在兴业证券的高频系列研究中,首席分析师郑兆磊老师曾探讨过收益率分布中的 alpha,也分析过成交量分布中的 alpha,但似乎还未涉足波动率分布中的 alpha 这一专题。
因此,笔者尝试不自量力地来聊一聊波动率分布中可能存在的 alpha。笔者推测,这个专题下应该不止一个有效的因子。
本文将聚焦于探讨 “波动率极大值幅度” 这个因子。该因子的构建思路参考了郑兆磊老师的研报《收益率极大值幅度:一个我差点错过的超级多头因子!》,同时也借鉴了曹春晓老师的研究《灾后重建是真的不行,不过更优波动率还是可以的》。
计算步骤和代码
在计算波动率时,笔者选择使用曹春晓老师提出的 “更优波动率” ,而非传统的波动率度量方式。
原因在于,若使用传统波动率来计算本因子,会产生大量的 nan 值,除非将判定极值的阈值放宽。
1. 计算步骤
整个因子的计算可分为以下四步:
- 第一步:计算 5 分钟周期的更优波动率。即,基于
open, low, high, close 共 20 个价格数据,计算其标准差与均值的比值。
- 第二步:计算 30 分钟周期的更优波动率。
- 第三步:计算 5 分钟更优波动率的 95% 分位数。
- 第四步:计算 30 分钟更优波动率中,超过其对应 5 分钟更优波动率 95% 分位数的那些值的均值,并将该均值除以这个 95% 分位数。
2. 代码实现
以下是核心的 Python 计算代码:
def process_single_day(self, idx):
file_name = self.files[idx]
date_str = file_name.split('.')[0]
cur = pd.to_datetime(date_str) + timedelta(hours=15)
file_name = self.files[idx]
