最近有读者分享,在小红书的面试中被问到了一个关于Agent架构的基础问题:“Agent的基本架构由哪些核心组件构成?” 只回答“大模型+Prompt”显然是不够的,这直接关系到对智能体工作原理的深层理解。
💡 核心答案
一个完整的Agent系统通常包含四个核心组件:LLM(大模型)、工具系统、记忆系统和规划模块。
- LLM:是整个系统的大脑,负责理解任务、做出决策。
- 工具系统:是Agent与外部世界交互的“手脚”,使其能够执行搜索、运行代码、调用API等具体操作。
- 记忆系统:用于在任务执行过程中保持状态和记录历史,防止Agent“失忆”。
- 规划模块:负责将复杂的宏观目标拆解为一系列可执行的子步骤。
这四个组件协同工作,共同赋予了Agent自主理解、规划并完成任务的能力。
📝 详细架构拆解
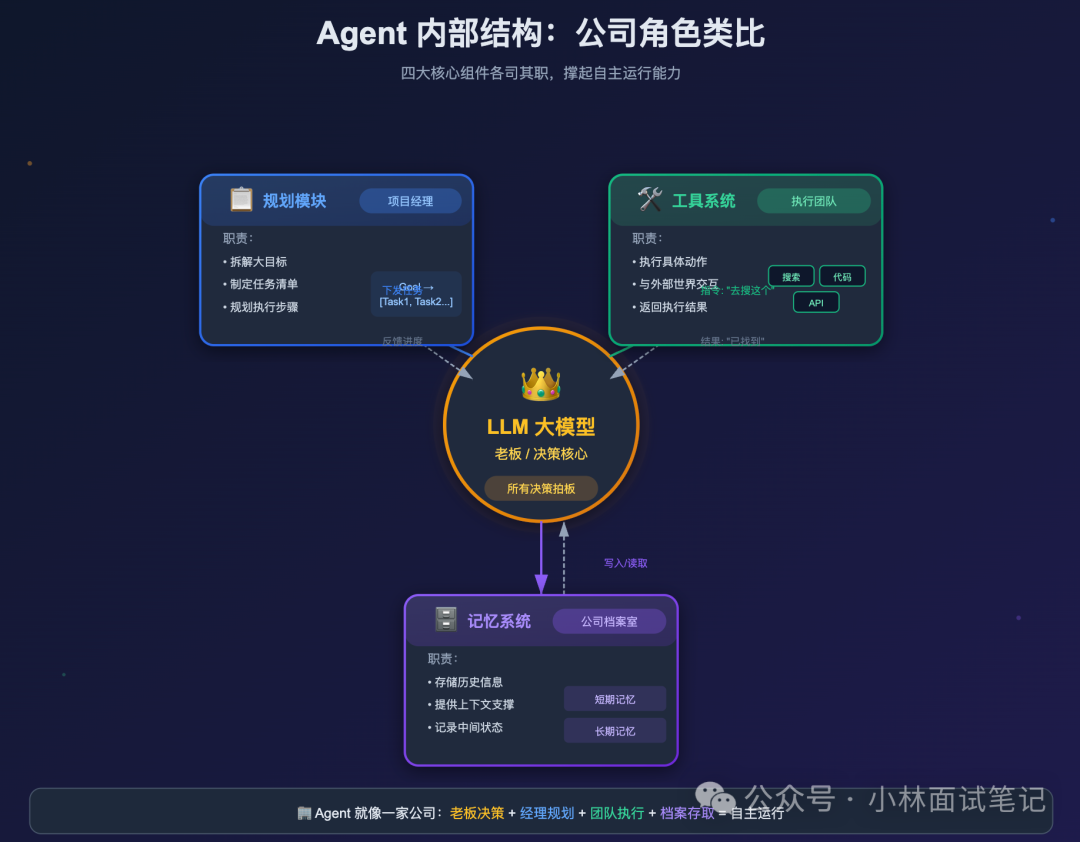
理解了Agent是什么之后,我们深入其内部,看看一个完整的智能体系统究竟由哪些核心部件构成。一个非常形象的类比是将其看作一家公司:
- LLM是老板,负责所有重大决策的最终拍板。
- 工具系统是外包执行团队,负责将老板的指令(如“搜索这个”、“发送邮件”)转化为实际行动。
- 记忆系统是公司的档案室,负责存储和调取各类历史信息与上下文。
- 规划模块是项目经理,拿到一个宏观目标后,负责将其分解为具体的、可执行的任务清单。
这四大角色各司其职,共同支撑起Agent的自主运行能力。
1. LLM核心:系统的大脑与决策中心
LLM是整个Agent的“大脑”。所有输入信息——无论是用户指令、工具返回的结果,还是从记忆中检索到的内容——最终都需要经过LLM的理解与处理。它的核心职责是判断:下一步该做什么? 是继续思考、调用某个工具,还是可以给出最终答案了?没有LLM这个统一的指挥中心,其他组件只是一堆无法协同的零件。
2. 工具系统:与外部世界交互的桥梁
工具系统是Agent突破其“纯语言模型”局限,与外部环境互动的唯一途径。LLM本身无法直接上网、读取文件或执行代码,这些能力都通过“工具”来扩展。任何可以用函数封装的能力,如搜索引擎、数据库查询、代码执行器或邮件API,都可以被定义为一个工具。
工具是如何定义的呢?这里以OpenAI的function calling格式为例,展示一个标准定义:
# 定义工具的结构(以 OpenAI function calling 格式为例)
# 你只需要告诉模型三件事:工具叫什么名、能做什么事、需要哪些参数
tools = [
{
"type": "function",
"function": {
"name": "search_web",
"description": "搜索互联网上的信息",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词"
}
},
"required": ["query"]
}
}
}
]
# LLM 决定调用工具时,会返回类似这样的结构:
# {"tool_call": {"name": "search_web", "arguments": {"query": "2024年大模型最新进展"}}}
# 然后你的代码负责真正执行这个搜索,把结果再塞回给 LLM
可以看到,工具定义本身并不包含具体的执行逻辑,它只是一份“说明书”,说明了工具的名称、功能和所需参数。模型阅读这份说明书后,决定调用哪个工具以及填入什么参数,并以结构化数据(如JSON)的形式告知程序。程序则负责真正的执行,并将结果反馈给模型。整个过程分工明确:模型负责“决定做什么”,程序负责“具体执行”。这正是当前人工智能领域实现工具调用的核心范式。
