对于 C/C++ 开发者而言,写完程序后我们常常会说“编译一下”。当编译完成后,可执行文件就生成了。因此很多人可能会误以为从源代码到可执行程序只需要“编译”这一步。
但实际上,这种理解忽略了从源文件到可执行程序中的一个关键环节——链接(link)。
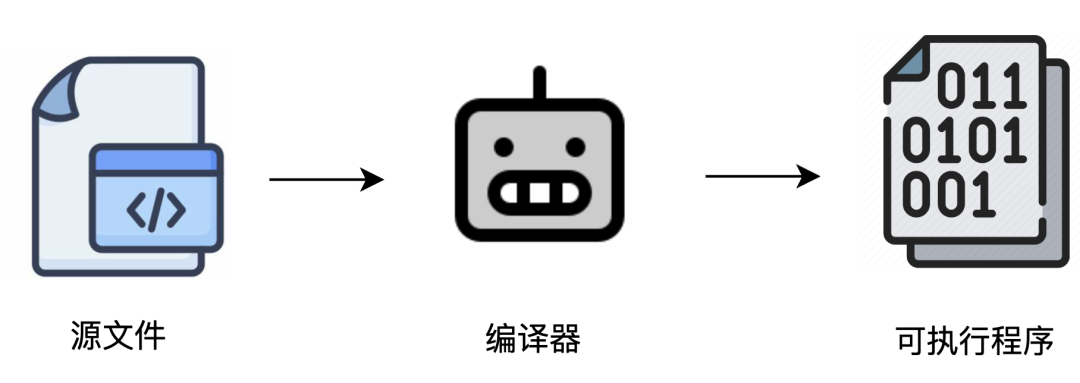
所以,从源文件到最终的可执行程序,通常需要两个核心步骤:编译与链接。
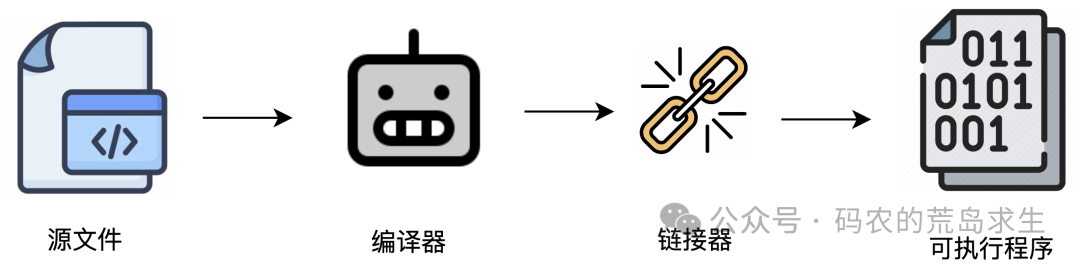
编译:生成中间产物
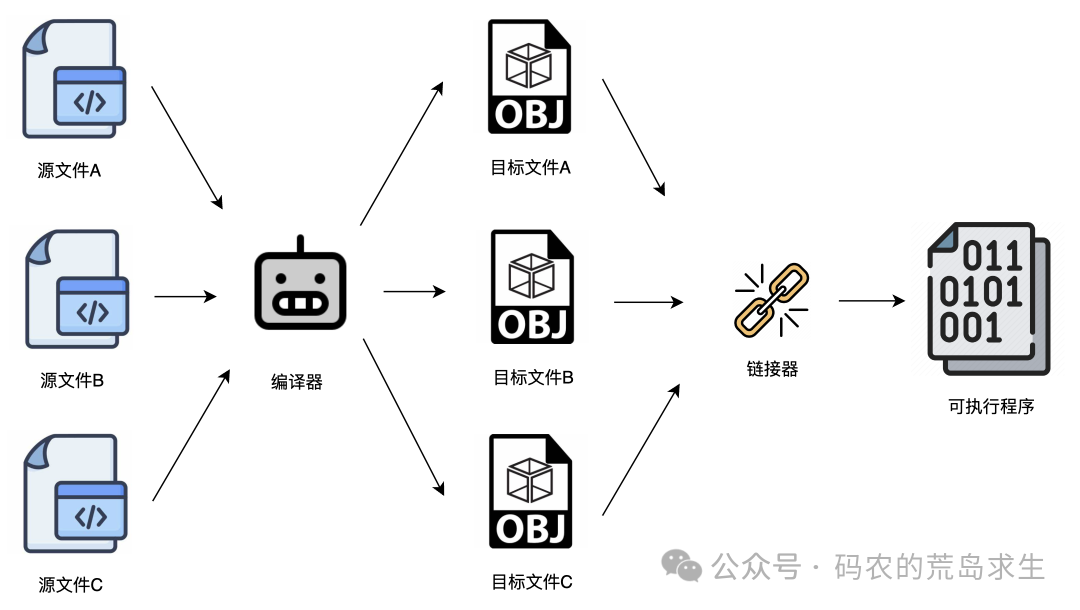
我们先来说说编译。编译实际上只是将人类可读的源代码转换为二进制的机器指令。保存这些二进制指令的文件,我们称之为目标文件(Object File)。
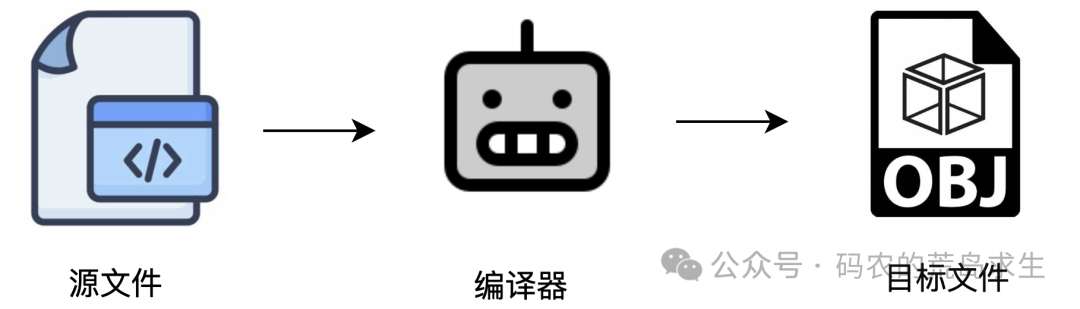
