原文测试实际基于 ASUS Ascent GX10 完成,该机型为 NVIDIA DGX Spark 的 OEM 版本,文中统一记作 DGX Spark。

一、背景与准备
“本地模型是不花钱的。”
如果你听到这句话,那多半是骗你的。因为本地模型要能顺畅跑起来,前提是你已经投入成本购置了能够承载它的硬件设备。而 NVIDIA DGX Spark,无疑是本地运行大模型的理想平台之一。
选择在 DGX Spark 上进行 Docker 部署,是出于安全与便捷的考虑。将应用及其依赖封装在容器中,可以最大程度地避免 npm 等包管理器可能带来的文件系统意外修改。正如官方安全提示所述,对于 OpenClaw 这类被授予了高系统权限的智能体软件,严格的环境隔离是首要前提。

二、安装与部署过程
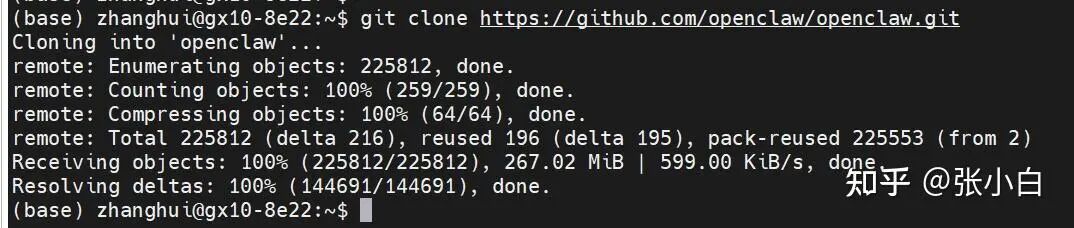
1. 克隆 OpenClaw 代码仓库
第一步是从 GitHub 获取 OpenClaw 的源代码。
git clone https://github.com/openclaw/openclaw.git
2. 首次尝试一键部署(失败)
进入项目目录,执行 Docker 部署脚本。
cd openclaw
./docker-setup.sh

脚本执行失败,错误信息显示 Docker 守护进程套接字连接被拒绝,原因是当前用户没有足够的 Docker 权限。
3. 将用户加入 Docker 用户组
为了解决权限问题,需要将当前用户添加到 docker 用户组中。
sudo usermod -aG docker $USER

执行完成后,需要重新登录系统以使组权限生效。登录后,可以通过以下命令验证用户组信息,确认 docker 组已加入。
id

重启 Docker 服务,并检查是否已无需 sudo 即可执行 Docker 命令。
sudo service docker restart
docker images


4. 第二次尝试一键部署(失败)
权限问题解决后,再次尝试部署。
cd ~/openclaw
./docker-setup.sh

这次遇到了新的问题:TLS handshake timeout。这通常是 Docker 在拉取基础镜像时,由于网络连接至默认的 Docker Hub 仓库速度过慢或失败导致的。
5. 配置 Docker 镜像加速器
为了提升镜像拉取速度,需要配置国内的 Docker 镜像加速源。编辑 Docker 守护进程的配置文件 /etc/docker/daemon.json。
{
“registry-mirrors”: [
“https://docker.hlmirror.com“,
“https://docker.1ms.run“,
“https://hub-mirror.c.163.com“,
“https://mirror.baidubce.com“,
“https://docker.xuanyuan.me“,
“https://docker.1ms.run“,
“https://docker.m.daocloud.io“,
“https://pull.loridocker.com“,
“https://ccr.ccs.tencentyun.com“,
“https://docker.hlmirror.com“,
“https://dockerpull.cn“
]
}
保存文件后,重启 Docker 服务使配置生效。
sudo service docker restart

