干了十几年量化,我发现大部分人亏钱不是因为看不懂K线,而是看不懂概率。这篇文章就聊聊金融市场的“地形图”——概率分布。从温顺的正态分布到狂野的肥尾分布,从中心极限定理到极值理论,带你搞懂为什么模型总在极端行情下失效,以及怎么用数学思维避开那些“千年一遇”的大坑。
文中示例仅用于技术讨论,不构成任何操作建议。量化策略开发应以学习和技术交流为目的。市场有风险,请合法合规投资。
开篇:市场是不确定的,但不确定本身可以被描述
做交易的朋友都知道,市场最大的确定性就是“不确定”。但是,这种不确定并不是完全随机的,它有自己的“脾气”和“规律”。
想象一下,你手里有一张地图。这张地图不是用来告诉你下一秒股价会涨到多少,而是告诉你:价格出现某种波动的可能性有多大。这就是概率分布在金融领域的核心作用——它是我们理解市场风险的“导航仪”。
在量化圈混了这么多年,我见过太多人把概率分布当成摆设。他们拿着正态分布的假设去算风险价值(VaR),结果遇到一次“黑天鹅”就爆仓。今天就用最直白的话,把这事给你掰扯清楚。
② 正态分布:金融世界的“理想型”
2.1 为什么大家都爱钟形曲线
正态分布,也叫高斯分布,是统计学界的“网红”。它的曲线像个钟,中间高两边低,对称美观。在金融市场里,这个分布被用得最广,原因很实在:
- 数学好算: 加减乘除都有现成公式,计算机跑起来快。
- 中心极限定理撑腰: 大量独立随机因素叠加,最后都会趋向正态。
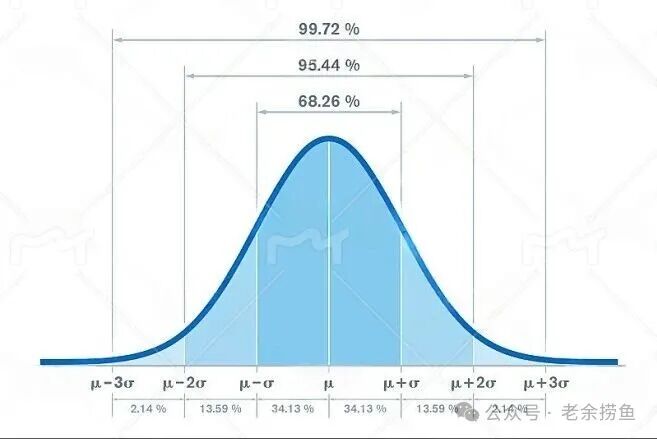
- 直观好懂: 68%的数据在一个标准差内,95%在两个标准差内。
现代投资组合理论(MPT)、Black-Scholes期权定价模型,这些经典理论都是建立在正态分布假设上的。可以说,没有正态分布,就没有现代量化金融。
2.2 正态分布的“人设”参数
正态分布就两个参数,简单到粗暴:
| 参数 |
含义 |
金融解释 |
| μ(均值) |
分布的中心位置 |
资产的预期收益率 |
| σ(标准差) |
分布的胖瘦程度 |
波动率,也就是风险大小 |
公式也简单:
$P(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \times e^{-\frac{(x-\mu)^2}{2\sigma^2}}$
2.3 实战演示:模拟股票日收益
假设某只股票日均收益0.05%,日波动率2%。我们用Python模拟10000个交易日的收益:
import numpy as np
import matplotlib.pyplot as plt
# 参数设置
mean_return = 0.0005 # 日均收益0.05%
volatility = 0.02 # 日波动率2%
days = 10000
# 生成模拟数据
returns = np.random.normal(loc=mean_return, scale=volatility, size=days)
# 可视化
plt.hist(returns, bins=50, density=True, alpha=0.7, color='steelblue')
plt.title("模拟股票日收益分布(正态假设)")
