前几天,我看到一位中学物理老师用显示屏向学生讲解电视成像原理。这个简短的视频,却意外地串联起了我脑海里关于图像处理、人工智能乃至世界底层逻辑的一系列思考。
光的三原色与RGB色域
提到光的三原色,我总会想起以前学Photoshop时的一个小实验:新建三个图层,分别填充纯红、纯绿、纯蓝,然后把它们叠在一起。
如果把图层的混合模式改成“线性减淡(添加)”或“变亮”,神奇的事情就发生了:红和绿叠加变成了黄色,绿和蓝叠加变成了青色,蓝和红叠加变成了品红色,当三个图层完全叠加时,呈现出的就是白色。
这个实验引出了一个核心概念:红、绿、蓝三个颜色通道的数值,各自在0到255的区间内变化,可以产生超过1670万种不同的组合。
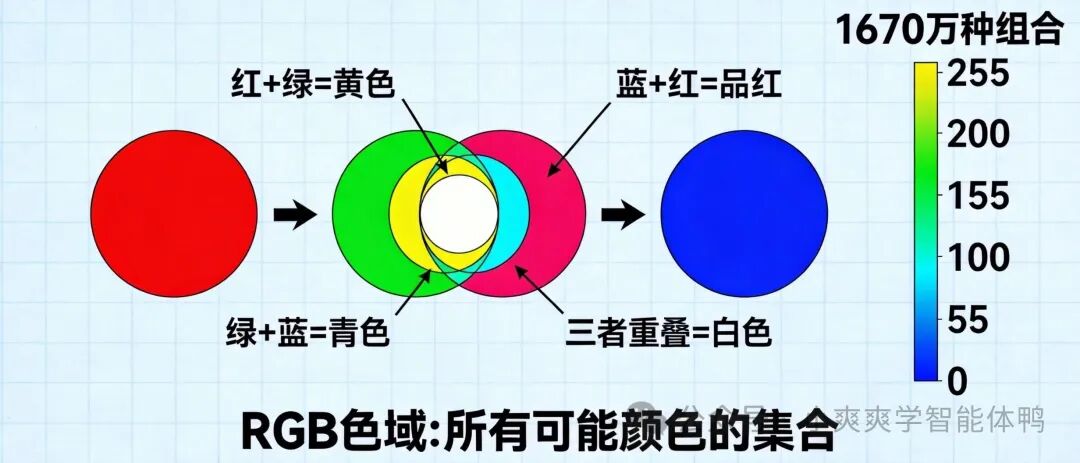
每一种组合都对应着一种唯一的颜色,所有这些可能颜色的集合,就构成了所谓的 RGB色域。我们在软件中调整图层的明暗,本质上就是在改变其RGB的数值,从而在这个庞大的色域“调色盘”中,精准地“选取”出我们想要的那一种颜色。
正片叠底与滤色的数学原理
实验过后,一个问题冒了出来:图层那些眼花缭乱的混合效果,是不是全靠调整明暗来实现的?