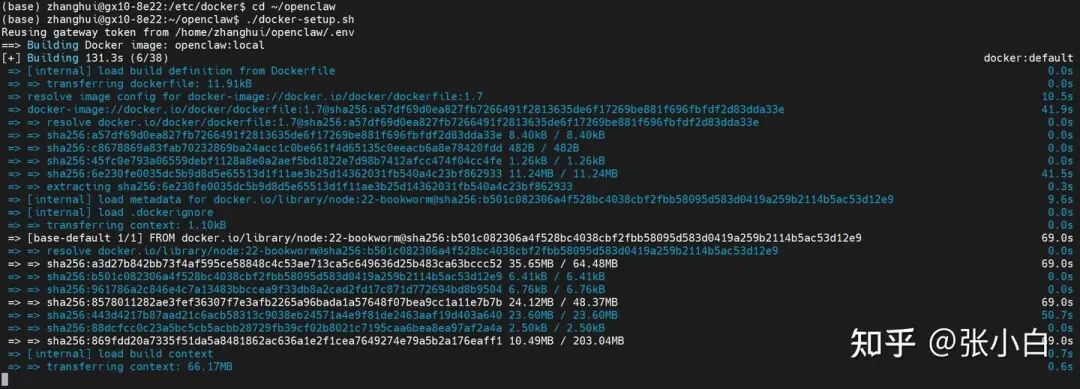
6. 第三次尝试部署与初始化配置
配置好镜像加速后,第三次执行部署脚本,这次构建过程顺利开始了。
cd ~/openclaw
./docker-setup.sh
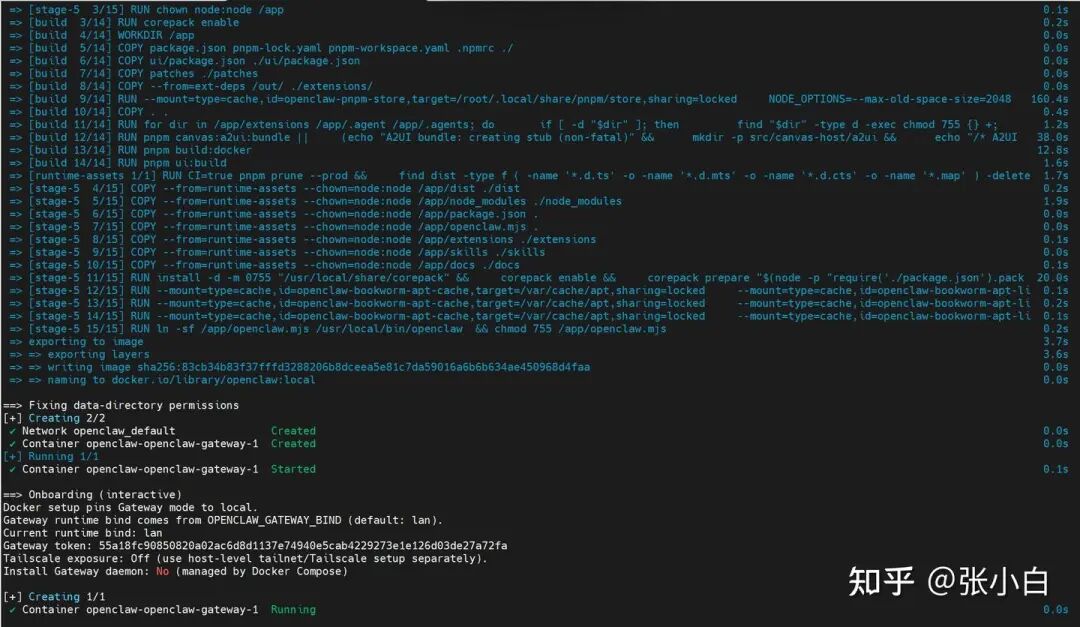
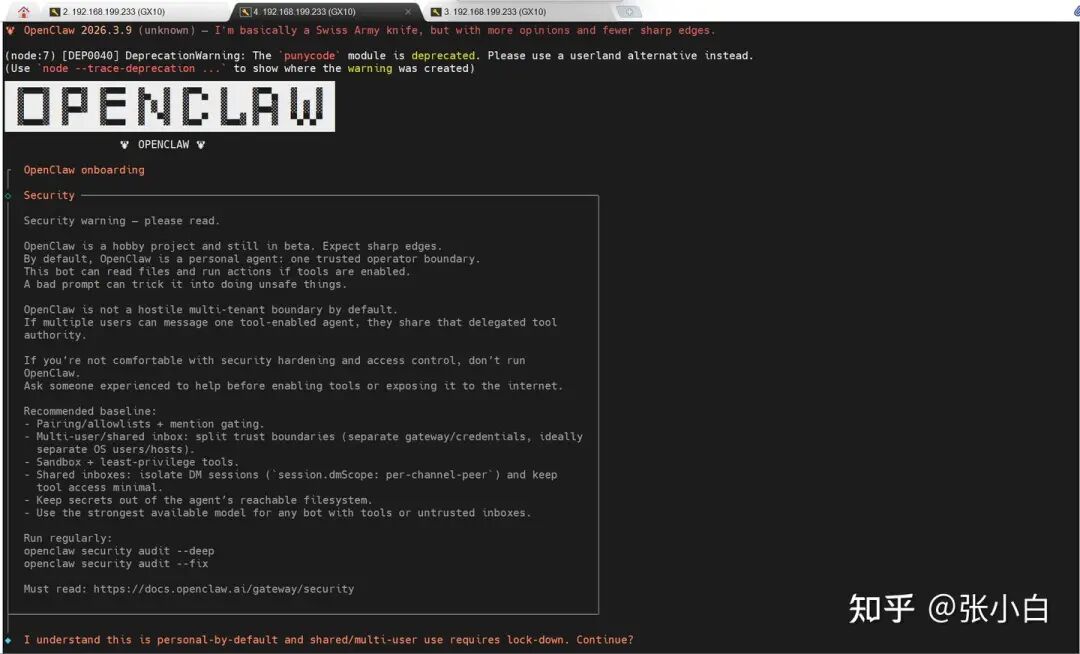
构建完成后,会进入 OpenClaw 的交互式初始化配置向导。首先是一个重要的安全警告,阅读后输入 Yes 继续。
选择 QuickStart 快速启动模式,网关端口保持默认的 18789,绑定地址为 Loopback。