plt.xlabel("收益率")
plt.ylabel("概率密度")
plt.show()
③ 理想很丰满,现实很骨感:肥尾危机
3.1 为什么正态分布会“翻车”
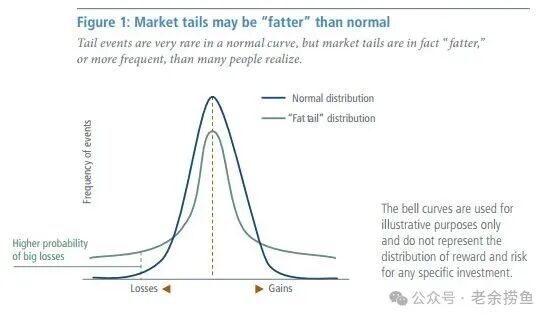
正态分布有个致命弱点:它太“温顺”了。在正态分布的假设下,超过5个标准差的事件(5-sigma事件)概率只有0.00006%,理论上几万年才发生一次。
但看看历史:
- 1987年黑色星期一,道指一天暴跌22.6%;
- 2008年金融危机,标普500跌幅超过40%;
- 2015年A股熔断,千股跌停;
- 2020年疫情暴发,美股四次熔断。
如果按正态分布算,这些事件的概率比“你连续中十次彩票头奖”还低。但它们就是发生了,而且发生得挺频繁。这就是著名的 “肥尾现象”(Fat Tails)。
3.2 肥尾分布家族
当正态分布不够用时,我们需要更“狂野”的分布:
| 分布类型 |
特点 |
适用场景 |
风险 |
| 学生t分布 |
自由度越小,尾部越厚 |
股票收益率建模 |
方差可能无限(自由度≤2) |
| 柯西分布 |
均值和方差都不存在 |
极端波动建模 |
传统统计方法失效 |
| 列维分布 |
尺度不变性,跳跃频繁 |
高频交易、跳跃扩散 |
难以估计参数 |
| 对数正态分布 |
取对数后为正态 |
资产价格建模(价格不能为负) |
右偏,大涨概率被低估 |
⚠️ 用正态分布做风险管理,就像用平均水位设计堤坝——平时没问题,洪水一来就完蛋。2008年金融危机前,很多机构的模型都假设房价不会全国范围下跌,结果大家都看到了。理解这种“肥尾”特性,对于现代人工智能与大数据分析模型的设计同样至关重要。
④ 对数正态分布:资产价格的“专属皮肤”
4.1 为什么价格不能用正态分布
股票价格是永远大于零的(破产除外),但正态分布可以取负值。这就不合理。所以金融工程师想了个办法:让价格的对数服从正态分布。
这就是 对数正态分布。它的特点是:
- 取值范围是(0, +∞),不会出现负数价格;
- 右偏分布,大涨的概率比大跌的概率高(相对而言);
- 符合“复利效应”:长期收益是每天收益的乘积,不是加总。
4.2 Black-Scholes的基石
著名的Black-Scholes期权定价公式,就是假设标的资产价格服从对数正态分布。公式长这样:
$C = S_0 N(d_1) - K e^{-rT} N(d_2)$
其中:
$d_1 = \frac{\ln(S_0/K) + (r + \sigma^2/2)T}{\sigma \sqrt{T}}$
$d_2 = d_1 - \sigma \sqrt{T}$
这里的 $N(·)$ 就是标准正态分布的累积分布函数。可以说,整个期权市场的定价体系,都建立在对数正态分布的假设上。
⑤ 极值理论:专门对付“黑天鹅”的利器
5.1 别预测,只准备
纳西姆·塔勒布在《黑天鹅》里说,极端事件无法预测,但可以为它做准备。极值理论(Extreme Value Theory, EVT)就是干这个的。
EVT不关注数据的“身体”部分,只关注“尾巴”——那些极端的、罕见的大涨大跌。它回答的问题是:给定已经发生了很多极端事件,下一个更极端的事件会有多糟?