凭着一些PS基础,我去查了资料,回忆起两种最基础的混合模式:正片叠底 和 滤色。它们的背后,其实都站着清晰的数学公式,通过计算基色和混合色的RGB值来得到最终的结果色。而这些公式本身,又是对现实物理规律的数学总结。
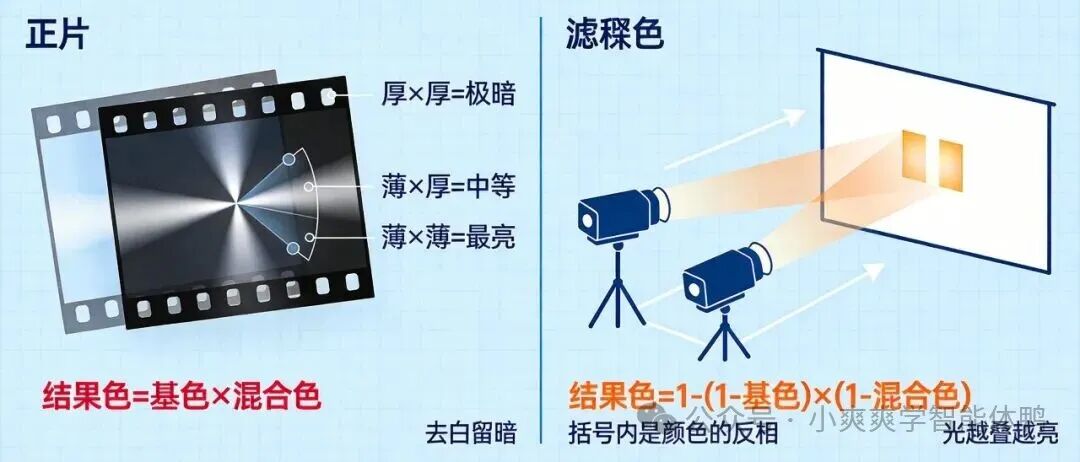
正片叠底:模拟光线穿透
你可以把“正片叠底”想象成两张胶片叠在一起。胶片上亮的地方薄,暗的地方厚。
当光线穿透这两层胶片时:
- 厚 × 厚:光线几乎无法透过,结果极暗。
- 薄 × 厚:能透过一部分光,呈现中等亮度。
- 薄 × 薄:光线几乎完全穿透,呈现最亮。
这整个过程就是 “去白留暗” 。用数学公式来表达就是(将颜色值归一化到0-1之间):
结果色 = 基色 × 混合色
这完美地对应了光线穿透介质时发生的衰减现象。
滤色:模拟光线叠加
“滤色”模式模拟的则是像投影仪那样,将光线投射叠加的效果。它的公式是:
结果色 = 1 - (1 - 基色) × (1 - 混合色)
公式中 (1 - 颜色) 其实就是该颜色的反相(例如红色的反相是青色)。整个计算过程可以理解为:先将两层颜色各自反相,然后用“正片叠底”的方式混合它们,最后将结果再次反相回来。
物理上,这对应了 “光越叠越亮” 的规律——与黑色混合保留原色,与白色混合直接变白,与彩色混合则会使画面变亮。
柔光:更灵活的中间态
除了这两种基础模式,还有像 柔光 这样更复杂的混合模式。它巧妙地将正片叠底和滤色的逻辑结合了起来。
它以50%中性灰(RGB值约为128)为分界线:
- 比中性灰暗的部分,按照类似正片叠底的逻辑处理,使画面更暗。
- 比中性灰亮的部分,则按照类似滤色的逻辑处理,使画面更亮。
这样一来,它就能同时影响图像的阴影和高光区域,比只能压暗的“正片叠底”和只能提亮的“滤色”要灵活得多,混合效果也更自然。
从物理到数学:软件功能的本质
想到这里,我忽然意识到一个关键点:修图软件里那些看似复杂花哨的功能,其灵感源头都来自于现实世界的物理规律。 工程师们将这些规律提炼、抽象,最终用严谨的数学公式描述出来,然后“教”给计算机去执行。
计算机本身并不“理解”物理世界,它只是忠实地按照预设的数学公式进行运算。在相同的输入条件下,公式的结果是确定的,因此计算机的行为也是确定的。而我们能在软件界面上调节的那些滑块和参数,本质上就是在调整这些公式里的变量——变量一变,输出结果自然随之改变。
AI与大脑:异曲同工的智能逻辑
这个发现让我联想到了 人工智能。既然计算机图形学是在用数学模拟物理规律,那么AI是否也在模拟某种现实规律呢?
答案是肯定的。AI的诸多灵感正来源于生物学,它试图用数学模型来模拟大脑神经网络的某些工作方式。
大脑如何工作?
