流控与反压是芯片数据通路设计的核心机制。为了便于讨论,我们先明确两个名词的基本含义:
- 反压 (Backpressure):接收端因自身资源不足(如缓冲区满、处理忙),向发送端传递信号以暂停或减缓数据发送的机制,是一种被动式调控手段。
- 流控 (Flow Control):对数据流的传输速率或传输量进行规划与限制,以避免接收端过载,可分为被动流控和主动流控,覆盖“发送-传输-接收”全链路。
本文将从实战角度出发,梳理在芯片设计中常见的几种流控方案及其典型应用场景。
一、没有流控的系统
没有流控的系统,从流控角度看结构最简单,但也常常需要额外的逻辑来适配上下游的流控需求。
典型的无反压模块包括:
- SRAM:发出读/写请求后,固定周期返回数据或完成写入,既不反压上游,也不接受下游反压。若下游未及时取走数据,下一拍数据可能被覆盖。
- 运算单元:如纯组合逻辑或多级流水线运算器(例如三级流水除法器)。输入使能有效后,固定延迟周期产生输出使能。
- 流式接口:如DPHY/MIPI图像采样接口、VGA显示接口。数据采到或产生后必须立即送出,否则会影响后续数据流。
- 低速接口:在特定模式下,UART、SPI、I2C等接口可能也无内置流控机制,依赖速率匹配。
这类模块通常采用流处理型接口,信号可能包括 enable(数据有效)、info(数据)、sop/eop(帧头/尾)、error(错误指示)等,甚至只有固定的输入输出时序关系。
如何将无反压模块集成到有流控的系统中?通常需要补充控制逻辑:
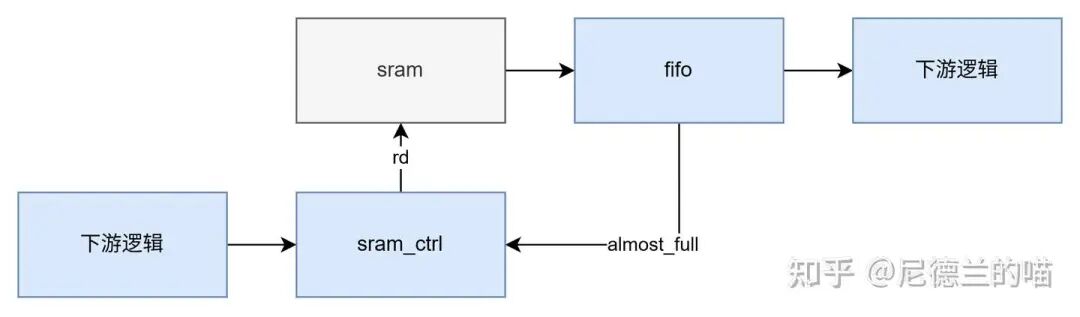
- 对于SRAM读操作:典型做法是在其后增加一个FIFO,利用FIFO的
almost_full 信号来判断是否可以发起对SRAM的读请求,确保FIFO有空间容纳返回数据。
- 对于运算单元:控制逻辑只在需要计算结果且有能力接收输出时,才发起运算请求。
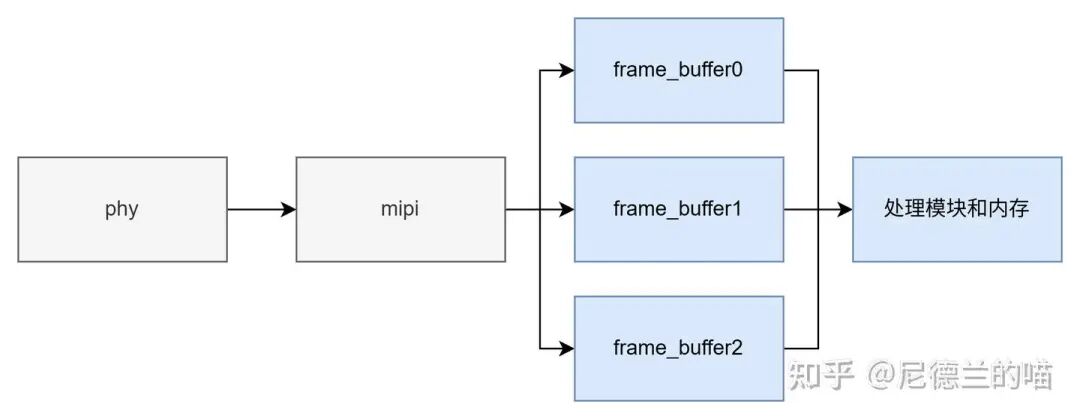
- 对于流式接口(如视频流):通常使用帧缓冲区(Frame Buffer)。发送端循环写入,接收端循环读取。当处理速率不匹配时,可采用丢帧策略适配。
| 接口/协议名称 |
核心类型 |
不支持反压/流控的原因 |
典型应用场景(芯片设计) |
| SRAM读写接口 |
芯片内部存储接口 |
读写延迟极低(1-2周期),可即时响应,无反压需求;依赖速率匹配。 |