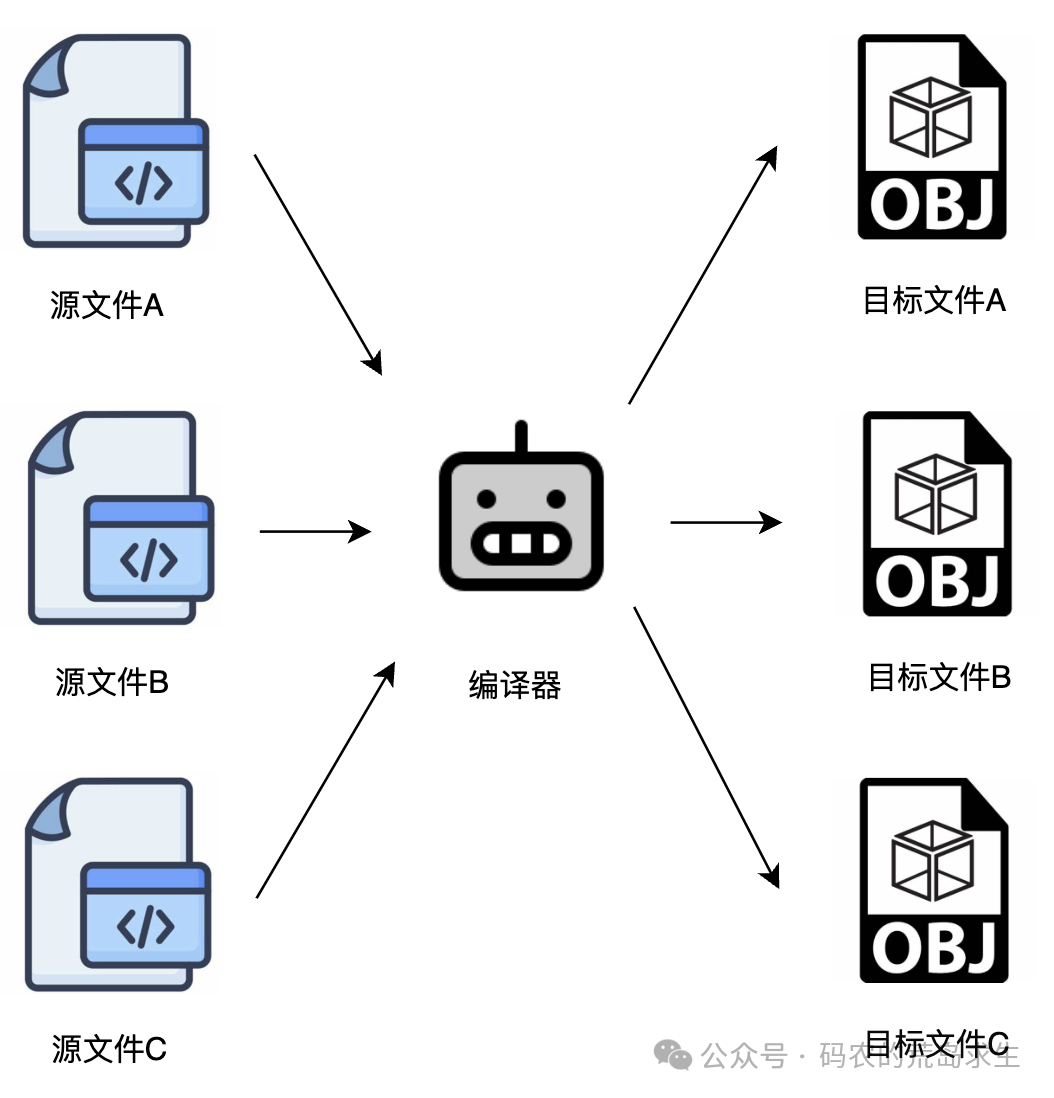
请注意,目标文件还不是最终的可执行程序。编译器是以源文件为单位进行工作的,这意味着每个源文件都会对应生成一个独立的目标文件。例如,如果你的项目中有 a.c、b.c 和 c.c 三个源文件,经过编译器编译后,会生成三个对应的目标文件。
到这里,编译器的工作就基本完成了。
链接:打包与决议
现在我们得到了一堆分散的目标文件。那么,这些零散的目标文件是如何最终融合成一个单一、可执行的程序呢?这就是接下来链接器登场的时候了。
链接器的首要任务,就是将这些独立的目标文件“打包”成一个最终的可执行程序。
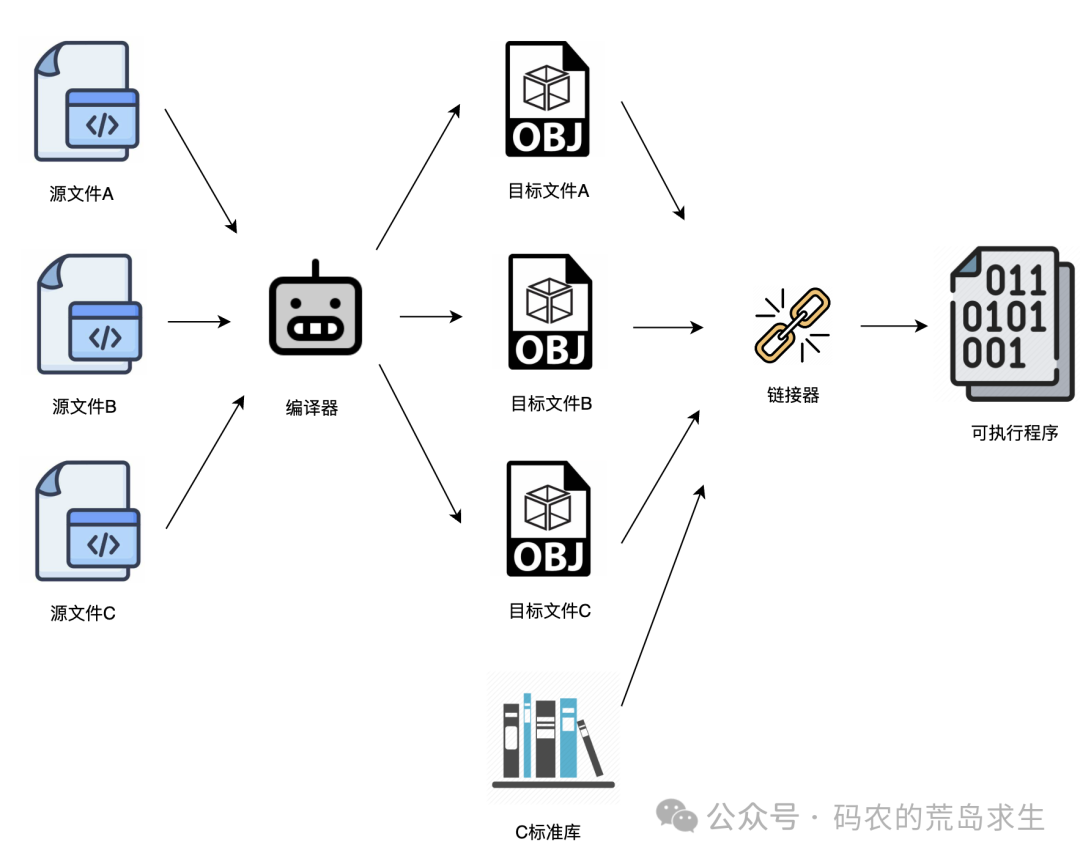
当然,除了打包我们编写的代码所生成的目标文件之外,链接器默认还会打包另一个至关重要的部分——标准库。以 C 语言为例,就是 C 标准库。
