前几天收到一个读者的私信,让我觉得又好笑又心疼。
这位朋友去参加腾讯AI应用开发的二面,聊项目时眉飞色舞,说自己做了好几个落地的多智能体应用,对LangChain等框架非常熟悉,工具调用流程更是信手拈来,面试官听着频频点头。
结果面试官话锋一转,慢悠悠地问了一个问题:“既然你天天和工具调用打交道,那你说说,大模型到底是怎么学会调用外部工具的?”
这位朋友当场就卡壳了。他说那一瞬间脑子里全是写过的 tool_calls 代码,可就是说不清楚这个能力是怎么来的,支支吾吾半天只憋出一句“是微调出来的”。当被进一步追问SFT和RLHF分别起了什么作用时,他直接哑火,二面也就此凉了。
说实话,这道题绝对是AI应用开发岗位面试的“重灾区”。很多同学每天都在写Function Calling、做工具调用的落地应用,却很少深入思考其底层原理,一旦被面试官问到根源,就容易翻车。
今天,我就把这道腾讯二面的高频真题,从训练逻辑到运行流程,结合图示和原理给大家拆解清楚。下次面试再遇到,就能稳稳拿捏。
💡 简要回答
这个问题可以从两个层面来回答:模型是如何被训练出工具调用能力的,以及训练好之后在运行时是如何工作的。
训练层面,主要依靠两个阶段:
- SFT(监督微调,Supervised Fine-Tuning):给模型输入大量「工具调用示范对话」,让它通过模仿学习「看到工具描述 -> 判断是否需要调用 -> 输出结构化JSON请求」这一整套流程。
- RLHF(基于人类反馈的强化学习,Reinforcement Learning from Human Feedback):收集人类对「哪种回答更好」的判断数据,训练一个专门的打分模型,再利用这个分数通过强化学习反复调整主模型,让它学会在合适的时机调用工具,建立行为边界。
运行层面,每次请求时,你的应用程序会将工具描述(称为schema,可以理解为工具的说明书)传递给模型。模型如果判断需要调用工具,就会输出一段结构化的 tool_calls JSON。你的代码拿到这段JSON后,去真正执行相应的工具,并把执行结果塞回对话上下文中,模型最后基于这个结果生成最终的自然语言答案。
这里有一个非常关键的点:模型全程只是在“下指令”,真正执行工具的是你的应用程序代码,而不是模型本身。这套「模型决策、代码执行」的运行时机制,就是我们常说的 Function Calling。
📝 详细解析
原始LLM的世界,为什么不会调工具
想象一个人从出生到成年,只生活在文字的世界里,读过几乎所有的书,却从未接触过任何真实工具——没用过锤子、没开过车、也没见过API是什么。你突然跟他说“去帮我查一下天气API”,他最多只会用语言描述“我需要查天气API来获取数据……”,绝对不会真的去操作工具。

大语言模型在预训练阶段经历的就是这样一个过程。它学习的是根据前面的文字预测下一个token(token可以理解为模型处理文字的最小单位,大致对应一个字或词)。整个训练完全在纯文本空间中进行,模型从未“见过”「工具调用」这件事。所以,即便你在提示词(Prompt)里写上“你可以调用天气API”,一个未经专门训练的模型也只会生成一段自然语言描述,例如“我需要调用天气API来回答你”,而不是输出一段可被程序解析的JSON调用请求。
工具调用能力不是天生的,是后天「教」出来的。 怎么教?主要靠两个阶段:SFT教会“怎么调”,RLHF教会“什么时候调”。

第一阶段:SFT,让模型「见过」工具调用
SFT是监督微调的缩写,核心思路非常直接:给模型看大量正确的示例,让它学会模仿。就像培养一名新员工,前期让他看几百份填好的标准工单,他自然就学会了“遇到这类问题该怎么写工单、该走哪个流程”。
要让模型学会工具调用,就需要构造专门的训练数据。一条完整的训练样本通常包含以下部分:

- System消息(工具说明书):列出模型当前可用的工具,包括每个工具的名称、功能描述以及所需参数。模型从这里开始“认识”工具。
- User消息(用户提问):例如“北京今天天气怎么样?”