CPU与SRAM交互、运算单元与缓存读写 |
| MIPI DPHY接口 |
高速图像传输接口 |
发送与接收速率严格匹配,接收端实时处理,无内置流控。 |
手机摄像头与ISP连接 |
| VGA接口 |
模拟显示接口 |
模拟信号持续输出与解析,无数据缓冲堆积需求。 |
传统显示器连接、嵌入式显示输出 |
| GPIO(简单场景) |
通用IO接口 |
低速开关信号,可即时采样处理,无数据堆积风险。 |
LED控制、按键输入 |
| SPI接口(低速模式) |
串行同步接口 |
低速模式下可实时接收处理,无反压设计;依赖速率匹配。 |
连接低速传感器、EEPROM |
| I2C接口(标准模式) |
串行半双工接口 |
标准速率下(≤400kbps)可即时处理,ACK仅用于确认而非流控。 |
连接温湿度传感器、OLED屏 |
| LVDS接口(简单显示) |
低压差分显示接口 |
显示信号持续输出与实时解析,依赖速率匹配。 |
工业显示器、平板设备显示传输 |
二、逐级反压
逐级反压即反压信号沿数据路径反向、逐级传导。
- 广义:在模块或系统级串联链路(TX → M1 → M2 → RX)中,末端阻塞引发的反压逐级向前传播。
- 狭义:在寄存器级流水线中,下游寄存器反压其直接上游寄存器。

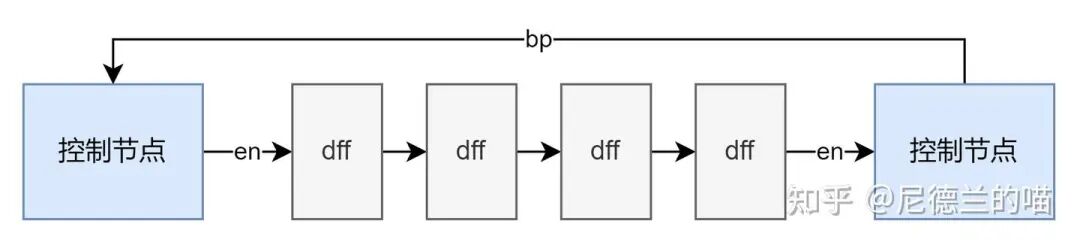
支持反压的使能型接口通常有两个关键信号:enable(上游数据有效)和 bp 或 xoff(下游反压)。上游发送数据前,必须确认下游未反压(即 enable 可依赖于 bp)。FIFO的写接口就是一个典型例子:
input clk;
input rst_n;
input winc;
input [WIDTH-1:0] wdata;
output wfull;
output almost_wfull;
input rinc;
output [WIDTH-1:0] rdata;
output rempty;
output almost_rempty;
其中的 wfull 信号即用于逐级反压。若 wfull=1 时仍写入 (winc=1),将导致数据覆盖或丢失。
反压的粒度可以灵活定义,如按拍、包、帧或突发传输的末尾进行反压。完备的流控系统常包含多粒度反压机制作为保险。
在实际设计中,逐级反压更常见于握手接口的互连场景。

使能型接口与握手型接口的核心区别:
- 使能型 (enable-xoff):发送端需要关注接收端状态。
enable 置起前需确认 xoff 无效(enable 依赖于 xoff),置起后即认为接收端已接收。enable 通常为脉冲。
- 握手型 (valid-ready):发送端无需关注接收端瞬时状态。有数据时置起
valid 即可(valid 不依赖于 ready)。接收端在 valid && ready 同时有效时才接收数据。valid 需维持到 ready 有效为止,通常为电平。
优缺点分析:
- 优点:逻辑简单、行为明确、与AMBA AHB/APB/AXI等标准协议适配性高。
- 缺点:每级均需响应反压,逻辑开销大;反压信号组合路径可能影响时序;设计不当易产生死锁或振荡;模块在不同深度流水线中复用性差。
三、超前反压
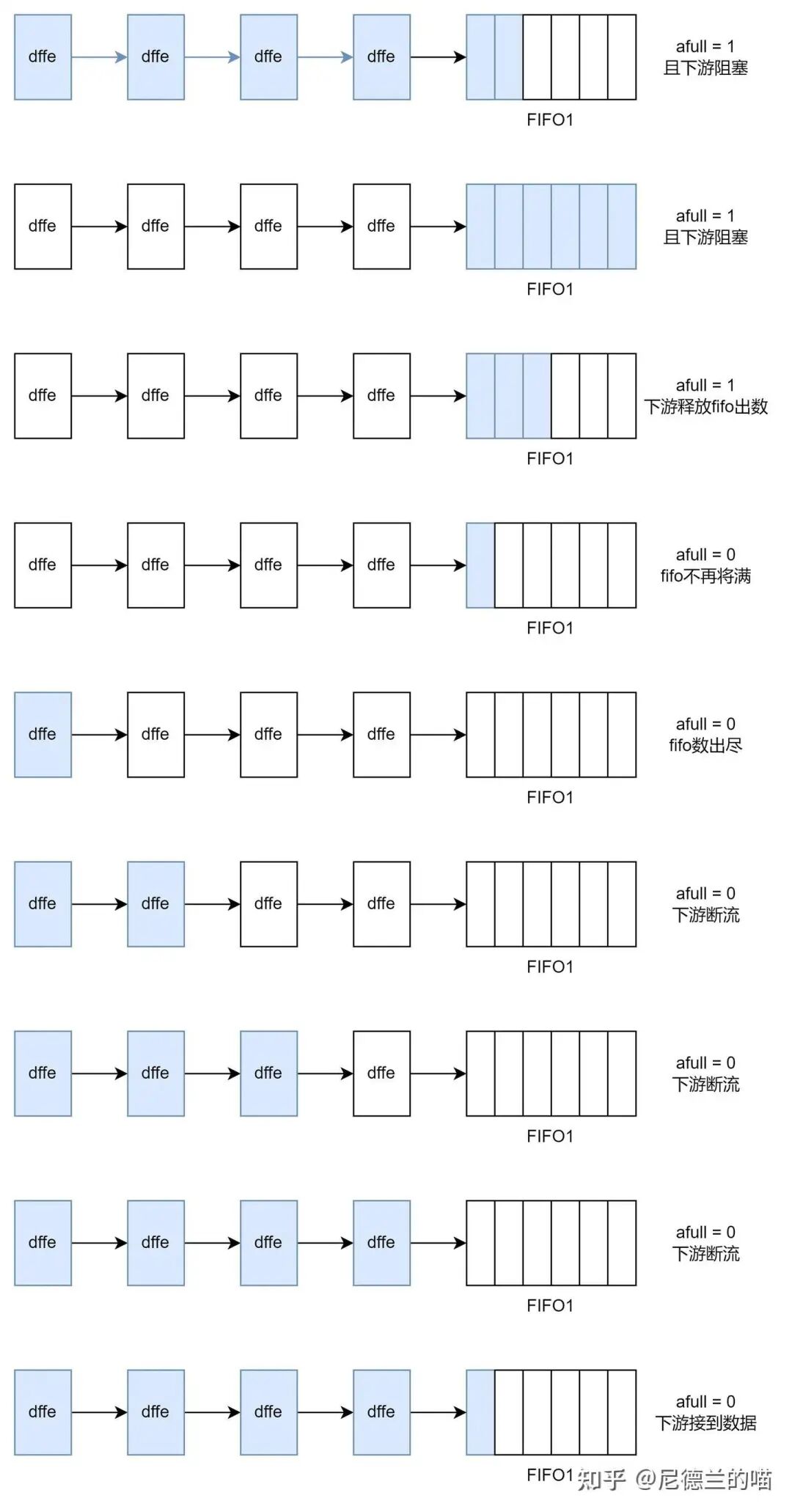
为克服逐级反压逻辑开销大、时序路径长的问题,可采用超前反压。其核心思想是:接收端或中间模块提前(基于预警阈值)向远端发送端或前级控制节点发出反压信号,无需逐级传导。
简单说,反压信号跨越中间流水线寄存器,直接送达前端的控制节点。
最常见的例子依然是FIFO的 almost_full 信号。它提前告知上游控制节点:“我即将满,请停止发送”。上下游必须精确配合,否则会导致数据溢出或性能损失。
关键设计在于FIFO深度、将满水线(almost_full阈值)与上游流水线级数的匹配:
- 水线过深(反压过晚):反压信号发出后,已在管道中的“过冲”数据会使FIFO溢出。
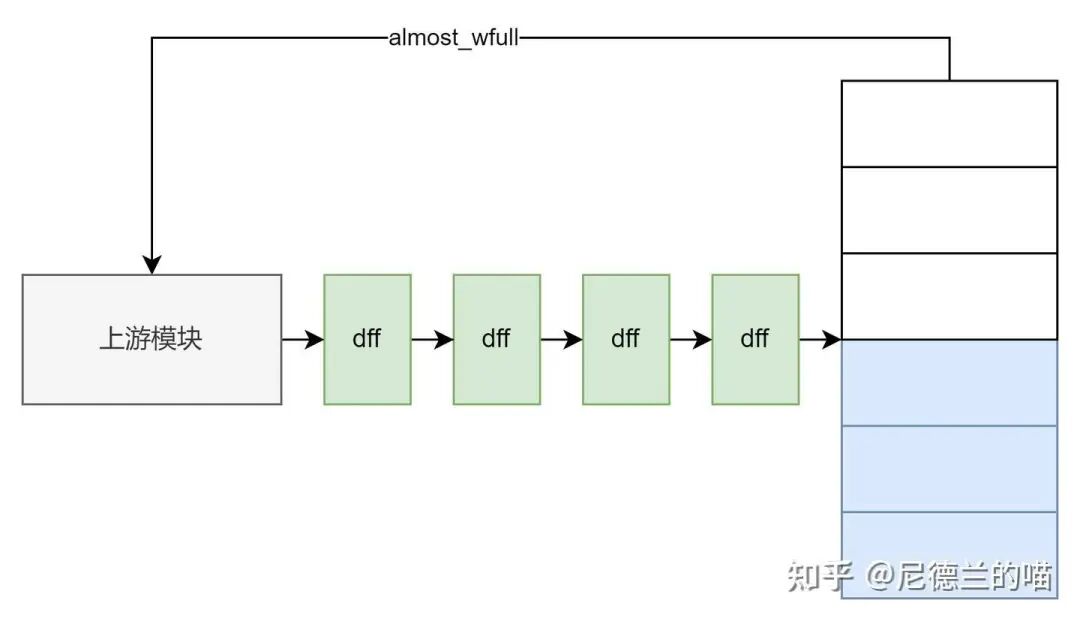
- 水线过浅(反压过早):FIFO远未满时即停止接收,导致下游断流,利用率降低。
| 应用场景 |
核心问题 |
典型实现机制 |
核心目的 |
| FIFO/缓冲队列管理 |
等缓冲区全满再反压已晚,数据在途会导致溢出。 |
使用 almost_full / almost_empty 水位阈值信号。 |
预防溢出/断流,为反压传播提供时间缓冲。 |
| 总线仲裁与带宽管理 |
单一主设备突发流量可能独占资源,饿死其他设备。 |
基于目标端资源水位预警,提前限制仲裁授权。 |
实现公平调度,预防拥塞,保证服务质量。 |
| 长流水线气泡预防 |
末端堵塞导致的反压沿长流水线传播,产生长气泡。 |
在级间插入缓冲队列并设置超前反压阈值。 |
