最近,我用 LangChain 搭建了一个面向“业务知识库”场景的 RAG 系统。这个系统并非泛泛的搜索引擎或演示版聊天机器人,而是更贴近企业内部的实际需求,比如客服 SOP、退款审批规则、OpenAPI 对接手册这类文档的精准问答。
最终,项目具备了以下核心能力:
- 支持文档上传、按路径导入
- 支持多轮对话和代词指代
- 回答严格基于上下文,不知道就明确说不知道
- 返回引用溯源,能看到答案来自哪个文档哪一段
- 检索层支持 Dense Recall + BM25 + Cross-Encoder reranking
- 用 LangChain InMemoryCache 做请求级缓存
- 用 RAGAS 做回归评估
本文我将重点分享三方面的内容:这套 RAG 的架构设计思路、为何单一的“向量检索 + 大模型回答”模式远不足以应对实际业务,以及在实现过程中踩过的那些“坑”及其解决方案。
01 系统架构
先来看整体的架构设计图:
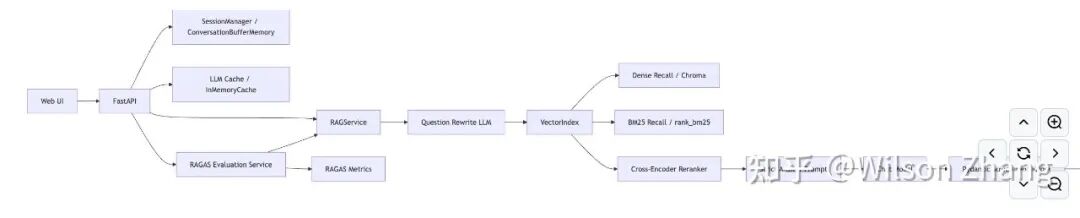
这张架构图清晰地展示了从用户提问到获取答案的完整流程。其中最核心的设计理念是将复杂的问答过程进行分层解耦:
- 将“检索前的问题改写”和“最终生成回答”拆分为两个独立阶段。
- 将“粗粒度召回”和“精粒度排序”拆开。
- 将“在线问答服务”和“离线效果评估”拆开。
这样做的好处是每一层都可以独立调优和替换,而不是把所有复杂性都推给大语言模型(LLM)去处理,使整个系统更可控、更易维护。
02 为什么要先改写问题再检索?
很多入门级的 RAG 教程都忽略了一个现实问题:在实际对话中,用户的第二句、第三句提问往往不是完整的独立问题。
例如:
Q1: 退款金额高于 200 元怎么办?
Q2: 那它需要谁二次确认?
第二句中的“它”对人类来说指代明确,但对于仅依赖当前句子进行向量相似度计算的检索器而言,却十分不友好,极易导致召回无关内容。
因此,我在检索步骤之前专门加入了一层“问题改写”(Question Rewriting)。其作用是将依赖上下文的追问(如Q2),补充、重写成一个语义完整的独立查询语句。
关键代码位于 app/rag_chain.py 中:
standalone_question = self._rewrite_question(llm, chat_history, question)
source_documents = self.vector_index.search(
session_id=session.session_id,
query=standalone_question,
top_k=self.settings.top_k,
)
这一步的目标并非让最终生成的答案“看起来更好”,而是为了确保“检索资料”这一步能够更加精准,为后续流程打下坚实基础。
03 为什么我最终做成了混合召回?
项目初期仅使用了向量召回(Dense Retrieval),在处理“语义相近”的问题时表现尚可。然而,一旦问题中出现以下元素,效果就变得极不稳定:
- 专有名词(如内部系统名称、产品代号)
- 金额阈值(如“高于200元”)
- 规则编号(如“条款第3.2条”)
- 明确的关键词
例如,对于“退款金额高于 200 元”这类问题,BM25 这类基于关键词匹配的检索方法其实更具优势。
因此,我对召回层进行了改造,采用了混合召回策略:
- Dense Retrieval(向量召回):主要负责处理语义近似、表达方式多样的查询。
- BM25 Retrieval(关键词召回):主要负责处理包含明确关键词、数字、条件判断的查询。
关键实现代码在 app/vector_store.py 中:
dense_results = self._dense_search(session_id, query, candidate_k)
keyword_results = self._keyword_search(session_id, query, candidate_k)
merged_results = self._merge_results(dense_results, keyword_results, candidate_k)
return self._rerank_results(query, merged_results, top_k)
这一步改造价值显著,因为业务文档问答往往既需要深度的语义理解,也离不开对关键词和精确条件的匹配。
04 为什么还要再加 Cross-Encoder 重排序?
