这次我想复现一个来自兴业证券金工首席郑兆磊老师的因子,源自他于2022年8月29日发布的研报《高频研究系列四:成交量分布中的Alpha》。
此前,我已经尝试过这篇研报里的几个因子,比如与同价成交量相关的,以及一系列关于成交量分布的Alpha因子。今天的主角是成交量极大值分布因子。(研报中还有个成交量分桶熵因子,我还没介绍)
为什么把这个因子留到了一年之后?因为一年前,我也没太搞明白它的计算逻辑。即便是现在,我也不能说完全吃透了,更多是凭着对方法的理解和感觉尝试了一遍。不过,从结果看效果并不差,所以值得写篇文章分享一下。
值得一提的是,同价成交量和成交量分桶熵这两个因子在《因子日历》上是出现过的,但成交量极大值分布这个因子一直没有。我这次尝试也算是一次小小的探索。
关于这个因子的具体逻辑,研报用了大半页来阐述,这里就不全文引用了。我只摘录其中一句核心观点:
因子值越大,说明该股在近一段时间内成交量极大值的分散程度较大,股价曾经或正在出现成交量多次过大,或极值差异明显。此时个股不稳定性极高,整体下行风险较大。
计算步骤与代码实现
说实话,研报里并没有给出像烹饪食谱一样具体的计算步骤,只是提到了会用到Bootstrap重采样这个方法。
我对这个方法还算熟悉,它的核心就是从原始数据中有放回地随机抽取样本,重复多次(比如n次),然后计算这些抽样数据的统计量(如均值)。一个有趣的性质是,当n足够大时,任何一个原始数据点大约有1/e的概率从未被抽中。
基于对研报描述的理解,我梳理了以下实现思路:
1. 总体分析
- 第一步:对每个股票的分钟成交量序列进行Bootstrap重采样,以得到“极大值样本数据”。这里我有个疑惑:是按成交量占比加权采样,还是等权采样?如果是等权,如何体现“极大值”的采样倾向?研报没说清楚,我暂时按照等权采样来实现。
- 第二步:将采样得到的数据减去其自身的均值后,再计算这些“中心化”后数据的均值,得到第一个因子。该值越大,理论上说明该股票成交量极值出现的次数相对较多,且骤增的量较大。