隔离上下游速度差异,吸收波动,保持流水线高效。 |
| 片上网络拥塞控制 |
局部节点拥堵会迅速扩散,导致网络性能骤降。 |
路由器监控下游节点缓冲区水位,提前调整路由或限流。 |
局部化拥塞,防止扩散,维持全局吞吐与低延迟。 |
四、接收端Credit流控
Credit流控是一种基于资源预约的机制。接收端预先向发送端分配一定数量的“信用”,代表其可接收的数据量(如帧数、字节数)。发送端每发一个数据单元,消耗一个Credit;Credit耗尽则必须暂停发送。接收端处理完数据、释放资源后,向发送端补充Credit。

Credit机制属于事务级或业务级流控,层级高于时序级的反压握手。常见协议包括:
| 协议/标准 |
主要应用场景 |
Credit机制的核心作用 |
| AMBA CHI |
高性能多核SoC、芯片间一致互连 |
通过协议层和链路层分层信用,实现高带宽、低延迟事务传输,隐藏长路径延迟。 |
| PCI Express |
板级设备互连、加速卡连接 |
实现可靠、无损的端到端传输,管理虚拟通道流量,是链路层流控基础。 |
| InfiniBand |
超算集群、高性能存储网络 |
作为链路层核心流控,为RDMA提供极低延迟、高吞吐的无损网络保障。 |
| CCIX / CXL |
芯片间缓存一致性扩展、内存池化 |
继承增强PCIe信用机制,支持更复杂、时效性要求更高的事务和内存访问。 |
| 以太网(无损) |
数据中心网络(如RoCEv2) |
在交换机/网卡中实现无损传输与高级拥塞控制,保障关键流量服务质量。 |
| 片上网络 |
多核SoC内部、大型芯片互连 |
管理虚拟通道缓冲区,预防死锁和局部拥塞扩散,优化全局数据流。 |
以 AMBA CHI 协议为例,其核心是用分层的Credit流控替代实时握手:
- 协议层信用(P-Credit):管理事务请求流量,防止归属节点被过多请求淹没。
- 链路层信用(L-Credit):确保物理链路数据包可靠传输,最大化链路利用率。
Credit的消耗与补充异步进行,将“停顿”转化为“调速”,使数据流平滑,彻底解决了长距离互连中握手反压的性能瓶颈。
PCIe的Credit流控要点:
- 分类管控:分为完成包信用(CL)、请求包信用(RL)、非Posted包信用(NL),适配不同类型数据,避免单一缓冲区阻塞整体链路。
