,也译为标度分析、尺度分析。这是一种通过比较一个事物的不同物理量随尺度缩放变化的大致定量关系来揭示自然界普遍规律的方法。它不仅在物理学和工程学中存在着广泛应用,也是理解生物、社会和复杂系统的重要工具。这一思想可以追溯到伽利略,并在后来的科学发展中不断演进,逐渐形成了我们今天所称的“规模法则”(Scaling Laws)。几种典型的规模分析方法应用实例如下。
1.1 伽利略的规模缩放理论
伽利略(Galileo Galilei)在《关于两种新科学的对话与数学证明》中首次系统性提出了规模缩放的思想:如果一个物体按照几何比例放大,那么其力学性质不会简单地按比例的方式扩展,而是呈现出了一定的非线性的缩放规律。例如:
1.1.1 面积与体积的幂律关系
假设一个立方体边长为 $L$:那么其表面积 $A \propto L^2$,体积 $V \propto L^3$。这里符号“$\propto$”代表“成比例于”后面的变量,这是对幂律关系的一种简约的表达,即忽略了前面的系数,而只关注于幂律指数。
因此,当边长增大一倍时:面积只增加 $2^2 = 4$ 倍,体积却增加 $2^3 = 8$ 倍。因此,当一个几何体生长的时候,它的体积会比表面积增长得更快。
1.1.2 强度与重量
几何体的横截面积 $A$ 往往也随着物体的长度而呈现2次方增长关系。进一步,支撑物体的应力强度 $S$ 通常也正比于横截面面积,因此 $S \propto A \propto L^2$;而物体重量 $W \propto V \propto L^3$。
伽利略根据这一几何关系指出:在放大过程中,物体体积(重量)增长速度快于面积(支撑力),这意味着随着体型增大,每单位体重的应力强度,即 $S/V$ 会降低,这一结论具有许多现实的意义,例如,大型生物体必须演化出更加粗壮的大腿,才能够支撑它们庞大的体重。正因如此,老鼠的腿细长而灵活,而大象的腿却像柱子一般粗壮。伽利略甚至打趣道:“一只小狗能背两三只与它体型相当的小狗,但一匹马却驮不起一匹与自身一样大小的马”。另外,我们在地球表面很难观察到比长颈鹿或大象更大型的动物,海洋里反而存在着体积更大的动物,如鲸,这是因为海水的浮力可以对抗鲸类巨大的体重。这些直观的自然现象,都是规模缩放规律的推论。
同样的,强度与重量的缩放规模也可以用来指导我们进行工程设计,例如:桥梁与高塔要想建得更高就必须加粗支撑柱。
1.2 异速生长
在伽利略根据几何和力学规律,发现了生物体身上的一系列规模法则之后,人们进一步针对更广泛的生物学量发现了与生物体尺寸(体重或身长)的规模法则(幂律关系),并将这些规律命名为异速生长标度律(Allometric Scaling Law),或简称异速生长(Allometry)。
异速生长(Allometry)是关于身体大小与形状、解剖学、生理学以及人类行为间关系的研究,于1892年被 Otto Snell,1917年被 D'Arcy Thompson,和1932年被 Julian Sorell Huxley 首先阐述。异速生长是个著名的研究论题,尤其在统计形状分析及活机体不同部分生长率研究的生物学上。应用之一就是在各种昆虫种类研究上,即整个身体中的某个小部位的变化,能够导致四肢附件如腿、触角等呈现巨大的不成比例的变化。
1.3 量纲分析
量纲分析(dimensional analysis)是一种只利用物理量的“量纲/单位”关系来推断公式结构、做数量级估算、检验推导是否可能出错的方法。核心思想:任何物理定律在单位变换下都应保持形式一致,因此等式两边的量纲必须相同。
量纲分析的历史大致经历了从“量纲一致性直觉”到“系统方法”的演进:17世纪经典力学兴起后,人们逐渐形成方程两边必须同类量的观念;19世纪傅里叶在热学中明确强调用量纲一致性检验推导,随后麦克斯韦等推动以基本单位幂次表示物理量、瑞利常用幂律假设做尺度推断;1914年Buckingham提出Pi定理,把量纲分析系统化为用无量纲群刻画物理规律的方法;20世纪在流体力学、传热与工程缩比实验中随着雷诺数、弗劳德数等无量纲数的广泛应用而成熟,并在现代与无量纲化和规模分析结合,用于建模、相似理论与数量级估算。
1.3.1 寻找无量纲量
根据量纲分析中Buckingham的Pi定理的基本思想,我们可以用量纲约束来构造无量纲量(dimensionless numbers)并把原问题降维。具体的,若有 $n$ 个变量、涉及 $k$ 个独立基本量纲,则可构造 $n - k$ 个独立无量纲量 $\Pi_i$,使得它们满足如下的约束方程:
$$
F(\Pi_1,\dots,\Pi_{n-k}) = 0.
$$
其中 $F$ 是对这 $n - k$ 个无量纲量的约束。无量纲量 $\Pi_i$(dimensionless numbers)是由若干物理量组合成的纯数,它不依赖单位选择,能揭示不同系统在本质上的相似性。
- 例如,圆周率 $\pi = C/D$ 就是最简单的无量纲量的例子(这里 $C$ 是周长,$D$ 是圆的直径)。
- 工程与物理中更典型的无量纲量是弗劳德数(Froude number):
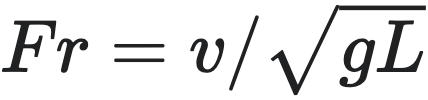
这里 $v$ 为船体运动的特征速度,$g$ 为重力加速度,$L$ 为船体的线性尺度。这个无量纲量比较了惯性力与重力的相对大小,决定了船只、波浪等运动的相似性。
在数学建模中,这种无量纲量的发现往往会对复杂问题的求解提供全新的思路,因为这些无量纲量的寻找可能揭示不同系统在本质上的相似性。系统性的寻找无量纲量的方法称为量纲分析。
1.3.2 规模不变量
规模不变量(scale invariants)或称标度不变量、尺度不变量,是指在“缩放变换”(把长度、时间、速度等按比例放大/缩小)下保持不变的量。因为缩放会改变有量纲量的数值,因此一个量若要保持在缩放下不变,就必须是无量纲量。但是,反过来无量纲量不一定是规模不变量。
根据公式(1),当幂指数 $\alpha = 0$ 的时候,$Y$ 就是一个与规模 $X$ 无关的规模不变量。由此可见,规模法则(1)式是蕴含了规模不变量的。著名的规模不变量包括流体力学中的雷诺数,再如代谢生态学中,哺乳动物一生的心跳次数也是不随生物体体重规模而变的量。
1.4 规模分析方法
规模法则可以说起源于早期的规模分析方法。所谓的规模分析是一种用“数量级/尺度”来近似分析物理问题的方法:不求精确解,而是通过估计各项的大小,找出主导平衡(dominant balance),从而得到典型尺度、幂律关系、无量纲参数的控制作用,以及在不同极限下哪些效应可忽略。
规模分析的核心思路包括:
- 选择特征尺度:即给变量选择有代表性的尺度,包括长度 $L$、速度 $U$ 等;
- 做数量级估算,例如把导数项用尺度来替代,如 $\partial/\partial x \sim 1/L$, $\partial/\partial t \sim 1/T$ 等,这里符号 $\sim$ 代表的是前后两项具有相同的数量级,或“大致相当于”的意思;
- 比较并确定主导项:即比较哪一项最大,属于哪一个量级;
- 最后,得出结论,包括推出幂律关系(如确定 $X \sim t^{1/2}$)。
一个具体的例子是,我们可以在不接方程的条件下,仅通过规模分析就能确定液体边界层厚度的幂律关系。
1.4.1 量纲分析与规模分析
量纲分析与规模分析(Scaling Analysis)是“相关但层级不同”的两类分析方法。量纲分析方法通过把问题构造为无量纲群,从而能够告诉我们“最少需要哪些无量纲量来描述问题”,但通常不能给出这些变量之间的具体函数关系。
规模分析的作用则是在给定方程/机制后,通过数量级估算出哪些项是主导,它们如何随尺度而变化,从而得到幂律关系(即规模法则)、相似解的指数、边界层的厚度等近似规律。
因此,通常在面临具体问题的时候,我们先根据量纲分析把问题无量纲化,然后再利用规模分析方法找到各个变量的幂律关系。