选择模型提供商。这里我们先选择 Z.AI (GLM Coding Plan) 进行初步配置,后续会替换为本地模型。

输入 Z.AI 的 API 密钥,并选择模型版本,例如 zai/glm-4.7。

接下来配置通信渠道(Channel),这里可以选择 Telegram、WhatsApp、Discord 等。为了简化初次设置,选择 Skip for now,稍后再配置。

同样,网页搜索(Web Search)功能和技能(Skills)配置也暂时跳过。
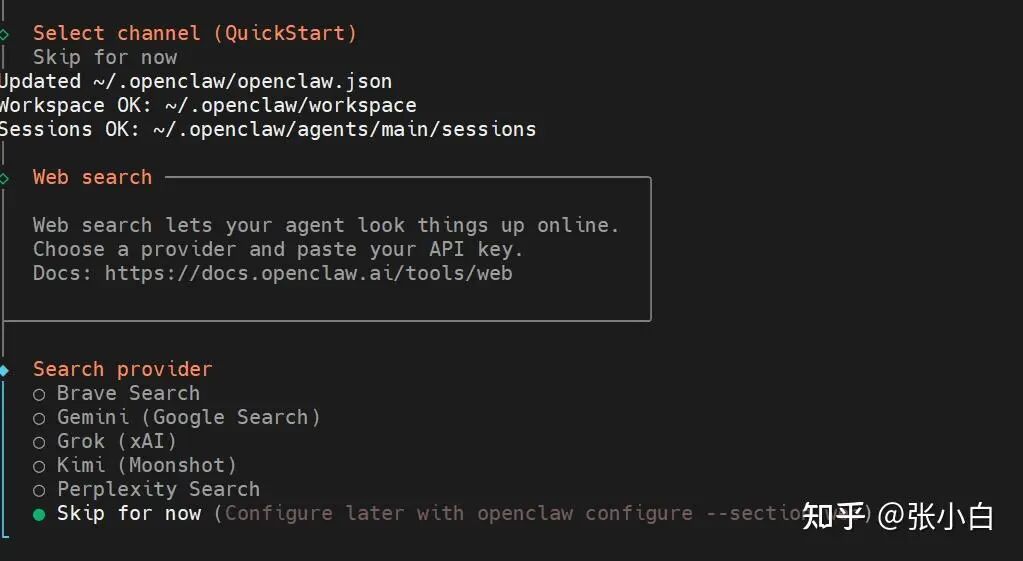