3. 记忆系统:维持状态与记录历史
记忆系统通常分为两层,可以类比人类的记忆方式来理解:
- 短期记忆:相当于当前对话或任务执行的上下文,存储在模型的上下文窗口(context window)中。它用于记录任务执行过程中的中间状态,例如第一步搜索到了什么、第二步的执行结果是什么。这类似于人的“工作记忆”,容量有限,且任务结束后通常会被清空。
- 长期记忆:通常借助向量数据库等技术实现。将重要的信息转换为向量(embedding)后存储起来,需要时通过语义检索召回。这类似于人的“长期记忆”,容量大、可持久化,但需要主动“回忆”(检索)才能调取。
4. 规划模块:复杂任务的拆解引擎
规划模块决定了Agent能否有效处理复杂任务。对于一个简单指令,Agent可能一步就能响应。但如果要求是“帮我写一份竞品分析报告”,这就需要拆解:搜索竞品资料 -> 整理关键数据 -> 对比分析 -> 撰写报告。规划模块的职责正是完成这种任务分解。有些实现是让LLM先生成一个完整的计划再逐步执行(规划后执行),有些则是边执行边根据结果动态调整计划(执行中规划)。
🔄 核心运作流程:组件如何协同?
这四个组件是如何组合在一起并运转起来的呢?通过下面这段伪代码,你可以清晰地理解它们的协作流程:
# Agent 运行的核心 loop(伪代码)
def agent_run(user_goal: str):
# 第一步:规划模块上场,把目标拆成步骤列表
plan = llm.plan(user_goal)
memory = [] # 短期记忆,用来存每一步的中间结果
for step in plan:
# 第二步:LLM 核心做决策,这一步该怎么做?
action = llm.decide(
step=step,
history=memory, # 把短期记忆传进去,让它知道之前做了什么
long_term=vector_db.search(step) # 从长期记忆里捞出相关历史
)
if action.type == "tool_call":
# 第三步:工具系统负责真正执行
result = tools.execute(action.tool_name, action.args)
memory.append({"step": step, "result": result}) # 执行结果存入短期记忆
elif action.type == "final_answer":
return action.content # LLM 判断任务完成,返回最终答案
通过这段伪代码,我们可以看到Agent的核心运行节奏其实是一个清晰的循环:规划 -> 决策 -> 执行 -> 结果存入记忆 -> 再决策...,如此往复,直至任务完成。在这个过程中,LLM始终扮演决策者的角色,工具系统是命令的执行者,记忆系统确保了状态的连续性,而规划模块则为处理宏大目标提供了清晰的路线图。
市面上主流的Agent开发框架,如LangChain、LlamaIndex、AutoGen等,其设计本质都是围绕这四大核心组件进行的,只是在封装方式、易用性和侧重点上有所不同。理解这个基础架构,是进行更深入的智能体开发或应对相关面试求职中技术考察的关键第一步。
 发表于 2026-3-14 03:40:32
|
查看: 134|
回复: 0
发表于 2026-3-14 03:40:32
|
查看: 134|
回复: 0