- Assistant的调用请求(关键正确答案):这里不是自然语言回答,而是一段结构化的JSON,类似于:
{"tool_calls": [{"name": "get_weather", "arguments": {"city": "北京"}}]}
这就是模型需要学会输出的内容。为什么是JSON而不是自然语言?因为JSON格式固定,便于机器解析,你的代码才能准确读取到“调哪个工具”以及“参数是什么”。
- Tool消息(工具执行结果):模拟工具返回的数据,例如“晴,15°C,东北风3级”。
- Assistant的最终回答:模型在看到工具返回的结果后,生成最终的自然语言答案:“北京今天天气晴朗,气温15°C……”。
模型在几十万甚至上百万条这样的样本上反复训练,就逐渐学会了整套流程:识别工具定义 -> 判断是否需要调用 -> 输出格式规范的JSON请求。
训练数据的来源通常有两种:
- 人工标注:成本高但质量好,一般用于构造核心的种子数据。
- 模型自动生成:用更强的模型(如GPT-4)自动批量生成,再进行人工抽查。这种方式成本低、数据量大,是目前业界的主流做法。
SFT的短板:会了动作,但不知道「该不该调」
SFT让模型学会了“调工具”这个动作,但它还不知道什么时候该调、什么时候不该调。你可以想象一个刚培训完的新员工,过于热情,每件事都想走标准流程。有人问他“1+1等于几”,他也要去查操作手册,这明显是多此一举,直接回答就行。
经过SFT后的模型也有类似的“毛病”:可能对简单问题也尝试调用工具,或者在工具调用失败时不知道该如何处理,行为边界感较弱。这个问题,就需要第二阶段的RLHF来解决。
第二阶段:RLHF,用反馈建立边界感
RLHF是人类反馈强化学习的缩写。如果说SFT是让新员工看示例学规范,那RLHF就是老板持续给他的工作表现打分,帮他建立判断力和分寸感。
它的典型流程可以分为四步:
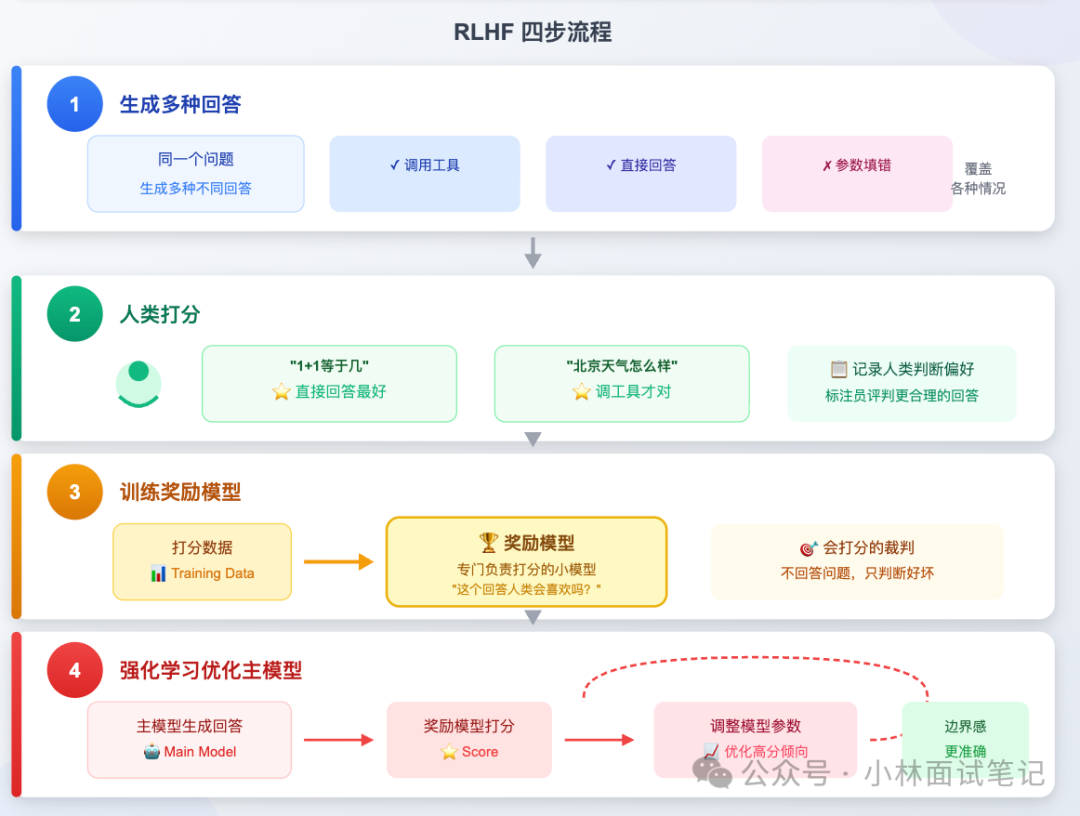
