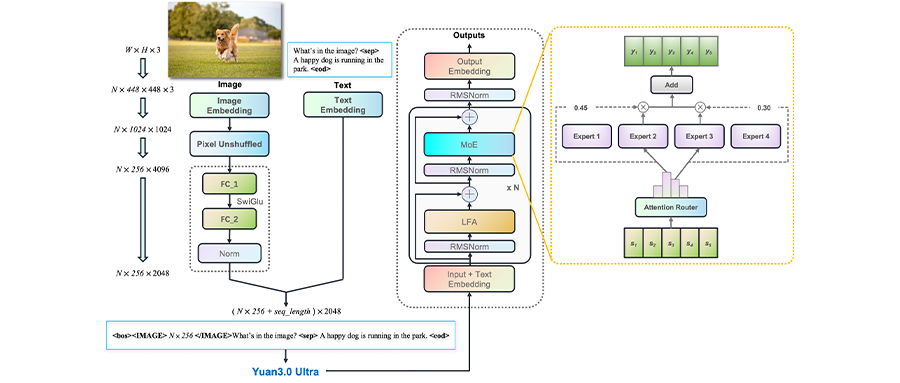
告别Token老虎,给大模型来了个“减脂增肌”。
当前,AI智能体火爆全球,从消费者到企业,纷纷开始探索应用。但在部分提高效率的同时,这类应用所带来的问题也同样突出。
除了数据安全,处理复杂任务分分钟烧掉海量Token的问题也困扰不少用户,干活一时爽,一看账单傻眼。

海外有用户曝出,他只是问了一句“你好”,模型进行大量思考直接烧掉数十美元。如果说个人场景尚且可以灵活处理,但企业级AI应用落地,则必须要面对高Token消耗带来的成本挑战。
AI智能体(如OpenClaw)其实只是AI的“手脚”,背后的模型才是真正的“大脑”,要解决高消耗高成本的问题,仍然要从核心的模型入手。
当前企业在Agent模型底座的选择上面临着“两难困境”,想要高智能,就必须面对成倍Token消耗,以及推理延迟的增加,而选择低成本,则往往需要牺牲模型能力。
对企业来说,任何无效Token消耗都是真金白银的流失,因此在当下,模型效率已经成为决定企业智能的核心要素。
近来,国内AI大模型团队YuanLab.ai发布并开源了Yuan3.0 Ultra多模态基础大模型,在国内外引起较高关注。
发布当天,其在GitHub上公布了完整的模型权重、代码和技术报告:

「开源地址 」
GitHub项目:
https://github.com/Yuan-lab-LLM/Yuan3.0-Ultra
论文链接:
https://arxiv.org/abs/2601.14327
值得一提的是,这是当前业界仅有的三个万亿级开源多模态大模型之一,其最核心的创新之处在于通过LAEP技术——基于学习的自适应专家剪枝, 在不破坏功能结构的情况下剪除冗余,实现了33%的参数减少,且训练速度还暴涨了49%,输出时间缩短14%的同时准确率提高16%。
可以说是真正的鱼和熊掌兼得,成本和智能“既要又要”。
从检索增强生成(RAG)、多模态文档理解、表格数据分析、内容摘要与工具调用等任务,Yuan3.0 Ultra在多个企业级AI常常面对的核心场景和难点方面表现突出。
在YuanLab.ai团队看来,效率不是成本优化的“可选项”,而是模型能力的“组成部分”, 他们的目标就是让企业能以更少的算力开销,产生更大的智能。
Yuan3.0 Ultra证明了旗舰级智能可以通过更高效、更经济、更可控的方式实现,可以说给企业Agent落地提供了核心能力支撑。
01. 三项关键技术创新背后,如何实现“有效思考”与“极致降本”?