2. 规模法则基本介绍
接下来,本词条首先介绍规模法则的一些基本概念,其次,分别针对生命系统、城市和企业这三类典型的复杂系统,介绍各自重要的规模法则。由于规模法则普遍存在,所以即使每一个具体的复杂系统中也存在着大量的规模法则,逐一介绍显得千篇一律,因此根据韦斯特的规模理论,本词条重点关注每一个系统中与新陈代谢有关的宏观变量的规模法则,这类规模法则对于理解复杂系统的生长、代谢、死亡等重要功能起到了至关重要的作用。
2.1 基本概念
2.1.1 非线性幂律关系
从伽利略时代起,人们就发现自然中的规模法则常常遵循幂律关系(power law)而非是线性(Linear)比例关系。
幂律关系的一般形式如公式(1)所示。如果我们忽略规模法则的系数,则(1)也可以简写为:
$$
Y \propto X^\alpha
$$
其中,“$\propto$”表示的是“成比例于”。式子中仅包含幂律指数 $\alpha$ 这一唯一的重要变量,它决定了变量之间的非线性关系。若 $\alpha = 1$,则该关系呈线性;若 $\alpha \neq 1$,则为非线性幂律关系,我们显然更关注非线性幂律关系。
自然界充满这种非线性缩放:树木高度的极限、动物的骨骼强度、代谢率等都表现出不同指数的幂律关系,这也是后来的克莱伯定律等更多规模法则的理论前提。
2.1.2 数量级与对数表示
在规模分析的框架下,数量级和对数刻度是两个极为重要的概念。数量级(order of magnitude)指的是一个数值以 10 为底的幂次表示方式,用于描述跨越巨大尺度的变化。例如,$10^1$, $10^2$, $10^3$, … 分别代表十、百、千这样成倍扩展的规模。对数刻度则能将等比数列转换为等差数列,例如对上面的序列取10为底的对数,则得到 $1$, $2$, $3$, …。
里氏(局地)震级 $M_L$ 本质上与地震记录到的最大振幅的常用对数有关;在相同条件与校正下,震级每增加 1,记录振幅约增大10 倍,因此相差2级时振幅约相差100倍。实际观测振幅还会随距离与场地条件变化,报告中也常用矩震级 $M_w$。
2.1.2.1 数量级与对数表示
除此之外,对数表示与规模法则,或更广泛的幂律关系也存在着深刻联系。这是因为,对数表示可以将幂律关系转变为线性关系。
如果对(1)式两边都取10为底的对数,则可以得到:
$$
\log Y = \alpha \log X + \log c \quad \text{(linear)}
$$
如果将 $\log X$ 和 $\log Y$ 看作两个新的变量 $X'$, $Y'$,则上式表达了 $X'$, $Y'$ 二者之间的一个线性关系,且该线性方程的斜率为 $\alpha$,截距为 $\log c$。
从数量级的角度来说,(linear) 式表达的含义是:$Y$ 变量的数量级是 $X$ 变量的 $\alpha$ 倍。
2.1.2.2 实证数据分析方法
这种线性关系很方便我们用线性回归,例如最小二乘法(Ordinary Least Square,简称OLS)或主轴回归法(Major Axis,简称MA)来根据数据求出方程中的斜率 $\alpha$ 和截距 $\log c$。
在实证数据分析中,例如原始数据为所有国家的人口($X$)与GDP($Y$),则我们可以对这两组数据取对数得到线性化的变量 $\log X$ 与 $\log Y$,讲这些对数化后的数据绘制到以 $\log X$ 为横坐标,以 $\log Y$ 为纵坐标的散点图上,通常能够得到一条近似的直线型的带状区域。进一步,我们可以使用最小二乘法(OLS)方法进行线性回归,就可以估计出这两组数据的规模法则系数 $c$ 和幂指数 $\alpha$ 了。最后我们还可以利用决定系数 $R^2$、F统计量等统计量来反映这组数据符合幂律关系的显著性水平。
2.1.3 相对增长关系
如果我们对式 (linear) 两边求差分(即考察 $X$, $Y$ 的变动情况,以及二者之间的关系),并注意到对数函数的求导法则($\Delta \log X \approx \Delta X / X$),则有:
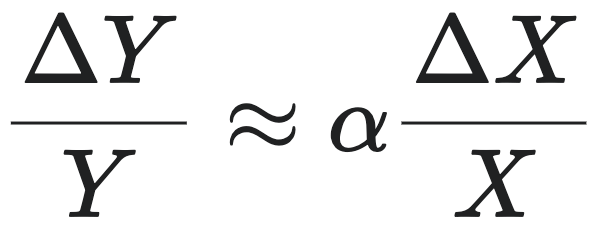 (growth_rate)
(growth_rate)
这里,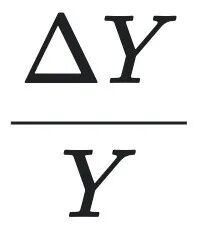 和
和 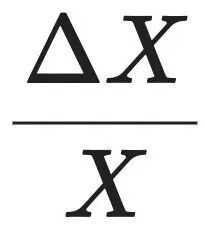 分别是 $Y$, $X$ 的增长率。
分别是 $Y$, $X$ 的增长率。
因此,(growth_rate) 式表达的含义是:$Y$ 的增长率是 $X$ 的 $\alpha$ 倍。
也就是说,规模法则(1)式实际上隐含了两个变量的相对增长速度关系,当 $X$ 增长1倍以后(即 $\Delta X / X = 1$),$Y$ 增长了 $\alpha$ 倍。
例如,地震能量释放是与里氏震级幂指数为1.5的规模法则,这意味着:震级每增加1单位,也就是地震波幅度增加一个数量级,地震释放的能量增加约 $10^{1.5} \approx 31.6$ 倍。
2.1.4 非幂律形式的规模法则
尽管无论在自然界还是经济社会等复杂系统之中,以幂律关系形式呈现的规模法则都普遍存在,但人们也发现了很多非幂律形式的规模法则。这类规模法则可以以非幂律形式的非线性函数为表现形式,常见的有对数关系,如 $Y \propto \log X$,修正的幂律形式:$Y \propto (X + C)^\alpha$,其中 $C$ 为一修正参数,等等。
2.2 生物的规模法则
生物界中广泛存在着各种规模法则,这些规律揭示了生物体大小与形状、结构、功能、行为等变量之间的幂律关系。在很多文献中,规模法则又被称为异速生长(Allometry),或异速生长律,它表明当生物体规模变化时,不同特征并非按相同比例缩放,而是遵循特定的异速生长规律。例如,招潮蟹的钳子大小随身体大小增长时,其增长速度要快于身体本身的增长速度;动物的脑袋大小与身体体重之间也存在类似的异速生长关系。这些规模法则在个体发育(如螃蟹从小到大的生长过程)和种间比较(如不同物种间的特征对比)中都有所体现。
在这些规模法则中,生物体的新陈代谢率与体重的关系尤为重要,也最为著名,被称为克莱伯定律(Kleiber's law),它描述了生物体的新陈代谢率如何与体重按幂律关系缩放,被誉为"生物学的开普勒定律"。围绕克莱伯定律的发现和解释,科学家进行了长期研究。
2.2.1 鲁布纳猜想
19世纪末,德国生理学家马克斯·鲁布纳(Max Rubner)基于热量交换的考量,猜想动物代谢率与其体表面积成正比,这是克莱伯定律研究的起点。根据几何相似原理,体表面积通常与体积的2/3次成正比,而体积又近似与质量成正比。因此,鲁布纳预言代谢率 $F$ 和体重 $W$ 满足如下关系:
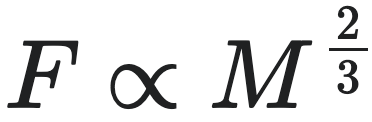
这意味着如果某动物的体重增加一倍,其代谢总需求将增加约 $2^{2/3} \approx 1.59$ 倍,而非成比例翻倍。鲁布纳通过对狗等少数动物的实验测量初步验证了这一关系,并于1902年正式提出,一度成为生理学教条。然而,后来研究指出其样本量小、实验条件不严谨等局限性。
2.2.2 克莱伯定律(Kleiber's Law)
真正的突破来自瑞士科学家马克斯·克莱伯(Max Kleiber)。1932年,克莱伯在分析了大量跨物种的数据后,发表了一篇重要论文。他将各种哺乳动物的体重作为横坐标,并通过它们在单位时间内呼出的二氧化碳,分别测量出它们的新陈代谢率作为纵坐标。结果显示,生物代谢率与体重的幂律关系并非鲁布纳所认为的2/3。而是接近3/4,这一发现标志着克莱伯定律的诞生。
2.2.2.1 代谢、体重的 3/4 幂律
克莱伯定律的核心是3/4幂律,它实质上是对鲁布纳幂律2/3的修正和拓展。在更广泛的物种范围和更精确的数据支持下,克莱伯确定了生物的基础代谢率 $F$ 与体重 $M$ 之间的关系:
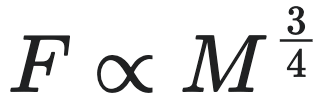 (2)
(2)
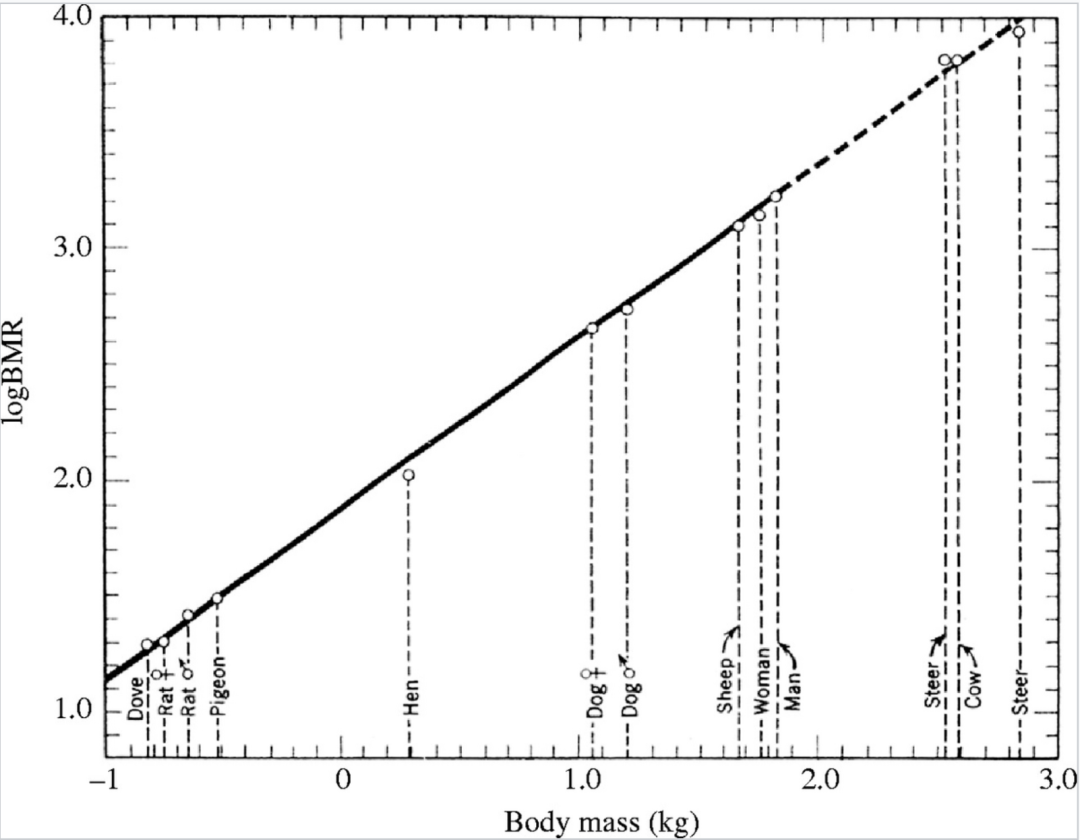
克莱伯定律在哺乳动物上的体现,其中横坐标为不同物种的平均体重(千克)的对数,纵坐标为基础新陈代谢率(瓦特)的对数
这一定律表明,生物体规模每扩大一倍,代谢总量仅增加约 $2^{3/4} \approx 1.68$ 倍。与之相对应,单位质量的代谢速率随着生物体增大而降低。例如,大象每公斤组织消耗的能量远低于老鼠每公斤组织的能量消耗。这解释了为什么大型动物会比小型动物更“节能”。
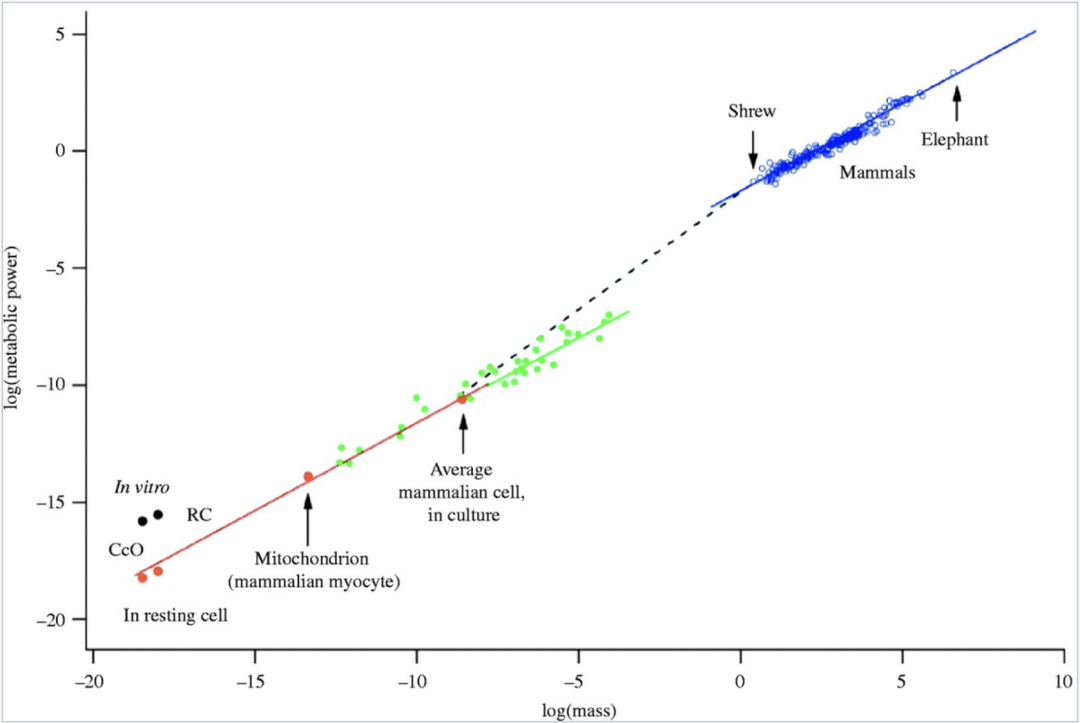
克莱伯定律在27个量级上的扩展,其中横坐标为不同物种的平均体重(千克)的对数,纵坐标为基础新陈代谢率(瓦特)的对数
West等人在2002年的研究对克莱伯3/4幂律进行了扩展,涵盖的量级范围超过了 27 个数量级,从个体(蓝色圆圈)到未偶联的哺乳动物细胞、线粒体和呼吸复合体中的末端氧化酶分子(细胞色素 c 氧化酶,CcO)(红色圆圈)。图中还显示了单细胞生物的数据(绿色圆圈)。在最小的哺乳动物(鼩鼱)以下的区域,根据预测,新陈代谢率与体重的关系将线性外推至体外的单个细胞,如虚线所示。在细胞和细胞内部的水平上,3/4幂律再次出现(如红色直线所示)。
克莱伯定律的发现最初让生物学家们困惑不已,因为它偏离了简单的几何比例。然而,现代的 WBE模型(West-Brown-Enquist 模型)等研究认为,生物体内如血管系统、呼吸道等分形网络结构经过优化,以实现能量传输效率的最大化,从而产生了3/4的幂指数,而非欧氏几何的2/3。
2.3 城市的规模法则
在城市科学和城市规划中,同样存在着引人注目的规模法则。这些规模法则分为了三大类:与社会互动相关的超线性规模法则(Super-linear scaling law)、与个人需求相关的线性规模法则(Linear scaling law),和与基础设施相关的亚线性规模法则(Sub-linear scaling law)。城市的规模一般用人口数 $N$ 来衡量。
2.3.1 与社会互动相关的超线性规模法则
首先,与生物不同的是,城市中的许多社会经济指标随规模呈现“超线性”增长,即幂指数大于 1 。这意味着大城市不仅绝对产出更多财富和创新成果,而且相对而言更高效,即大城市的人均产出更高。除此之外,城市也存在着大量的负面因素,例如犯罪、疾病传播、环境污染等,研究表明,这些负面因素也大多与规模呈现超线性规模法则。无论正向与负向,这类超线性规模法则的起源被认为都可以归结为人与人之间的互动(interaction)的。互动既可以创造财富和科技创新,也同样会带来犯罪和疾病传播。
2.3.1.1 GDP
城市的GDP与人口规模存在着如下的规模法则:
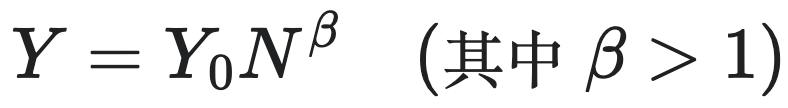 (3)
(3)
其中,$Y$ 代表城市的GDP水平,$N$ 代表城市的人口规模,$\beta$ 为规模法则的幂指数,$Y_0$ 为规模法则的系数,含义为单人城市的产出GDP(即城市只剩下一个人时候的产出水平)。在中国和美国的城市中,GDP 与人口数 $N$ 的幂指数 $\beta$ 约为 1.15。这一关系意味着,当城市人口增加一倍,GDP 增长约 $2^{1.15} \approx 2.22$ 倍,人均 GDP 也会随之提升。这反映了城市中的网络效应和聚集效应——人口规模增长带来更频繁的人际交互和知识溢出,使得整体产出以超过线性的速度提高。
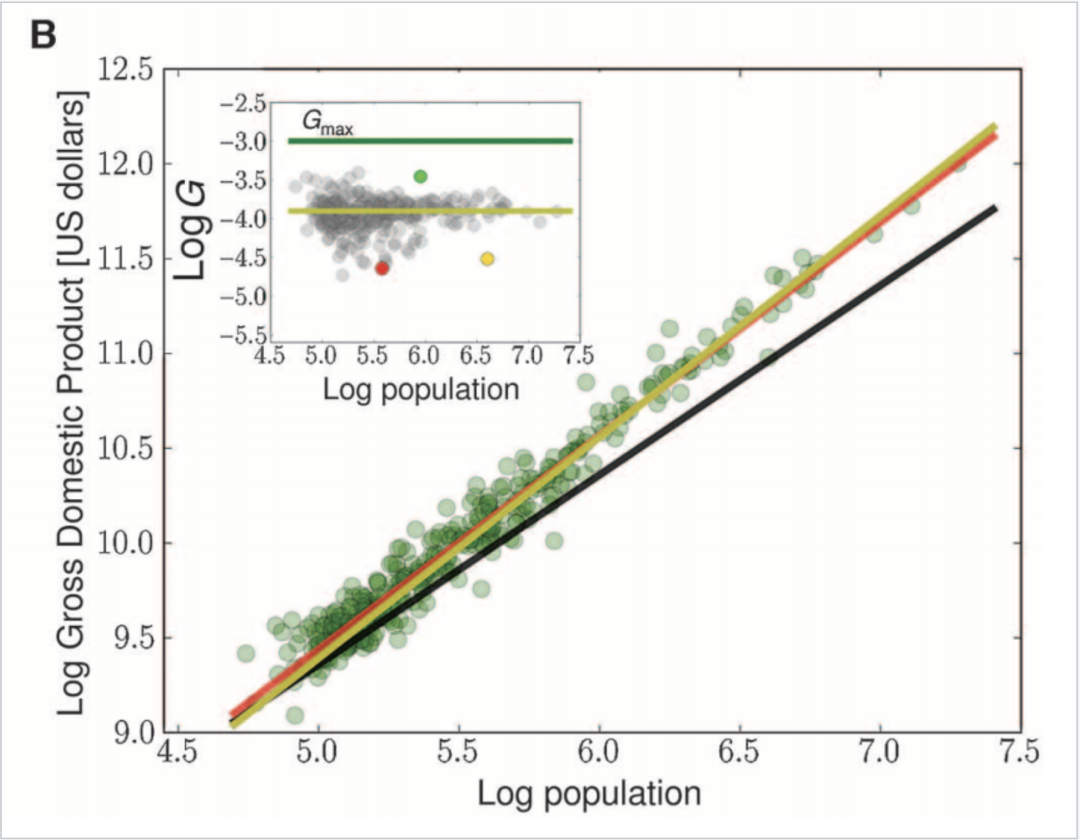
图中数据显示的是2006年363个美国大都市统计区(MSAs)的大都市区的总人口和国内生产总值(Gross metropolitan product)数据,这些数据来源于美国经济分析局(U.S. Bureau of Economic Analysis)。
下表给出了更多国家城市的GDP与人口规模法则的幂指数:
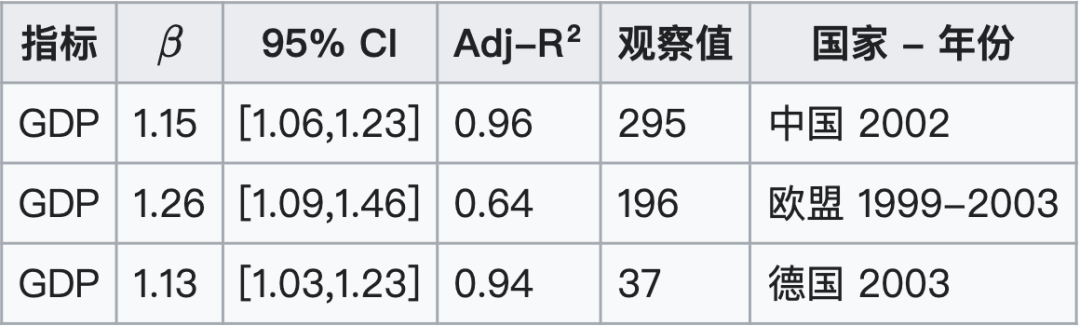
CI,置信区间;Adj-R²,调整R²;GDP,国内生产总值。
Bettencourt等人的研究发现,GDP(国内生产总值) 是超线性增长的,其规模指数 $\beta$ 在 1.06 到 1.26 之间。具体数据显示:
- 中国:2002 年的 GDP 指数 $\beta = 1.15$。
- 欧盟:1999–2003 年的 GDP 指数 $\beta = 1.26$。
- 德国:2003 年的 GDP 指数 $\beta = 1.13$。
2.3.1.2 科技创新
除了 GDP 之外,城市的创新指标也会呈现超线性规模法则。
Bettencourt等人在2007年的研究指出,城市人口规模($N$)与发明活动(以专利数量 $Y$ 衡量)之间的关系,发现两者同样遵循超线性幂律关系,幂律指数约为 1.27,同样大于 1。这个超线性关系表明,随着城市人口规模的增加,人均发明产出也随之提高,体现了发明活动的规模报酬递增效应。
- 超线性 ($\beta > 1$):这类指标反映了城市独特的社会特征,表明知识溢出推动了增长。随着城市规模的扩大,人均产出增加。
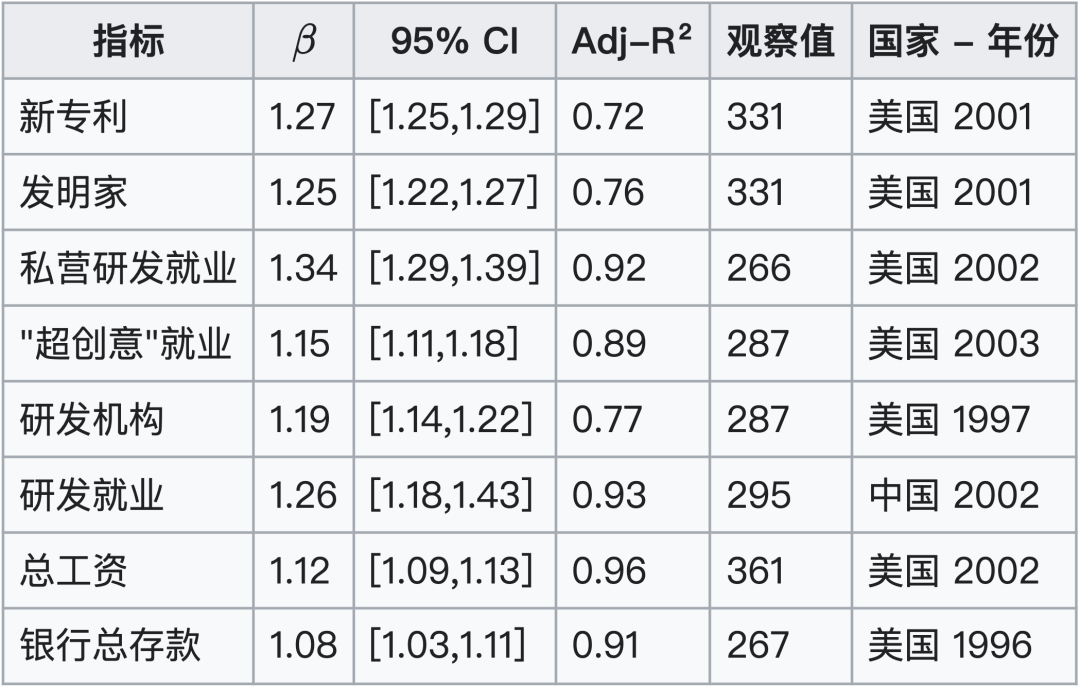
- 创新和财富创造:新专利 ($\beta = 1.27$)、发明家数量 ($\beta = 1.25$)、私营研发就业 ($\beta = 1.34$)、“超创意”就业 ($\beta = 1.15$)、研发机构 ($\beta = 1.19$) 和研发就业 ($\beta = 1.26$) 等指标均呈超线性增长。
- 社会财富:总工资 ($\beta = 1.12$) 和银行总存款 ($\beta = 1.08$) 也呈超线性增长。
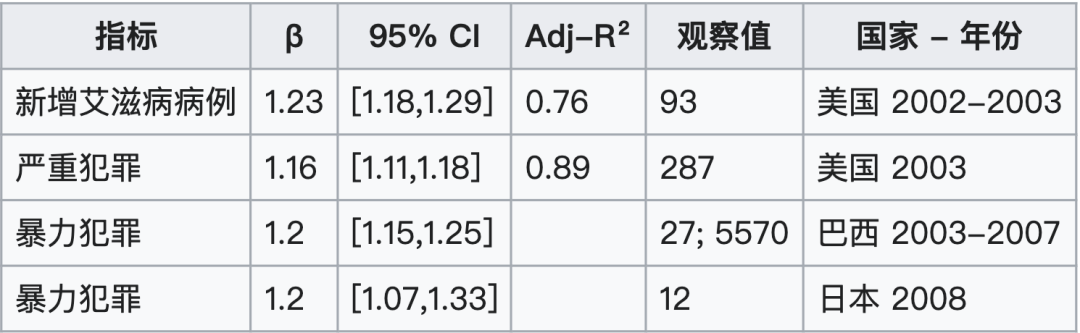
- 负面社会影响:新增艾滋病病例 ($\beta = 1.23$) 和严重犯罪 ($\beta = 1.16$) 等指标同样呈超线性增长,表明这些负面影响随着城市规模的扩大而加剧。
与科技创新、财富创造有关的正向超线性规模法则幂指数列表:
2.3.1.3 负面指标:社会熵
另外,城市就是一个大熔炉,人与人之间的互动除了产生财富和科技创新之外,也会带来负面影响,在《规模》一书中,作者将其所有这些指标统称为社会熵。
城市规模扩大的另一面是负面效应也在放大:
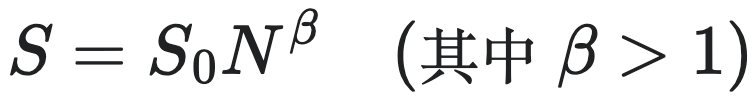 (6)
(6)
这里的 $S$ 即代表社会熵,它可以是犯罪率、传染病新增病例、污染等,它们同样与城市人口之间存在超线性关系。
这揭示了城市作为复杂巨系统的内在矛盾:一方面,人口集聚带来超线性的繁荣;另一方面,也滋生了超线性的混乱。
2.3.1.4 社会连接度
Bettencourt等人认为,之所以城市会存在上述超线性规模法则,包括正面和负面,本质原因是源于人与人之间的互动。为了佐证这一观点,他们专门对社会连接作为社会互动的代理量,进行了实证性的验证。
Andris和Bettencourt于2014年采用了规模法则来描述城市连接度与其人口规模之间的关系。这个关系可以用一个幂律函数来表示:
$$
C = C_0 N^b \quad \text{(5)}
$$
其中:
- $C$ 代表城市的连接度(connectivity),在这项研究中具体指一个地区的总电话呼叫量(包括呼出和呼入)。
- $N$ 代表该地区的人口规模(population size)。
- $C_0$ 是一个归一化常数。
- $b$ 是规模指数或幂指数(scaling exponent),它衡量了人均社会连接度随城市人口规模变化的程度。