- 第三步:同样是“中心化”后的数据,计算其标准差,得到第二个因子。该标准差越小,说明该股票成交量极大值的量级相对均衡,极值部分差异较小。
2. 代码
实现的关键在于Bootstrap重采样。好在pandas库提供了便捷的sample方法,让代码不至于太复杂。
def process_single_day(self, idx):
# 加载当日分钟数据
file_name = self.files[idx]
date_str = file_name.split('.')[0]
cur_time = pd.to_datetime(date_str) + timedelta(hours=15)
file_name = self.files[idx]
full_path = os.path.join(self.file_pth, file_name)
data = BaseDataLoader.load_data(full_path, fields=['volume']).to_dataframe('volume')
resample_data = []
for i in range(1000):
new_data = data.iloc[:]
resample_data.append(new_data.sample(2400, replace=True).mean())
resample_data = pd.concat(resample_data, axis=1)
resample_data = resample_data - resample_data.mean(axis=1).values.reshape(-1, 1)
res = [resample_data.mean(axis=1), resample_data.std(axis=1)]
res = pd.concat(res, axis=1)
res.columns = ['resample_mu', 'resample_sigma']
res['datetime'] = cur_time
return res
- 第1-8行:读取指定日期的分钟成交量数据。
- 第9-12行:执行Bootstrap重采样1000次。每次采样2400个数据点(假设一日有240分钟),并计算这次采样数据的均值。循环结束后,得到一个包含1000个“采样均值”的数据集。这里也有另一种理解:先将所有重采样的原始数据拼在一起,再整体做中心化和计算统计量。理论上我应该都尝试一下,但单次计算就需要近10小时,时间成本太高了。
因子评价
这两个因子的相关性几乎为0,所以相关性图就省略了。
研报中提到,使用过去15个交易日的标准差将因子低频化。为了与我之前的所有因子评价标准保持一致,我选择了过去21个交易日的标准差。