- 工作流程:链路初始化时接收端广播初始Credit额度 → 发送端按类型消耗Credit发送 → Credit耗尽则暂停该类型发送 → 接收端处理完毕后补充Credit。
- 设计关键:Credit额度需匹配接收端缓冲深度(通常80%-90%);补充时序需极快(1-2周期),以避免发送端长时间停顿。
一个常见问题是:有了Credit机制,是否还需要链路级的时序反压?答案是视情况而定。例如,在跨异步时钟域的数据通路上,即使接收端有能力,数据在异步FIFO中也可能需要排队等待(高频打低频),此时仍需要时序级的反压机制来保证正确性。叠加不同层级的流控机制可以增强系统的稳健性。
五、Host端Credit流控
这是一种主动流控机制,通常由系统Host(如中央控制器、流量管理单元)主导,目的是进行全局带宽管理、限制流量突发与抖动。
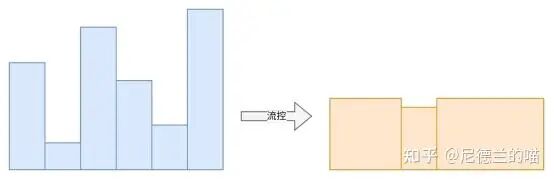
Host提前为各个从端或用户分配Credit额度,限制其发送速率和总量。从端发送时消耗自身Credit,耗尽则暂停。Host根据系统整体负载动态调整各端的Credit分配策略。
| 典型应用场景: |
应用场景 |
机制简述 |
解决的问题与价值 |
| 多核SoC服务质量与公平性 |
归属节点作为Host,根据优先级、带宽配额动态调节分配给各请求节点的协议层Credit。 |
防止高性能核心独占资源,确保IO、低功耗核等获得必要带宽,实现系统级QoS。 |
| 芯片间互连资源管理与隔离 |
在CXL等场景中,Host CPU主动管理分配给各设备(加速卡、内存卡)的Credit。 |
实现资源隔离,防止单一高负载设备耗尽Host资源,确保系统稳定,支持多租户资源池化。 |
| 动态功耗与热管理 |
Host根据功耗预算或温度反馈,动态减少向非关键/高功耗组件发放的Credit。 |
将功耗管理从“开关式”转变为“调速式”,精细控制能效与温升。 |
| 防止拒绝服务与错误遏制 |
Host检测到节点行为异常时,主动收回或停止发放Credit,从源头限流。 |
快速隔离错误源或恶意流量,提升系统健壮性,防止局部问题扩散导致崩溃。 |
总结
流控与反压是芯片数据流管理的核心技术,不同模式适用于不同场景:
| 流控方式 |
核心控制理念 |
核心机制与信号 |
典型协议/场景 |
优点 |
缺点与挑战 |
| 无流控 |
发送者主导,不管接收者 |
有数据就发,无反向控制信号。 |
SRAM、MIPI DPHY、VGA等速率严格匹配场景。 |