- 第一步,生成多种回答:针对同一个问题,让模型生成几种不同的处理方式。有的调用了工具,有的直接回答,有的参数填错了。目的是故意覆盖各种可能的情况。
- 第二步,人类打分:由标注员评判哪种回答更合理。例如,“1+1等于几”直接回答最好;“北京天气怎么样”调用工具才对。这批打分数据记录了人类的判断偏好。
- 第三步,训练奖励模型:用这批打分数据,单独训练一个小模型。这个模型专门负责打分,它不直接回答问题,只判断“这个回答人类会喜欢吗?”。你可以把它理解成一个“会打分的裁判”。
- 第四步,强化学习优化主模型:利用奖励模型的打分,通过强化学习算法不断调整主模型的参数,让主模型越来越倾向于产出能够获得“高分”的回答,也就是工具调用行为边界感更准确、更符合人类预期的回答。
经过这个过程,模型逐渐学会了更微妙的判断:能直接回答的就直接回答,不要多此一举去调工具;需要实时数据、需要执行具体操作的,才去调用。这个边界感是仅靠SFT给不了的,必须依赖人类(或AI)的反馈信号来塑造。
RLAIF(AI反馈)是RLHF的一个变体,它用另一个AI模型代替人类标注员进行打分,成本更低、速度更快,目前在业界也很常用,其效果与人工反馈相差不大。
运行时:训练好之后怎么用?
训练阶段结束后,模型就上线投入使用了。每次你的应用程序调用模型时,流程是这样的:
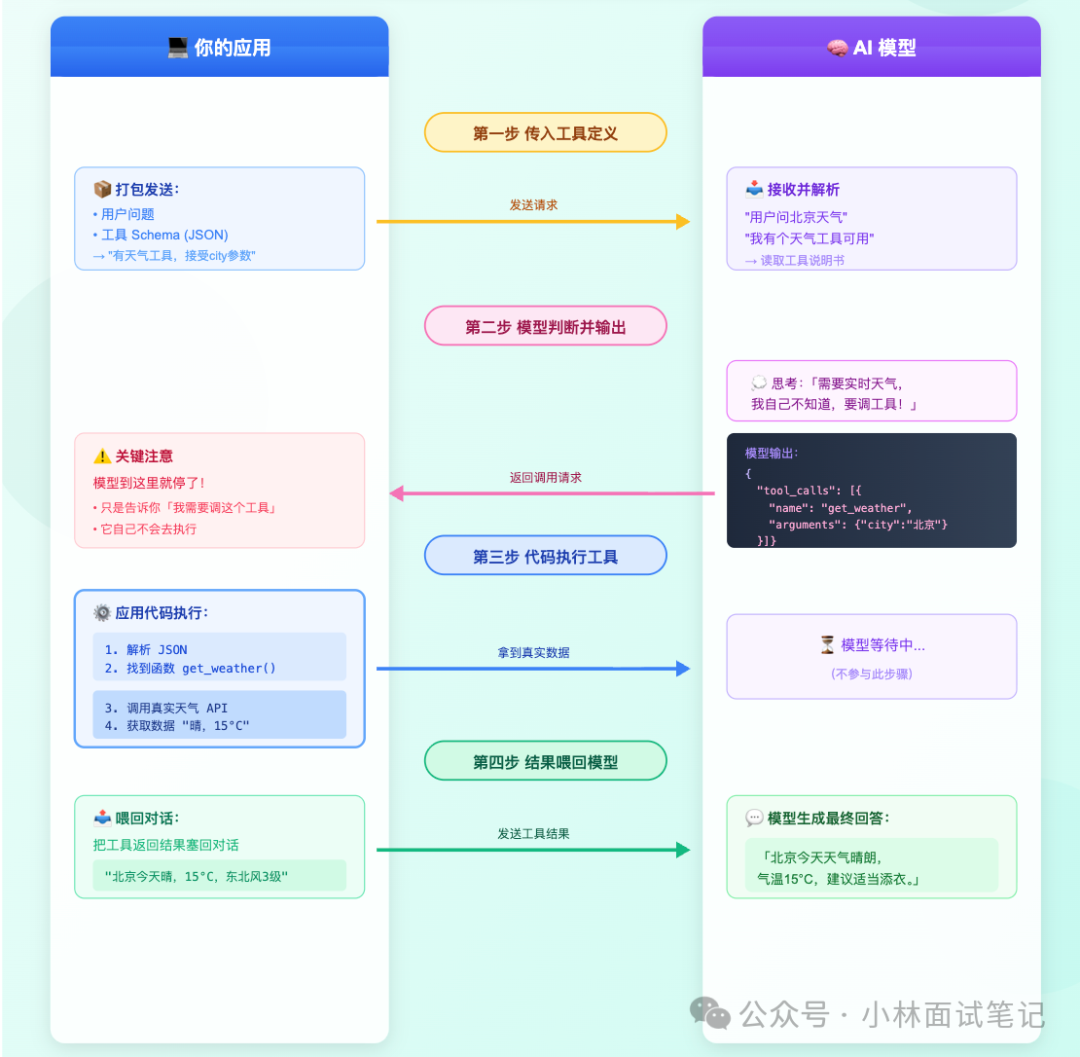
- 第一步,传入工具定义:你的应用程序代码将“有哪些工具可用”打包成JSON格式(称为schema,即工具的说明书),连同用户的问题一起发送给模型。例如告诉模型:“你现在有一个天气查询工具
get_weather,接受city参数,返回该城市的实时天气。”
- 第二步,模型判断并输出调用请求:模型读完工具定义和用户问题后,做出判断:这个问题需要查询实时天气,我自己不知道答案,需要工具帮忙。于是它不直接生成最终回答,而是输出一段结构化的JSON调用请求:
{
"tool_calls": [{
"name": "get_weather",