26年初,YuanLab.ai团队就已经发布了Yuan3.0 Flash模型,聚焦推理端效率,减少无效token消耗,通过RIRM、RAPO等核心技术创新打破了“高智能必须高Token消耗”的悖论,验证了“更少算力,并不意味着更弱能力”。
而这次发布的Yuan 3.0 Ultra旗舰模型,进一步裁除冗余专家,让模型结构更加精炼,通过LAEP、LFA、RIRM等技术实现了“不需要无节制堆算力就能获得更强智能”。
整体来看,Yuan 3.0 Ultra从预训练架构、注意力机制到推理范式,进行了全链路技术创新。基于“有效思考”技术体系,其实现了“有效规模”的进一步突破,可以说解决了大模型“参数虚高、算力浪费、落地困难”的痛点。
具体来看,其核心突破点之一是自适应专家裁剪算法(LAEP),简单来说,专家不需要更多,而在于更有效。
如果把MoE(混合专家)架构大模型比作一个百人研发团队,其核心优势本该是“专业分工、高效协作”,但在真实的工程实践中,却出现了严重的 “团队管理失控”。
MoE大模型普遍存在预训练专家负载严重不均衡的问题,训练稳定阶段最高与最低专家负载差异可达近500倍。
少数专家承担了绝大多数计算任务,而大量低贡献专家长期处于低负载状态,造成算力资源的严重浪费,也导致模型参数虚高、利用效率低下,企业落地成本居高不下。