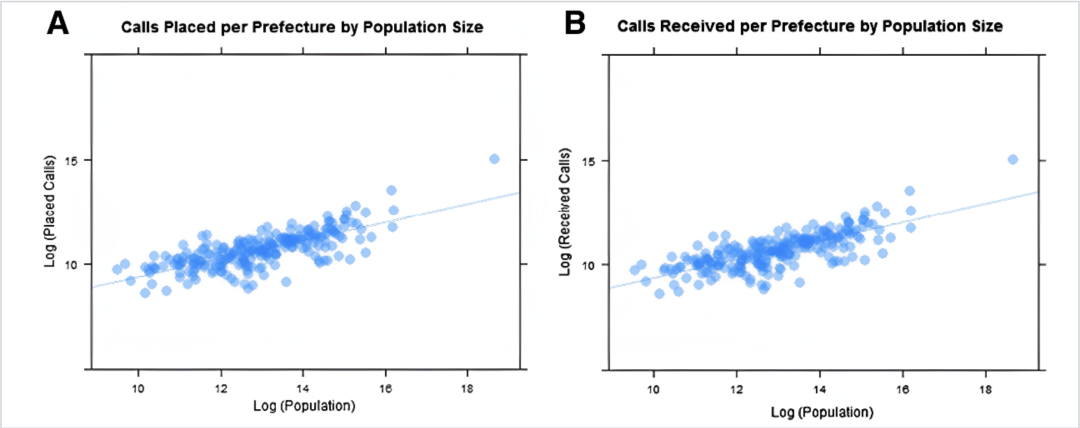
城市人口与电话通讯量(作为社会连接的代理变量)之间的幂律关系。图A显示了各行政区呼出电话量与人口规模的关系 (Calls Placed per Prefecture by Population Size) ,图B显示了各行政区呼入电话量与人口规模的关系 (Calls Received per Prefecture by Population Size) 。
图中的每一个蓝点代表科特迪瓦的一个行政区。这些数据点在人口的对数-呼出/呼入电话总量的对数坐标系下呈现出明显的线性上升趋势,证明了呼出/呼入电话量与人口规模之间存在幂律关系。
幂指数 $b$ 的具体数值:
- 总体连接度指数:研究发现,$b = 1.26$(95%置信区间为 [1.19, 1.34]),属于“超线性”(super-linear)增长。换言之,大城市里的居民平均比小城镇的居民拥有更多的社会互动(以电话通信衡量),城市的社会经济过程会随着城市规模的扩大而加速。
- 内部通话连接度指数:只分析城市内部的通话时,这个指数变得更高,$b = 1.49$(95%置信区间为 [1.39, 1.58])。这表明,随着科特迪瓦的城市不断发展壮大,其内部通话在总通话量中所占的比例会越来越高。
2.3.2 与个人需求相关的线性规模法则
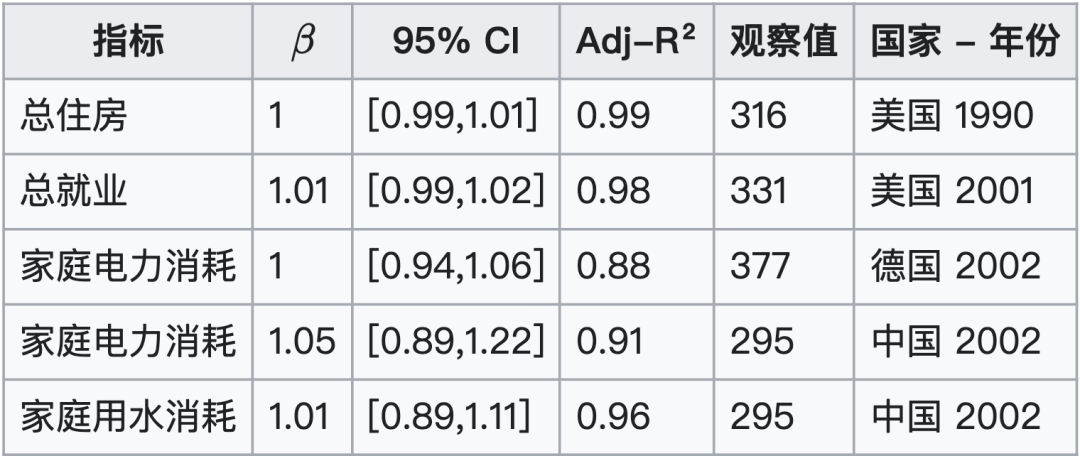
- 线性 ($\beta \approx 1$):这类指标通常与满足个人需求相关,其增长率与人口增长率成正比,即人均指标保持不变。相应的规模法则包括:
- 个人需求:例如住房总量 ($\beta = 1.00$) 和总就业量 ($\beta = 1.01$)。
- 家庭消费:德国家庭用电量 ($\beta = 1.00$)、中国家庭用电量 ($\beta = 1.05$) 和中国家庭用水量 ($\beta = 1.01$) 也大致呈线性增长。
2.3.3 与基础设施相关的亚线性规模法则
- 亚线性 ($\beta < 1$):这类指标代表基础设施,其特点是随着城市规模的扩大,效率会提高,即人均需求会减少。相应的规模法则包括:
- 基础设施:加油站 ($\beta = 0.77$)、汽油销量 ($\beta = 0.79$)、电缆长度 ($\beta = 0.87$) 和道路面积 ($\beta = 0.83$) 等指标均呈亚线性增长。这表明,较大的城市在基础设施方面实现了规模经济。
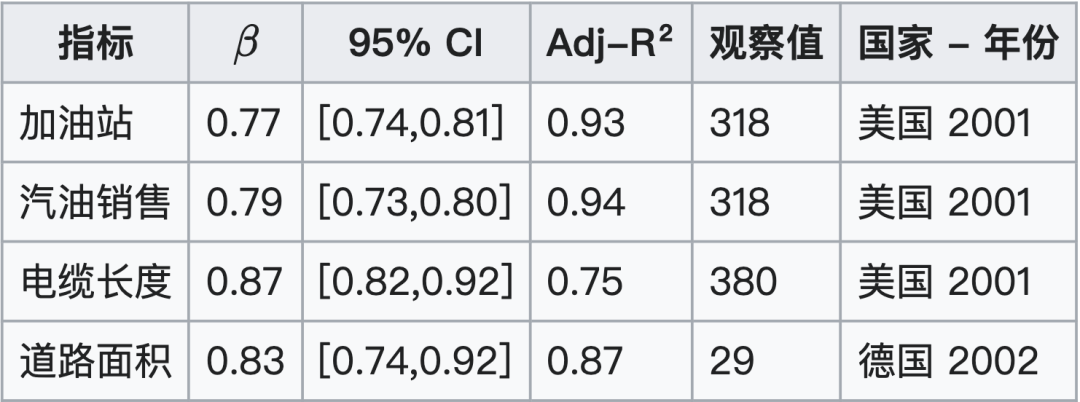
2.3.4 城市规模法则总体概括
总结概括上述发现,可以概括出下表:
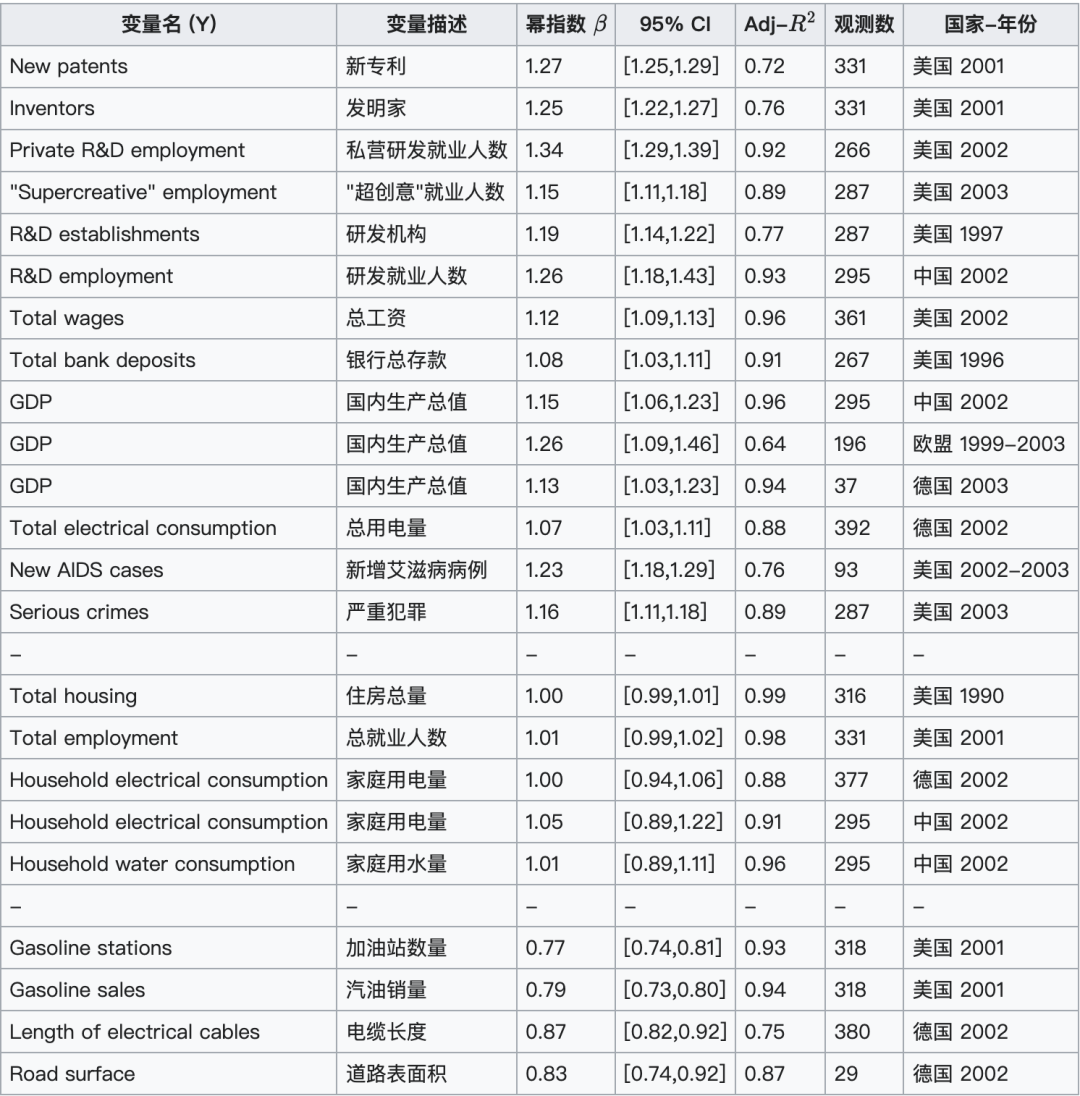
2.3.5 用离差评估城市
城市规模法则不仅揭示了城市普适的缩放生长规律,而且还能够用于评估个体城市的发展水平。Bettencourt等人发表于2010年的研究通过分析城市规模与各项指标(如经济、创新、犯罪等)之间的非线性关系,提出了“离差指标”的方法。该方法的核心在于区分因城市规模而产生的普遍性效应与特定城市独有的局部动态。传统的人均指标往往将这两者混为一谈,而“离差评估”则通过一套城市指标(SAMIs)来衡量一个城市与其规模所预期的平均水平之间的偏差。该方法基于以下两个主要公式:
城市指标的幂律定标法则(Scaling Law)
这是描述城市指标($Y$)与人口规模($N$)之间平均关系的基础公式:
$$
Y(t) = Y_0 N(t)^\beta \quad \text{(7)}
$$
其中:
- $Y(t)$ 是城市指标在时间 $t$ 的值。
- $N(t)$ 是时间 $t$ 的人口规模。
- $Y_0$ 是一个归一化常数。
- $\beta$ 是定标指数。当 $\beta \approx 1.15$ 时,表示该指标具有超线性增长效应,即人口每增加一倍,该指标的人均值将系统性地增加约15%。
尺度调整后的大都市区指标(SAMIs)
该指标用于量化每个特定城市相对于其规模所预期的平均水平的偏差(离差)。
![log[ Y_i / Y(N_i) ] = ζ_i](https://static1.yunpan.plus/attachment/ae59de449ac50216.webp) (8)
(8)
其中:
- $Y_i$ 是某个特定城市的指标观察值。
- $Y(N_i)$ 是根据公式(7)预测的该城市规模下的平均值。
- $\zeta_i$ 是 SAMI 值,它是一个无量纲的指标,与城市规模无关,反映了该城市独有的成功或失败。
2.4 企业的规模法则
企业作为经济系统的基本单元,同样展现出多种规模法则。为了理解这些规律,我们可以从不同的角度来衡量和分析公司的规模,其中最常见的两种视角分别是将其视为现金流系统和人员组织系统,前者以总资产为企业规模的衡量标准,后者则以员工数为企业规模的衡量标准。
2.4.1 作为现金流系统:基于总资产的规模法则
将一家公司的总资产(Total Assets)视为其“体重”,各类财务流(如收入、成本、利润、债务等)视为“类新陈代谢”指标,则可以发现它们之间普遍存在显著的幂律关系。基于这一类比,张江等学者的研究分析了全球数万家上市公司的财务数据,考察各主要财务变量相对于总资产的标度行为,发现所有考察的财务指标与总资产之间均存在显著的幂律关系:
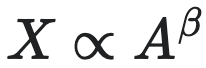
这里,$X$ 是某种财务指标,例如收入、成本、利润等,$A$ 为企业的总资产规模,这些变量都可以用美元或人民币来衡量。
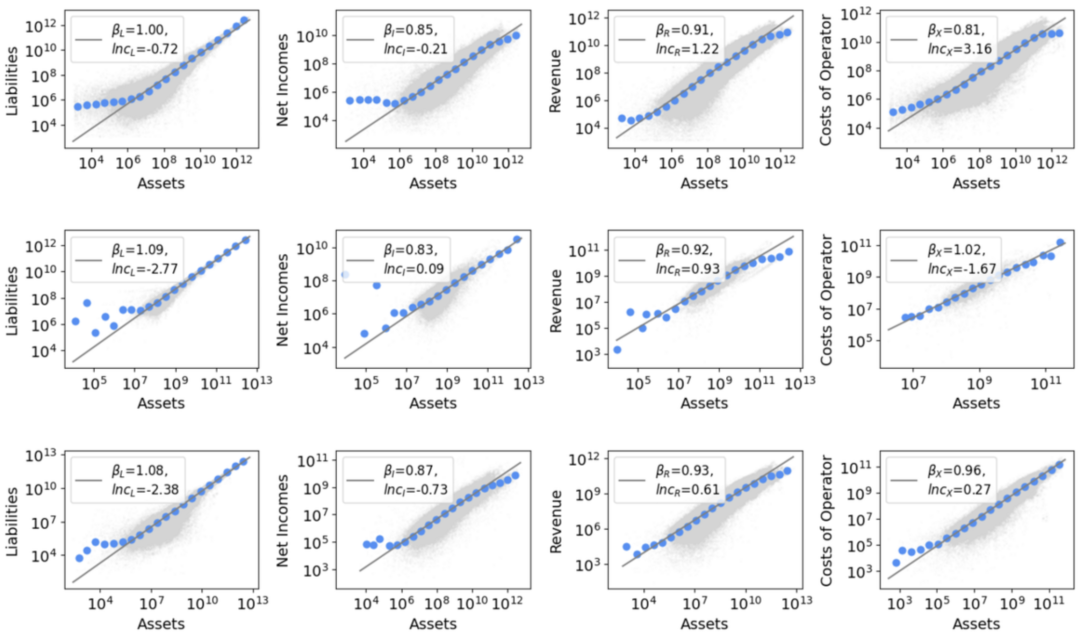
美中欧公司财务指标与总资产的亚线性规模法则
下面,重点看几种规模法则:
收入与成本
美中欧公司的总收入(Revenue, R)和总成本(Cost of Operator, C)都与总资产(Total Assets, A)普遍呈现亚线性关系,即幂指数 $\beta$ 略小于 1(中国的 Cost of Operator除外)。
- $R \propto A^\beta$
- 美国:$\beta = 0.91$
- 中国:$\beta = 0.92$
- 欧洲:$\beta = 0.93$
- $C \propto A^\beta$
- 美国:$\beta = 0.81$
- 中国:$\beta = 1.02$
- 欧洲:$\beta = 0.96$
收入和成本的亚线性关系意味着,企业规模越大,平均每单位资产产生的收入或成本就越低。这体现了企业经营中的规模报酬递减现象。随着资产规模的扩大,企业可能面临市场饱和、管理效率下降等问题,导致新增资产带来的边际收益减少。
利润
净利润(Net Income, I)作为收入扣除成本后的剩余(只保留正数的部分),与企业规模之间也遵循亚线性规模定律,而且其幂指数往往比收入更低。而且不同市场的利润幂指数相近,在0.85左右。
- $I \propto A^\beta$
- 美国:$\beta = 0.85$
- 中国:$\beta = 0.83$
- 欧洲:$\beta = 0.87$
该幂律关系表明,大公司的利润增长速度慢于资产的增长。也就是说,企业规模越大,在保持利润率方面反而越困难,这与生物体越庞大单位质量所消耗的能量越少类似,因此张江等人将这一发现称为企业中的广义克莱伯定律。
债务
公司的总债务(Liability, L)与总资产之间的幂律关系,则反映了不同市场环境下资本分配的差异。
- $L \propto A^\beta$
- 美国:$\beta = 1.00$
- 中国:$\beta = 1.09$
- 欧洲:$\beta = 1.08$