在 Hooks(钩子)配置页面,启用所有推荐的钩子功能,如 boot-md、command-logger 等,以增强自动化能力。
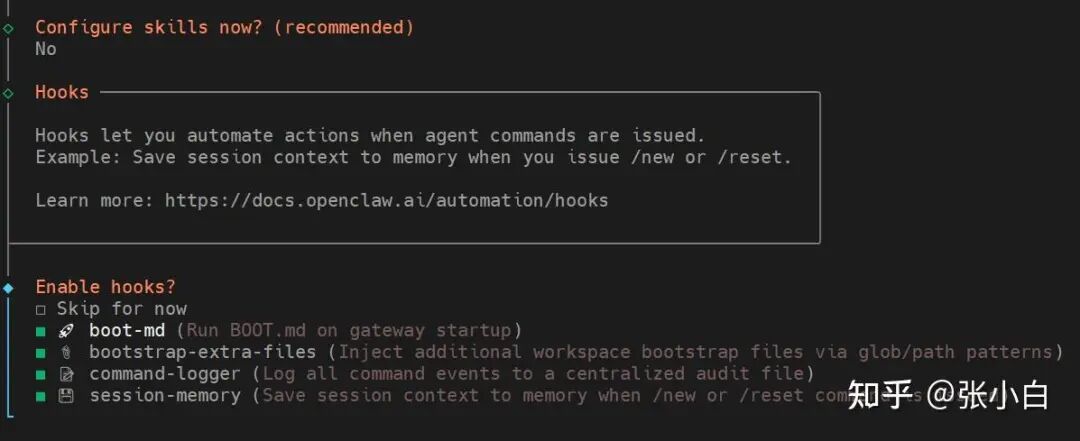
配置完成后,向导提示健康检查失败,网关连接异常。
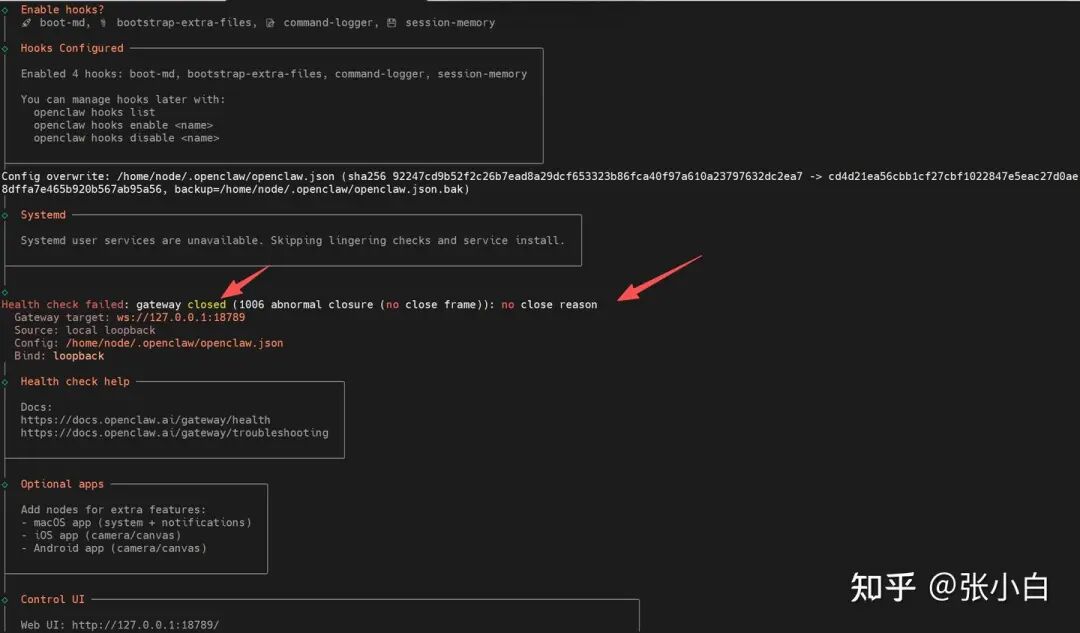
同时,终端也显示 Docker 网关容器启动失败,处于不断重启的状态。
Error response from daemon: cannot join network namespace of container: Container b1b001ba93db... is restarting, wait until the container is running

7. 解决网关启动故障
首先检查 Docker 容器状态,确认网关容器确实在重启循环中。
docker images
docker ps

问题的根源在于 OpenClaw 网关的跨域安全策略。需要修改其配置文件,允许控制 UI 从特定的来源进行访问。编辑 ~/.openclaw/openclaw.json 文件,在 gateway 配置段中添加 controlUi.allowedOrigins。
{
“gateway”: {
“controlUi”: {
“allowedOrigins”: [
“http://127.0.0.1:18789“,
“http://localhost:18789“,
“http://192.168.199.233:18789“
]
},
}
}

