最近,Thoughtworks、GitHub 以及 Martin Fowler 等技术圈的意见领袖都在频繁讨论一个缩写:SDD,即规范驱动开发(Spec-Driven Development)。
简单来说,SDD 的核心就是 先写规范,再写代码。并且,这里的规范不是为了给人阅读,它的首要目标是让 AI 能够精确理解和执行。这个概念听起来有些抽象?别急,我们一步步拆解。
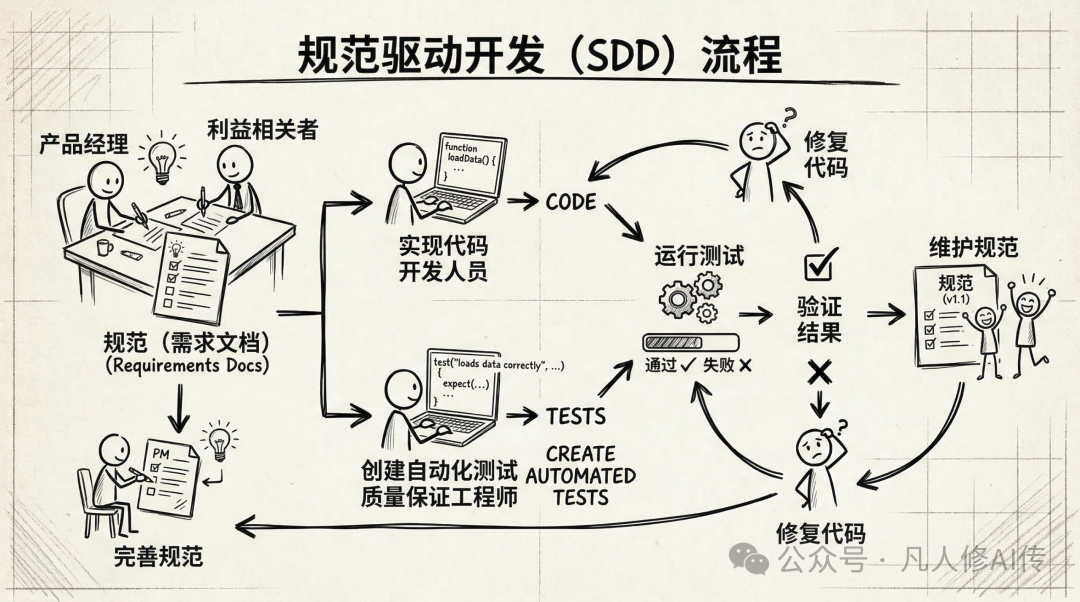
传统开发模式的困境:需求与代码的断层
我们不妨先回顾一下传统的软件开发流程:
- 产品经理产出 PRD(产品需求文档)。
- 开发工程师阅读 PRD 后开始编写代码。
- 测试工程师同样依据 PRD 来设计测试用例。
- 当需求发生变更时,需要同步更新 PRD、代码和测试用例。
这个流程的根本问题在于,PRD 和代码是彻底脱节的两套体系。PRD 的表述往往依赖自然语言,细节模糊,开发过程中大量依赖口头沟通来澄清。几个月后,代码可能已经迭代了十几个版本,而 PRD 文档还停留在最初的模样。新加入团队的成员面对陈旧的文档和复杂的代码,会感到无所适从。
更重要的是,PRD 是为人设计的,机器无法准确解析其意图。在 人工智能 辅助编程日益普及的今天,如果你直接将一份传统的 PRD 丢给 AI,它生成的代码常常南辕北辙,因为 AI 不得不去“猜测”那些模糊需求背后的具体实现。
SDD 的核心思想:规范即代码
SDD 提出了一种新的思路:放弃那种笼统的、描述性的 PRD,转而编写结构清晰、无歧义的规范(Specification)。
那么,规范和 PRD 究竟有什么区别?来看一个直观的例子:
传统的 PRD 可能会这样描述:
“用户需要能够登录系统,输入用户名和密码,登录成功后跳转到首页。”
而一份 SDD 规范会这样定义:
## 登录功能
### 输入
* `username`: string, 必填, 长度 3-20 字符
* `password`: string, 必填, 长度 8-32 字符
### 处理逻辑
GIVEN 用户提交了登录请求
WHEN 验证用户名存在且密码匹配
THEN 返回登录成功,生成 JWT token
AND 跳转到 `/dashboard`
### 错误处理
* 用户名不存在 → 返回 HTTP 401,提示信息:“用户名或密码错误”
* 密码不匹配 → 返回 HTTP 401,提示信息:“用户名或密码错误”
* 参数缺失 → 返回 HTTP 400,提示具体缺失的字段名
看出差别了吗?
