资产定价中最根本的问题,是理解为什么不同资产具有不同的平均收益率。无套利定价理论给出了明确答案——预期收益之所以不同,是因为资产对系统性风险的暴露不同。所有定价信息都可以概括为随机贴现因子(Stochastic Discount Factor, SDF)或定价核。过去40年来,资产定价领域的实证研究一直致力于估计一个能够解释所有资产预期收益的随机贴现因子。
现有文献在单一模型中面临四个主要挑战:
- SDF在构造上可能依赖于所有可获得的信息,因此是一个关于大量变量的函数。
- SDF的函数形式未知且可能十分复杂。
- SDF可能具有复杂的动态结构,个别资产的风险暴露会随经济状况和资产特征变化而随时间变动。
- 个股风险溢价的信噪比较低,使得估计能够解释所有股票预期收益的SDF变得困难。
模型方法简介
本文基于大量宏观经济和公司特征信息,利用全部美国股票数据,通过深度学习神经网络估计一个一般性的非线性资产定价模型。我们的关键创新是在神经网络算法中引入无套利条件。我们根据无套利所隐含的条件矩约束,估计能够解释所有股票收益的随机贴现因子。深度学习等机器学习方法自然适用于处理高维问题。本研究的重要洞见是,必须将经济条件纳入机器学习框架。在学习算法中加入无套利约束显著增强了风险溢价信号,使解释个股收益成为可能。
资产定价与最优投资是一体两面。求解SDF等价于获得条件均值—方差有效投资组合。资产对SDF的暴露可以预测未来预期收益,并可直接用于交易策略。我们的估计方法创新性地结合了无套利定价与三种神经网络结构:
- 利用前馈神经网络(FFN)刻画SDF关于信息集合的一般函数形式。
- 通过长短期记忆网络(LSTM)识别少量宏观经济状态过程,以刻画SDF的时间变化。
- 利用生成对抗网络(GAN) 识别包含最多未解释定价信息的状态和投资组合,从而实现对所有资产的定价。
- 无套利约束有助于分离风险溢价信号与噪声,并作为正则化工具识别相关定价信息。
当将SDF限制为线性函数形式时,模型退化为具有时变载荷的线性因子模型。此时估计量选择基于公司特征的多空因子线性组合,因子载荷是时变特征的线性函数。一般情况下,我们允许更灵活的函数形式,捕捉因子权重和载荷对公司特征与宏观变量的任意非线性与交互效应。
美国股票的实证结果
数据说明
A.1 收益率与公司特征变量