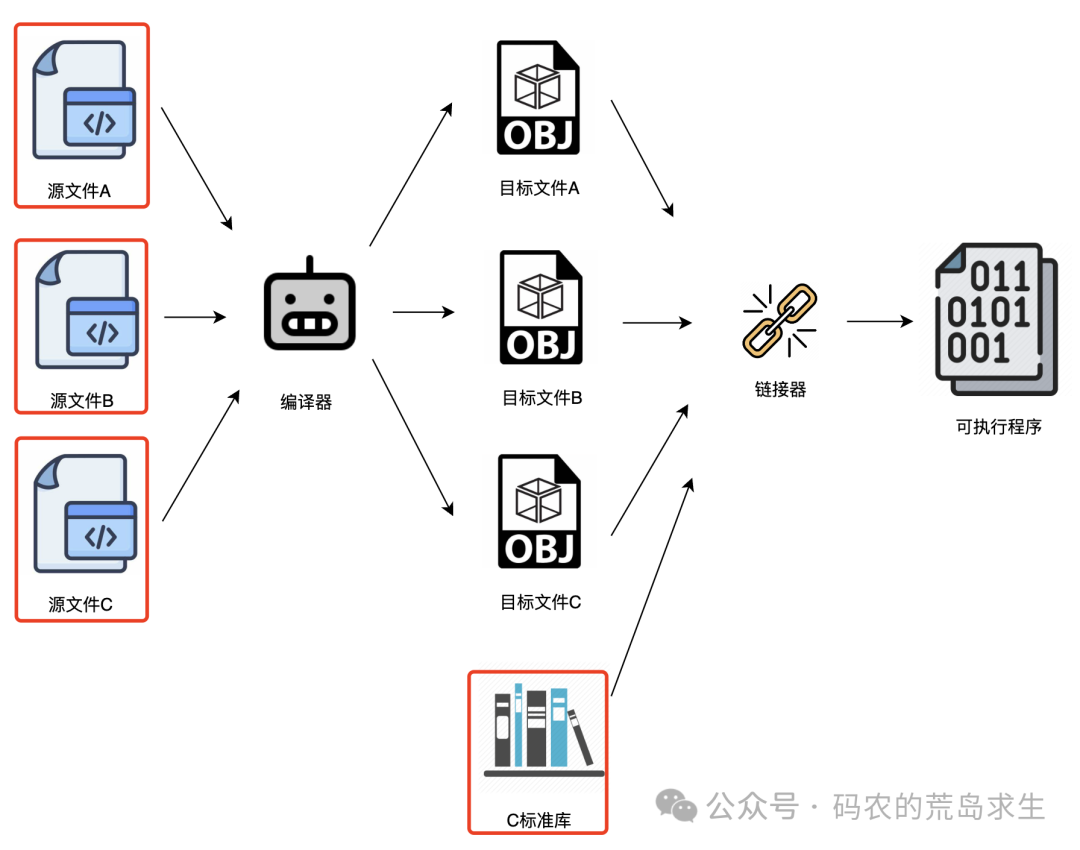
所以,如果我们忽略中间的“目标文件”这个临时产物,从源头和最终结果来看,可执行程序其实由两部分组成:我们亲手编写的代码,以及系统提供的标准库。
读到这里你可能会想:链接器的作用听起来很简单嘛,不就是个“打包工具”吗?
之前使用“打包”这个词主要是为了方便理解。实际上,链接器最核心、最重要的工作是 符号决议(Symbol Resolution)。这里的“符号”,指的就是程序中的变量名或函数名。链接器要确保程序中引用的每一个符号都“有定义”,并且在存在多个定义时,决定“使用哪一个”。
一个经典示例:Hello World
让我们以经典的“Hello World”程序为例来理解这一点。
int main() {
printf("hello world!\n");
};