保存配置后,再次检查容器状态,发现已经成功启动并运行。
docker ps

8. 访问 Web 控制面板
进入正在运行的 Docker 容器内部。
sudo docker exec -it b1b001ba93db bash
在容器内获取 Dashboard 的访问链接(包含令牌)。
openclaw dashboard --no-open

将输出的 URL(如 http://192.168.199.233:18789/#token=xxx)在浏览器中打开。初次访问时,可能会因为 HTTP 协议的安全限制而提示需要设备身份验证。
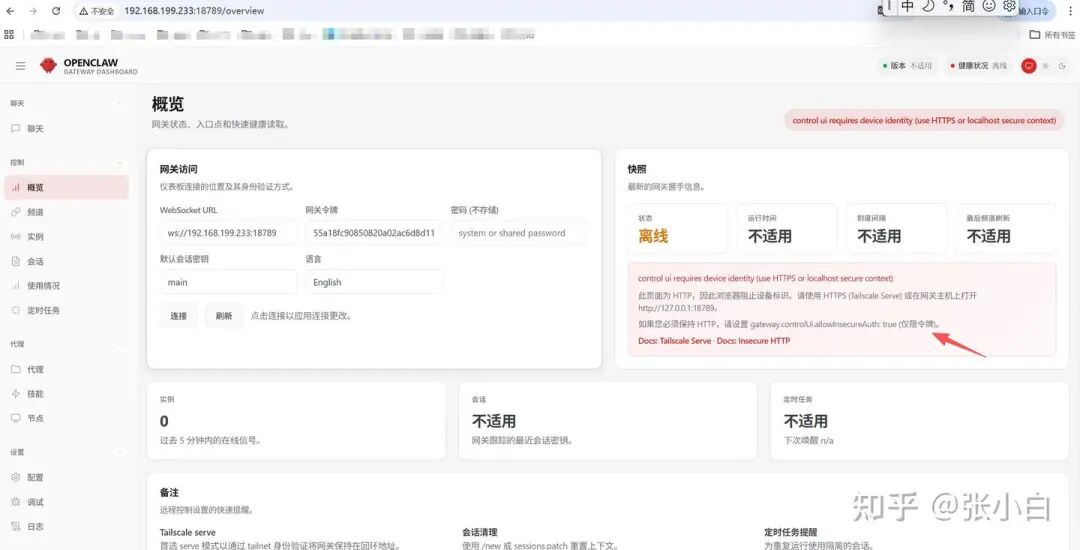
根据提示,需要进一步修改配置文件,允许不安全的身份验证方式(仅限本地测试环境)。在 ~/.openclaw/openclaw.json 的 gateway.controlUi 部分添加 “allowInsecureAuth”: true。
“gateway”: {
“controlUi”: {
“allowInsecureAuth”: true,
“allowedOrigins”: [
“http://127.0.0.1:18789“,
“http://localhost:18789“,
“http://192.168.199.233:18789“
]
},
}
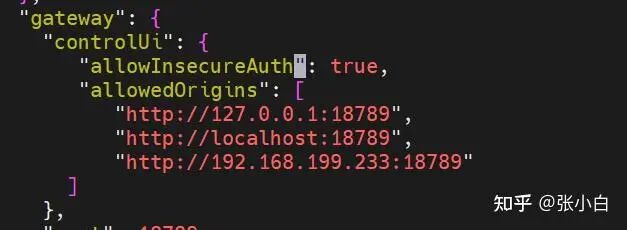
修改并保存后,刷新浏览器页面,即可成功连接到 OpenClaw 网关 Dashboard。

9. 尝试网页版对话
通过 Dashboard 的聊天界面,可以开始与 AI 助手进行对话。系统会引导你完成初始的身份设定。


三、接入 QQ 机器人
为了让 OpenClaw 可以通过 QQ 接收指令,我们需要配置一个 QQ 机器人。
1. 注册并配置 QQ 开放平台
访问 QQ 开放平台 (https://q.qq.com),使用 QQ 号登录并完成开发者实名认证。在“管理”页面中,需要绑定一个超级管理员账号。

2. 创建 QQ 机器人
在平台内点击“创建机器人”,为其命名(例如 OpenClaw-QQ)。

创建后,进入该机器人的“开发管理”页面。这里需要获取两个关键信息:
- AppID:机器人的唯一标识。
- AppSecret:机器人的密钥,需要点击“生成”按钮获取,并妥善保存。