从IC分析来看,两个因子的表现比较接近。因此,在展示具体的收益分析前,我将主要展示 resample_sigma 这个因子的评价结果。而在收益分析部分,则会同时展示两个因子的表现。
01 IC分析
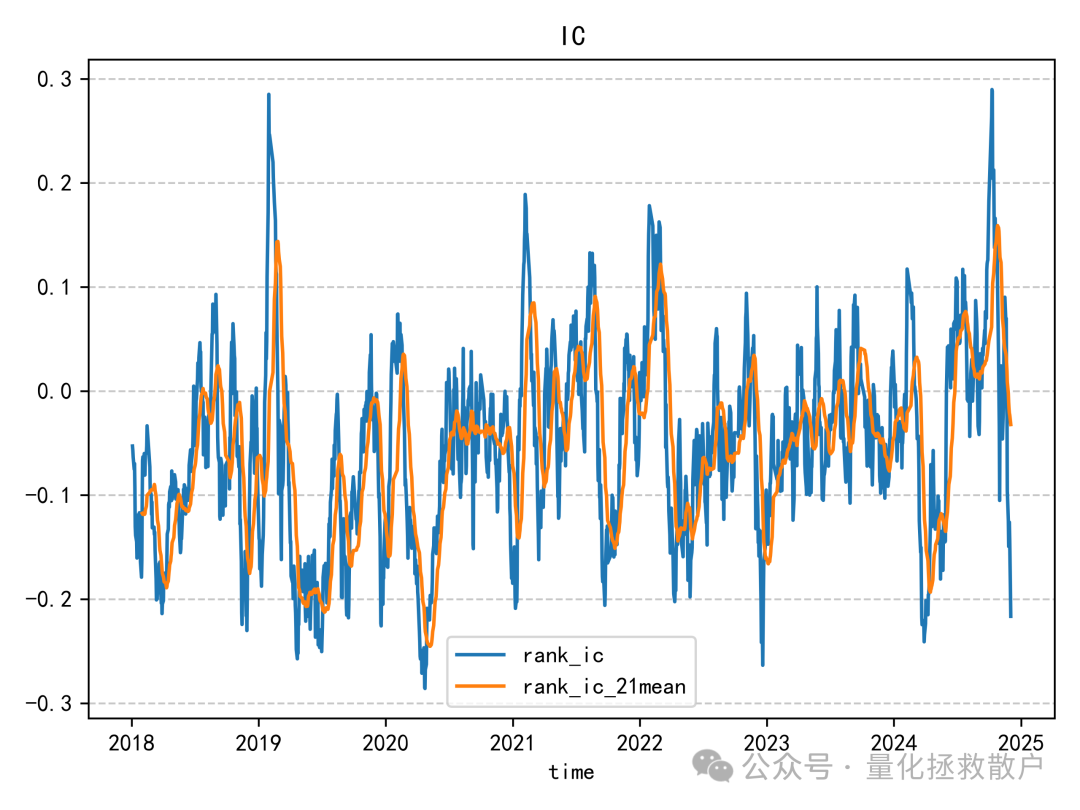
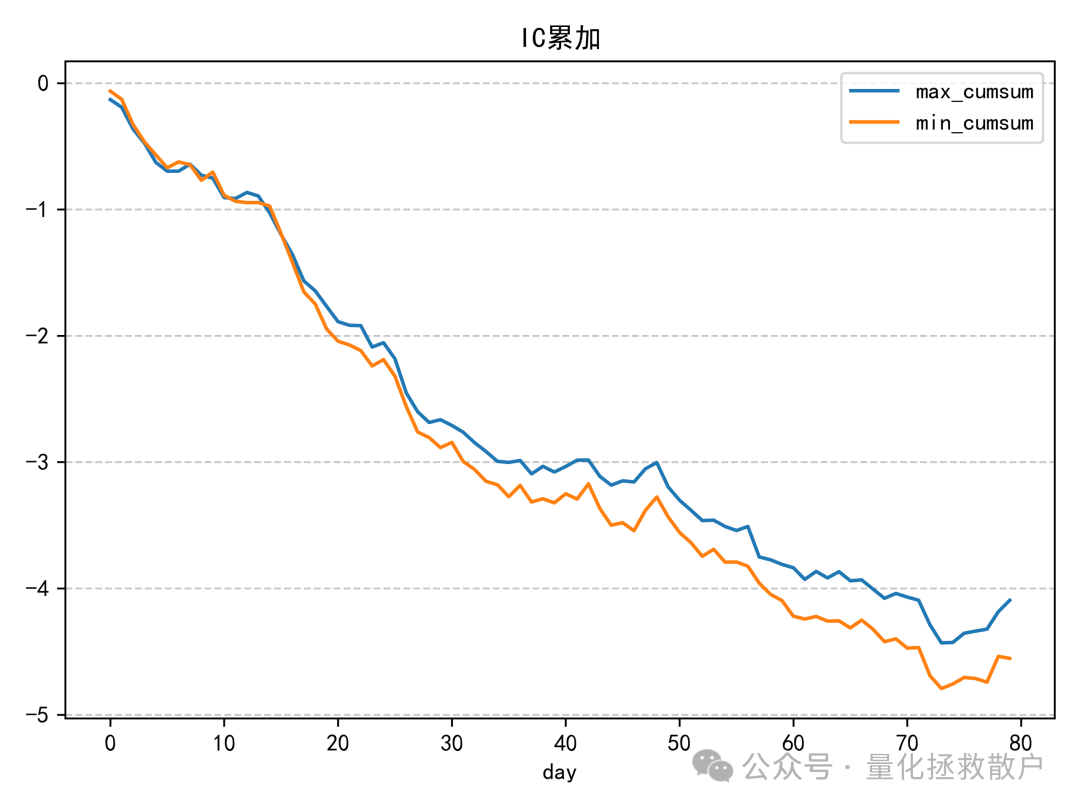
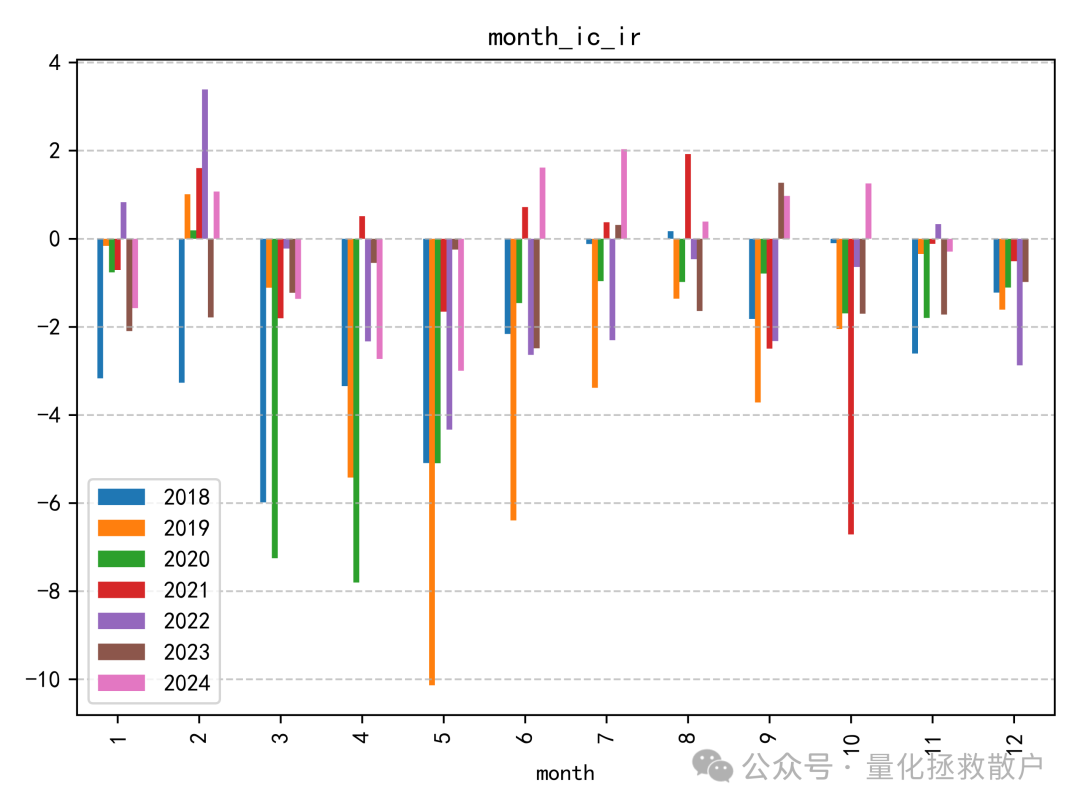
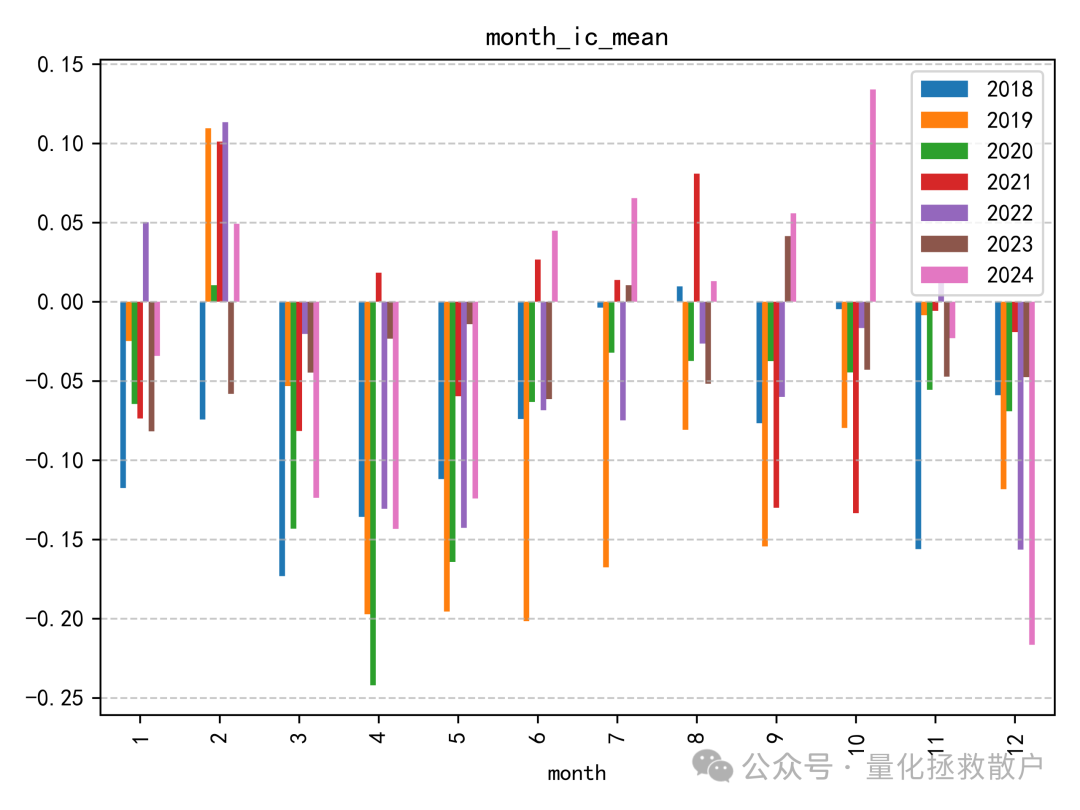
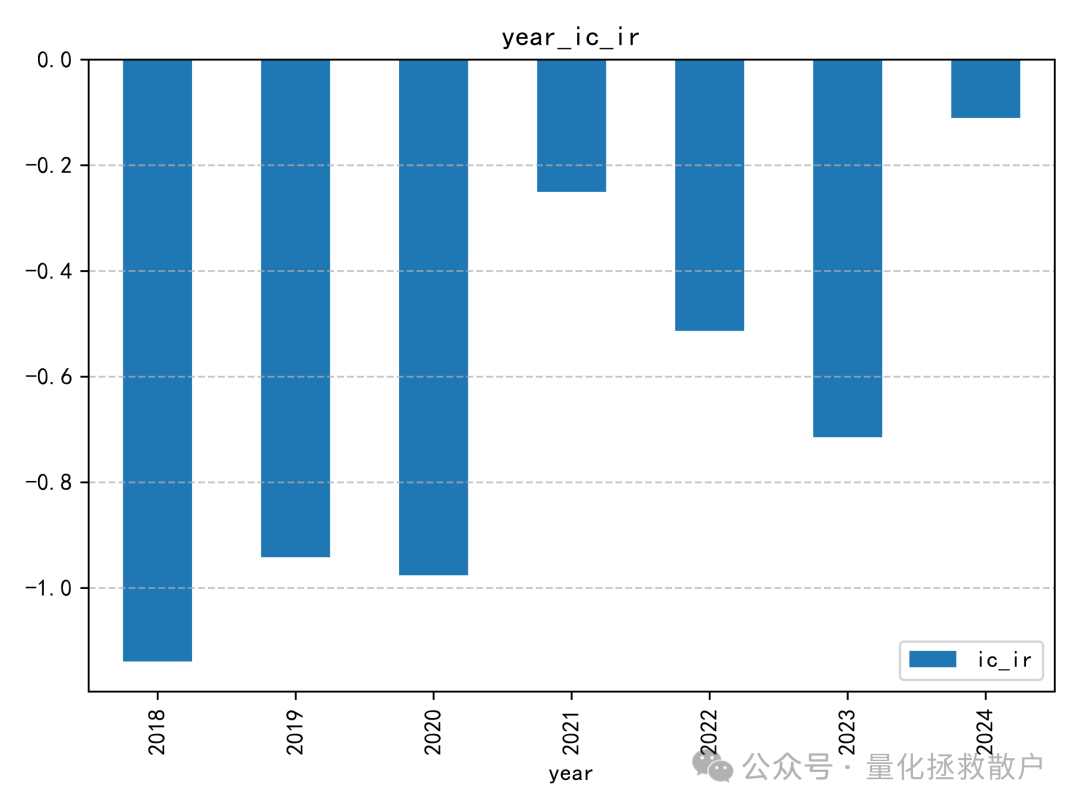
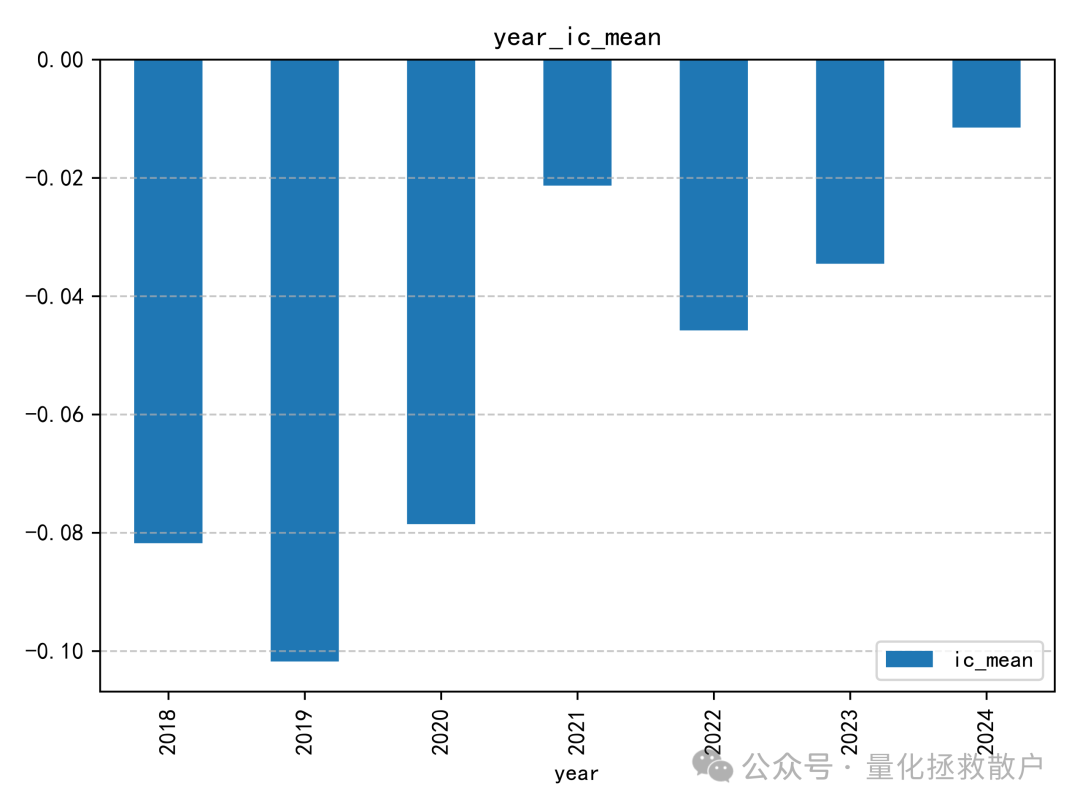
从IC来看,这个因子在2018年至2020年间表现出一定的有效性,但自2021年起,效果似乎开始减弱甚至失效。这种随时间变化的现象在因子挖掘过程中很常见,值得深入分析其失效的原因。