我们从CRSP收集了所有证券的月度股票收益数据。样本期为1967年1月至2016年12月,共计50年。我们将全部数据划分为20年的训练样本(1967–1986)、5年的验证样本(1987–1991)以及25年的样本外测试样本(1992–2016)。我们使用Kenneth French数据库中的一个月期国库券利率作为无风险利率,以计算超额收益。
此外,我们收集了Kenneth French数据库中列示的或Freyberger等(2017)所使用的46个公司特征变量。所有这些变量均由CRSP/Compustat数据库中的会计变量或CRSP中的历史收益构建而成。
CRSP中所有可获得的股票数量约为31,000只。与Kelly等(2018)或Freyberger等(2017)类似,我们仅使用在某一月份具有全部公司特征信息的股票收益数据,这使样本规模约为10,000只股票。图1展示了每个月可用股票的数量。
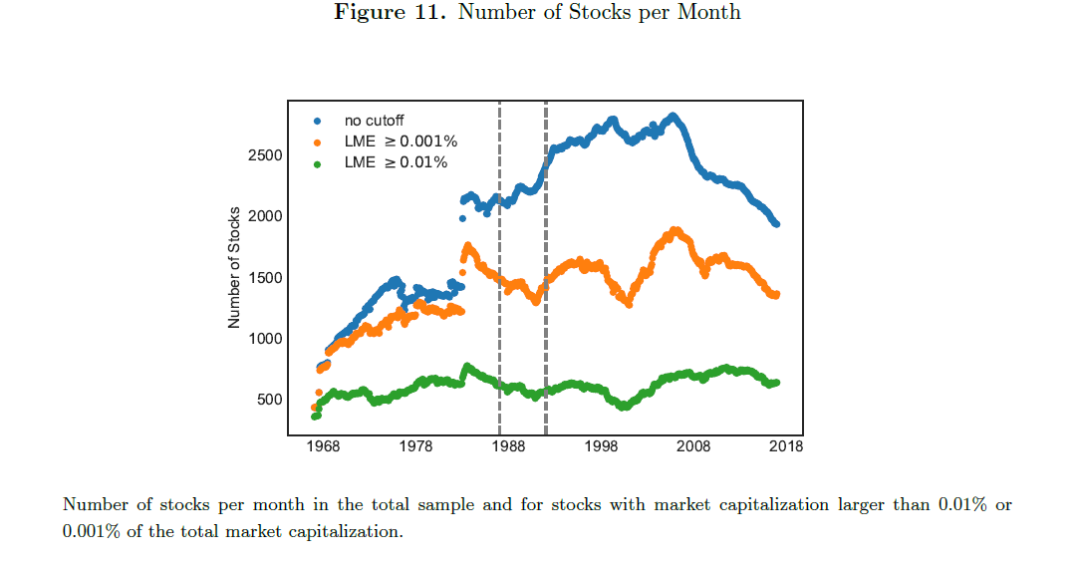
对于每个月的每一个特征变量,我们在横截面上对其进行排序,并将其转换为分位数。这是一种处理不同量纲的标准变换方法。
A.2 宏观经济变量
我们从三个来源收集了178个宏观经济时间序列。我们从FRED-MD数据库中获取了124个宏观经济预测变量。接着,我们为每个46个公司特征增加了横截面中位数时间序列。第三,我们补充了Welch和Goyal(2007)提出的8个宏观经济预测变量。
我们对时间序列数据应用了标准变换,以获得平稳时间序列。
性能表现分析
GAN的SDF因子在样本外表现出更高的夏普比率,同时解释了更多的收益变异性和定价能力,相比其他基准模型表现更优。表1报告了四种模型(LS线性、EN弹性网、FFN前馈网络、GAN生成对抗网络)的三个主要性能指标:夏普比率(SR)、解释变异(EV)和横截面R²。
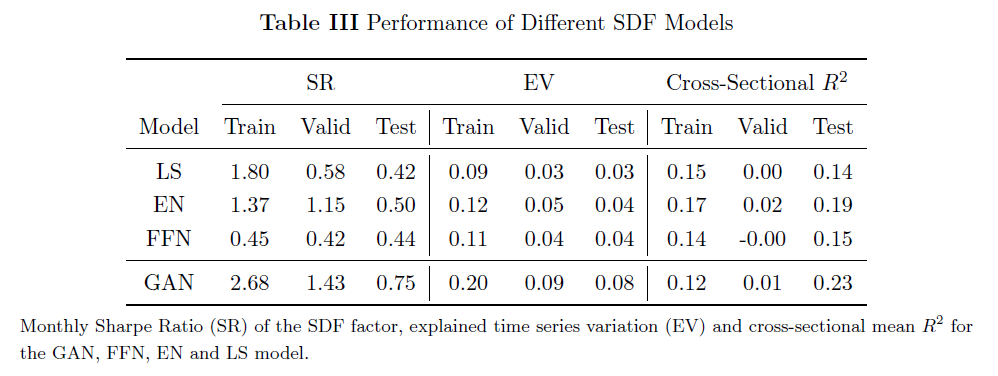
GAN的年度样本外夏普比率约为2.6,几乎是简单预测方法FFN的两倍。GAN能捕捉非线性和交互结构,使其相比正则化线性模型的表现提升约50%。因此,更灵活的模型形式确实重要,但设计得当的线性模型也能取得令人印象深刻的表现。样本内结果存在过拟合,但GAN的年度样本内夏普比率高达9.3,明显突出。
非正则化线性模型在解释变异和定价误差方面表现最差。GAN能解释个股收益8%的变异,是其他模型的两倍;其横截面R²为23%,也远高于其他模型。有趣的是,基于无套利目标函数的正则化线性模型在时间序列和横截面收益的解释上至少与不含无套利条件的灵活神经网络同样出色。