"arguments": {"city": "北京"}
}]
}
请注意:模型到这里就停止了! 它只是告诉你“我需要调用get_weather这个工具,参数是city: 北京”,它自己并不会去执行这个调用。
- 第三步,你的代码执行工具:你的应用程序代码负责解析这段JSON,找到代码中对应的
get_weather()函数,真正去调用天气API,并拿到实际的天气数据(如“晴,15°C”)。
- 第四步,把结果喂回给模型,模型生成最终答案:你将工具返回的结果(“北京今天晴,15°C,东北风3级”)作为一条新的消息塞回对话历史中。模型接收到这个结果后,才组织成一句通顺的自然语言回答用户:“北京今天天气晴朗,气温15°C,建议适当添衣。”
这套「模型输出结构化调用请求 -> 应用程序代码执行 -> 结果喂回模型生成最终回答」的机制,其专有名词就是 Function Calling。
换句话说,Function Calling 就是大模型工具调用能力在运行时的具体实现形式。
一个关键认知:模型只负责「决策」,不负责「执行」
这是理解工具调用最重要的一点。
模型在整个过程中只做了一件事:判断要调用哪个工具、参数填什么,然后把这个决策用JSON格式输出出来。真正去运行函数、访问网络、查询数据库的,是你写的宿主程序(应用程序)代码。
这个分工设计得非常合理:大语言模型擅长理解意图和逻辑推理,但它不应该(也通常没有权限)直接操作系统资源;而宿主程序负责安全地执行,可以进行权限控制、参数校验、沙箱隔离等安全措施。这样的设计使得工具调用既灵活又安全,是目前所有主流Agent和工具调用框架的核心设计原则。
希望这篇对大模型工具调用原理与实现的解析,能帮助大家在技术理解上更深入一层,不仅在面试中应对自如,在实际开发时也能知其所以然。如果你有更多相关问题或心得,欢迎在云栈社区与大家一起交流探讨。
 发表于 2026-3-14 03:37:42
|
查看: 147|
回复: 0
发表于 2026-3-14 03:37:42
|
查看: 147|
回复: 0