02 回归分析
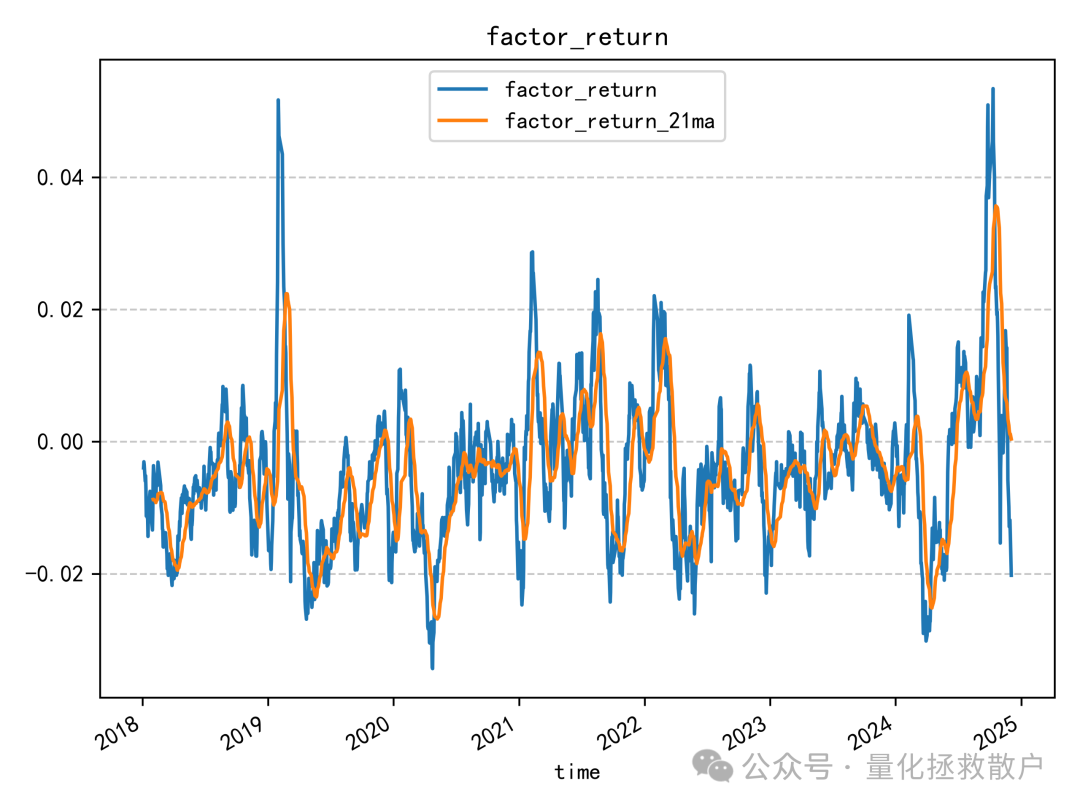
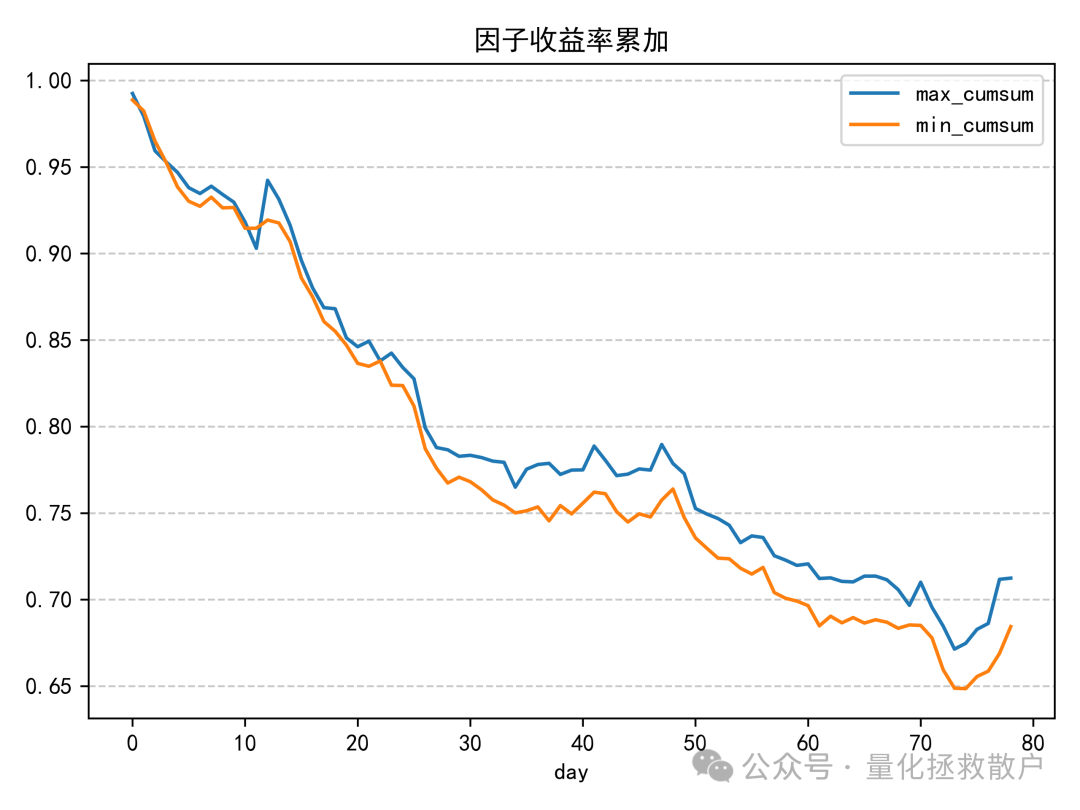
03 换手率分析
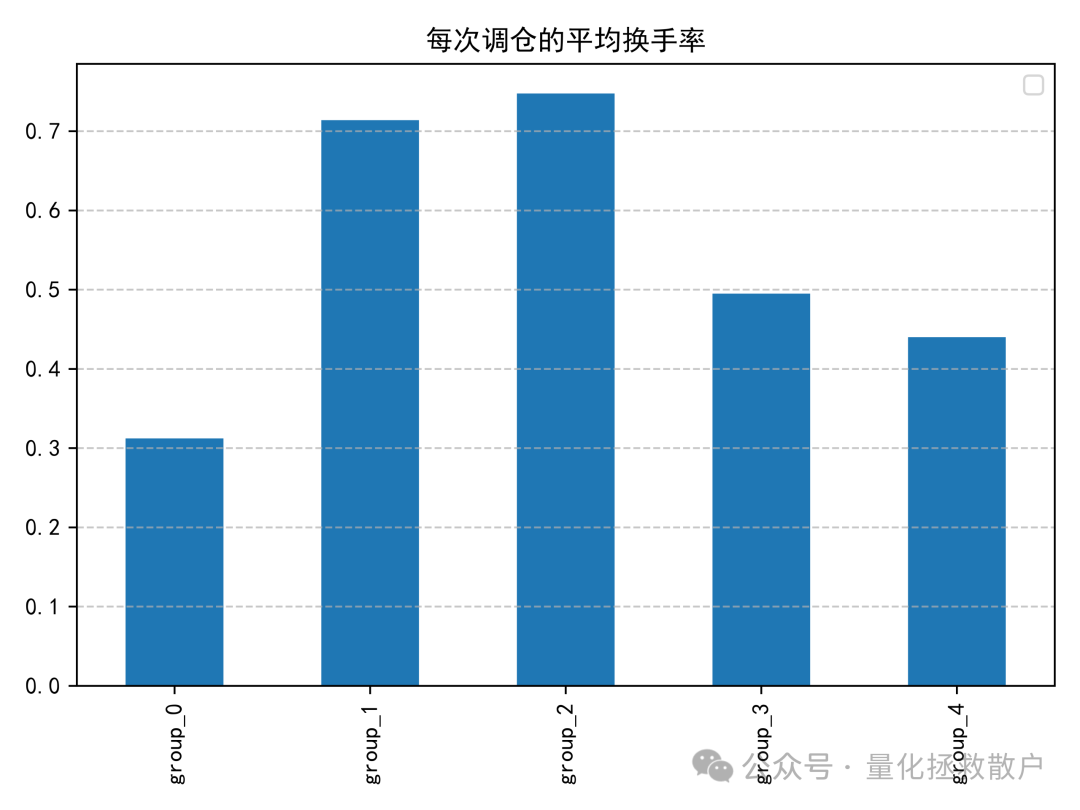
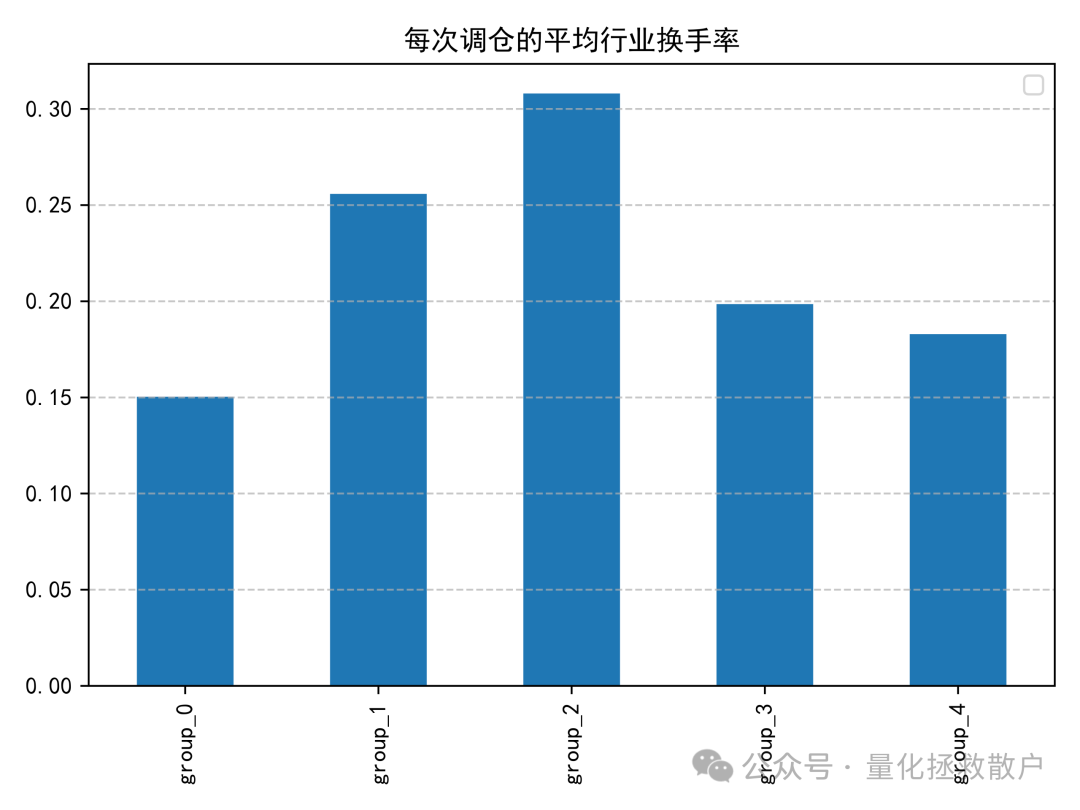
04 收益分析
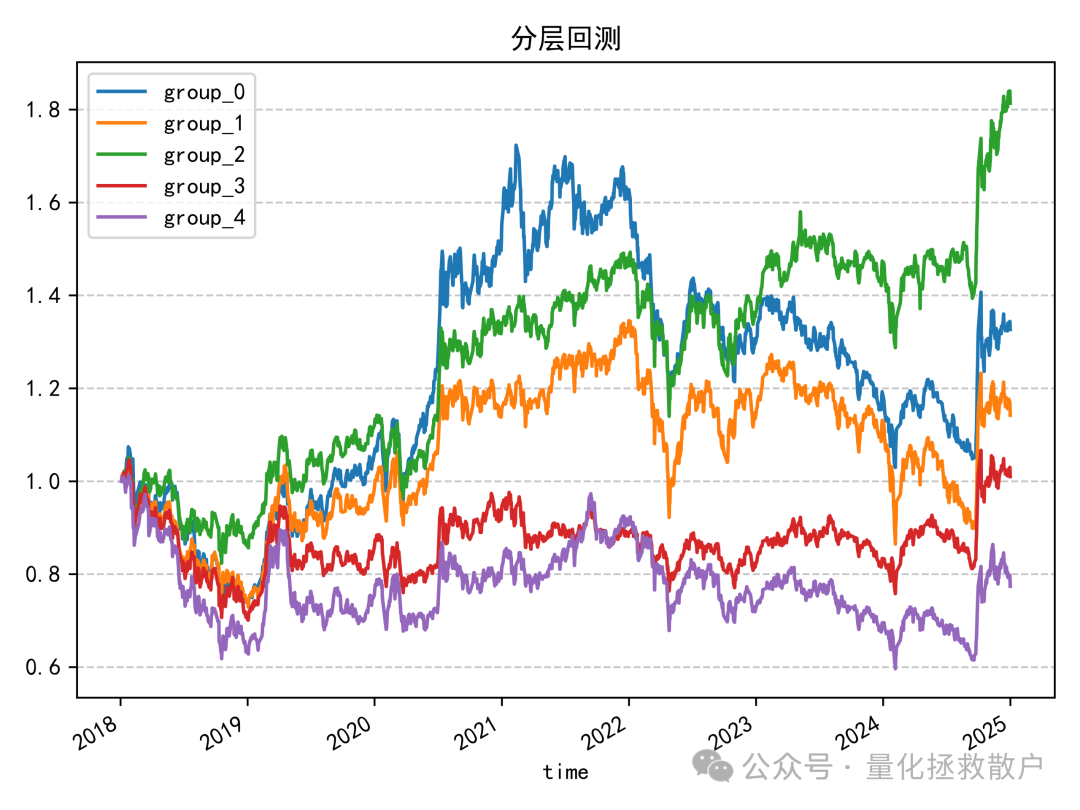
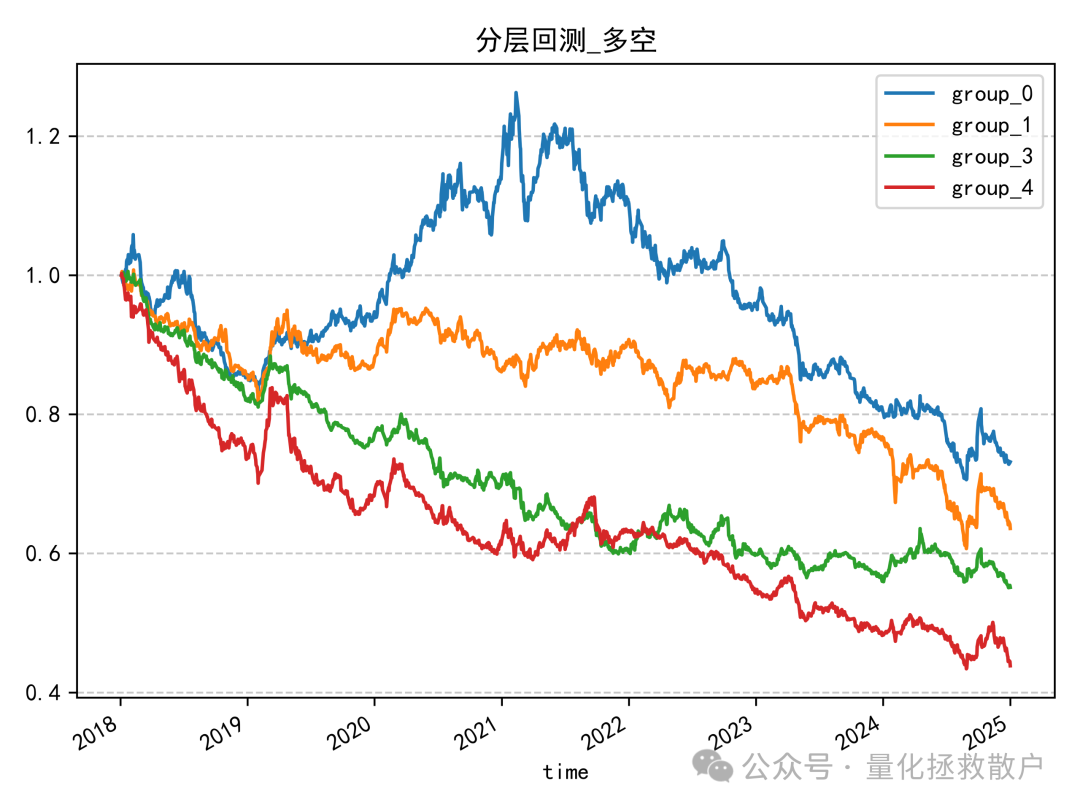
首先看 resample_sigma 因子(使用标准差低频化)的分层回测结果:

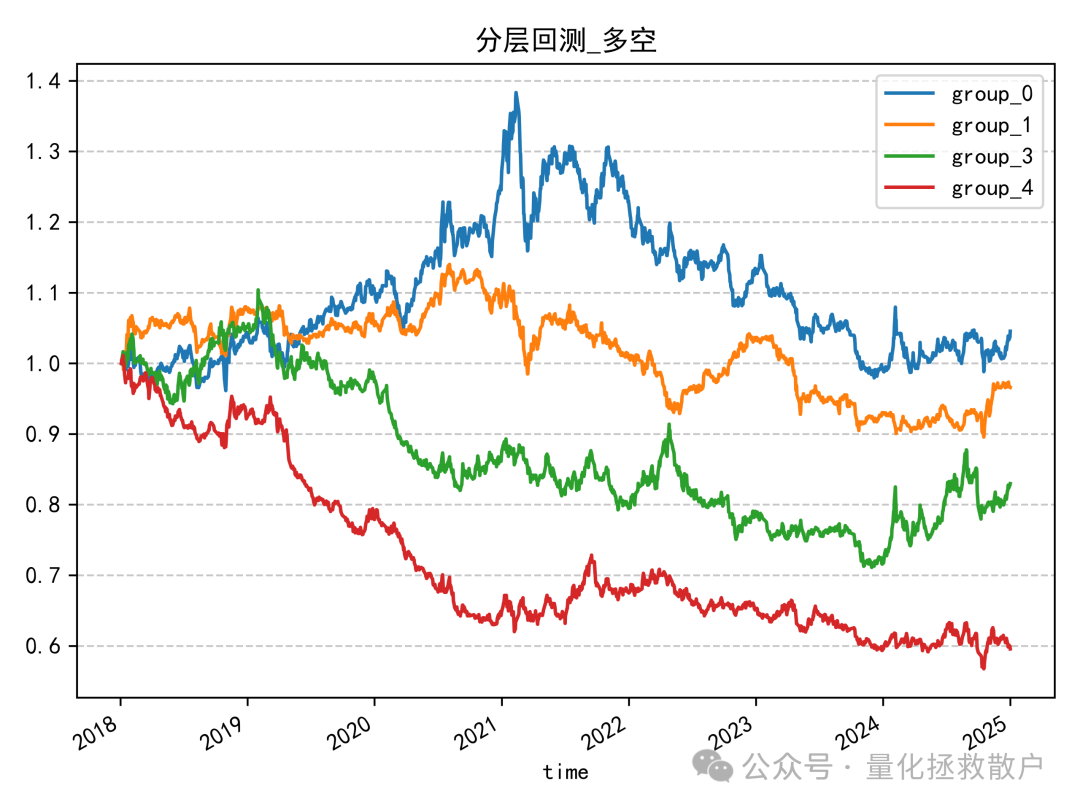
从分层回测来看,主要的超额收益是在2020年积累的。resample_mu 因子的表现也类似:

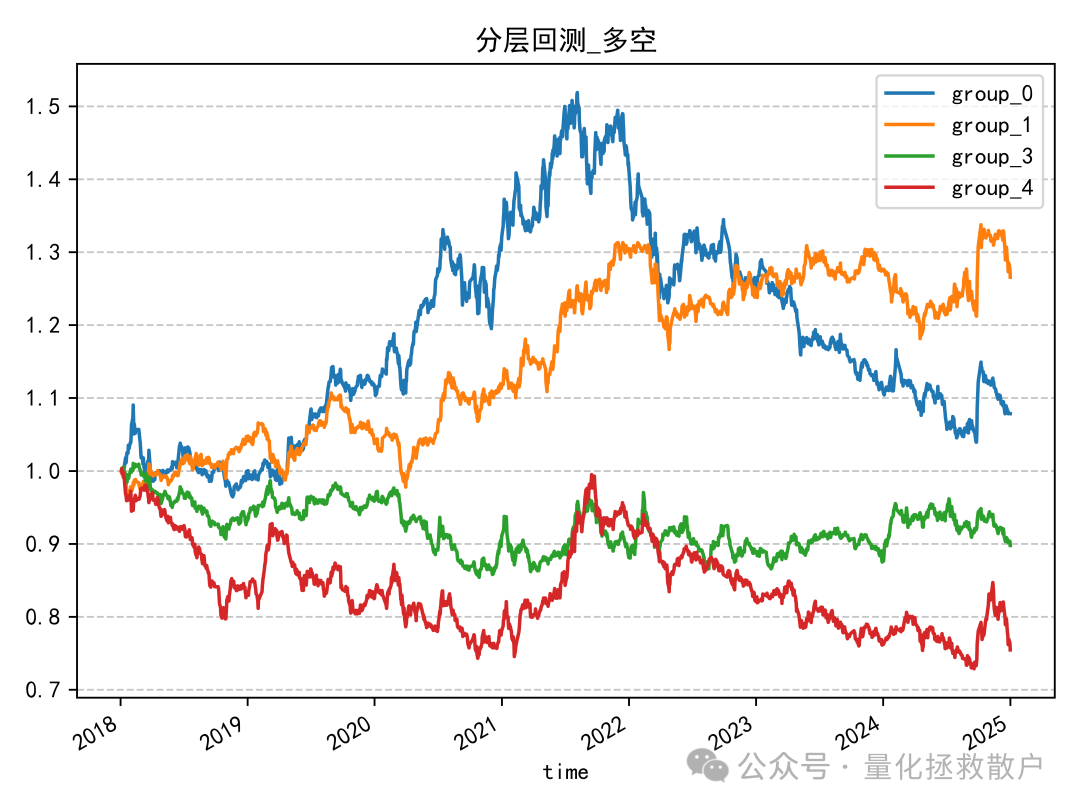
即使是使用均值(而非标准差)进行低频化处理的 resample_sigma 因子,其表现也差不多。(而 resample_mu 因子用均值低频化则效果不佳)
由于这次复现包含了较多基于个人理解的猜测和尝试,其结果必然与原始研报存在出入。不过,这个过程本身对于理解大数据背景下的复杂因子构建逻辑很有帮助。复现顶尖机构的研报确实很烧脑,但也充满了挑战和乐趣。希望这份带有实践性质的复盘,能为同在量化领域探索的朋友们提供一些不一样的视角和启发。如果你对这类因子的构建、回测以及更深入的数据分析话题感兴趣,欢迎在云栈社区交流讨论。
— END —
 发表于 2026-3-15 18:26:37
|
查看: 231|
回复: 0
发表于 2026-3-15 18:26:37
|
查看: 231|
回复: 0