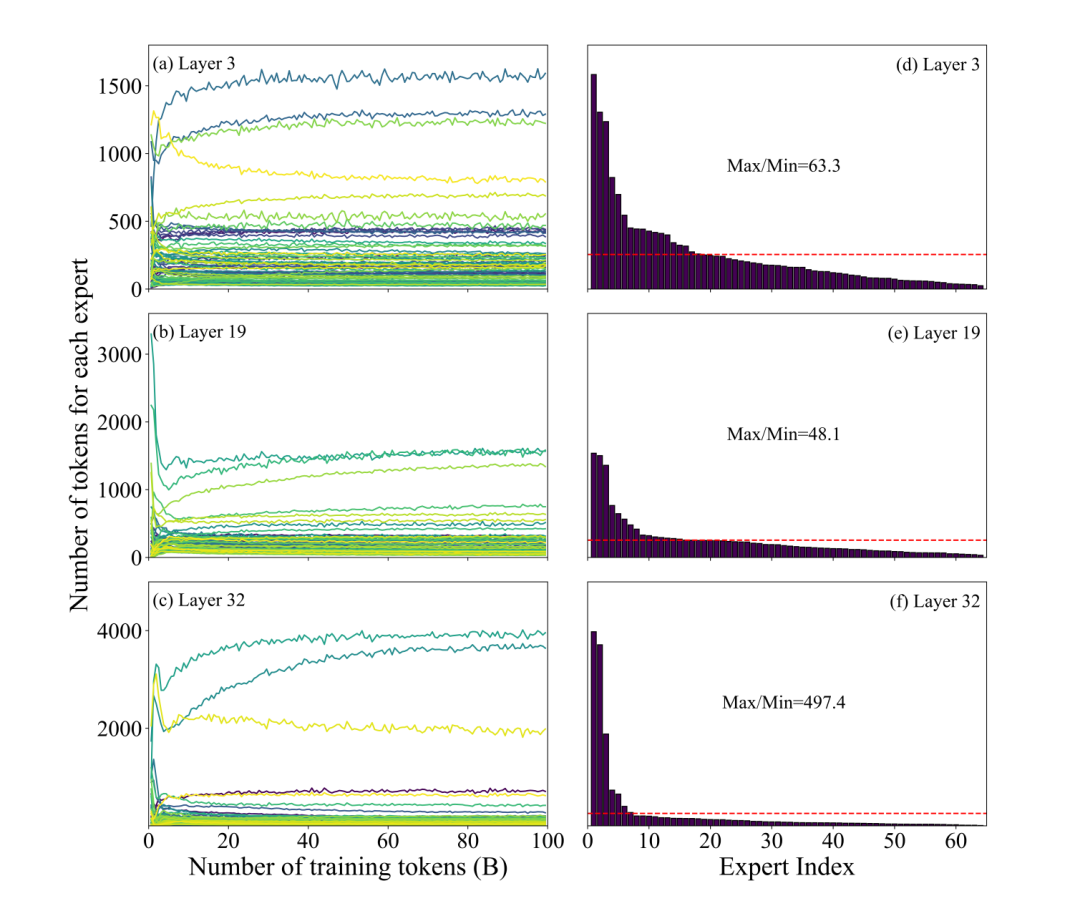
简单来说:少数几个专家干了绝大多数的活,部分专家全程“摸鱼”。
行业主流MoE模型(如Mixtral、DeepSeek-V3)普遍依赖辅助损失函数来约束专家利用率,“精度与均衡不可兼得”。
YuanLab.ai团队研发了自适应专家裁剪算法(LAEP),基于MoE模型预训练过程中自然形成的专家功能专一化规律,动态识别并剔除低贡献冗余专家,对模型结构进行自适应裁剪与专家重排。
具体来说,就是“多劳多得”、“按劳分配”,计算资源倾斜给价值和贡献更高的专家。
这一过程类比人类大脑学习过程中对神经连接的优化重组——保留高效信息处理通路,削弱低效连接,在维持甚至强化模型专业化能力的同时,提升算力利用效率。
从实际效果来看,预训练初始1515B参数优化至1010B,参数规模减少33.3%;预训练算力效率提升49%、单次推理仅激活68.8B参数;性能方面也处于头部阵营。

核心突破点之二,是语义建模能力升级,基于LFA技术强化长上下文语义关联能力。
