
摘要: 股息期限结构的研究长期受制于 dividend strips 数据的稀缺。Giglio, Kelly and Kozak (2024) 提出了一个仿射模型,仅凭股票组合的横截面收益数据,便能反推出任意组合、任意期限的股息期限结构,且与实际交易数据高度吻合。
0
研究股息期限结构,你绕不开一个问题:数据从哪来?
理论上,答案很清晰。Dividend strips——即对未来某一特定时点股息的单独索取权——的价格,直接反映了投资者对不同期限现金流的折现率。观察这些合约的价格,就能读出期限结构的形状。
现实中,答案很骨感。交易所交易的 dividend strips 数据,最早只能追溯到 2004 年。20 年的数据,只覆盖了一次完整的衰退与复苏。更要命的是,这些数据几乎只有市场层面(S&P 500)的,个股或组合层面的数据极为稀缺;可观测的期限最长也就七年,长端完全是盲区。
于是,研究者面临一个经典的两难:用 dividend strips 数据,直接、干净,但样本太短、截面太窄、期限太有限;用股票横截面数据推断,样本长、覆盖广,但需要对投资者偏好和现金流动态施加大量假设,结论的可信度存疑。
Giglio, Kelly and Kozak (2024)(以下简称 GKK)选择了后者——但他们做了一件很漂亮的事:在完全不使用 dividend strips 数据的前提下,构建了一个模型,然后用实际交易的 dividend strips 数据来验证它(OOS test)。
结果,模型通过了 OOS test。
1
在进入模型之前,我们先回答两件事:期限结构是什么,以及为什么它重要。
股票可以被理解为无数张有期限的索取权的叠加。每一笔未来的股息,都是一张独立的“债券”:明年的股息,是一张 1 年期的索取权;后年的股息,是一张 2 年期的索取权;以此类推,直到无穷远。这种对单一期限股息的索取权,在文献中被称为 dividend strip。它有明确的到期日,即那笔股息发放的年份。因此,股票的当前价格,本质上是所有 dividend strips 价格之和:
$$
P_t = \sum_{n=1}^{\infty} P_t^{(n)}
$$
其中 $P_t^{(n)}$ 是第 $n$ 年 dividend strip 的当前价格。
有了 dividend strip,我们就可以定义股息期限结构的纵坐标——equity yield:
$$
y_t^{(n)} = -\frac{1}{n} \log \left( \frac{P_t^{(n)}}{D_{t+n}} \right)
$$
它和债券 yield 类似:你现在花多少钱,买到第 $n$ 年的股息,对应的年化回报率是多少。