引入混合召回后,我发现新的问题出现了:候选文档片段“能被召回”,并不代表它们的“排序顺序就是正确的”。
尤其是在以下场景中,召回的前 Top-K 个结果里常常会混杂一些看似相关、实则并非答案核心证据的段落:
- 同一主题但涉及不同角色或权限的段落。
- 同样讨论“退款”,但处理条件和流程截然不同的段落。
- 同一文档中相邻、且都包含关键词的段落。
为此,我在召回层之后又添加了一层 Cross-Encoder reranking(交叉编码器重排序):
return self.reranker.rerank(query, candidates, top_k)
它与普通的向量检索(Embedding)核心区别在于:
- Embedding:是“先将查询和文档分别编码成向量,再计算向量间的相似度”。
- Cross-Encoder:是“将查询和文档片段一起送入模型,让模型直接判断两者的相关性得分”。
Cross-Encoder 的计算成本更高,但判断也更为精准,因此特别适合作为第二阶段的精排器,对少量高质量候选进行最终排序。
05 严格回答和结构化输出
对于业务问答系统而言,最可怕的不是“答不上来”,而是“答错了却显得十分自信”。
因此,我在设计提示词(Prompt)时加入了两条硬性约束:
- 回答必须严格基于提供的上下文。
- 如果上下文没有相关信息,必须明确回答“我不知道”。
同时,我没有让模型自由发挥地进行文本输出,而是采用了 Pydantic 结构化输出(Structured Output):
class StructuredAnswer(BaseModel):
answer: str
grounded: bool
citations: List[Citation] = Field(default_factory=list)
这样做有两个明显好处:
- 前端展示稳定:无需再猜测或解析模型返回的非结构化文本,直接使用定义好的字段即可。
- 引用关系可校验:可以通过程序检查
citations 字段与上下文的对应关系,减少模型“虚构引用”的情况。
06 缓存优化:我为什么选择 InMemoryCache
在调试提示词、反复运行相同问题、进行回归测试时,最耗时的往往是重复调用大模型。
为了提升开发与评估效率,我集成了一层 LangChain 的 InMemoryCache:
from langchain_core.caches import InMemoryCache
from langchain_core.globals import set_llm_cache
set_llm_cache(InMemoryCache())
这里有一个至关重要的点需要澄清:LangChain 的 InMemoryCache 不是基于向量相似度的语义缓存(semantic cache),它是“仅当完全相同的 Prompt 再次出现时才会命中”的精确缓存。
为了避免误解,我后来还在系统中添加了简单的缓存状态观测功能,记录并展示 hits(命中)、misses(未命中)、writes(写入)等指标,方便在 Web 界面上直观了解缓存的使用情况。
07 RAGAS 评估如何集成
仅仅靠人工查看几轮问答结果,几乎不可能稳定地优化一个 RAG 系统。
因此,我为项目集成了一套内置的评估流程,使用 RAGAS 框架来量化以下几个关键指标:
- Faithfulness(忠实度):答案是否严格基于给定的上下文,有无幻觉。
- Answer Relevancy(答案相关性):答案是否直接回答了问题。
- Context Recall(上下文召回率):给定的上下文是否包含了回答所需的所有信息。
- Context Precision(上下文精确率):给定的上下文是否都是与问题高度相关的。
- Answer Correctness(答案正确性):对比参考答案,答案的准确程度。
核心评估流程如下:
- 准备一组带有标准答案(ground truth)的业务测试问题集。
- 使用当前的 RAG 系统对这些问题进行实际问答,并记录生成的答案以及检索到的上下文(contexts)。
- 将
question、answer、contexts、ground_truth 喂给 RAGAS 进行评估计算。
关键代码位于 app/evaluation.py:
result = evaluate(
Dataset.from_list(dataset_rows),
metrics=[
faithfulness,
answer_relevancy,
context_recall,
context_precision,