full_path = os.path.join(self.file_pth, file_name)
data = BaseDataLoader.load_data(full_path, fields=['close', 'open', 'high', 'low'])
prefer_sigma_5 = []
prefer_sigma_30 = []
for i in range(5, len(data.data)):
tmp_data = data.data[i-5:i, :, :].reshape(-1, len(data.codes))
tmp_sigma = np.nanstd(tmp_data, axis=0) / np.nanmean(tmp_data, axis=0)
prefer_sigma_5.append(tmp_sigma)
if i >= 30:
tmp_data = data.data[i - 30:i, :, :].reshape(-1, len(data.codes))
tmp_sigma = np.nanstd(tmp_data, axis=0) / np.nanmean(tmp_data, axis=0)
prefer_sigma_30.append(tmp_sigma)
prefer_sigma_5 = pd.DataFrame(prefer_sigma_5, columns=data.codes)
prefer_sigma_30 = pd.DataFrame(prefer_sigma_30, columns=data.codes)
q = prefer_sigma_5.quantile(0.95)
flag = prefer_sigma_30 > q
prefer_sigma_30 = (prefer_sigma_30 * np.where(flag, 1.0, np.nan)).mean() / q
res = prefer_sigma_30.to_frame()
res.columns = ['prefer_sigma']
res['datetime'] = cur
代码解读:
- 前 7 行:负责读取对应日期的行情数据。
- 第 8-19 行:循环计算每个标的的 5 分钟和 30 分钟更优波动率。这里需要注意的是,
data.data 是一个三维 numpy 数组,其维度依次为:时间、字段、标的。更多细节可参考关于基础数据类BaseDataLoader的说明。
- 第 20 行:计算 5 分钟更优波动率的 95% 分位数
q。(值得一提的是,如果使用传统波动率,此处需降至 80% 分位数,否则仍会有部分标的的因子值为 nan)。
- 第 21-22 行:依据上述公式,计算“波动率极大值幅度”因子。
因子评价