实现最简单,零开销。 |
可靠性差,极易导致数据丢失或覆盖。 |
| 逐级反压 |
接收者驱动,被动响应 |
反压信号(full)沿数据路径逐级反向传播。 |
同步FIFO、简单数据流水线。 |
概念直观,保证数据不丢失,实现简单。 |
性能低,反压传播产生“气泡”;长路径时序复杂。 |
| 握手协议 |
交互式协商(逐级反压的标准化实现) |
valid(发送方有效)与 ready(接收方就绪)双向握手。 |
AMBA AXI/AHB/APB总线。 |
标准化,灵活可靠,易于集成验证,解耦时钟。 |
吞吐量受限(≤1 data/cycle),长路径ready延迟影响性能。 |
| 超前反压 |
预测性避免,提前干预 |
基于水位阈值(almost_full)提前发出反压信号。 |
高速设计、网络交换机内部队列。 |
减少性能波动,避免缓冲区溢出,使数据流平滑。 |
需要精确预测和权衡,设计更复杂。 |
| 接收端Credit流控 |
资源预约制,接收方管理 |
接收方提前分配“信用”,发送方消耗信用发送,信用耗尽则停。 |
CHI, PCIe, InfiniBand, 片上网络链路层。 |
隐藏延迟,高吞吐,发送方可连续发送,极大提升链路利用率。 |
需额外信用管理逻辑,信用初始数量需合理设置。 |
| Host端Credit流控 |
系统级调度,中央管控 |
Host主动、策略性地向各请求节点分配协议层信用,并动态调节。 |
流量调度芯片、CXL设备管理。 |
实现系统级目标:QoS、公平性、功耗管理、错误隔离等。 |
设计最复杂,需要全局视图和高级调度算法。 |
在现代复杂的芯片设计中,尤其是AI加速器、网络处理器和多核SoC,多种流控方式常协同工作:
- 链路层使用 Credit流控 保证高吞吐与低延迟。
- 模块内部使用 超前反压 保护FIFO和关键缓冲区。
- 系统层面使用 Host端Credit流控 进行全局QoS调度和资源管理。
- 关键时刻仍保留 逐级握手 作为底层、可靠的最终保险。
理解和灵活运用这些流控方案,是每一位芯片设计工程师(尤其是数据通路设计者)的核心技能之一。希望本文的梳理能为大家的系统设计提供参考。欢迎在云栈社区继续交流探讨相关技术细节。

 发表于 2026-3-18 06:12:08
|
查看: 340|
回复: 0
发表于 2026-3-18 06:12:08
|
查看: 340|
回复: 0