在美国市场中,总债务随总资产近似线性增长,表明大、小企业平均负债率相差不大。中国、欧洲企业的债务规模法则呈现超线性特征,这说明公司在变大时,其负债增长速度快于资产本身的增长。这体现了“强者愈强” 的资本倾斜现象,大型企业更容易获得贷款,但同时也潜藏着更高的财务风险。
2.4.2 作为人员的组织系统:基于员工数的规模法则
如果将企业看作是一个由人员构成的系统,则我们也可以用企业的雇员总数作为企业规模的衡量。因此,此时的规模法则表现为各项变量与员工数($E$)与总雇员数规模之间的关系可以用这个公式来描述:
$$
Y = c E^\gamma
$$
其中:
- $Y$ 代表了各个财务指标变量,如总销售额、总资产、研发支出等。
- $E$ 代表雇员数,是衡量企业规模的基底。
- $\gamma$(伽马) 是幂指数,是衡量变量随企业规模(员工数)增长的速度。
- $c$ 是一个比例系数,命名为:单人产出/销售/成本,代表的是当企业只有一个人的时候,它的产出/销售/成本等。
其中,以上市的3万多家北美企业数据拟合出的各个不同财务指标的规模法则系数与幂指数列表如下:
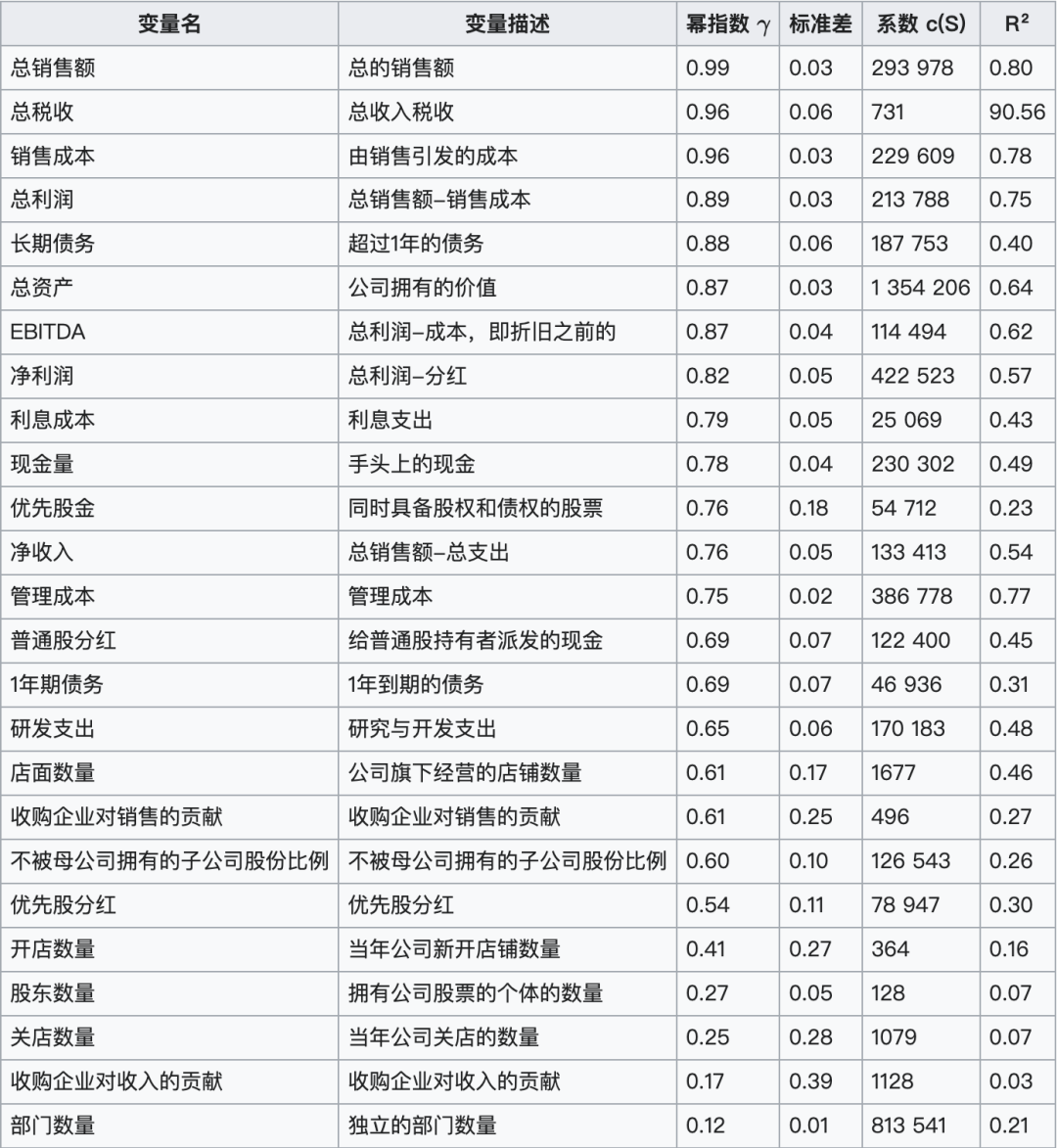
表格中的数据揭示了几个重要的发现:
- 亚线性规模法则:表格中所有的幂指数 $\gamma$ 都小于1,这表明当企业规模(员工数)扩大时,所有的变量都以比员工数增长更慢的速度增长。这与城市和互联网社区的超线性增长($\gamma > 1$)形成鲜明对比,也表明企业并非是一种高效的人类组织。
- 人均产出的下降:由于所有变量的增长速度都比员工数慢,这意味着人均值(如人均销售额、人均资产、人均研发支出)都会随着企业规模的扩大而减小。这表明“大企业病”的存在,即公司规模越大,效率反而可能越低。
- 不同变量的增长速度不同:尽管所有变量的幂指数都小于1,但它们的值各不相同,这表明不同变量随企业规模增长的速度是不同的。
- 增长最快:总销售额($\gamma = 0.99$)和总税收、销售成本($\gamma = 0.96$)等财务收入和成本的增长速度最接近员工数。
- 增长较慢:开店数量($\gamma = 0.41$)、股东数量($\gamma = 0.27$)、关店数量($\gamma = 0.25$)和部门数量($\gamma = 0.12$)等变量的幂指数非常低。
尽管企业规模在扩大,但其产出和各项指标的增长并未跟上员工数量的增长,这体现了企业在效率方面的局限性。
虽然上述表格展示了规模法则的一般规律,但对比中美两国企业的数据可以发现,它们在基于员工数的规模法则上存在显著差异。这种差异不仅体现在幂指数 $\gamma$ 的数值上,更重要的是体现在比例系数 $c$ 的系统性差异上。对于相同的变量(如总销售额、净利润等),两国企业的 $c$ 值往往不同,这反映了不同的发展阶段和效率模式。具体而言,中国企业由于处于更快速的发展阶段,其 $c$ 值在某些产出指标上可能更高,体现了快速增长阶段的市场活力和单位员工的产出潜力;但在管理成本、组织复杂度相关指标上,可能存在不同的结构特征。这种系统性差异反映了多个层面的因素:一是市场发展阶段的不同,中国企业整体处于更快速的发展轨道;二是企业管理模式和资源配置效率的差异;三是宏观经济环境的差异,中国的经济增长速度长期以来快于美国。从预测误差分布的角度看,中美两国企业的生长率分布都呈现右偏特征,表明两国企业都遵循相似的规模法则规律,但在具体的效率参数(尤其是 $c$ 值)上存在系统性差异。这进一步说明,虽然规模法则是普适的,但不同发展阶段和市场环境会塑造出不同的效率基础。
2.4.3 用离差评估企业
与城市的规模法则研究类似,企业的规模法则不仅揭示了市场中所有企业的普遍规律,也可以用个体企业偏离规模法则的程度,评估每个个体企业在各个财务指标上的健康状况。
首先,我们可以通过绘制双对数坐标图来研究某个变量(如总利润)与企业规模(如总销售额)之间的关系。在理想状态下,这些数据点会落在一条直线上,这条直线代表了该市场中所有企业在该指标上的平均水平。
其次,对于双对数坐标下的每一个点(代表一家企业),我们可以计算规模法则的离差(或称离差),即该企业的数据点偏离这条平均直线的垂直距离,这个偏离距离就用于评估企业的表现。
- 离差 > 0:如果企业的点位于平均直线的上方,表明该企业在该指标上的表现高于市场平均水平。
- 离差 = 0:如果企业的点正好位于平均直线上,表明该企业的表现恰好等于市场平均水平。
- 离差 < 0:如果企业的点位于平均直线的下方,表明该企业的表现低于市场平均水平。
作为企业的评估指标,企业的离差相比较传统的比例指标(例如,总利润/总销售额)存在着显著优势。这是因为,传统的比例指标没有考虑企业非线性的规模效应,因此存在着局限性。而规模标度律的离差则更具优势,这体现为:
- 考虑了规模效应:规模法则本身已经考虑了规模效应,因此这条直线代表了行业整体的平均水平。通过计算离差,我们可以将一个企业的表现与该行业的平均水平进行公正的比较。
- 更准确的评估:离差能够更准确地反映企业在该指标上的相对表现。当两个不同规模的企业进行比较时,仅使用比例指标是不够的,因为规模效应可能导致不同规模的企业有不同的比例值。离差则将规模效应纳入了考虑,提供了更合理的比较基础。
- 反映市场动态:对于正向指标(例如利润、销售额等),则离差越大,表明企业在该指标上的表现越突出(高于)市场平均水平。在同类企业中,离差越大,说明该企业越成功地获取了更多利润或收入。反之,对于负向指标(如成本),则离差越负(即成本低于行业平均水平),企业表现越好。
例如,下图的雷达图展示了微软和苹果公司在多个财务指标上的离差。通过比较这两个公司各指标的离差值,我们可以看到,它们的离差在所有指标上都大于0,说明两家公司的正向指标表现都高于市场平均水平,但同时也说明成本等负向指标也显著高于行业平均。同时,离差值越大,对于正向指标,排名越靠前,显示了该企业在市场中的领先地位。
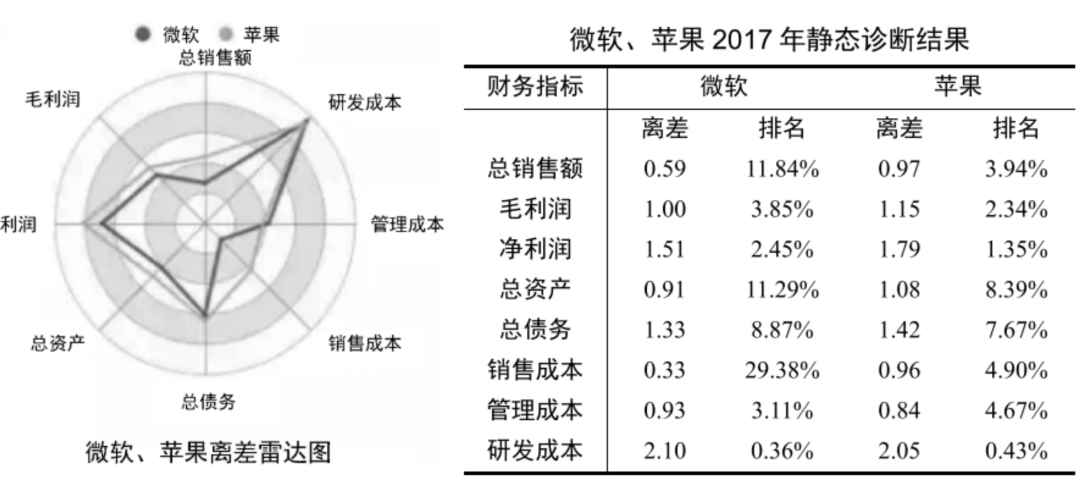
利用规模法则的离差法对苹果与微软两家企业在多个财务指标上的评估比较
3. 规模法则导出的生长方程
之所以人们通过规模法则能够构建统一的理论,是因为在诸多规模法则中,有一类特殊的变量的存在,即“广义的新陈代谢”,这就包括生物体的“新陈代谢率”,城市的“GDP”或更广义的“社会交互”,以及企业中的“净利润”。这类可以代表广义新陈代谢的变量与规模之间的规模法则可以直接推导出复杂系统的一种广义的生长方程。例如,生物体中的“韦斯特方程”。
3.1 生物体的生长方程——韦斯特方程
韦斯特(Geoffrey West)等人在2001年的研究中总结了生物体个体发育的生长轨迹,基于代谢能量在维持现有组织生存和⽣产新⽣物量之间分配的基本原理,推导出⼀个通⽤的描述生物体个体发育生长(ontegenetic growth)的方程,即韦斯特方程。
3.1.1 核心方程
首先,我们可以根据能量守恒原理,推出一个方程用来描述代谢能量在生物体内的分配:
![B = ∑_c [N_c B_c + E_c dN_c/dt]](https://static1.yunpan.plus/attachment/70f149ba2b95a1c8.webp) (9)
(9)
- $B$ 是生物体在 $t$ 时刻的平均基础代谢率,即生物体在单位时间内总的摄入能量。
- $N_c$ 是生物体内的细胞总数。
- $B_c$ 是单个细胞的代谢率。
- $E_c$ 是创造一个新细胞所需的代谢能量。
- $N_c B_c$ 代表维持一个现有细胞所需的能量。
- $E_c dN_c/dt$ 代表用于产生一个新细胞的能量,即用于生长的能量。
- $\sum_c$ 对所有细胞求和。
这个方程的推导基于一个前提:生物体的代谢能量被分配用于维持现有生物体系统的能量(即方程右侧的第一项)和产生新组织,即生长所耗费的能量(方程右侧的第二项)。
3.1.2 结合规模法则的生长方程