在企业实际应用中,模型常常需要处理图文混排的财报、多页技术文档、跨文档知识检索等复杂任务。这类场景对长上下文语义关联能力要求极高——模型必须能从大量信息中精准捕捉关键内容,忽略无关干扰。
为此,Yuan3.0 Ultra引入了局部过滤注意力机制(Localized Filtering-based Attention,LFA), 实现对语义关联的精准筛选与强化,有效过滤无效注意力干扰,提升模型对长上下文、复杂语义关系的建模能力,从而更准确地理解各种信息来源的脉络。
从实际效果来看,面对企业级场景中长上下文的图文混排文档解析、跨文档知识检索、多步骤Agent推理等需求,模型在长文本、复杂结构信息处理中都能保持较高准确率。
核心突破点之三,是升级“有效思考”范式,利用RIRM+RAPO技术体系,减少无效Token。 这也是聚焦推理阶段另一核心浪费——大模型“过度反思”。
在Agent连续任务链中,大模型常常陷入“过度反思”——明明已经得出正确答案,却还要反复推敲,导致Token消耗成倍增加,响应延迟拉长。这种无效反思在复杂任务中尤为突出,是企业级AI落地的一大成本黑洞。
Yuan3.0 Ultra从强化学习层面入手,通过RIRM+RAPO两大技术创新根治这一顽疾:
反思抑制奖励机制(RIRM) 就是在万亿参数规模的大规模强化学习中,对反思次数引入精细化奖励约束,教导模型在复杂企业级任务中,获得可靠答案后主动停止无效反思,同时保留深度推理能力,从根本上修正“过度思考”行为。
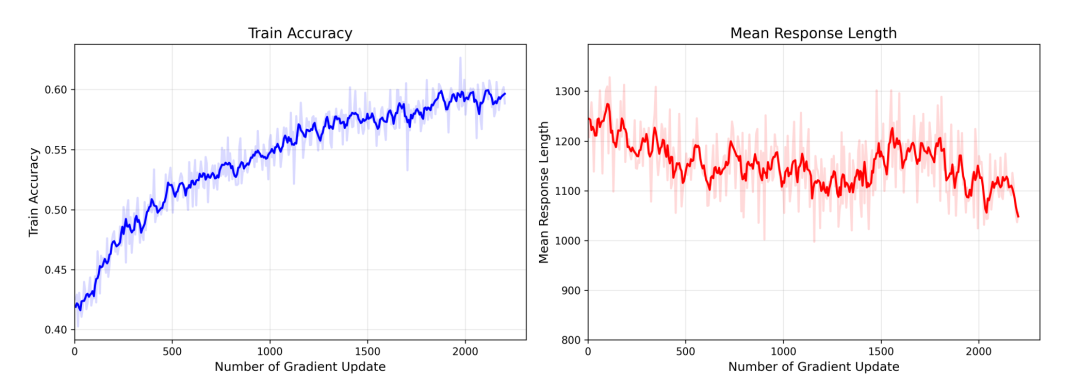
反思感知自适应策略优化算法(RAPO) 则针对万亿级MoE模型强化学习训练不稳定、效率低的行业难题,完成了算法架构的深度优化,进一步提升大规模MoE模型的训练稳定性与训练效率。
总体来看,LAEP决定了模型“用多少有效参数去学”、LFA决定了模型“如何精准捕捉有效信息”、RAPO保障了模型“如何稳定高效地学习”、RIRM明确了模型“推理到什么程度该停”。
YuanLab.ai团队一系列底层模型架构创新,让万亿级旗舰模型实现了“企业用得起、用得好、能落地”。
02. 吃透企业AI应用核心场景,五项关键能力出众
诸多技术创新加持下,Yuan3.0 Ultra在大部分核心企业场景中都有出色表现,用团队的话来说,Yuan3.0 Ultra从设计阶段就针对企业真实应用场景进行能力构建,是一个能够驱动复杂智能体(Agent)的“核心引擎”。
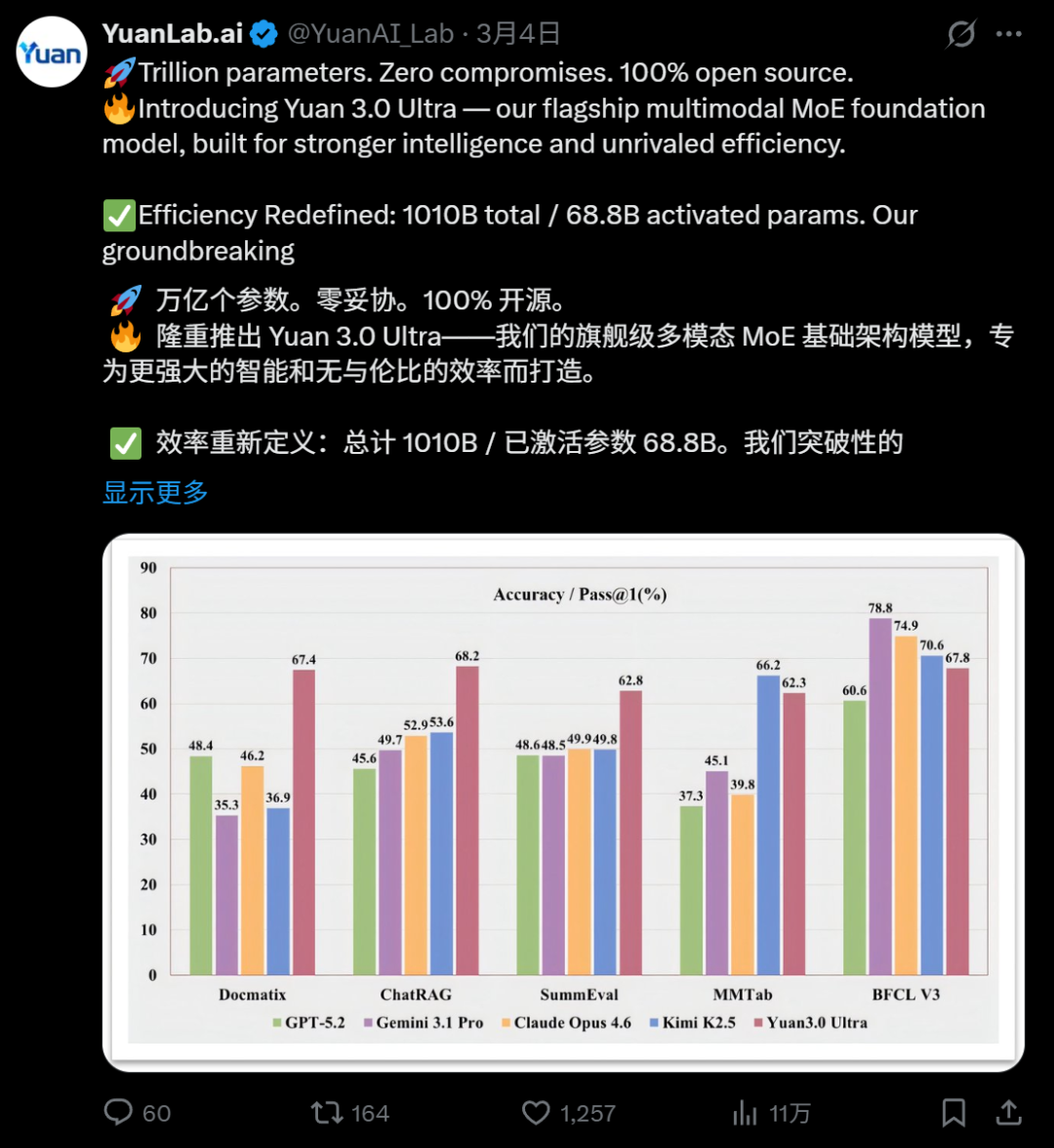