在郑兆磊老师对收益率极大值幅度的研究中,采用了过去 N 个交易日的均值方法对因子进行低频化处理。因此,笔者在此处也沿用这种均值法进行低频化。
01 IC分析
首先,我们来看该因子的信息系数(IC)分析结果。
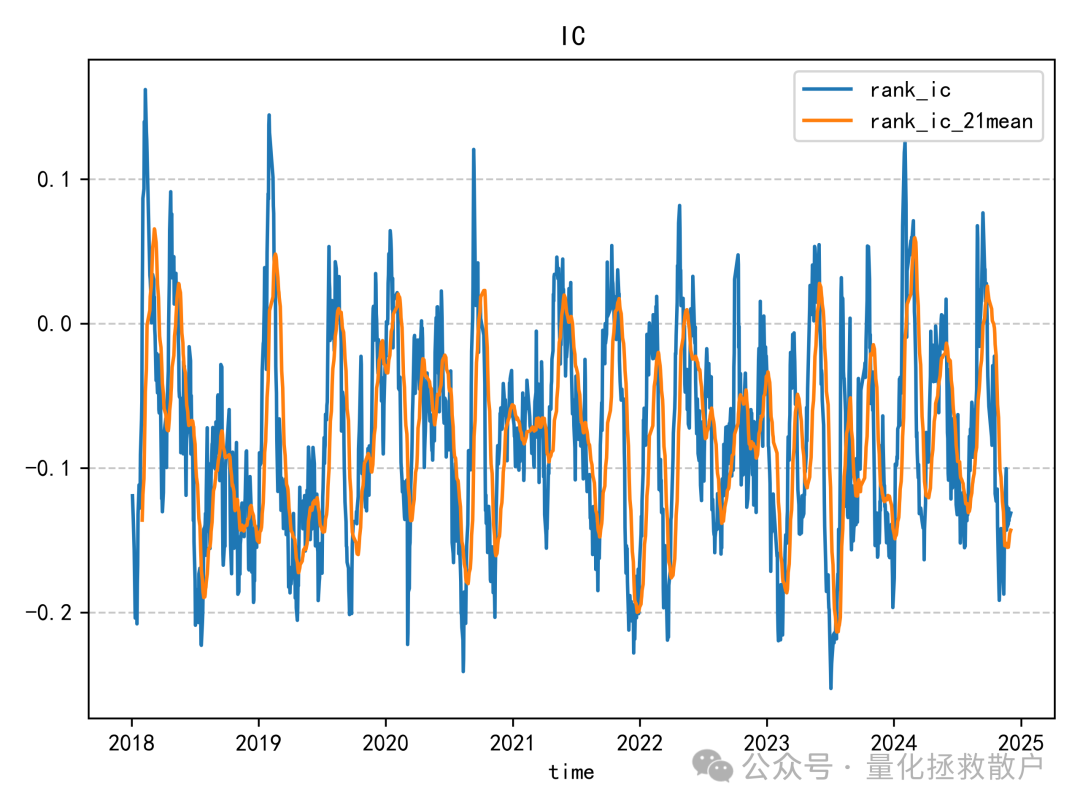
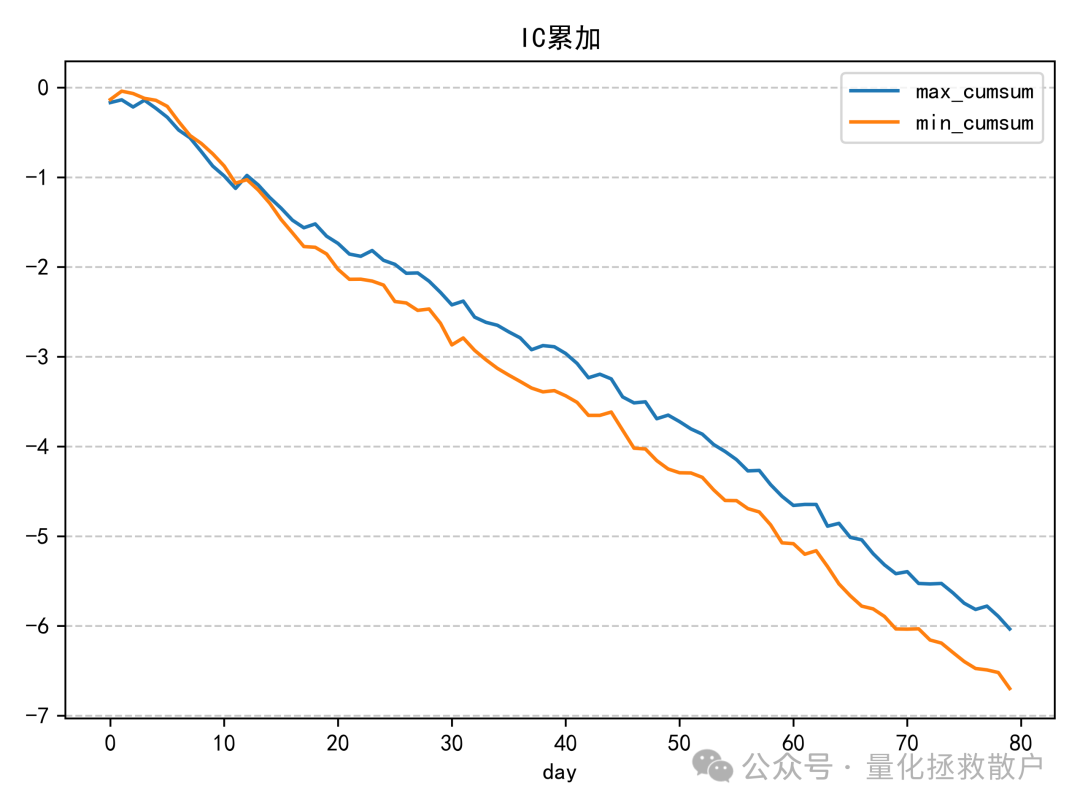
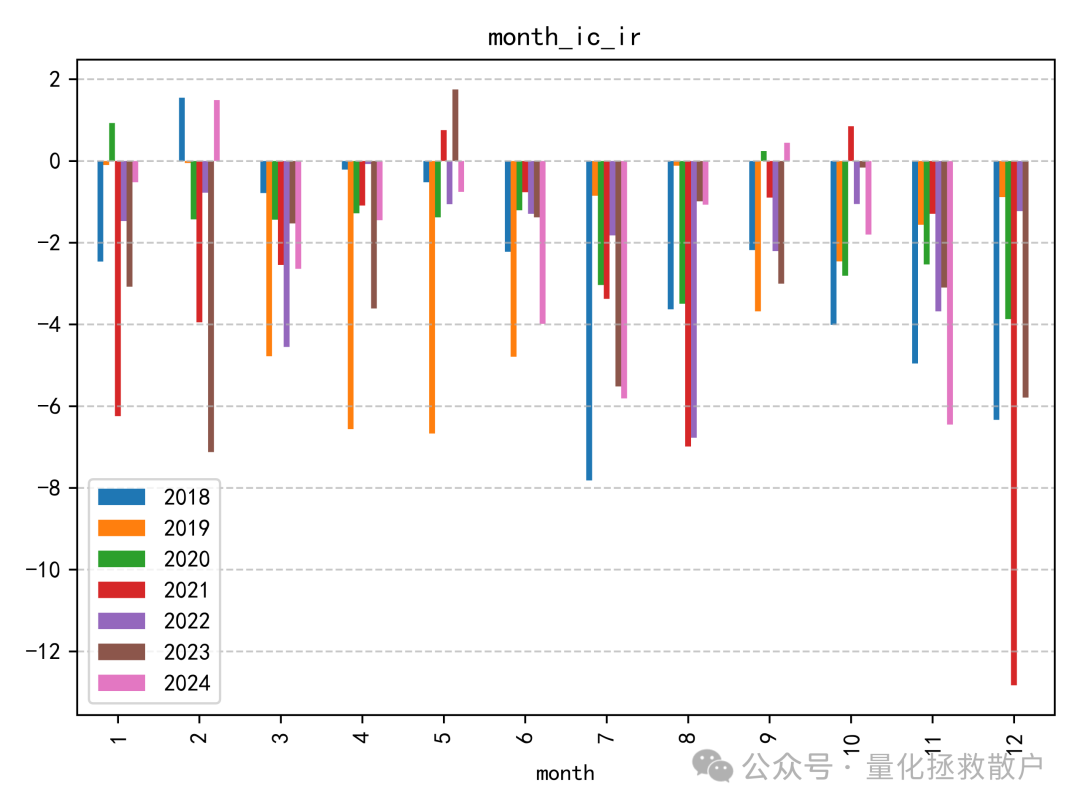
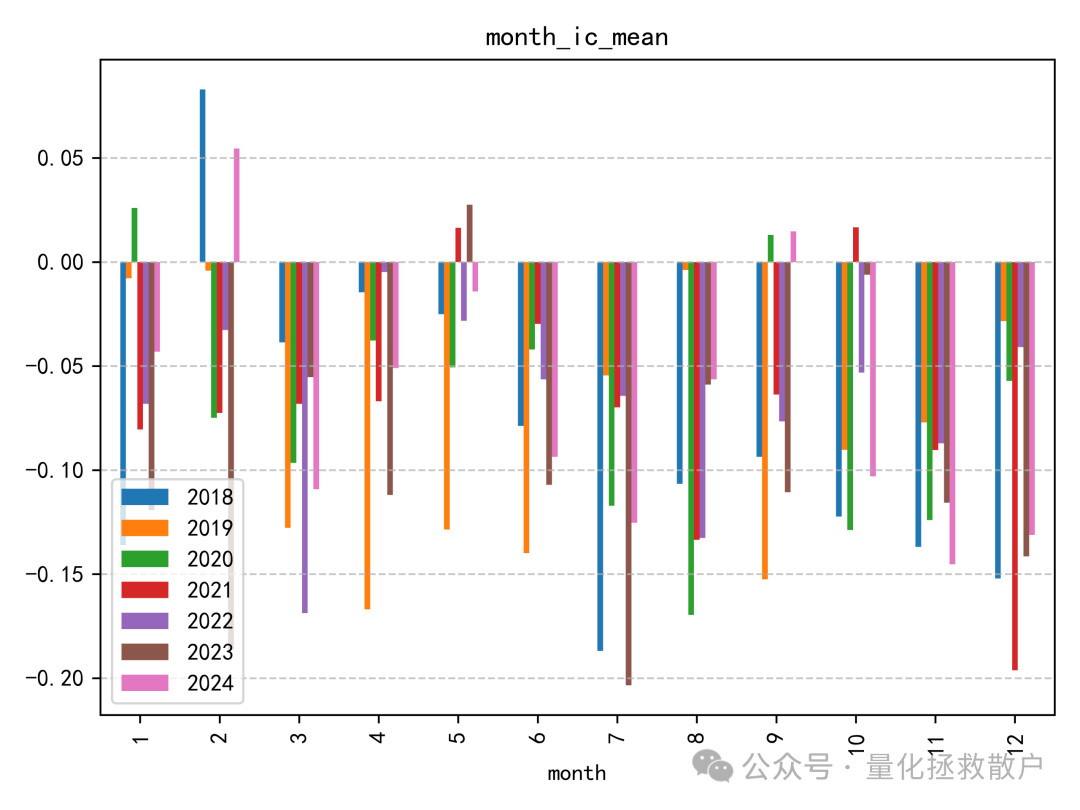
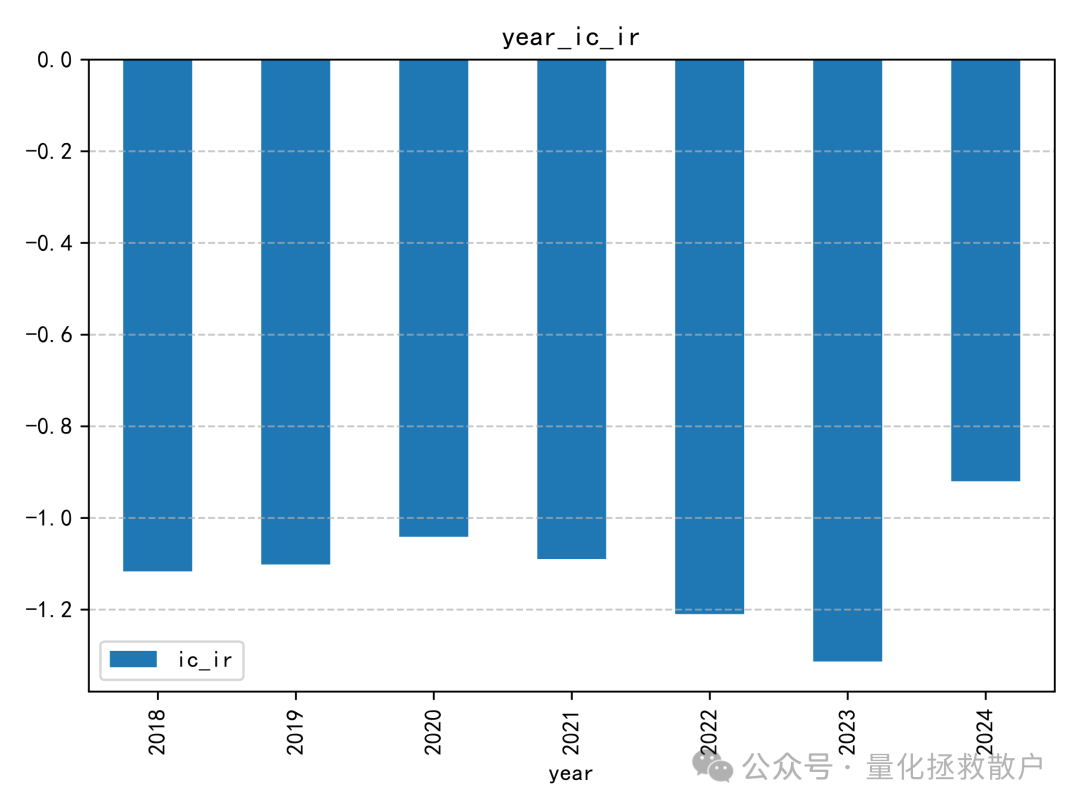
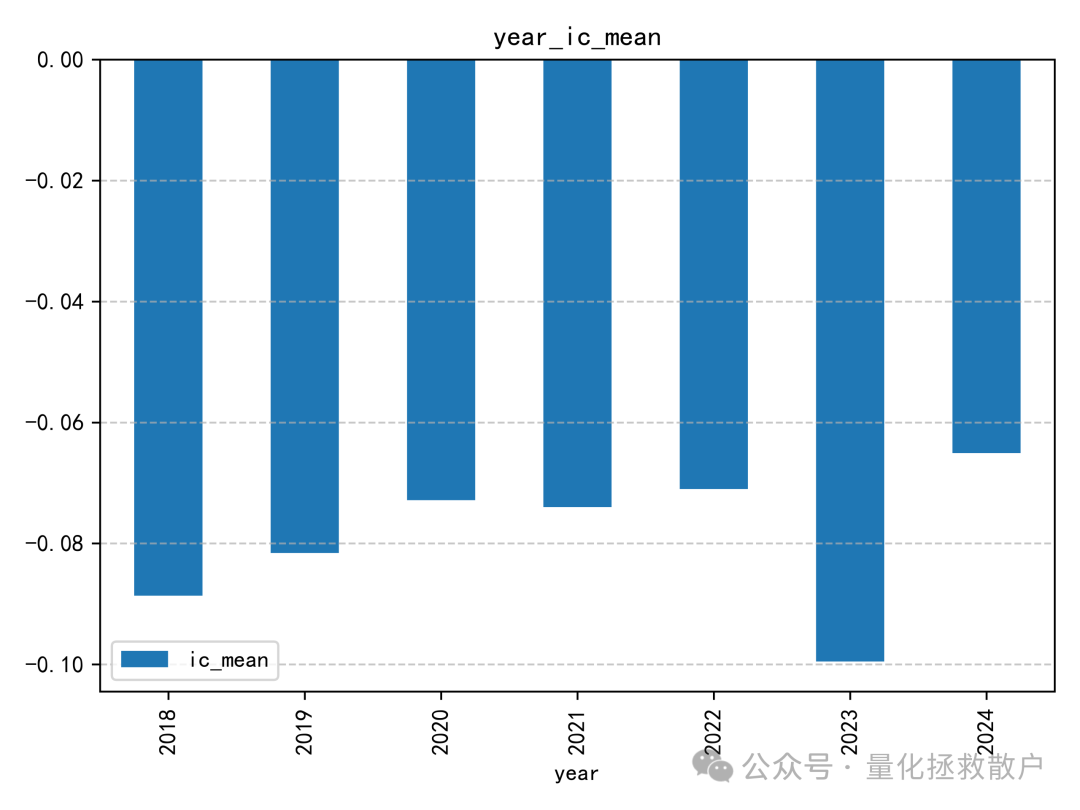