answer_correctness,
],
llm=LangchainLLMWrapper(self.rag_service._build_llm()),
embeddings=LangchainEmbeddingsWrapper(EmbeddingAdapter(self.embedding_service)),
raise_exceptions=False,
)
在 Web 界面中,我将 RAGAS 的总体评分以及每个问题的细分分数都展示出来。这样,每次调整系统参数(如召回数量、Prompt 等),都可以立即从数据上看出是“检索效果变差了”还是“答案生成跑偏了”,让优化工作有据可依。
08 我踩过的几个坑
坑 1:RAGAS 安装成功,但在 Python 3.8 环境导入时报错
最初我安装了 ragas 0.2.x 版本,安装过程顺利,但在代码中 import 时直接抛出 SyntaxError。
原因:新版本的 RAGAS 内部使用了 Python 3.9+ 的语法特性(如字典合并运算符 |),而我本地的项目环境是 Python 3.8。
解决方式:
- 没有选择强行升级整个项目的 Python 版本。
- 而是将
ragas 的版本锁定在兼容 Python 3.8 的 0.1.21。
- 并在项目的 README 中明确说明了版本依赖关系。
这种方式比“为了一个评估库而推翻整个项目环境”要稳健得多。
坑 2:误将 InMemoryCache 当作语义缓存使用
正如前文强调的,很多人看到“Cache”会想当然地认为它能缓存“语义相似”的问题。
实际上,LangChain 的 InMemoryCache 只进行字符串级别的精确匹配。
解决方式:
- 在代码中按照其真实功能接入
InMemoryCache。
- 在界面说明和 README 中明确标注:“此为精确请求缓存,非语义缓存”。
技术命名的准确性远比营销式的模糊表述更重要。
坑 3:评估时污染了对话历史记忆(Memory)
如果直接使用同一个对话会话(Session)来运行批量评估,其中的 ConversationBufferMemory 会不断累积历史对话。这会导致后面的评估问题受到前面问题的影响,使评估结果失真。
解决方式:
- 评估时,复用了当前会话加载的文档知识库。
- 但为每一个测试问题都创建一个全新的、隔离的
memory 对象。
这样既保证了评估基于同一套知识数据,又避免了测试用例间的相互干扰。
坑 4:仅使用向量召回时,金额阈值类问题效果不稳定
在业务规则文档中,“高于 200 元”、“连续三次失败”、“24 小时内”这类包含明确条件和数字的信息至关重要。
仅依赖语义检索,经常会把主题相关但条件不符的段落排在前面。
解决方式:
- 引入 BM25 进行关键词召回,确保精确条件能被匹配。
- 引入 Cross-Encoder 进行精排,对混合召回的结果进行更准确的排序。
这是整个项目迭代中,效果提升最显著的一次架构改造。
09 如果让我再做一次,我会优先补什么?
如果你已经跟着教程跑通了 RAG 的基础流程,我建议接下来优先补全以下三个模块:
- 混合召回:结合向量与关键词检索,覆盖更全面的查询意图。
- Reranking:对召回结果进行精细排序,提升最终输入给 LLM 的上下文质量。
- Benchmark + 回归评估:建立可量化的评估体系,告别“凭感觉调参”。
真正让一个 RAG 系统变得“工程化”的,往往不是更精巧的 Prompt,而是:
- 检索的稳定性:能否持续、准确地命中正确答案所在的证据片段。
- 评估的持续性:能否通过数据指标驱动迭代,而非盲目调整。
最后
这个项目我已经完成了 Web 界面、缓存观测、RAGAS 评估和引用溯源等功能的集成。代码已在 GitHub 开源,地址如下:
https://github.com/wilsonIs/langchain-business-rag
如果你也在构建面向中文业务场景的知识库 RAG 系统,我的核心建议是:不要把所有问题都归咎于“模型不够强大”。很多时候,性能瓶颈在于工程架构的细节。优先补齐以下环节,通常比单纯更换更强大的模型能带来更显著的稳定性提升:
- 检索前改写:让查询更完整。
- 混合召回:让检索更全面。
- 精排:让证据更精准。
- 评估:让优化有方向。
- 观测:让系统更透明。
希望这篇来自真实项目的 开源实战 经验总结,能帮助你在云栈社区探索 RAG 技术的道路上少走弯路。
 发表于 2026-3-17 02:59:03
|
查看: 207|
回复: 0
发表于 2026-3-17 02:59:03
|
查看: 207|
回复: 0