3. 为 OpenClaw 安装 QQ 插件
回到 DGX Spark 的终端,进入 OpenClaw 的 Docker 容器,安装官方提供的 QQ 机器人插件。
docker exec -it b1b001ba93db bash
openclaw plugins install @sliverp/qqbot@latest

安装完成后,添加 QQ 渠道,命令格式为 AppID:AppSecret。
openclaw channels add --channel qqbot --token “你的AppID:你的AppSecret”

4. 扫码绑定与测试
配置完成后,访问 QQ 开放平台的机器人管理页面,找到你创建的机器人,点击“扫码聊天”。

使用手机 QQ 扫描弹出的二维码,即可将机器人添加为好友。现在,你可以直接在 QQ 中向这个机器人发送消息,指令会由 OpenClaw 处理并回复。

四、切换至本地 Ollama 模型
最初我们配置了云端 GLM 模型,现在将其替换为本地运行的模型,真正实现“本地化”。
1. 下载并运行本地模型
这里以 mirage335/Nemotron-3-Nano-30B-A3B-virtuoso 模型为例。使用 Ollama 拉取并运行该模型。
ollama run mirage335/Nemotron-3-Nano-30B-A3B-virtuoso

模型拉取完成后,可以查看其运行状态。
ollama ps

2. 配置容器网络访问
默认情况下,Ollama 服务只监听本地回环地址。为了让 Docker 容器内的 OpenClaw 能够访问宿主机上的 Ollama,需要修改 Ollama 服务配置,使其在所有网络接口上监听。
编辑 Ollama 的服务配置文件 /etc/systemd/system/ollama.service,在 [Service] 部分添加环境变量:
Environment=“OLLAMA_HOST=0.0.0.0:11434”
保存后,重新加载服务配置并重启 Ollama。
sudo systemctl daemon-reload
sudo systemctl restart ollama
sudo systemctl status ollama
重启后,测试在容器网络内是否能访问到 Ollama 服务(172.17.0.1 是 Docker 容器的默认网关,指向宿主机)。
curl http://172.17.0.1:11434

3. 在 OpenClaw 中配置 Ollama 模型
进入 OpenClaw 容器,重新运行配置向导。
docker exec -it b1b001ba93db bash
openclaw configure
在配置过程中,做出以下关键选择:
- Model/auth provider: 选择
Custom Provider
- API Base URL: 填入
http://172.17.0.1:11434/v1
- API Key: 如果 Ollama 未设置鉴权,可留空或填入
ollama
- Endpoint compatibility: 选择
OpenAI-compatible
- Model ID: 填入你所使用的模型名称,如
mirage335/Nemotron-3-Nano-30B-A3B-virtuoso

配置完成后,向导会提示更新成功。

为了使新的模型配置生效,需要重启 OpenClaw 网关进程。在容器内找到网关进程并结束它,系统会自动重启。
ps -ef | grep gateway
kill [进程号]

4. 验证本地模型对话
网关重启后,获取新的控制面板链接并打开。
openclaw dashboard --no-open

在浏览器中打开 Dashboard,输入令牌并连接。现在,无论是通过网页聊天界面还是 QQ 机器人,所有的请求都将由你本地 DGX Spark 上的 Nemotron 模型进行处理。

在聊天界面中尝试一个需要联网搜索并分析的任务,例如查询油价并绘制趋势图。你可以看到模型调用工具、执行指令的全过程。



此时,通过 DGX 的系统监控可以看到,GPU 利用率已经提升至 90% 左右,表明本地模型正在全力工作。

5. 最终效果
最后,通过 QQ 机器人进行一段复杂的对话测试,例如请求介绍一部电视剧的剧情。模型会根据其知识进行生成回答,整个过程完全在本地完成。

至此,一个部署在强大 计算平台 上、支持多通道交互、完全由本地大模型驱动的 AI 助手就搭建完成了。整个过程涵盖了从环境准备、部署排错、服务配置到最终接入本地 开源模型 的完整链条,希望这份在云栈社区的实践记录能为有类似需求的朋友提供清晰的参考。
 发表于 2026-3-13 07:31:28
|
查看: 624|
回复: 0
发表于 2026-3-13 07:31:28
|
查看: 624|
回复: 0