5.2 两种实战方法
方法一:区块极值法(Block Maxima)
把历史数据切成一块一块(比如按月切),取每块的最大值(或最小值),然后用广义极值分布(GEV)拟合。
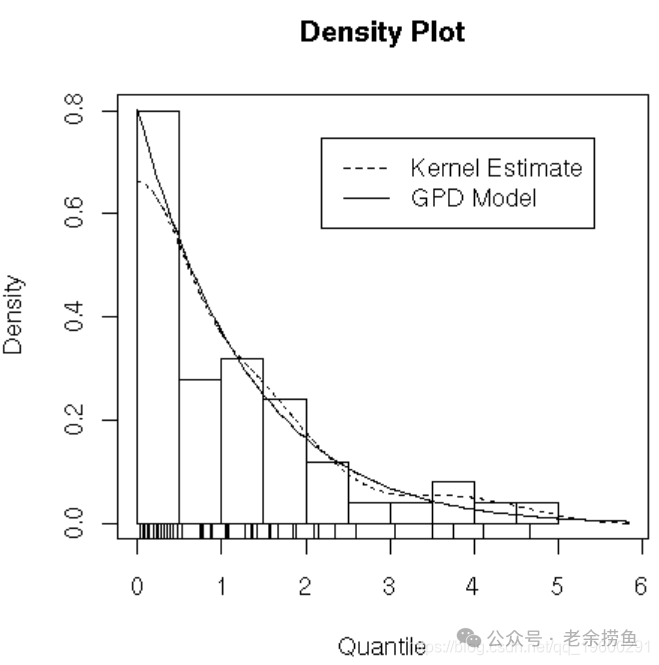
方法二:超阈值法(POT, Peak Over Threshold)
设定一个阈值,只看超过这个阈值的数据,用广义帕累托分布(GPD)拟合。这种方法更省数据,也更直观。
💡 实战案例: 假设你想算某只股票的99% VaR(风险价值)。传统方法用正态分布,可能得出“最大亏损5%”的结论。但用EVT的POT方法,考虑到肥尾效应,可能会告诉你“最大亏损8%,而且发生这种极端情况时,平均亏损是12%”。这就是预期损失(ES)的概念。
5.3 EVT的局限
EVT也不是万能的:
- 需要大量历史数据,特别是极端事件的数据。
- 假设数据独立同分布,但金融市场有聚类效应(波动率聚类)。
- 只能外推“已见过的极端”,对前所未有的灾难(如新冠疫情初期的市场反应)预测能力有限。
⑥ 实战指南:怎么选分布模型
不同的业务场景,需要不同的分布模型。给你整理了个对照表:
| 应用场景 |
推荐分布 |
理由 |
注意事项 |
| 日常风险管理 |
正态分布 + 压力测试 |
计算简单,监管认可 |
必须定期做极端情景压力测试 |
| 期权定价 |
对数正态分布(基础)+ 隐含波动率微笑 |
符合价格非负特性 |
实际市场存在波动率偏斜,需要调整 |
| 高频交易 |
学生t分布或列维分布 |
捕捉跳跃和厚尾 |
参数估计困难,需要大量数据 |
| 保险/操作风险 |
极值理论(EVT) |
专门处理低频高损事件 |
阈值选择很关键,选不好模型会失真 |
| 组合优化 |
Copula + 边缘分布 |
处理资产间的相关性 |
尾部相关性往往被低估 |
⑦ 认知升级:从“预测”到“应对”
说了这么多,核心就一句话:别迷信任何分布模型。
正态分布是理想化的假设,肥尾分布更接近现实,但也不是真理。市场是由人组成的,人有情绪,会恐慌,会贪婪,这些都不是数学公式能完全捕捉的。
我的建议是:
- 多层防御: 别只依赖一个模型。用正态分布做日常管理,用EVT做极端情景准备,用压力测试填补模型盲区。
- 动态调整: 市场结构会变,2008年前的模型参数,到2009年可能就不适用了。定期回测,及时调整。
- 留足安全边际: 模型说最大回撤10%,你就按20%准备资金。活得久比赚得快重要。
- 关注尾部相关性: 平时不相关的资产,在危机时刻可能一起跌。分散投资在极端行情下可能失效。
- 承认无知: 知道自己不知道什么,比知道什么更重要。对模型保持敬畏,对市场保持谦卑。
⑧ 观点总结
🎯 核心要点回顾
概率分布是量化金融的“地图”,但地图不是领土。正态分布好用但过于理想,肥尾分布更真实但计算复杂,极值理论专门对付黑天鹅但数据要求高。没有完美的模型,只有合适的工具组合。
五条黄金法则:
- 正态分布适合“正常时期”,但必须配套极端情景分析。
- 资产价格优先用对数正态分布,避免负数价格尴尬。
- 遇到厚尾数据(如加密货币、小盘股),考虑学生t分布或列维分布。
- 管理极端风险用极值理论(EVT),关注超过阈值的数据。
- 任何模型都要配合严格的风险管理和资金控制。
希望这篇关于金融数学中概率分布应用的讨论,能为你构建更稳健的风控体系带来启发。如果你想深入了解数据科学与模型训练的其他实战技巧,欢迎到云栈社区与更多开发者交流探讨。
 发表于 2026-3-12 11:11:09
|
查看: 229|
回复: 0
发表于 2026-3-12 11:11:09
|
查看: 229|
回复: 0
