
本文目录
- 为什么需要万卡乃至三万卡规模
- 这个集群到底有多大:3万卡的真实规模感
- Spine-Leaf:AI集群网络的骨架
- scaleFabric400 与 SuperTunnel 核心设计解析
- 国产方案 vs NVIDIA InfiniBand:差距在哪
- 国产AI基础设施的未来在哪里
01、为什么需要万卡乃至三万卡规模
在深入技术架构之前,我想先回答一个很多朋友都会有的疑问:我们真的需要动用3万张GPU吗?
答案是:不仅需要,这个规模可能很快也会变得不够用。
驱动这一切的是大语言模型参数规模的指数级增长。从2020年GPT-3的1750亿参数,到2024年前沿模型突破万亿参数,年均增长约10倍。其背后的底层逻辑是Scaling Law——简单来说就是,参数越多、数据越多、算力越强,模型就会越“聪明”,并且这个趋势目前还看不到天花板。

训练一个千亿甚至万亿参数的AI大模型,单张卡连装下模型参数都做不到,更别说计算了。于是,我们必须将模型拆解,分布到成千上万张卡上进行并行计算。这就引出了三种核心的并行策略:

当这三种并行策略协同工作时,意味着集群网络必须同时承受两种压力:高频率、低延迟的节点内通信,以及大带宽、稳定的跨节点集合通信。而要达到60%以上的模型算力利用率(MFU),网络性能是决定性的瓶颈,几乎没有其他因素比它更重要。

02、这个集群到底有多大:3万卡的真实规模感

让我们用数字来感受一下这个集群的庞大规模:

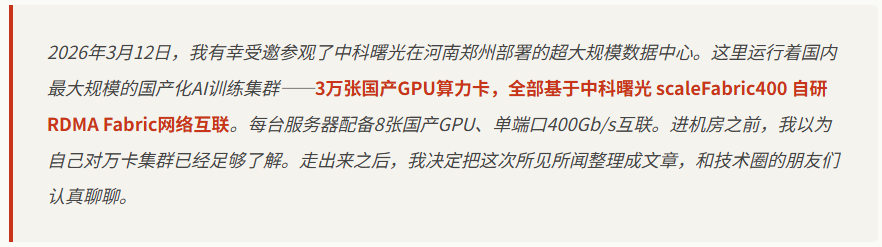
总计3万张算力卡,按每台服务器搭载8张GPU计算,共需要3,750台服务器。中科曙光此次采用了“算存网一体化”的 scale X(S-X)架构,以浸没式相变液冷机柜为基本部署单元。单台机柜可集成640张高密度加速卡。如此算来,3万卡仅需约47台scale X机柜;每两台设备组成一个拥有1,280张卡、算力高达640 PFlops的计算单元。单机柜最高支持860 kW的惊人功率密度,远超传统风冷方案,使得整体数据中心的PUE可低至1.04。
光模块的规模更是令人惊叹。在这个量级的集群中,网络芯片、交换链路、端口及光模块的数量已接近百万量级。曙光为此设计的智能运维系统(AI Info)能够支持对百万级设备端口和光模块进行集中监控与自动化配置。这套系统背后,是长达10个月的产品验证与累计1,100万小时的端口链路测试数据作为支撑。
03、Spine-Leaf:AI集群网络的骨架
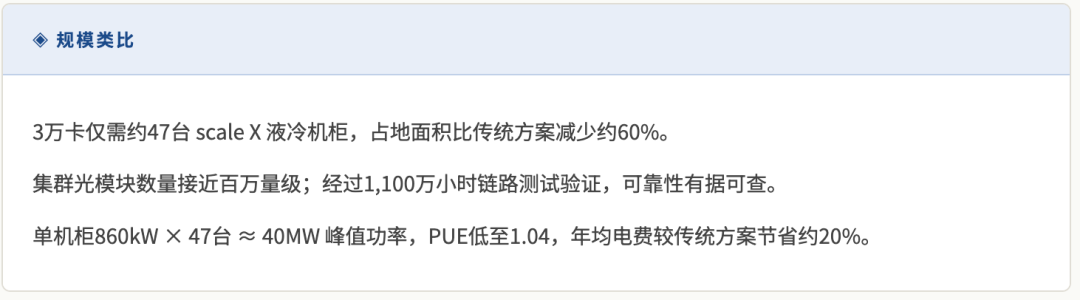
要理解scaleFabric,必须先搞清楚为什么AI训练集群普遍采用 Spine-Leaf架构(脊叶架构)。
传统数据中心网络多为三层架构:接入层→汇聚层→核心层。这种架构在处理南北向流量(客户端与服务器之间)时表现良好,但AI训练的流量模式截然不同——它以东西向流量为主,是服务器与服务器之间密集的通信,并且经常是“所有节点同时与所有其他节点通信”(AllReduce)。在三层架构下,汇聚层极易成为严重的性能瓶颈。
Spine-Leaf只有两层,每台Leaf交换机都直接上联到所有的Spine交换机。这样,任意两台服务器之间的通信路径长度和跳数都是固定的(2跳)。这带来了两个关键优势:低延迟(路径最短)和带宽均等(没有单点瓶颈)。
04、scaleFabric400 与 SuperTunnel 核心设计解析
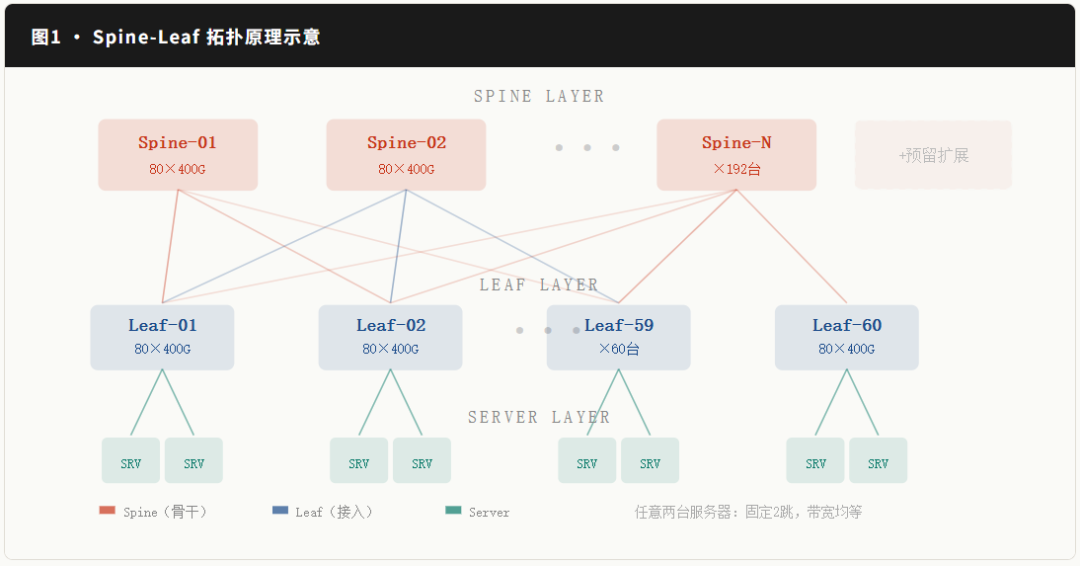
曙光scaleFabric并非单一产品,而是一套专为万卡级AI训练设计的网络体系化方案。此次参观的集群采用了最新的 scaleFabric400 交换机(提供1U液冷和2U风冷两种形态),搭配自研的RDMA Fabric协议(定位对标InfiniBand,实现全链路自主可控)以及SuperTunnel通信优化技术。整个方案包含四层清晰的技术栈:
在现场,令我印象最深的技术是 iLossless 智能无损网络。要理解它的重要性,首先要明白AI训练集群最害怕什么:丢包。
AI训练广泛使用RDMA协议来绕过CPU,实现GPU之间的直接内存访问。RDMA协议对丢包极度敏感——一旦发生丢包,协议栈需要触发重传机制,AllReduce集合通信中的某一个环节被卡住,就会导致其他数千张卡集体等待。在万卡规模下,即便是0.01%的微小丢包率,也足以导致训练吞吐量大幅下降。
在基于RoCEv2的方案中,防止丢包的传统手段是PFC(优先级流量控制)——当下游缓冲区即将填满时,向上游发送暂停信号。但PFC有一个严重缺陷:暂停信号可能像多米诺骨牌一样在网络中逐跳传播,最终引发“PFC风暴”,导致整个网段陷入拥塞甚至瘫痪。
参观中工程师强调,SuperTunnel最大的工程价值在于开箱即用。传统高性能网络方案的调优往往需要资深网络工程师耗费数月时间,而SuperTunnel的AI训练通信模式感知机制能够自动适配不同模型的流量特征。实际案例也印证了这一点:曙光已在国家超算互联网核心节点部署了3套万卡集群,从设备上架到服务上线,全程仅用了36小时。
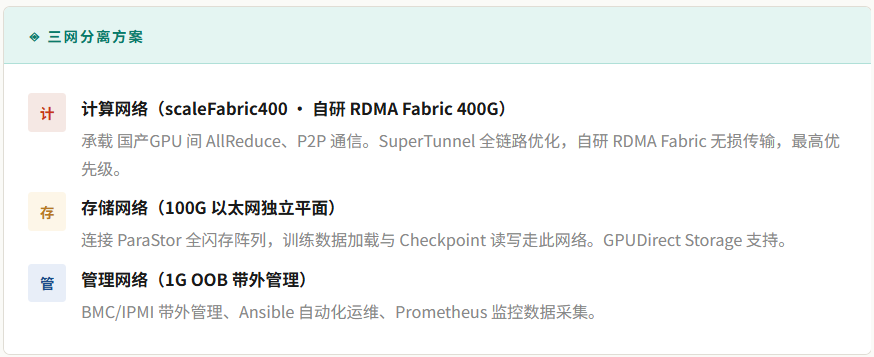
此外,scaleFabric400延续了“三网分离”的设计理念——计算网络、存储网络、管理网络在物理上完全隔离,从而避免Checkpoint大文件写入等高I/O操作影响AllReduce训练通信的延迟。scale X架构通过“算存网一体化”,进一步将这三张网络在机柜级别进行统一管理与优化,这是对传统分散部署模式的系统性升级。
05、国产方案 vs NVIDIA InfiniBand:差距在哪
这是整篇文章中最敏感也最关键的部分。参观结束后,我与几位工程师深入探讨了这个问题,力求客观地梳理差距与优势。有一点特别值得指出:在QP支持量(856K vs 128K)和最大组网规模(11万 vs 5万)这两个关键指标上,scaleFabric400已经实现了对NVIDIA IB的局部超越。这说明差距并非全面落后,而是存在选择性的技术取舍。
从下表的对比中可以清晰看出,国产RDMA Fabric方案与NVIDIA InfiniBand的差距集中在五个具体维度:

看清这五个差距的性质,才能客观评估国产方案的真实竞争力。其中,①④属于时间和资源投入问题,是可以追赶的;②是硬件级创新问题,难度大但并非不可能;③是生态构建问题,难度最高、耗时最长;⑤是体系化协同问题,需要产业链整体配合。
06、国产AI基础设施的未来在哪里
离开机房前,我与该数据中心的首席架构师进行了一个多小时的交流。他的一句话让我深思:

在我看来,国产AI基础设施的未来可以从三个维度来观察:
第一,硬件参数正在不断创下新高。 国产GPU产品线持续迭代,而scaleFabric400网卡高达856K的QP支持量(约为NVIDIA ConnectX-7的6.7倍)已在关键指标上实现反超。这意味着,在十万卡以上的超大规模集群中,国产方案的并发通信能力具备了技术领先的潜力。同时,GPU算力与交换芯片速率(从100G到400G)也完成了重要的代际跨越。
第二,软件生态是真正的长期赛点。 NVIDIA最深的护城河并非H100芯片本身,而是其积累了近20年的CUDA生态——包括丰富的算子库、强大的调优工具和稳固的开发者习惯。国内的CANN等生态正在加速完善,但这绝非一两年可以追平。最现实的路径是:在兼容PyTorch、JAX等主流框架的同时,于关键应用场景提供同等甚至更优的性能体验,从而逐步建立起用户的信任。
第三,“国产化”本身正在升级为“自主创新”。 我在参观中看到的iLossless、scaleOS等技术,已经不再是简单的替代品,而是在特定技术场景下融入了自身深刻见解的原创方案。当国产方案开始在某些细分技术维度上实现超越,才是真正的质变起点。这一天,或许比许多人预期的要来得更早。
参观结束的傍晚,我站在数据中心门口,回望那座低矮却占地广阔的建筑。里面3万张算力卡正在持续运转,训练着某个或许明年就将改变某个行业的AI模型。
国产AI基础设施的道路依然漫长,但这条路上,已经留下了扎实而坚定的脚印。对这类前沿基础设施技术的持续追踪与讨论,正是像云栈社区这样的技术社区存在的价值之一。
 发表于 2026-3-17 04:29:50
|
查看: 266|
回复: 0
发表于 2026-3-17 04:29:50
|
查看: 266|
回复: 0