大脑的工作流程大致是:接收外界信息,在内部进行整合处理,过程中会强化某些神经元之间的连接,同时弱化另一些,最后输出决策或反应信号。
哪些神经元被激活、激活的强度如何,这个过程充满了概率性。更重要的是,大脑突触的连接强度会发生物理层面的改变,例如长时增强效应(LTP)——如果两个神经元频繁地被同时激活,它们之间的连接就会得到加强,这相当于大脑的“硬件结构”在进行动态调整。
AI的注意力机制
而在以 Transformer 架构为代表的大模型中,核心组件之一是 注意力机制 。它通过计算,给输入信息的不同部分分配一个“重要性”权重,从而决定在本次处理中应该重点关注哪些内容、忽略哪些内容。在输出时,模型同样会计算一个概率分布,从中选择最可能的词或决策。
比如输入“今天去超市买了苹果,它吃起来……”,注意力机制可能会给“苹果”分配比“超市”高得多的权重,从而让模型更倾向于输出“很甜”而不是“很大”。

核心差异
当然,两者存在根本区别:
- 大脑的“概率性”源于生物机制与生俱来的随机性和结构可塑性。
- AI的“概率性”则是工程师用确定的数学运算(例如
Softmax 函数,它将一组数值转换为概率分布)刻意设计出来的。
AI的注意力权重并非物理结构的永久性改变,而是在每次推理时临时计算出的数值。一个是“硬件”层面的重塑,另一个是“软件”层面的瞬时计算。
尽管底层机制截然不同,但人类大脑和AI在输入输出的行为层面却展现出相似性:它们都根据输入,选择性地激活一部分“处理单元”,然后产生相应的输出结果。
AI内容连贯性的三大支柱
要让AI生成的内容保持连贯、符合逻辑,主要依赖三大技术支柱:
- 上下文窗口:相当于模型的短期记忆,使其能记住对话或文本中上文的信息。
- 注意力机制:如前所述,负责筛选和聚焦关键信息。
- 预训练过程:这相当于模型的长期经验积累,就像人类通过阅读和学习来增长知识。
预训练的数据越丰富、质量越高,模型学到的“知识”和“语言模式”就越多。这就像一个孩子学说话,从最初的单词“饿”,到后来能说出完整的句子“爸爸我饿了想吃饭”,输出的连贯性和复杂性随着“学习”的深入而不断提升。
AI的本质,就是运用数学工具(加权求和、激活函数、注意力机制等)来模拟生物神经元的功能特征,如信号整合、阈值激活和选择性关注。这使得机器能够模仿人类,根据输入做出选择并输出结果——尽管二者的实现原理天差地别,但在功能表现上却有了交汇点。
模型蒸馏:知识的传承与压缩
这让我又联想到一个有趣的技术——模型蒸馏。
模型蒸馏的核心思想是让一个参数较少、体积较小的“学生”模型,去学习一个庞大而强大的“教师”模型。训练时,给两个模型相同的输入,教师模型会输出一个详细的概率分布(例如:70%是猫,20%是狗,10%是狼),这被称为“软标签”,它比单纯的“硬标签”(只说“这是猫”)包含了更丰富的知识。
学生模型的目标就是努力模仿教师输出的这个概率分布。通过一个 损失函数 (用来计算学生输出与教师输出的差异,差异越大,“损失”越高)来获得反馈,并不断调整自身参数,使自己输出的分布越来越接近教师。
这个过程与人类的学习方式异曲同工:我们并非总是从零开始探索,而是常常通过学习前辈总结的经验和知识(相当于教师模型的输出)来快速成长。最终学生模型能“学”到多少,既取决于教师模型的能力上限,也受限于学生模型自身的参数容量。
数学:构建与理解智能世界的底层语言
最后的思考落在了更宏观的层面:我们如何理解并塑造世界?
我们通过观察物理、化学、生物乃至社会现象,先获得定性的认知,进而将其量化,最终用数学语言进行精确的描述和模拟。
无论是PS中一个简单的图层混合,还是AI中复杂的 神经网络,其本质都是先用数学这把“尺子”和“语言”,将现实世界的规律“翻译”成机器可读的指令,然后交由机器去高效执行。

数学,或许正是那个帮助我们解码物理世界、模拟生物智能,并最终构建出庞大数字世界的、最底层的元语言。
这次从显示屏成像到AI原理的联想之旅,让我对熟悉的PS功能多了份“原来如此”的透彻,对AI的运作少了份“神秘莫测”的敬畏,而对作为一切基础的 数学,则生出了更多的亲近与好奇。技术的世界层层相扣,其美感往往就藏在这些跨越领域的连接与洞察之中。
 发表于 2026-3-20 07:54:47
|
查看: 123|
回复: 0
发表于 2026-3-20 07:54:47
|
查看: 123|
回复: 0