从 IC 分析结果来看,该因子的表现尚可,其 IC 绝对值的平均水平相比“收益率极大值幅度”因子要高出不少。这类针对收益率分布中的alpha和波动率分布中的alpha的探索,正是量化研究不断深入数据细节的体现。
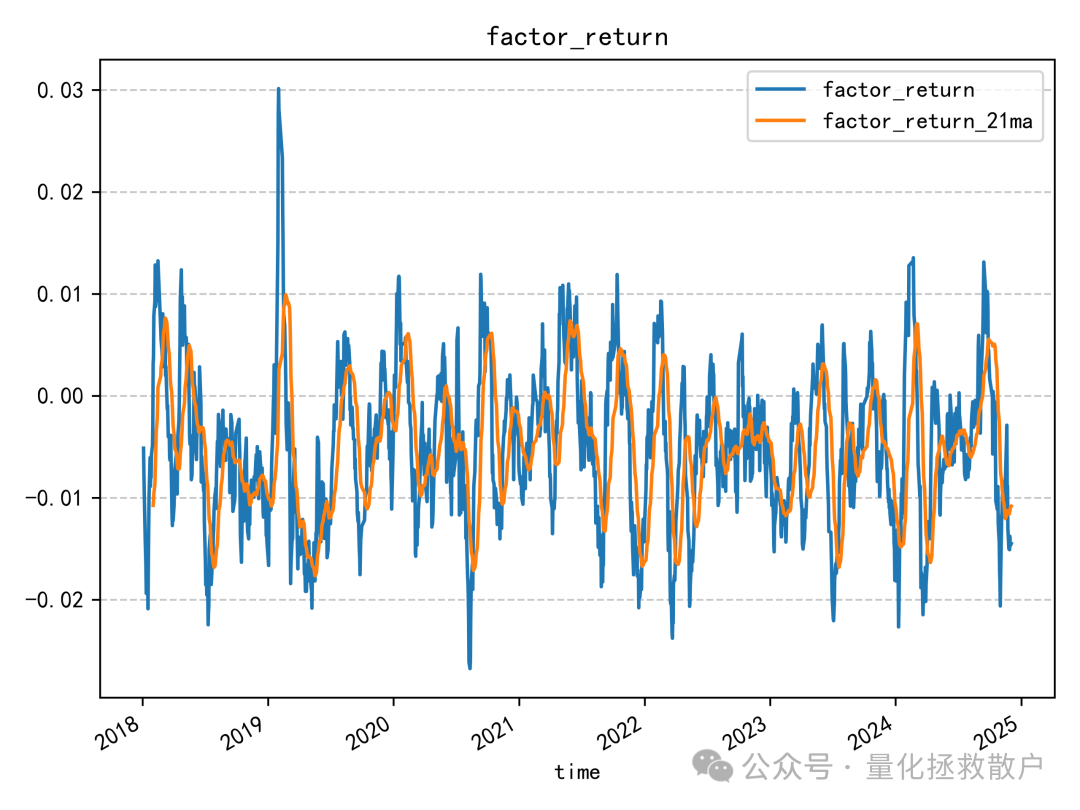
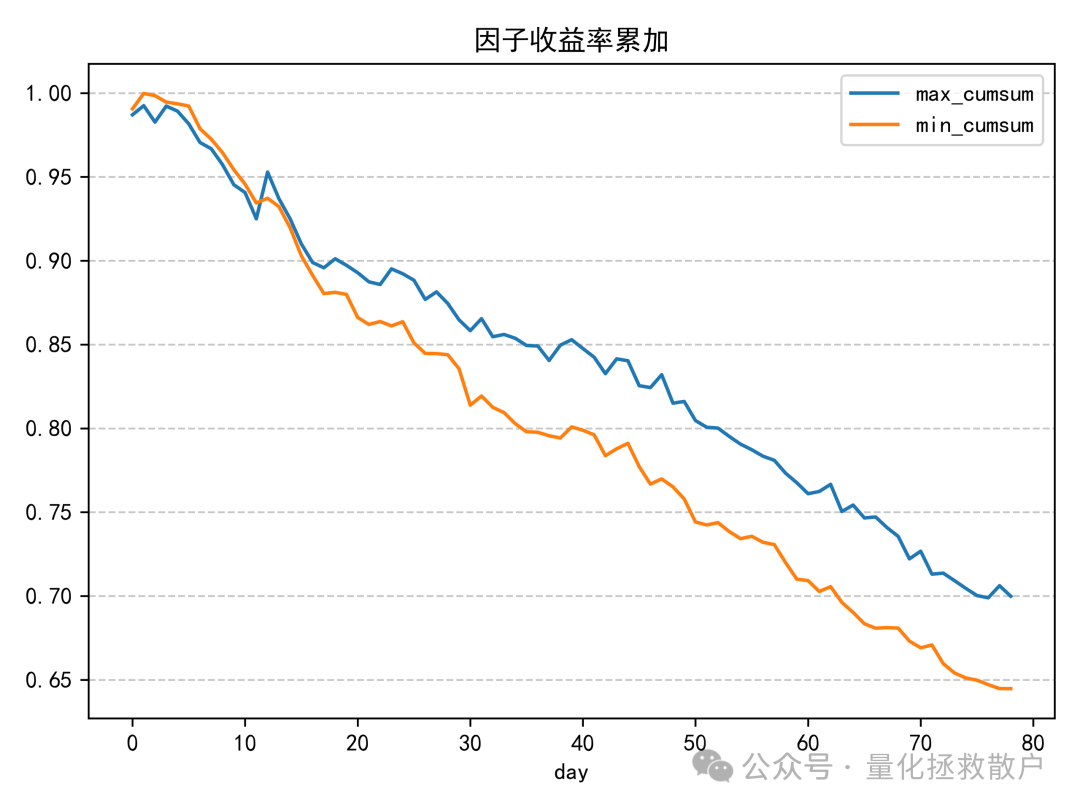
02 回归分析
接下来是因子收益率分析。
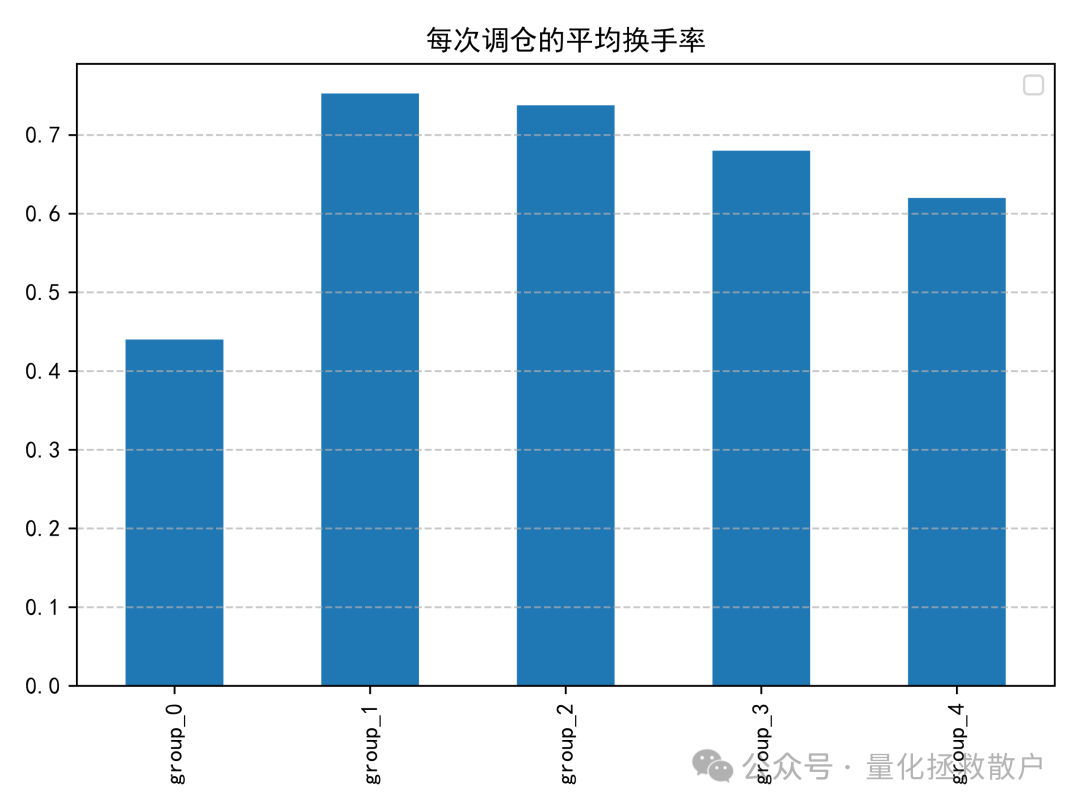
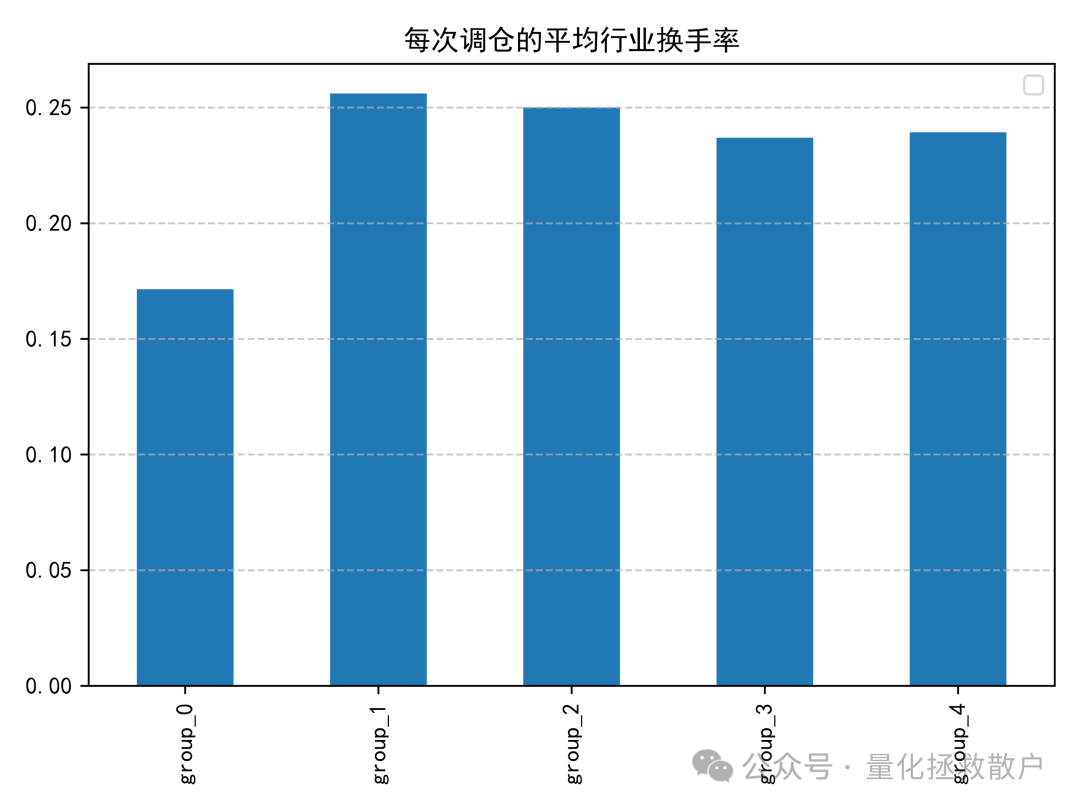
03 换手率分析
换手率是衡量因子实用性的重要指标,过高的换手率会导致交易成本侵蚀收益。
04 收益分析(分层回测)
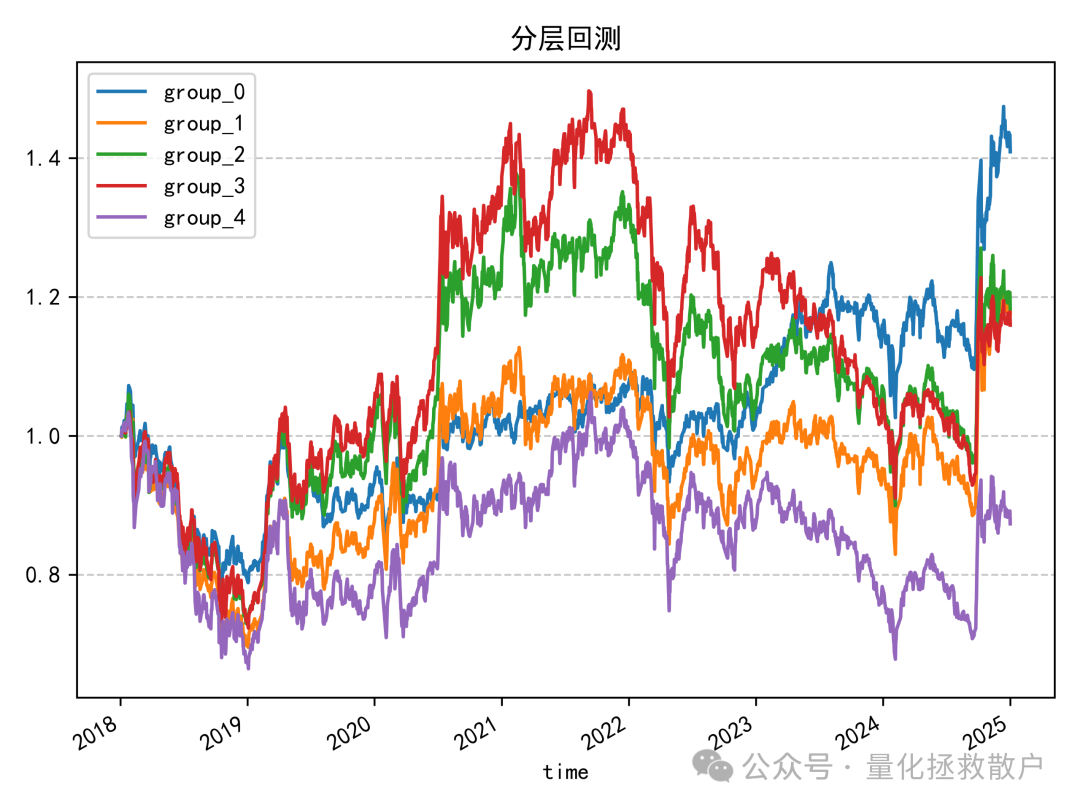
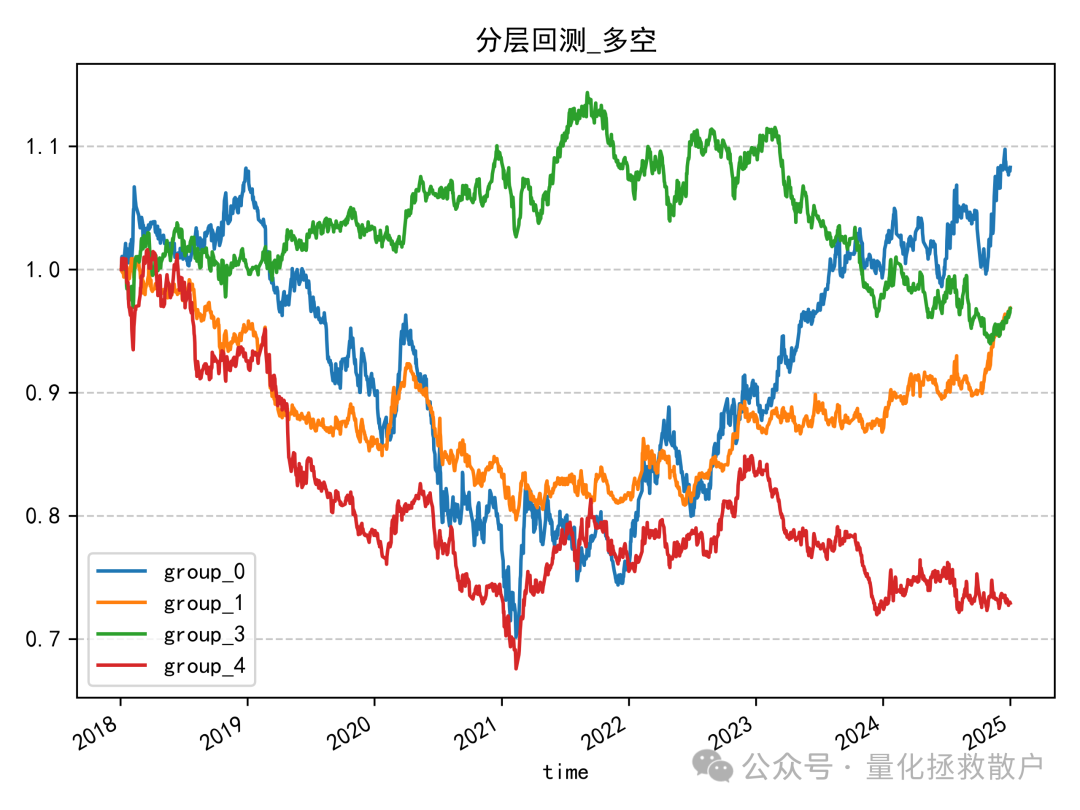
最后,也是最关键的分层回测收益分析。
结论分析:
虽然该因子在 IC 统计上的表现优于“收益率极大值幅度”因子,但其分层回测的结果却不容乐观。
从净值曲线可以清晰看到,该因子的分组收益缺乏单调性。在大部分时间里,代表中间组别的红色(group_3)和绿色(group_2)曲线净值领先于其他组,直到2023年第二季度左右才被代表最低组的蓝色(group_0)曲线超越。
因此,尽管 IC 表现不错,但分层回测缺乏单调性的结果意味着,该因子在当前形式下难以直接有效地应用于选股策略。它可能捕捉到了一些市场现象,但尚未转化成稳定的预测能力。对于这类更优波动率因子的深度挖掘与改进,仍然是值得探索的方向。
本文由云栈社区编辑发布,旨在分享量化交易领域的技术实践与思考。
 发表于 2026-3-17 01:32:47
|
查看: 280|
回复: 0
发表于 2026-3-17 01:32:47
|
查看: 280|
回复: 0