任何学过 C 语言的同学对这段代码都不会陌生。我们将它保存为 hello.c。
当编译器在编译 hello.c 遇到 printf 这个函数调用时,它根本不知道 printf 这个符号的定义在哪里。这超出了编译器的职责范围。
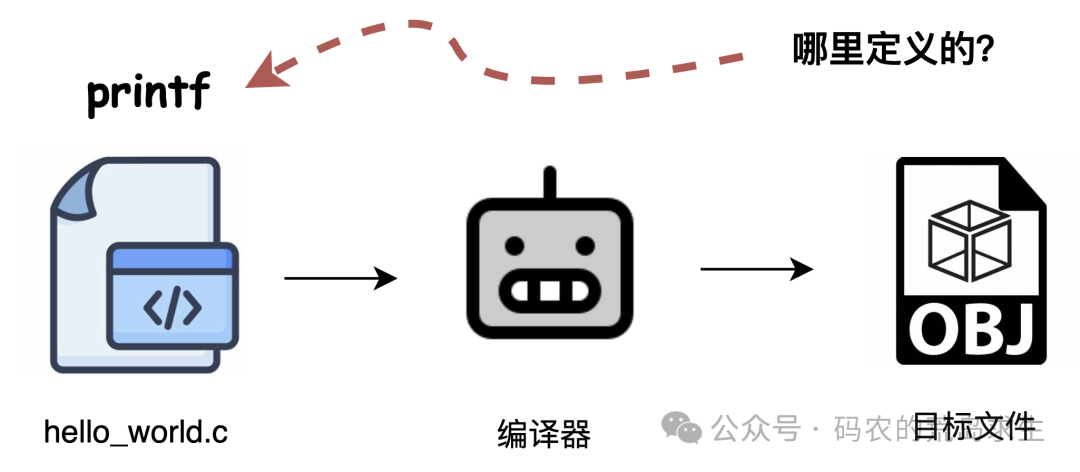
因此,编译器只具备“局部”视野,它的关注点局限在一个源文件内部。那么,谁来关心 printf 到底定义在哪里呢?答案就是链接器。
别忘了,链接器要打包所有的目标文件(以及库),因此它拥有“上帝视角”,能够看到程序的全局。
在我们的例子中,只有一个 hello.c 源文件,因此只会生成一个目标文件。既然在这个目标文件里没有定义 printf,那它还能定义在哪呢?再看看这张完整的流程图,答案就很清晰了。
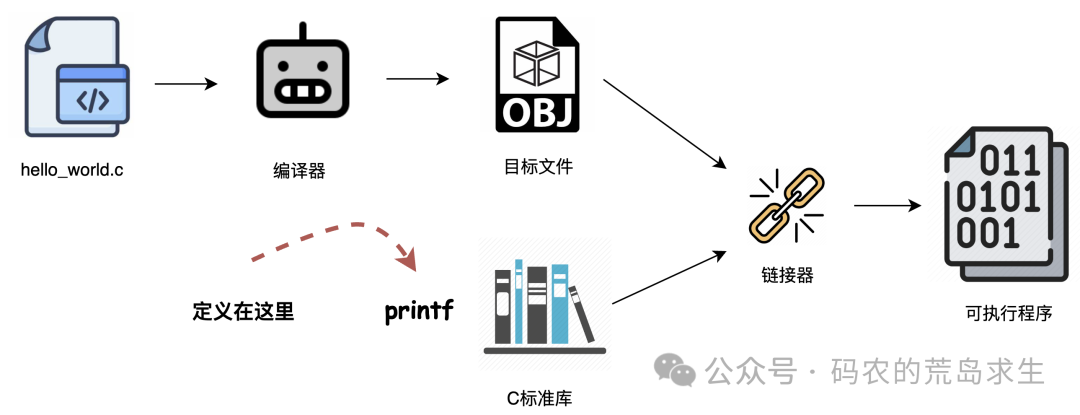