Yield 的高低,是市场对这期现金流的风险的定价投票。Yield 高,说明这期股息的价格被压低了——市场认为它风险大,要求更高的补偿才愿意持有。Yield 低,则说明市场认为这期现金流相对安全,愿意接受更低的回报。期限结构的形状,直接反映了投资者如何看待不同时间尺度上的风险。向上倾斜,意味着远期现金流更危险,符合正常的风险厌恶直觉——类似于债券收益率曲线通常向上倾斜的原因。向下倾斜则更反直觉,也更有信息量:它意味着投资者反而更恐惧近期的现金流风险。这种情况常见于经济衰退期——明年的股息能不能发出来都是问题,市场对短期现金流要求的补偿,反而高于长期。
那么,为什么期限结构重要?传统资产定价研究把一只股票作为整体来看,关注的是:持有这只股票,整体上需要多少风险溢价?但这个问题其实掩盖了更细致的结构。同样是持有一只股票,你同时持有的是它明年的股息、五年后的股息、二十年后的股息——这些现金流的风险特征,未必相同,市场对它们的定价,也未必一致。对于一个有固定期限现金流的项目,你需要知道对应期限的折现率。气候变化投资、私募股权估值、基础设施项目——这些场景里,长端折现率至关重要。从这个角度说,期限结构是检验资产定价模型的利器:长期风险(long-run risk)模型、习惯形成(habit formation)模型、稀有灾难(rare disaster)模型,对期限结构的形状都有截然不同的预测。
GKK 的目标,是用一个经济上合理、统计上简约的模型,将期限结构数据在时间维度上、截面维度上以及期限维度上扩展。
2
GKK 的模型是一个仿射模型(affine model)。这类模型在利率期限结构文献中早有先例,GKK 将其移植到股票定价领域。
模型的核心是一个状态向量 $F_t$,其动态满足线性系统:
$$
F_{t+1} = \mu + \Phi F_t + \Sigma \varepsilon_{t+1}
$$
此外,在随机折现因子(SDF)中,风险价格 $\lambda_t$ 是状态变量的仿射函数:
$$
\lambda_t = \lambda_0 + \lambda_1 F_t
$$
这是一个相当标准的设定。真正有意思的,是 GKK 对状态向量 $F_t$ 的选择。
GKK 将 $F_t$ 定义为两部分:因子收益($r_t^f$),即市场超额收益加上 51 个异象组合收益的前 3 个主成分(PC);以及因子 dividend-to-price ratio D/P($dp_t^f$),即上述 4 个因子对应的股息收益率。合计 8 个状态变量。