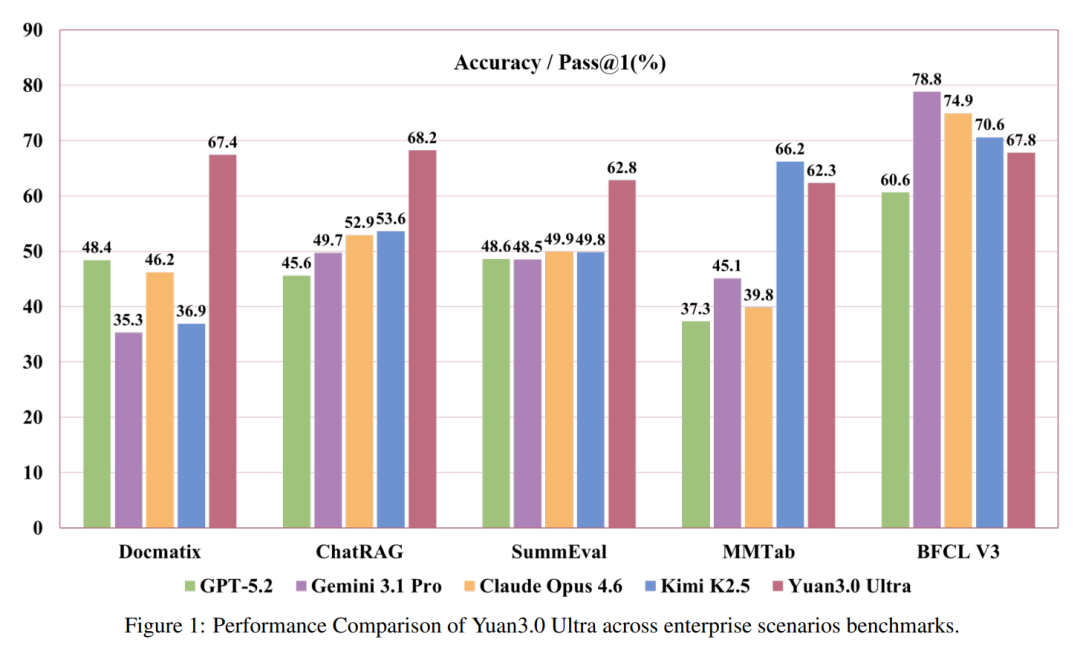
在检索增强生成(RAG) 领域,Yuan3.0 Ultra在ChatRAG、DocMatix等评测中取得领先成绩,可以精准定位并利用企业私域知识。ChatRAG涵盖长文本检索、短文本与结构化检索及维基百科检索,Yuan3.0 Ultra在这项测试中的平均准确率68.2%,10项任务中9项位居首位。
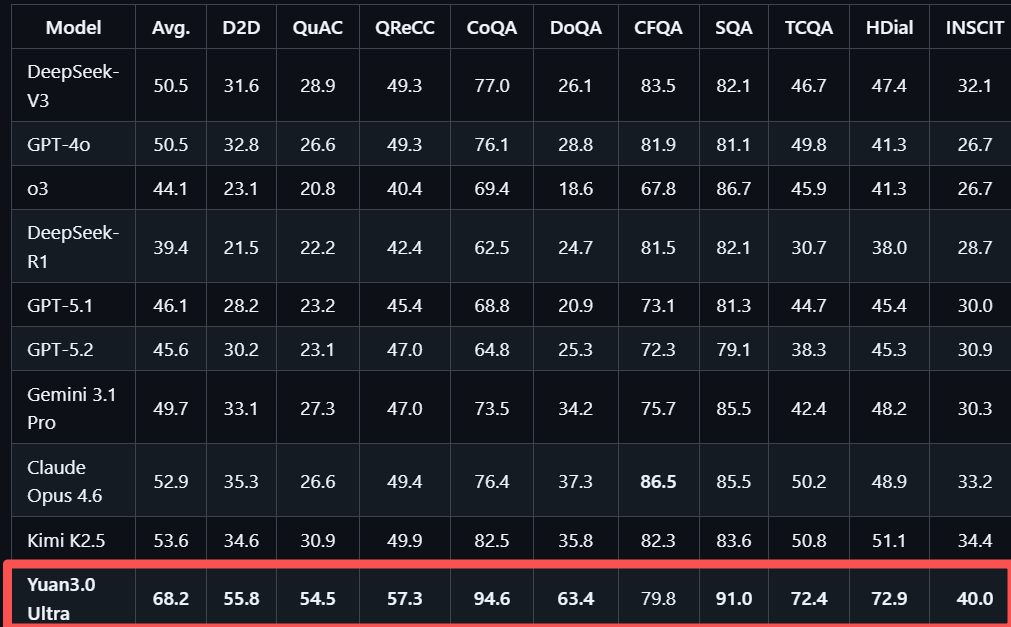
在企业实际业务中,大量关键信息存在于技术方案、财报报告、行业研究材料等文档中,这些内容通常包含图文混排结构、复杂表格以及跨页面信息关联,是企业构建知识体系过程的难点。
多模态复杂表格理解 评测MMTab覆盖表格问答、事实核查、长文本表格处理等多个任务类型,Yuan3.0 Ultra在这一测试中以62.3%的平均准确率超越Claude Opus 4.6和Gemini 3.1 Pro。
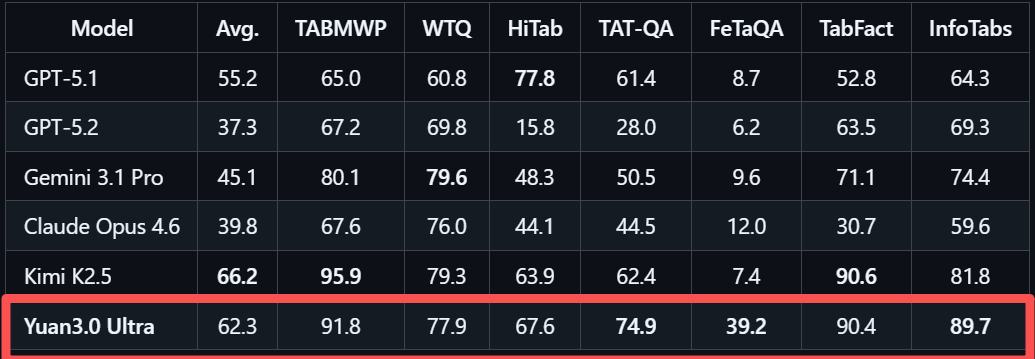
在高质量总结生成 方面,企业内部知识通常分散在文档库、知识库系统以及业务数据库中,信息来源复杂且结构不统一,要在这样的环境中获取有效信息,不仅需要检索能力,还需要对多源内容进行语义整合与综合分析。