上述能量平衡方程可以转化为质量增长的微分方程。因为总质量 $m$ 等于细胞总数 $N_c$ 乘以单个细胞的质量 $m_c$(即 $m = m_c N_c$),所以方程(9)可以重写为:
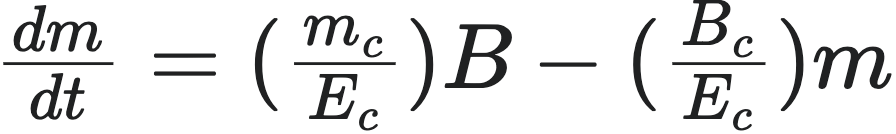 ,这是描述整个生物体质量增长的方程。
,这是描述整个生物体质量增长的方程。
进一步,将这个方程与规模法则联系起来,引入克莱伯定律(Kleiber's Law)的 3/4 幂律关系,即生物体的静息代谢率 $B$ 与其总质量 $m$ 遵循以下关系:
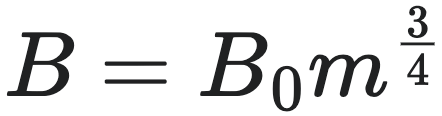 ,其中 $B_0$ 是克莱伯法则的系数。将 上式代入上述质量增长方程,便得到了关键的韦斯特生长方程:
,其中 $B_0$ 是克莱伯法则的系数。将 上式代入上述质量增长方程,便得到了关键的韦斯特生长方程:
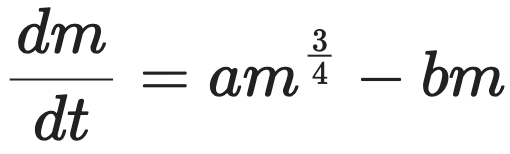 (10)
(10)
这里 $m$ 为生物体的总质量,$a$ 和 $b$ 是常数,其中 $a \equiv B_0 m_c / E_c$,$B_0$ 为克莱伯定律的系数,$m_c$, $E_c$ 分别为单个细胞的平均质量和平均代谢能量,且 $b \equiv B_c / E_c$,其中 $B_c$ 是单个细胞的代谢率,$E_c$ 是创造一个新细胞所需的代谢能量。
针对不同物种,代入(9)式中的参数具体数值,就可以对方程(10)式进行求解,即得到该物种的个体发育生长曲线。下图展示了四个不同物种的求解结果,并与实际的生长数据进行了比对。可以看出,理论预测与实际曲线吻合得非常好。
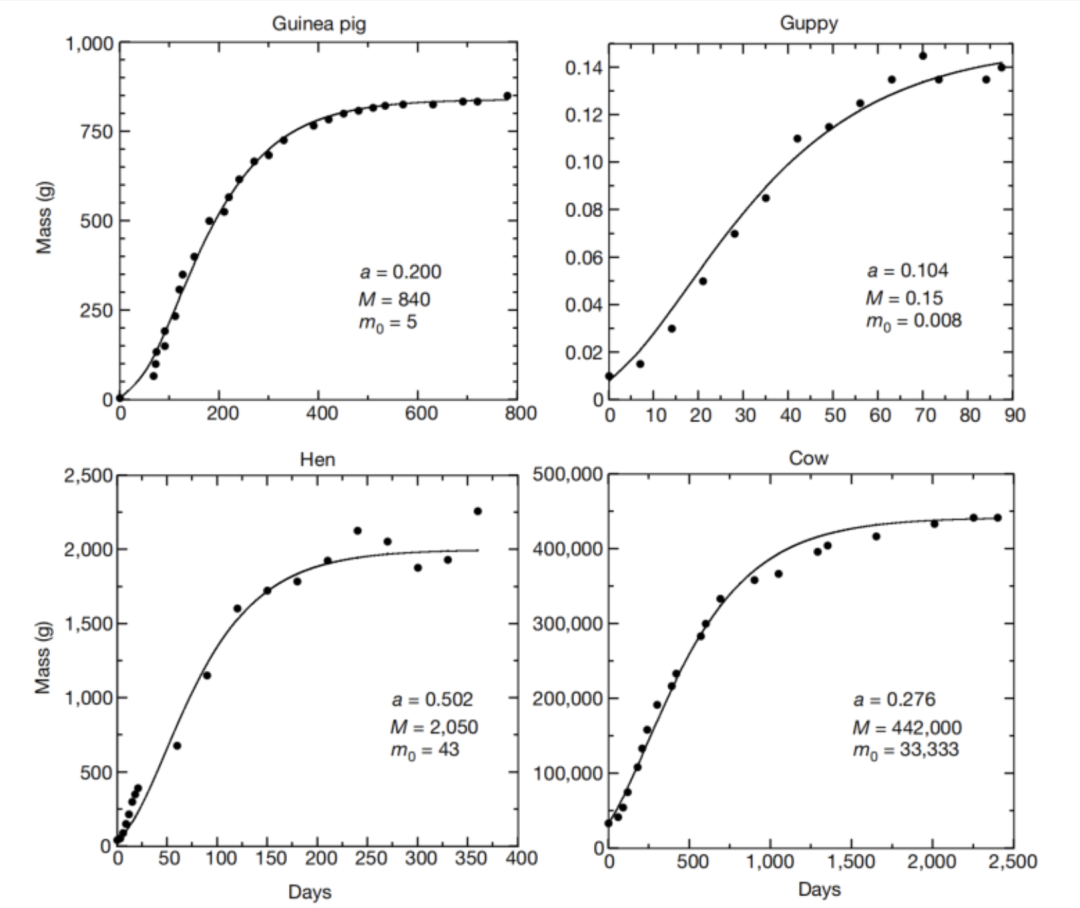
上图是四个典型生物体的生长曲线(散点)的例子,以及模型预测的结果(实线)。其中横坐标为生物体的发育年龄,纵坐标为对应年龄下的体重大小。
3.1.3 解释渐近最大体型 (Determinate Growth)
这个方程解释了为什么生物体具有确定的最大体型(determinate growth),即为什么生物体大多长到一定规模后就停止生长了。
当生物体停止生长时,也就意味着生长率 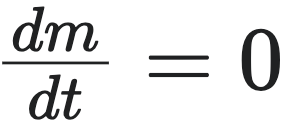 ,此时对应的 $m$ 的解即生物体达到的渐近最大体型 $M$。也就是说,最大体型实际上是韦斯特生长方程(10)式的不动点。从方程中可以看出:
,此时对应的 $m$ 的解即生物体达到的渐近最大体型 $M$。也就是说,最大体型实际上是韦斯特生长方程(10)式的不动点。从方程中可以看出:
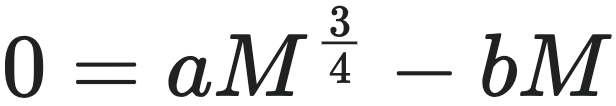 ,从而得到最大体型 $M$ 的表达式:
,从而得到最大体型 $M$ 的表达式:
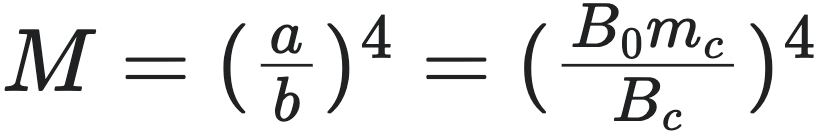 。这个结果表明,物种之间的最大体型差异主要由其细胞代谢率 $B_c$ 的系统性变化决定。
。这个结果表明,物种之间的最大体型差异主要由其细胞代谢率 $B_c$ 的系统性变化决定。
3.1.4 统一的、无参数的生长曲线
由于不同物种对应的方程(10)中的参数会不同,因此导致它们具有不同形状的生长曲线。为了消除这些差异,我们可以通过重新定义变量,从而将生长曲线归一化,以得到一条统一的、无参数的生长曲线。
通过将 $b = a/M^{1/4}$ 代回生长方程(10),可以得到一个更具普遍性的方程形式:
![dm/dt = am^(3/4) [1 - (m/M)^(1/4)]](https://static1.yunpan.plus/attachment/f561430e67dc5a32.webp) 。通过对这个微分方程进行积分,可以得到描述质量 $m$ 随时间 $t$ 变化的经典S形曲线方程:
。通过对这个微分方程进行积分,可以得到描述质量 $m$ 随时间 $t$ 变化的经典S形曲线方程:
![(m/M)^(1/4) = 1 - [1 - (m0/M)^(1/4)] * e^(-at/(4*M^(1/4)))](https://static1.yunpan.plus/attachment/a45515f6627c9420.webp) (11)
(11)
其中,$m_0$ 是出生时的质量。
这个方程可以被重新整理为一个无参数的普适曲线,首先,我们需要定义两个无量纲量:
- 无量纲质量比:
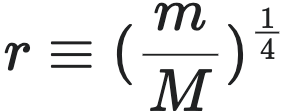
- 无量纲时间:
![τ ≡ at/4M^1/4 - ln[1 - (m0/M)^1/4]](https://static1.yunpan.plus/attachment/8086276f65780805.webp)
将这两个无量纲量带入韦斯特生长方程(10),可以得到所有物种统一的生长方程(Universal Growth Equation):
$$
r = 1 - e^{-\tau}
$$
这表明,尽管物种大小差异巨大,它们的生长过程在能量分配和时间尺度上具有普适的内在规律。通过以无量纲质量比 $r$ 为纵坐标,无量纲时间 $\tau$ 为横坐标,重新将不同物种的生长曲线绘制在一起,可以得到一条普适的生长曲线(Universal Growth Curve):
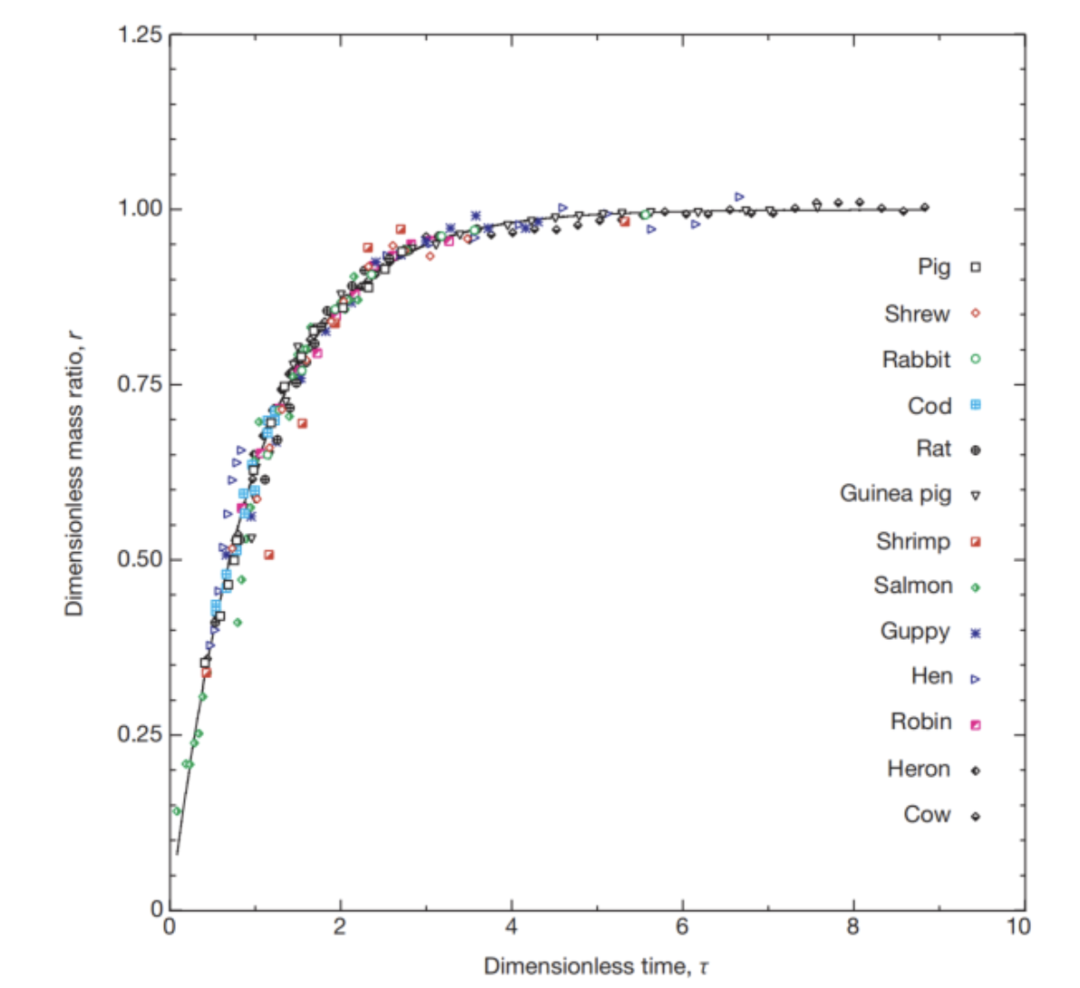
该图展示了通用的生长曲线。它绘制了无量纲质量比 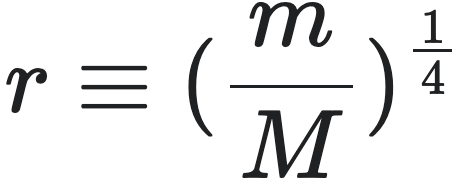 (横坐标) 与无量纲时间变量 $\tau$(纵坐标)的函数关系,从而得到了多个物种的统一生长曲线。其中 $r$ 可以理解为一种用于维持生命和其它活动的代谢总功率。该图涵盖了多种受限生长(determinate)和不受限生长(indeterminate)物种。当以这种方式绘制时,韦斯特生长方程预测所有生物的生长曲线都应该落在同一条没有参数的普适曲线 $r = 1 - e^{-\tau}$ 上(图中用实线表示)。
(横坐标) 与无量纲时间变量 $\tau$(纵坐标)的函数关系,从而得到了多个物种的统一生长曲线。其中 $r$ 可以理解为一种用于维持生命和其它活动的代谢总功率。该图涵盖了多种受限生长(determinate)和不受限生长(indeterminate)物种。当以这种方式绘制时,韦斯特生长方程预测所有生物的生长曲线都应该落在同一条没有参数的普适曲线 $r = 1 - e^{-\tau}$ 上(图中用实线表示)。
3.2 城市生长方程
与生物体的统一生长方程和生长曲线的推导类似,我们也可以从城市的基本规模法则,即(3)式和城市的投入产出预算平衡推导出城市的生长方程。
2007年,Bettencourt等人在文中得出该生长方程。城市的GDP类比于生物的新陈代谢,为城市创造的总价值。这表明规模法则在城市中同样适用,只是生物体随着体重增大会导致新陈代谢以较慢的速度生长,而城市GDP的超线性规模法则会使城市的新陈代谢率随其规模增大而以更快的速度生长。
3.2.1 核心方程
从规模法则推导出的城市生长方程是:
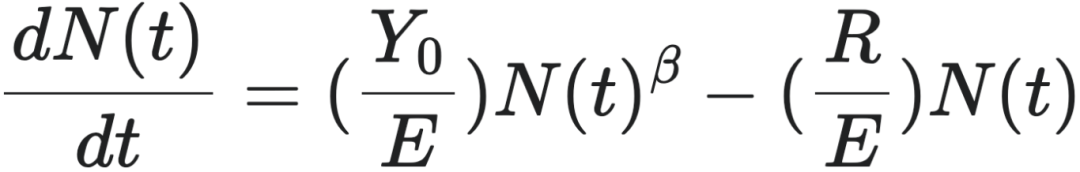 (12)
(12)
- $N(t)$:城市在时间 $t$ 的人口规模;
- $Y(t)$:城市在时间 $t$ 的资源产出(GDP);
- $dN(t)/dt$:人口随时间的变化率,即城市增长率;
- $Y_0$:规模法则(3)式的系数,代表城市的单人产出,即城市只有一个人的时候,资源产出是多少;
- $\beta$:规模法则(3)式的幂律指数(scaling exponent),反映了系统在规模($N$)缩放的时候,资源产出 $Y$ 的相对缩放速度;
- $R$:维持每个个体平均所需的资源量;
- $E$:增加一个新个体所需的平均资源量。
这个方程是如何得到的呢?