没错,printf 函数就定义在 C 标准库中。链接器在打包时,会发现 hello.c 生成的目标文件引用了 printf 符号,然后它会在所有待打包的目标文件和库文件(这里是 C 标准库)中搜索这个符号的定义。找到之后,它就会将这个定义和引用正确地关联起来。
链接器错误:未定义的符号
当然,如果链接器翻遍了所有指定的目标文件和库文件,都找不到某个符号的定义,那么它就会抛出一个经典的错误:undefined reference to ‘xxx‘。
例如下面这段代码:
void func(int a);
void main() {
func(1);
}
我们编译一下这段代码,实际上编译器阶段是没有错误的。因为编译器看到 func(1) 时,它知道你在调用一个外部定义的函数 func,并且调用方式(参数类型)根据函数声明来看是合法的,所以编译通过。
但是,当链接器开始工作时,它会尝试寻找 func 这个符号的定义。它找遍了所有我们提供的目标文件以及默认链接的库,都没有发现 func 函数的实现。于是,链接器就会报错,抱怨它找不到这个符号的定义。这也就是为什么错误发生在链接阶段,而非编译阶段。
总结
现在你应该对链接器的作用有了更清晰的认识。它远不止是一个简单的打包工具,更是保证程序各部分能正确连接在一起的“桥梁”和“检察官”。它的核心职责是解决符号引用,确保程序中的每个部分都能找到其依赖的实现。
理解编译与链接的分工,尤其是链接器在符号解析和库整合中的作用,对于深入掌握 C/C++ 程序的构建过程、以及排查复杂的构建和运行时错误至关重要。希望这篇文章能帮你彻底理清这个基础知识。如果你想进一步探讨程序底层的工作原理,欢迎在云栈社区与其他开发者交流。
 发表于 2026-3-17 00:09:33
|
查看: 159|
回复: 0
发表于 2026-3-17 00:09:33
|
查看: 159|
回复: 0