这个选择背后有两篇文献的支撑。Kozak, Nagel and Santosh (2020) 表明,少数几个主成分能解释大截面预期收益——4 个因子收益合计解释了 102 个组合收益变异的 93.3%。Haddad, Kozak and Santosh (2020) 进一步表明,这些主成分的估值比率(D/P)在时间序列上强力预测其未来收益和 SDF 风险价格。换言之:因子收益捕捉截面定价,因子 D/P 捕捉时序动态。两者合在一起,构成了一个既能解释截面又能描述动态的状态向量。
在此基础上,GKK 还施加了两个关键约束。第一,SDF 的冲击完全由因子收益冲击张成,即定价信息来自收益本身。第二,因子 D/P 包含了关于未来的全部信息:控制了滞后 D/P 之后,滞后收益率对未来收益率和 D/P 均不再有预测力。这与大量实证文献一致——股息收益率对未来收益的预测力,远强于滞后收益率本身,GKK 直接将这一规律作为假设加入模型。
参数估计上,GKK 采用的是广义矩估计(GMM)方法。这背后的原因很直观:模型要对 102 个组合、横跨近 50 年的月度收益率和股息率数据同时定价,参数之间还存在跨方程的约束,须借助 GMM 这种能一次性处理所有方程的系统估计工具。
这套估计流程有一个至关重要的特点:整个过程中,矩条件里只有 102 个股票组合的收益率和股息率数据,完全没有引入任何 dividend strips 的价格信息。这意味着,在参数估计阶段,模型对“股息期限结构”一无所知。而这,恰恰为接下来最关键的样本外验证埋下了伏笔——用从未见过的真实 dividend strips 数据,去检验模型预测的准确性。
3
有了估计好的 SDF,dividend strips 的定价就成了一个纯粹的计算问题。
在无套利定价框架下,任何资产的当前价格都等于其未来现金流与 SDF 的乘积的期望值,而 GKK 的仿射设定让这个期望值有解析解。这意味着,只要知道当前的状态 $F_t$(这些都可以从股票数据中直接观测或构造),就能直接算出任意期限 $n$ 的 dividend strip 价格,而不需要任何额外的估计。
有了价格,就可以定义 equity yield——它相当于 dividend strip 的“到期收益率”。GKK 沿用 van Binsbergen et al. (2013) 的定义:
$$
y_t^{(n)} = -\frac{1}{n} \log \left( \frac{P_t^{(n)}}{E_t[D_{t+n}]} \right)
$$
如果再结合无风险利率的期限结构数据,还能得到远期股息收益率(forward equity yield):
$$