图2总结了以隐藏宏观经济状态变量为条件的效果。
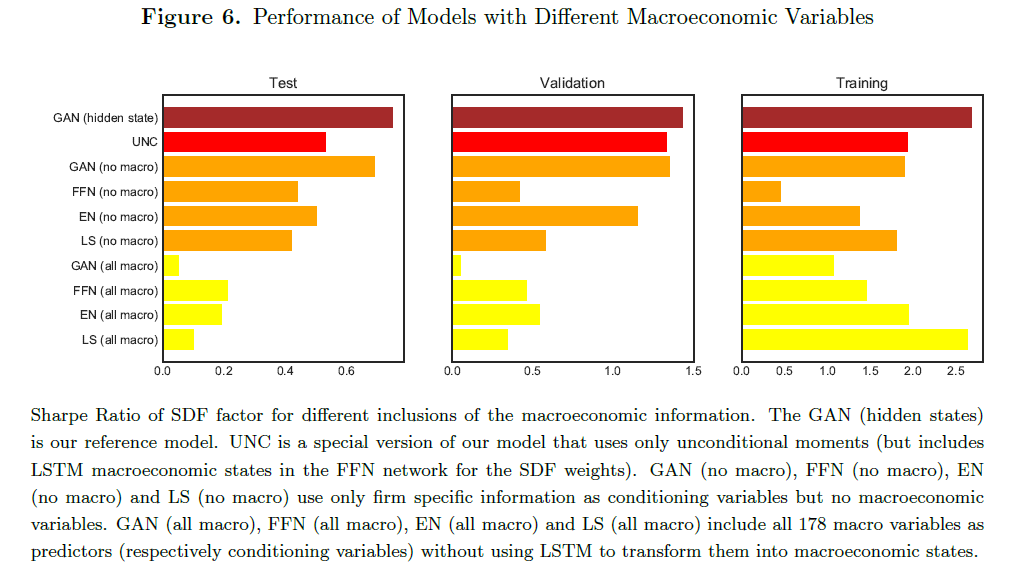
首先,我们将178个宏观经济变量作为预测变量加入所有网络,而不降维到隐藏状态变量。此时LS、EN、FFN和GAN的样本外夏普比率表现完全崩溃。原因在于,仅以宏观经济变量的最后一次标准化观测作为条件,无法捕捉动态结构,例如商业周期。
夏普比率下降表明,仅使用过去宏观信息会丢失有价值的信息。更糟的是,加入大量无关变量实际上会降低模型表现,相比完全不使用宏观信息的模型更差。尽管模型采用了某种正则化,过多的无关变量仍会干扰挑选真正相关变量。
样本内训练数据的结果显示,当加入大量宏观经济变量时,模型完全过拟合。FFN、EN和LS在不使用宏观信息时表现更好,因此我们选择它们作为对比基准模型。GAN仅使用公司特征变量而不使用宏观变量时,其样本外夏普比率比使用宏观隐藏状态低约10%,这进一步表明包含时间序列动态是必要的。
变量重要性分析
SDF因子的结构是什么?作为第一步,在图3中,我们计算了不同方法所推导出的各因子之间的相关性。很明显,每个模型的因子都是不同的。我们的GAN因子与弹性网(EN)因子的相关性最高,也就是说,它与基于同一模型但限制为线性形式的因子相关性最高。GAN因子与市场因子(Mkt)的相关性仅为8%。令人惊讶的是,FFN因子与市场因子的相关性却超过70%。
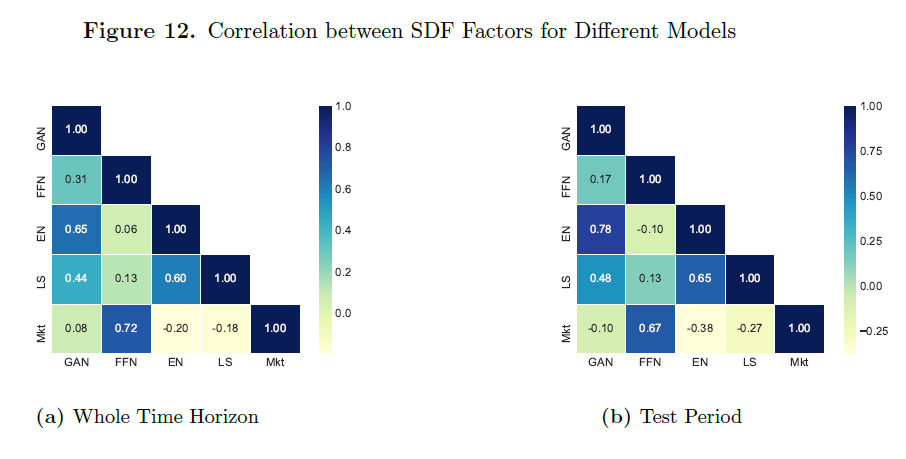
作为第二步,我们将GAN因子与Fama-French五因子模型进行比较。五个因子中没有一个与我们的因子有较高相关性,其中盈利能力因子与我们的因子的相关性最高,为17%。接下来,我们进行时间序列回归,用Fama-French五因子解释GAN因子投资组合。结果显示,只有市场因子和盈利能力因子具有显著性。回归中显著的定价误差表明,这些因子未能捕捉我们SDF投资组合中的定价信息。
我们展示了隐藏的宏观经济状态与商业周期及整体经济活动密切相关。图4绘制了四个隐藏宏观经济状态变量的时间序列。这些变量是从LSTM输出的,LSTM对宏观经济信息的历史进行了编码。灰色阴影区域表示NBER(美国国家经济研究局)定义的经济衰退期。
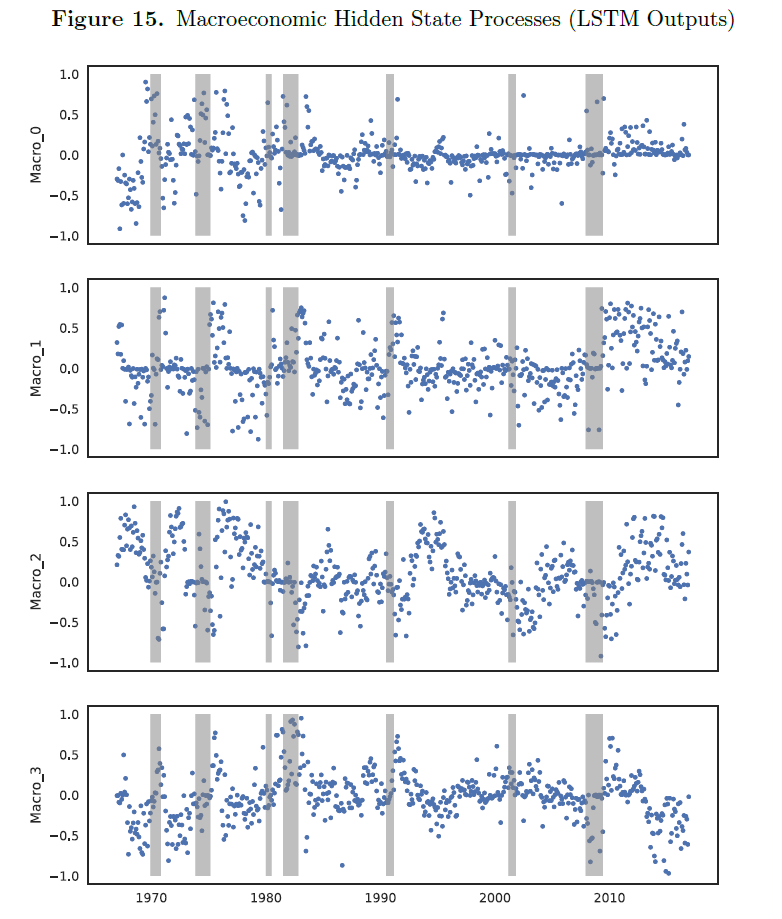