Bettencourt等人首先从一个基本的假设开始:城市的增长受到可用资源及其消耗速度的制约,其中资源 $Y$ 被用于两个主要方面:一是维持现有的人口生存,二是促使新的人口增长。
-
资源被分配来维持人口生存和增加新人口。这个关系被表达为:
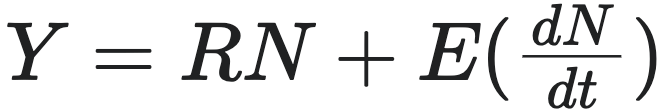
- $RN$ 代表维持现有 $N$ 个个体生存所需的资源总量,其中 $R$ 是维持每个个体所需的资源量。
- $E(dN/dt)$ 代表增加新人口所需的资源总量,其中 $E$ 是增加一个新个体所需的资源量,$dN/dt$ 是人口增长率。
-
接下来,作者将规模法则(Scaling Law)引入这个方程。规模法则描述了城市的资源产出 $Y$ 与其人口规模 $N(t)$ 之间的幂律关系:$Y(t) = Y_0 N(t)^\beta$
-
将规模法则的表达式代入资源分配方程中,得到:$Y_0 N(t)^\beta = RN(t) + E(dN/dt)$
-
最后,对这个方程进行重新整理,解出人口增长率 $dN/dt$,从而得到最终的城市生长方程
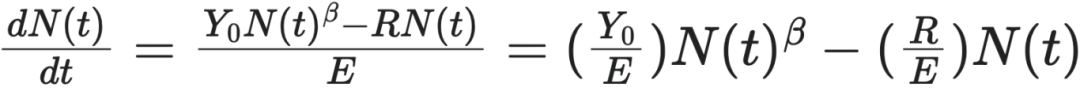 ,即(12)式
,即(12)式
该生长方程的解析解为:
![N(t) = { Y0 / R + [ N^(1-β)(0) - Y0 / R ] · exp [ -R/E (1 - β)t ] }^(1/(1-β))](https://static1.yunpan.plus/attachment/ce9c3382406b6cdf.webp)
- $N(0)$:为第0期的人口规模,即初始人口规模。
这个生长方程的解的缩放指数 $\beta > 1$,因此会导致城市人口的增长是无限制的,并将在一个有限的时间内达到“奇点”(Singularity),即城市规模的增长速度比指数增长还要快。这反映了城市独特的自催化(autocatalytic)性质,即城市规模的扩大能通过创新和社交互动等过程进一步加速自身的增长。
3.2.2 城市与生物的区别
城市生长方程与生物的核心区别在于其内在机制和增长模式:
- 增长极限:生物的生长方程(如West方程)解释了为什么生物体最终会达到一个确定的最大体型(determinate growth)。这是因为生物体的生长方程(10)的右侧的两项分别代表代谢摄入的能量与维持成本。由于代谢能量随体重增加(亚线性)比维持成本(线性)随体重增加得更慢,所以这就会存在着一个平衡点,达到平衡时,增长便会停止。相比之下,城市的超线性规模法则($\beta > 1$)意味着其在理论上没有增长上限,除非面临外部资源约束,否则将持续加速。
- 内在机制:生物的生长由能量在维持现有组织和创造新组织之间的分配决定,其代谢效率随规模增大而降低。城市的增长是社会经济活动的结果,其超线性本质源于人口密度增加所带来的创新、财富创造和信息流动效率的提升。
- 规模法则差异:生物体的关键属性(如代谢率)随体型呈亚线性规模法则,即 $\beta = 3/4$。而城市的创新率、收入和专利数量等关键社会经济指标则随人口呈超线性规模法则,即 $\beta > 1$,这正是城市区别于前两者的根本特征。
3.2.3 超指数增长:繁荣与崩溃
Bettencourt等提出,由超线性规模法则($\beta > 1$)驱动的城市增长,这种增长模式被称为 “繁荣-崩溃”(boom/collapse) 模式。方程(12)的解分为两种情况:
-
当 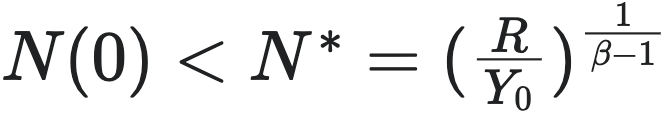 时:
时:
该公式表明,城市的生长存在着一个临界人口规模阈值,即 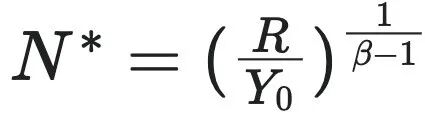 。这个阈值正比于维持每个个体平均所需的资源量 $R$,反比于单人城市产出规模。当初始的人口规模(即 $N(0)$)小于这个阈值时,则系统走向崩溃(collapse),此时的生长曲线呈现如下图所示。这反映了城市人口规模达不到临界要求,而导致的不稳定性和脆弱性。
。这个阈值正比于维持每个个体平均所需的资源量 $R$,反比于单人城市产出规模。当初始的人口规模(即 $N(0)$)小于这个阈值时,则系统走向崩溃(collapse),此时的生长曲线呈现如下图所示。这反映了城市人口规模达不到临界要求,而导致的不稳定性和脆弱性。
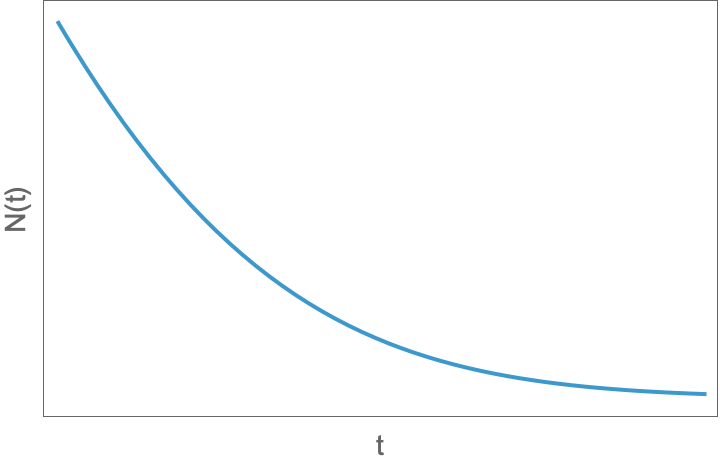
城市生长方程(12)在第一种情况下($N(0) < N^*$)的解曲线。这是一条指数衰退的曲线
-
当 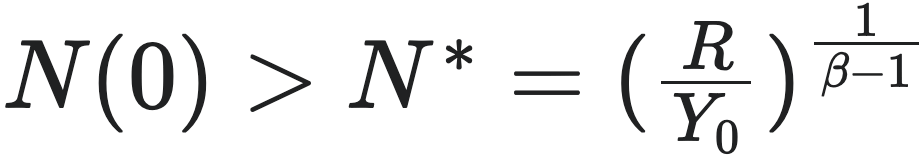 时
时
即当初始人口规模超越阈值时,城市呈现超指数增长,即在有限时间内,人口规模 $N(t)$ 达到无穷大,其生长曲线表现为如下图所示。
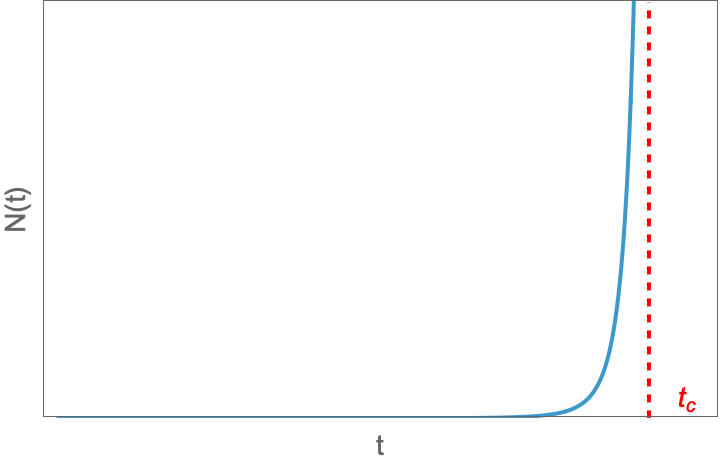
城市生长方程(12)的第二种情况($N(0) > N^*$)的解曲线。这是一条超指数生长曲线,即在有限时间内($t_c$),$N(t) \to \infty$。
其中 $t_c$ 为人口规模达到无穷的时间点,该点也被称为有限时间奇点。
3.2.4 奇点
根据城市生长方程(12),城市的增长过程会在繁荣与崩溃之间循环。在这个动态过程中,存在两种性质不同的奇点:有限时间奇点(finite time singularity)和不可回避的奇点(unavoidable singularity)。
3.2.4.1 有限时间奇点
真实的城市增长,会在繁荣与崩溃二者之间切换。即当初期,满足条件 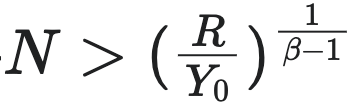 的时候,城市进入超指数(super-exponential)增长曲线,并在一个有限时间 $t_c$ 处发散(即有限时间奇点(finite time singularity))。这个 $t_c$ 被称为“奇点时间”或“崩溃时间”。这个 $t_c$ 的值由以下公式近似得出:
的时候,城市进入超指数(super-exponential)增长曲线,并在一个有限时间 $t_c$ 处发散(即有限时间奇点(finite time singularity))。这个 $t_c$ 被称为“奇点时间”或“崩溃时间”。这个 $t_c$ 的值由以下公式近似得出:
![t_c ≈ [E / ((β - 1)R)] * [1 / N^(β-1)(0)]](https://static1.yunpan.plus/attachment/ba540bc258db59c8.webp)
然而这种超指数的增长不可持续,因为方程将在有限时间内达到奇点,此时人口趋于无穷大。此时,条件 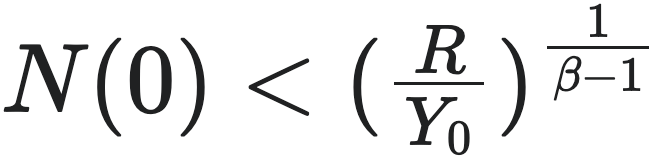 条件可能被触发(例如无限的人口扩张导致每人的平均成本升高),因而城市走向崩溃。为了避免这种情况,城市必然会在此之前就经历“重大质变”,也就是通过创新来“重置”初始条件 $N(0)$ 和参数 $Y_0$, $R$, $E$,以使得
条件可能被触发(例如无限的人口扩张导致每人的平均成本升高),因而城市走向崩溃。为了避免这种情况,城市必然会在此之前就经历“重大质变”,也就是通过创新来“重置”初始条件 $N(0)$ 和参数 $Y_0$, $R$, $E$,以使得 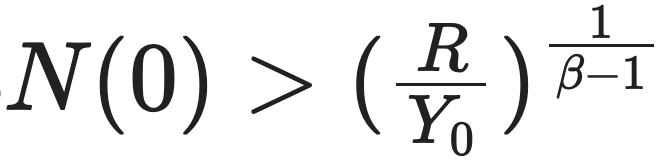 条件得到满足。这种创新活动确保了城市的主导动力仍然处于“财富和知识创造”的超线性增长阶段。历史上,当人类社会发生重大技术的跃迁正可以对应这种情况。这样,为了避免崩溃,城市必须在接近奇点时间 $t_c$ 时引入新的创新周期。每一次新的创新都有效地重置了增长参数,开启了一个新的超线性增长周期。
条件得到满足。这种创新活动确保了城市的主导动力仍然处于“财富和知识创造”的超线性增长阶段。历史上,当人类社会发生重大技术的跃迁正可以对应这种情况。这样,为了避免崩溃,城市必须在接近奇点时间 $t_c$ 时引入新的创新周期。每一次新的创新都有效地重置了增长参数,开启了一个新的超线性增长周期。
重置过程包括两个方面:
- 重置初始条件:调整初始人口规模 $N_0$
- 重置方程系数:这是更重要的环节,需要重置系数:
- $Y_0$:归一化常数,代表城市的单人产出
- $R$:增加一个新个体所需的平均资源量
- $E$:维持每个个体平均所需的资源量
历史上,人类社会发生重大技术跃迁时,正是对应这种重置机制。
3.2.4.2 分阶段超指数增长曲线
当参数重置以后,城市增长便进入了第二轮增长曲线。然而,这一增长曲线也不可持续,在有限时间内仍然会趋近第二个有限时间奇点,于是又会导致 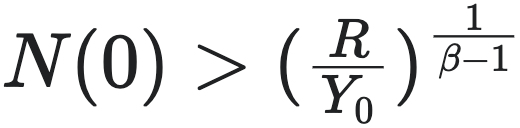 条件遭到破坏,于是城市进入第二轮崩塌模式中,这会导致第二轮的变革将会出现,从而重置初始条件和方程系数,于是进入第三波增长曲线,如此往复下去……。
条件遭到破坏,于是城市进入第二轮崩塌模式中,这会导致第二轮的变革将会出现,从而重置初始条件和方程系数,于是进入第三波增长曲线,如此往复下去……。