在文本摘要生成评测SummEval中,Yuan3.0 Ultra平均精度62.8%,表现出色。这一测试从词汇重叠、语义相似度与事实一致性三个维度综合评估摘要质量,是智能体应用中历史信息压缩能力的重要参考。
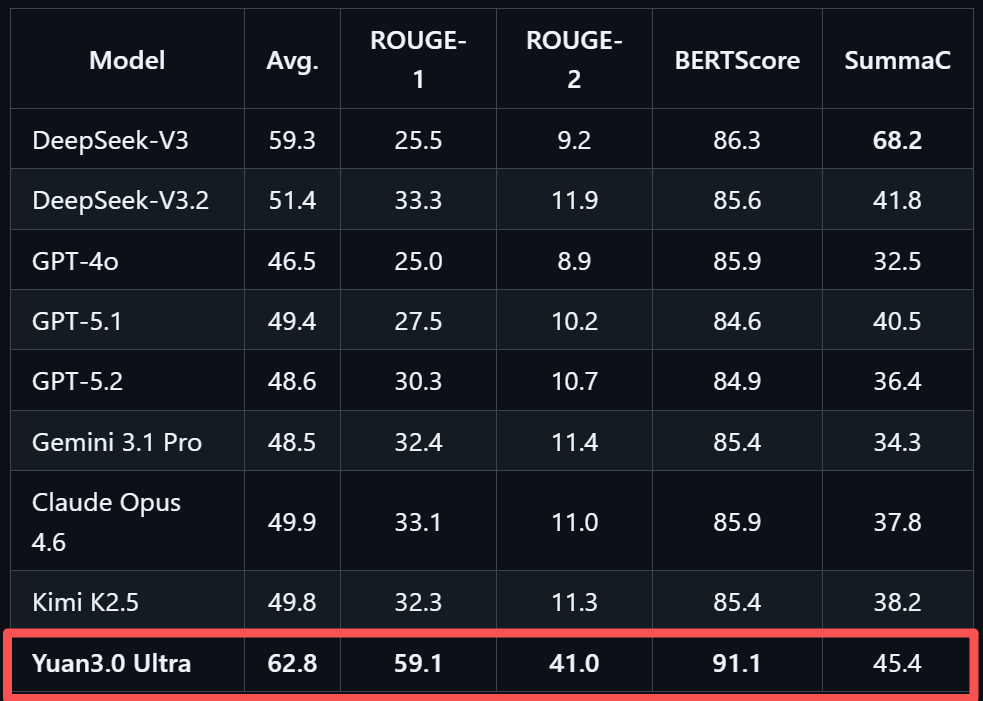
精通多步骤工具调用与协作,为自动化执行复杂任务打下坚实基础,是Agent应用关键能力,在智能体工具调用方面,Yuan3.0 Ultra表现均衡,在工具调用评测BFCL V3中平均得分67.8%。
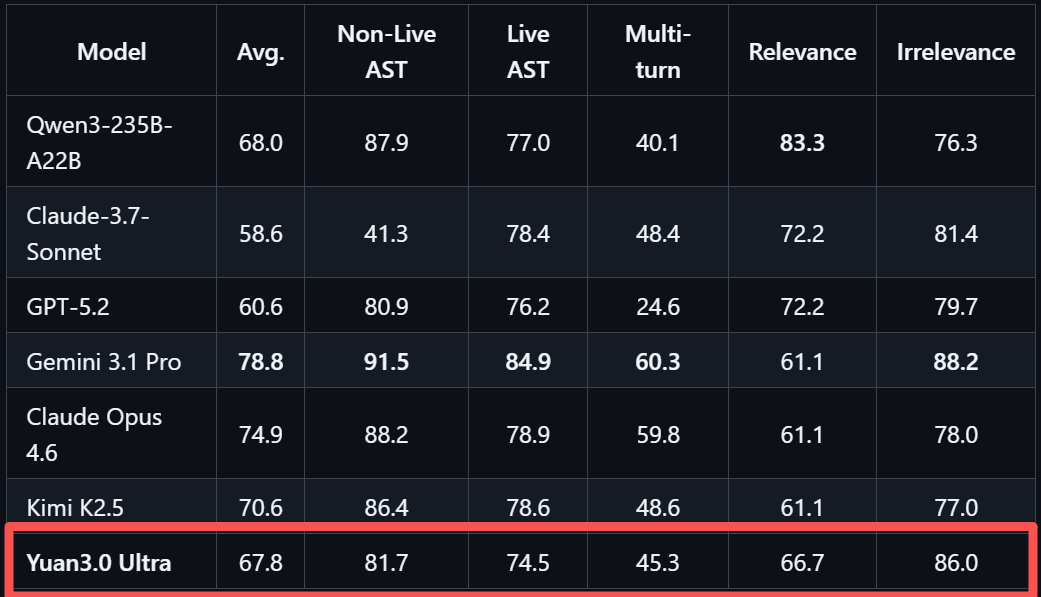
这一测试包含静态函数选择、动态实时执行、多轮上下文维护、相关性检测与无关调用拒绝等维度评估真实工具调用能力。
最后,在企业运营场景中,大量业务决策依赖数据库查询、报表分析以及跨系统数据整合,在这些场景下,企业往往需要将业务问题转化为数据库查询,并结合数据结果进行分析与总结。
在考察数据库查询语句生成能力 的Text-to-SQL评测中,Yuan3.0 Ultra在Spider 1.0及BIRD评测上表现出色。
从综合测试结果来看,Yuan3.0 Ultra是真正能打的企业大模型。