f_t^{(n)} = y_t^{(n)} + \frac{1}{n} \sum_{i=1}^{n} r_t^{f, (i)}
$$
至此,GKK 从股票横截面数据出发,走完了全程:从状态变量到 SDF,从 SDF 到 dividend strips 的解析定价,最后生成可观测的期限结构数据。接下来要做的事情很自然——用真实市场上的 dividend strips 数据,来检验模型算出的这些值到底准不准。
GKK 将模型隐含的 1 年、2 年、5 年、7 年远期股息收益率,与 Bansal et al. (2021) 的实际交易数据对比(由于数据可得性,此处用的 Traded S&P 500 Dividend Forwards)。结果(下图)显示,时间序列走势高度吻合,金融危机期间的期限结构倒挂,模型准确捕捉。模型从未见过 dividend strips 数据,却能复现它的主要特征。
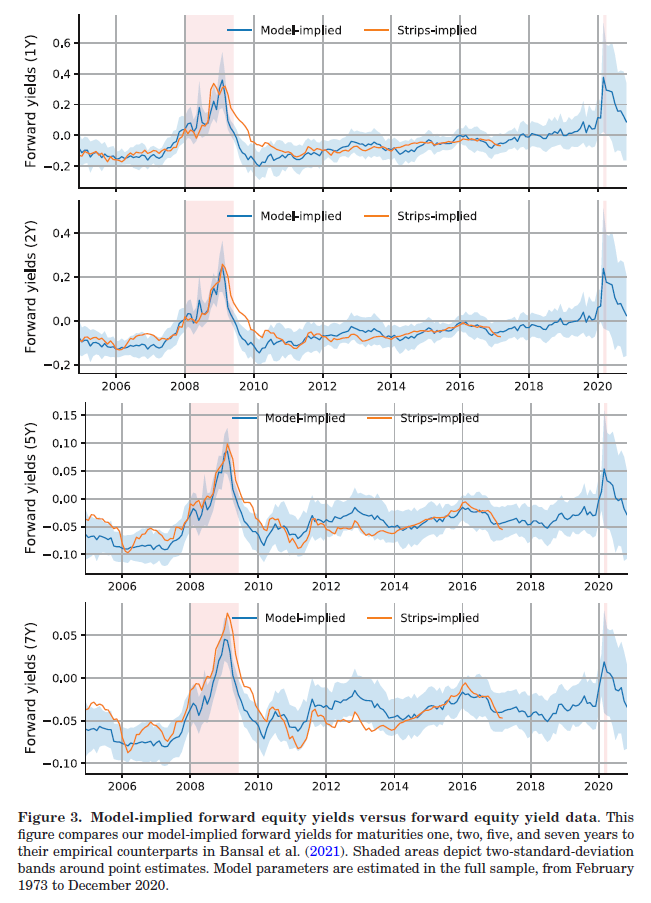
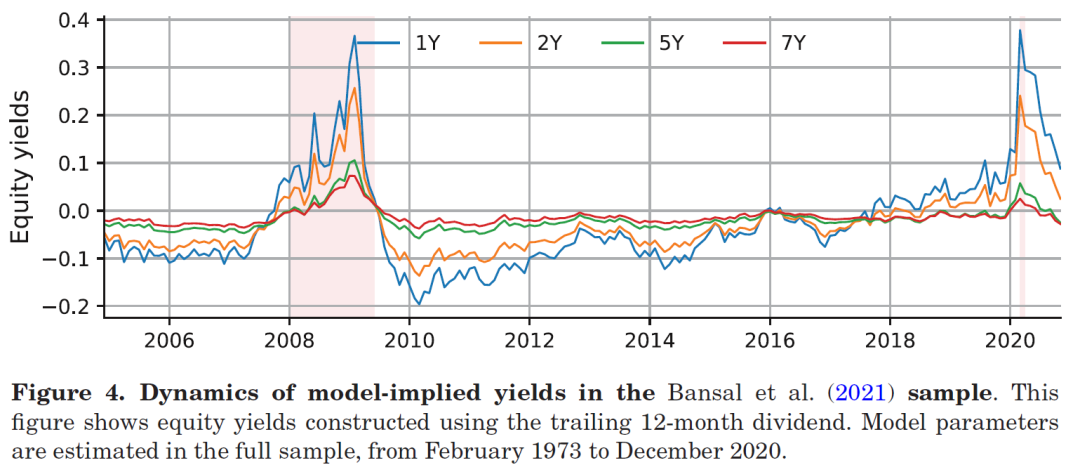
验证完模型,GKK 开始挖掘新事实。将样本延伸至 1970 年代,他们发现期限结构在几乎所有衰退期间均倒挂——不只是金融危机,1980 年代初、1990 年代初、新冠均如此;扩张期间期限结构温和上倾,但统计上不显著;短期股票收益率的波动,主要由股息增长预期驱动,而非折现率变化。
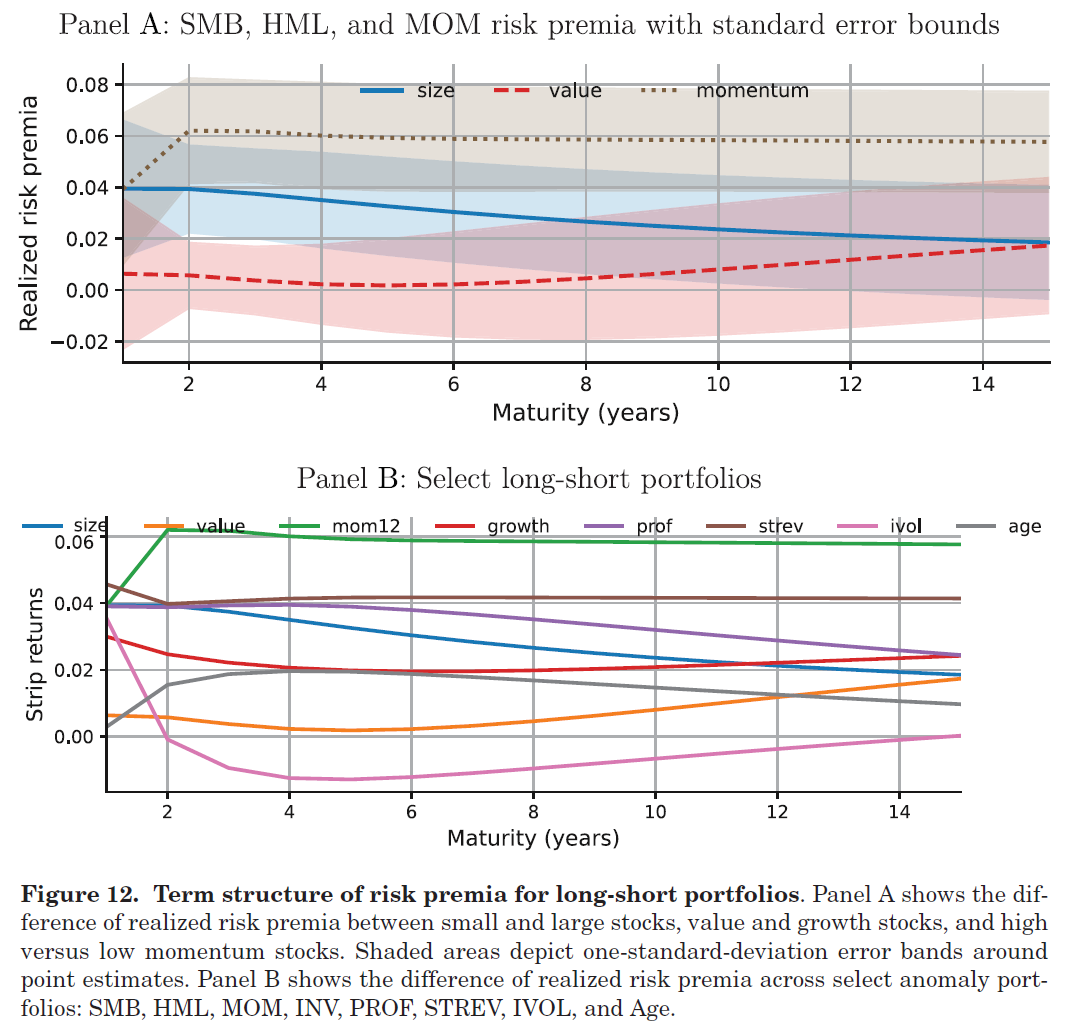
再来看看 cross-section。GKK 为 102 个组合各自生成了一条期限结构曲线。SMB 的期限结构向下倾斜,HML 的期限结构向上倾斜,动量呈非单调形态,特质波动率则先陡降后温和上升。SMB 和 HML 都有正的无条件风险溢价,但期限结构形状截然相反。这意味着:小盘股的风险溢价集中于短期,而价值股的风险溢价集中于长期。任何试图同时解释 size premium 和 value premium 的模型,都必须能够复现这一差异。这是对资产定价模型的精细约束,也是 GKK 这套方法最有价值的地方之一——它把稀缺的 dividend strips 数据,变成了一个覆盖 40+ 年、102 个组合、任意期限的期限结构面板,大幅丰富了模型评估的信息集。
4
读完这篇论文,几点感受。
第一,模型设计的选择至关重要。GKK 的成功,很大程度上来自状态向量的精心选择。他们自己也做了稳健性检验:CAPM 和 Fama-French 五因子模型均无法复现 dividend strips 数据的动态特征。简约但设计得当的模型,胜过复杂但设计随意的模型。(这也是为什么我喜欢经济学直觉强的研究,而非复杂模型的“无脑”堆砌。)