当我们汇总上述情况并推演下去,最终可以得到城市的增长曲线如下图:
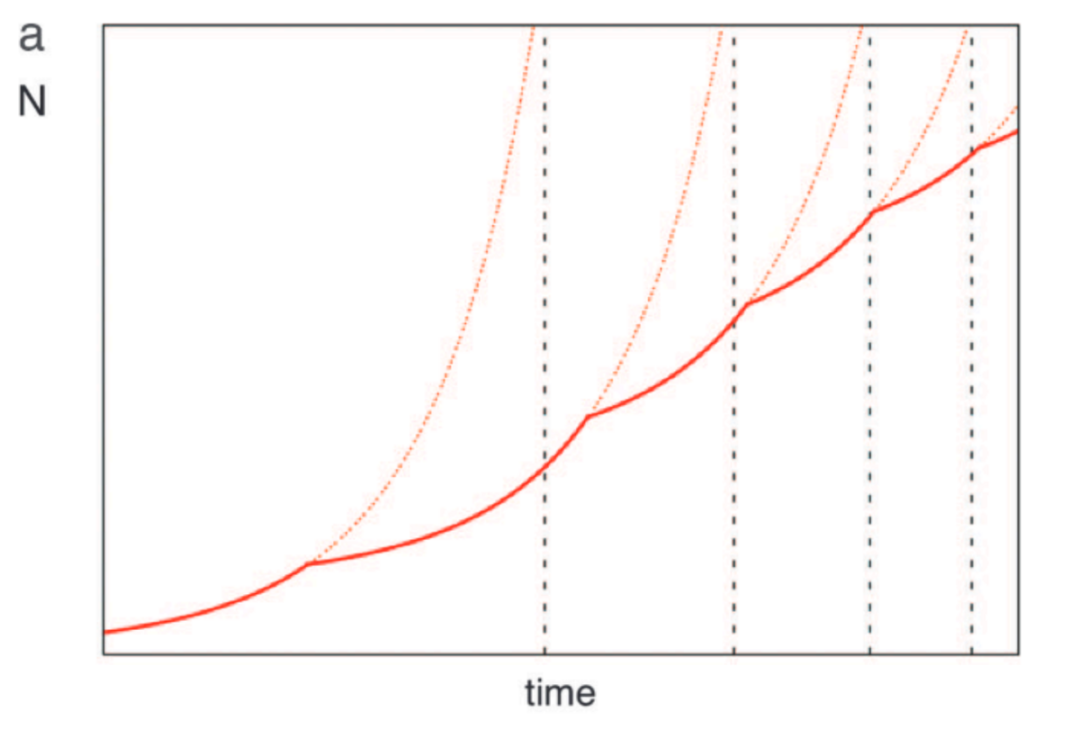
结合上述两种情形,即超指数增长和崩溃情形,得到的综合准周期的城市增长曲线。其中的竖直虚线即每一个准周期的有限时间奇点,实际的城市人口增长在达到这一奇点之前即走向崩溃,因而通过重置参数(包括 $Y_0$, $R$, $E$ 以及初始人口 $N_0$ 等)而实现新一轮的增长
这一波浪形的曲线与技术增长的准周期曲线十分相近。
Bettencourt的论文通过纽约市的人口相对增长率随时间变化的观测数据,为上述理论提供量化的实证数据支持(如下图)。
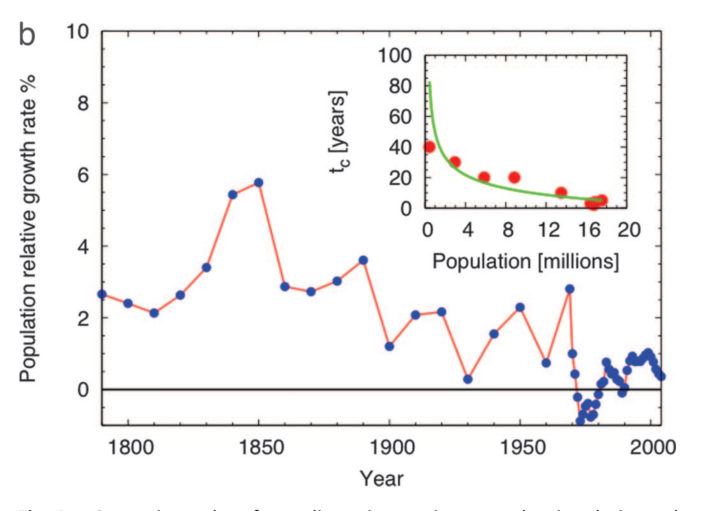
纽约市人口的实际增长情况,为了看到多个准周期增长现象,该图展示的人口的增长率随时间的变化。其中的内置小图展示的是每个准周期中初始人口与本周期内的奇点到达时间的幂律关系
注意该图绘制的并不是人口随时间变化的曲线,而是人口生长率随时间变化的曲线,因而该图与分阶段超指数增长曲线本质上是一致的。
从该图,我们可以得到以下结论:
- 纽约市的相对人口增长率图显示出连续的、加速的(超指数)增长时期。这些超指数增长期被短暂的减速期分隔开来。这种连续加速增长的模式与理论预测的“成功接续的超线性创新周期会重置奇点并推迟不稳定性和随后的崩溃”的机制相符。
- 奇点时间 $t_c$ 的拟合:针对纽约市不同增长周期起始时的人口 $N(0)$ 与预测的崩溃时间 $t_c$ 的关系进行拟合(小图),结果与预测吻合良好。观测数据最佳拟合的 $\beta$ 值为 $\beta \approx 1.09$,这与美国城市的幂指数 $\beta \approx 1.15$ 接近。
3.2.4.3 不可回避的奇点
虽然通过重置系数可以暂时避免崩溃并开启新的增长周期,但这一过程是不可持续的。
事实上,从方程(12),以及对有限时间奇点的分析,我们还可以得到一个关键的结论:为了维持持续增长,创新周期之间的时间间隔必须不断缩短。这是因为根据奇点时间公式:
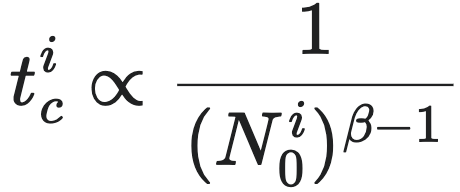
这里 $t_c^i$ 代表第 $i$ 个准周期的周期长度,即达到有限时间奇点的时间长度,$N_0^i$ 则代表第 $i$ 个准周期在开始被重置时候的初始人口规模。由此可以推断:当初始人口 $N_0^i$ 增加时,达到下一次崩溃的时间 $t_c^i$ 会变短。因此,新的重大创新或适应措施必须以不断增加的速率出现,才能维持城市的增长。
于是,随着 $N_0^i$ 持续增长,$t_c$ 必然会变得越来越短。最终当 $t_c \to 0$ 的时候,城市便遭遇了不可回避的奇点(Unavoidable singularity)。在这一点,人们将不能通过重置系数而进入新的增长轨迹。
3.3 企业生长方程
既然企业也普遍遵循亚线性的规模法则,而且企业可以类比生物体,因此从规模法则导出生长方程的逻辑同样也适用于企业。但是,与生物和城市不同,企业在生长的过程中还需要考虑另外一个非常重要的因素,这就是债务。由于,企业可以通过借贷的方式而扩张资本,所以负债的规模法则是影响企业生长方程中的关键因素。
张江等人在2021年的研究基于规模法则推导出了符合任意单一市场的企业生长方程。该理论基于企业的财务平衡原理与规模法则,提供了一个描述任意单一市场代表性企业随时间增长的通用方程。
该理论建立在两个基本假设之上:
-
财务平衡方程: 企业的总资产 $A(t)$ 随时间的变化率,等于其净收入 $I(t)$ 加上负债 $L(t)$ 的变化率。在忽略资本注入和股息支付等次要因素后(通过研究实证数据,这两项与债务增量相比较对于上市企业都是可以忽略的),这一关系可以表达为微分形式:
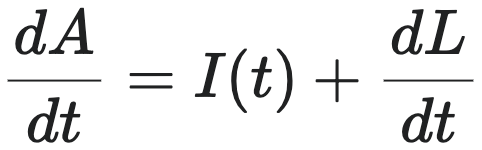
此方程在任何时刻都成立,它描述了企业的资源流入和流出如何驱动其增长。该方程称为财务平衡方程。
-
企业的财务指标均符合总资产的规模法则(如净收入 $I$ 和负债 $L$)与公司规模(用总资产,即Total Assets: $A$ 来衡量)之间均存在着幂律关系。这与生物体和城市中观察到的规模法则类似:
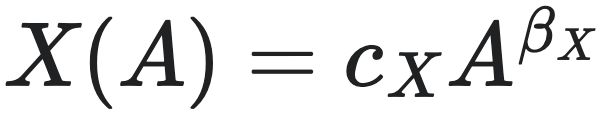 。其中 $X$ 代表某一财务指标,$c_X$ 为规模法则的常数,$β_X$ 为规模法则的幂律指数。
。其中 $X$ 代表某一财务指标,$c_X$ 为规模法则的常数,$β_X$ 为规模法则的幂律指数。
3.3.1 重要公式推导
通过将规模法则代入微分形式的财务平衡方程,可以得到一个通用的企业增长微分方程,它能预测公司总资产随时间的变化轨迹。
这里,我们主要关注两个规模法则:收入的规模法则 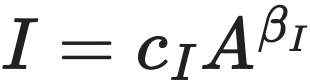 ,以及负债的规模法则:
,以及负债的规模法则: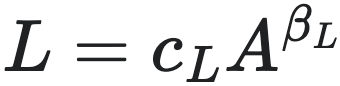 。代入财务平衡方程
。代入财务平衡方程 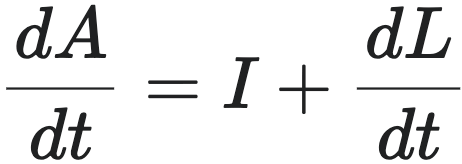 ,得到:
,得到:
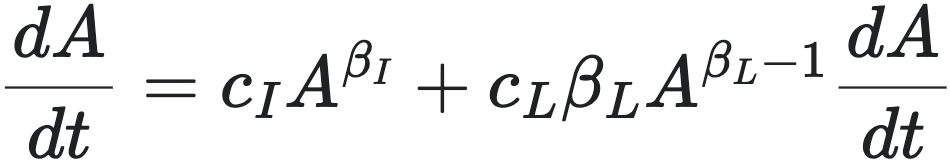
重新整理此方程,得到普适的企业增长率方程(Generalized Growth Equation):
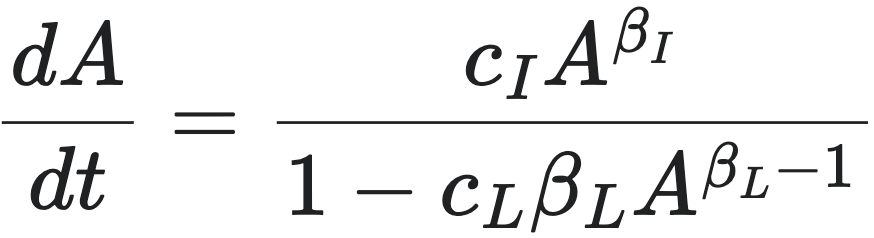 (13)
(13)
这个方程描述了企业资产 $A$ 随时间 $t$ 变化的速率。
3.3.2 通用增长曲线与近似解
如果将某市场的参数(包括:$β_I$, $β_L$, $c_I$, $c_L$ 等)代入式(13),则该微分方程的解给出了企业随时间的增长轨迹。通过对该方程进行积分,可以得到一个描述企业资产 $A(t)$ 与其年龄 $t$ 之间关系的隐式表达式,该表达式被称为:
通用增长曲线(Generalized Growth Curve):
![t = A^(1-β_I) / (c_I(1 - β_I)) [1 - ((1 - β_I)/(β_L - β_I))c_Lβ_LA^(β_L-1)]](https://static1.yunpan.plus/attachment/cf07f49845a811c2.webp)
然而,对于一般的情形,这个方程通常无法直接反解出 $A(t)$ 的显式表达式。当负债的标度指数 $β_L$ 约等于 1 时,可以得到一个很好的近似解:
幂律增长近似解(Power Law Approximation):
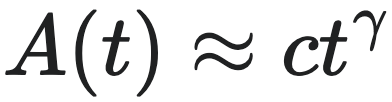
其中,指数 $\gamma$ 和系数 $c$ 由幂指数 $β_L$ 和 $β_I$ 决定。当 $β_L$ 近似等于 1 时(例如在美国市场),指数 $\gamma$ 的表达式简化为 $\gamma = 1 / (1 - β_I)$。根据美国市场的实证数据,$β_I \approx 0.85$,这导致 $\gamma \approx 6.79$。当然,我们也可以通过数值的方式,反解出 $A(t)$。
总之,该模型表明,公司的增长轨迹是一个复杂的、由其内在财务结构决定的动态过程。与生物体最终停止生长的S形曲线不同,该模型预测企业可以经历类似城市一样的开放式增长,即具有较大幂指数的超线性幂律增长,而且不存在着饱和效应。这种理论框架能够灵活地适用于不同市场(例如,中国、欧洲市场的 $β_L$ 略大于1),并做出准确的预测。
3.3.3 模型的验证
陶如意等人利用美国、欧洲和中国的数据,验证了上述企业生长方程的有效性。
- 美国和欧洲:数据来自Compustat数据库,包含了美国(1950–2023)和欧洲(1987–2023)公开上市公司的财务信息。
- 中国:数据来自Wind资讯的上海证券交易所和深圳证券交易所数据库,包含了1996年至2022年中国公开上市公司的财务信息。
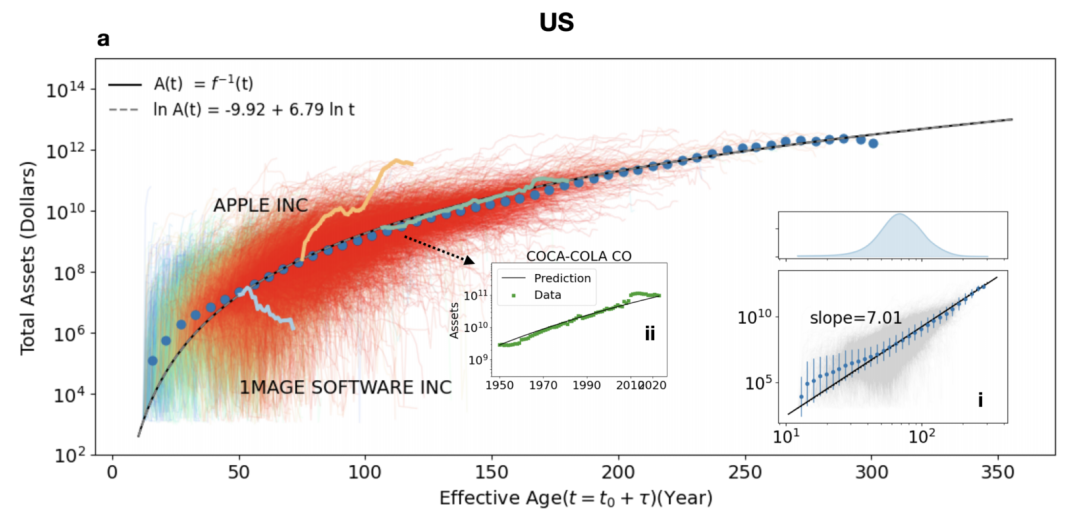
该图展示了美国预测的一般性的增长曲线,以及基于估计的 $t_0$(即根据的每个公司的实际的初年数据 $A_0$,反解出 $t_0 = (A_0/c)^{1/\gamma}$),然后再根据 $t_0$, $A_0$,将每家企业的增长轨迹放置到总资产和时间 $t$ 的平面上。这突出表明,企业的增长是时间的幂函数。指数 $\gamma = 6.79$,归一化系数的对数值 $\ln c = 3.11$。
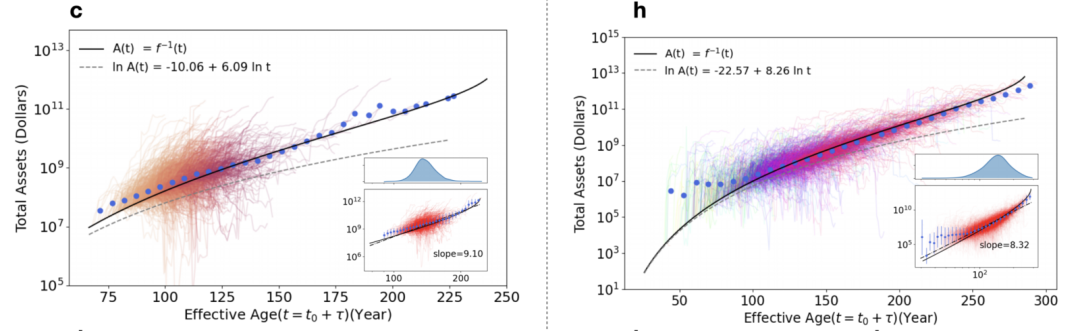
左图和右分别展示了中国和欧洲市场中的一般生长曲线以及各市场企业的实际增长轨迹。该图的绘制与图a中对美国市场的测试方式相同,即求出每家具体企业的 $t_0$,从而与企业的 $A_0$ 一起将每家企业的增长曲线绘制在图中。值得注意的是,中国的增长曲线与美国的不同,这主要体现在幂指数 $β_L > 1$。
(未完待续)
 发表于 2026-3-12 09:35:10
|
查看: 220|
回复: 0
发表于 2026-3-12 09:35:10
|
查看: 220|
回复: 0