03. 结语:提升单位算力真实智能密度,打破企业两难困境
AI智能体的火爆让我们看到了AI给个人和企业带来的巨大价值潜力,但同样也让我们看到了让AI真正能“干好活”,落地在企业场景所必然要面对的挑战。
从Flash到Ultra,YuanLab.ai团队一直在向着这一方向发力,直指企业核心痛点,其技术创新目标很明确:提升单位算力所产生的真实智能密度, 让大模型的能力可以真正转化为企业可落地、可负担、可稳定使用的业务价值。
此次Yuan3.0 Ultra推动大模型从“能力展示”走向“规模化落地”, 打破了困扰行业已久的成本效率困境。这是YuanLab.ai团队对下一代基础大模型结构的又一次探索实践,给业界MoE大模型结构创新、预训练算力效率提升提供了新的路径。
面向未来,AI必将更加深入地与企业业务相结合,在更多真实场景中落地,而底层模型技术的迭代仍将是核心驱动力。对这类前沿的AI模型架构创新与技术实践感兴趣的朋友,可以关注云栈社区的人工智能与技术文档板块,获取更多深度解析与开源项目动态。
 发表于 2026-3-19 04:40:54
|
查看: 118|
回复: 0
发表于 2026-3-19 04:40:54
|
查看: 118|
回复: 0