第二,样本外验证的价值不可低估。GKK 的模型从未见过 dividend strips 数据,却能复现它的主要特征——这是一个真正意义上的样本外检验,而非事后调参的结果。在实证资产定价中,这样的验证难能可贵。
第三,这套方法的应用场景广泛。私募股权估值、气候变化投资的折现率选取、资产定价模型的校准——这些场景都可以使用。该论文的代码和数据已公开在 Kozak 的个人主页上,这类模型的应用属于数据科学与金融工程结合的典范,值得在云栈社区这类技术论坛中深入探讨。
当然,这套方法也有其局限。模型隐含的 dividend strips 价格终究是模型的产物,而非直接观测值。在使用这套数据时,这一点值得牢记。
总体而言,GKK 做了一件很漂亮的事:他们用一个设计精良的模型,把稀缺的数据变得丰富,把短暂的历史变得悠长,把单薄的截面变得厚实。
这不是魔术。这是好的模型应该做的事。
References
- Bansal, R., S. Miller, D. Song, and A. Yaron (2021). The term structure of equity risk premia. Journal of Financial Economics 142(3), 1209–1228.
- Giglio, S., B. Kelly, and S. Kozak (2024). Equity term structures without dividend strips data. Journal of Finance 79(6), 4143–4196.
- Haddad, V., S. Kozak, and S. Santosh (2020). Factor timing. Review of Financial Studies 33(5), 1980–2018.
- Kozak, S., S. Nagel, and S. Santosh (2020). Shrinking the cross-section. Journal of Financial Economics 135(2), 271–292.
- van Binsbergen, J. H., W. Hueskes, R. S. J. Koijen, and E. Vrugt (2013). Equity yields. Journal of Financial Economics 110(3), 503–519.
 发表于 2026-3-17 03:01:27
|
查看: 153|
回复: 0
发表于 2026-3-17 03:01:27
|
查看: 153|
回复: 0