首先,很明显,状态变量,特别是第三和第四个状态,在经济衰退期间达到峰值。其次,这些状态过程似乎具有周期性行为,这验证了我们的直觉:相关的宏观经济信息很可能与商业周期相关。不同状态变量的周期和峰值并不总是完全一致,这表明它们捕捉的是不同的宏观经济风险。
结论与启示
我们提出了一种新的方法来估计个股收益的资产定价模型,该方法能够利用大量条件信息,同时保持完全灵活的函数形式并考虑时间变化。为此,我们以一种创新方式结合了三种不同的深度神经网络结构:前馈神经网络用于捕捉非线性关系;循环(LSTM)网络用于识别一小组经济状态过程;生成对抗网络用于识别包含最多未被解释定价信息的投资组合策略。我们的关键创新在于将无套利条件纳入神经网络算法之中。
我们的主要结论可以概括为四点:
- 机器学习的潜力:我们展示了机器学习方法在资产定价中的潜力。我们能够在比传统计量经济学方法更一般的函数形式下、更高的精度上识别驱动资产价格的关键因素及其函数关系。
- 无套利约束的重要性:我们展示并量化了在机器学习资产定价模型估计中纳入无套利条件的重要性。采用深度学习的“全变量”预测方法并不优于带有无套利约束的线性模型。
- 时间维度处理:金融数据具有时间维度,必须相应地加以考虑。我们表明,宏观经济状况对资产定价具有重要意义,并且可以由少数几个经济状态变量加以概括,而这些状态变量依赖于所有时间序列的整体动态。
- 线性与非线性:资产定价在某种意义上出人意料地“线性”。只要我们单独考察异常现象,线性因子模型就能提供良好的近似。然而,资产定价所面临的多维挑战无法通过线性模型解决,而需要另一套工具。
我们的结果对资产定价研究者具有直接实践意义。我们提供了一组新的基准测试资产和一组概括了与资产定价相关宏观经济信息的隐藏状态时间序列。最后,我们的模型对投资者和投资组合管理者具有直接价值。模型的主要输出是风险度量与SDF因子权重,它们是公司特征和宏观经济变量的函数。基于估计,即使某项资产没有长期时间序列数据,模型使用者也可以为其分配风险度量及其投资组合权重。
这项研究展示了将前沿的深度学习技术与严谨的金融经济理论(如无套利原理)相结合所能产生的强大力量。对于希望深入探索大数据在金融领域应用的技术人员与研究者而言,这无疑是一个值得深入研究的范本。更多关于人工智能与量化金融的深度讨论,欢迎访问云栈社区的智能 & 数据 & 云与人工智能板块进行交流。
 发表于 2026-3-15 05:08:12
|
查看: 223|
回复: 0
发表于 2026-3-15 05:08:12
|
查看: 223|
回复: 0