- PRD 描述的是“要做什么”(What)。
- 规范 定义的是“具体怎么做”(How),包括精确的输入输出、边界条件、异常流程。
最关键的是,规范是结构化的、机器可读的。将这样一份规范交给 AI,它生成代码的准确率和贴合度会显著提升。
为什么 AI 时代 SDD 变得至关重要?
在过去,编写如此详尽的规范可能费时费力,性价比不高。但AI能力的爆发改变了游戏规则。
好处一:AI 能基于规范生成高质量代码。
给定一份细节完备的规范,AI 可以直接产出符合所有要求的初始代码。开发者从而节省了大量基础编码时间,可以将精力集中在代码审阅、架构设计和关键逻辑的微调上。
好处二:AI 能辅助进行代码维护。
当需求变更时,你只需要修改作为源头的规范,然后指示 AI 根据新规范重新生成或调整代码。只要规范是正确的,代码就不会偏离轨道。
好处三:大幅降低团队沟通成本。
规范成为了项目的“唯一事实来源”(Single Source of Truth)。产品、开发、测试乃至AI都基于同一份精确的文档工作,有效消除了理解偏差。
好处四:自动化测试变得顺理成章。
规范中使用的 Given/When/Then 等结构,可以近乎直接地转换为自动化软件测试用例。代码修改后运行测试套件,能迅速验证原有功能是否被破坏。
SDD 实践的三个成熟度层级
Martin Fowler 对此做了很好的总结,SDD 大致可以分为三个演进层级:
Level 1:规范优先(Spec-First)
先编写规范,然后利用规范来指导 AI 生成代码。此处的规范更像是“一次性”的指导文档,用完后不一定长期维护。
这是最简单的入门方式,非常适合小型功能或一次性任务。
Level 2:规范锚定(Spec-Anchored)
规范被作为核心资产进行长期维护。当需求变化时,首先更新规范,然后让 AI 基于新版规范来修改代码。
这是目前最主流且可行的实践方式。规范与产品代码一同进行版本管理,保持同步迭代。
Level 3:规范即源码(Spec-as-Source)
这是最激进的理想状态:规范是项目中人类维护的唯一“源码”。所有可执行代码均由 AI 从规范生成,并且明确标记为“由规范生成,请勿直接编辑”。
该模式仍在探索阶段,目前仅有 Tessl 等少数工具提供支持。
实战演练:用 SDD 构建一个 Todo 应用
理论说得再多,不如动手一试。我们以一个经典的 Todo 待办事项应用为例,看看 SDD 如何落地。
第一步:编写规范
首先,我们创建一个名为 todo-app.spec.md 的规范文件。
# Todo 应用规范
## 概述
一个简单的待办事项管理应用,支持增删改查和状态切换。
## 数据模型
### Todo 实体
```typescript
interface Todo {
id: string; // UUID,唯一标识
title: string; // 待办标题,必填,1-100 字符
completed: boolean; // 完成状态,默认 false
createdAt: Date; // 创建时间
updatedAt: Date; // 更新时间
}
```
## API 规范
### 1. 创建待办
**POST /api/todos**
**Request Body:**
```json
{
"title": "string, 必填, 1-100 字符"
}
```
**Response 201:**
```json
{
"id": "uuid",
"title": "string",
"completed": false,
"createdAt": "ISO8601",
"updatedAt": "ISO8601"
}
```
**Error Response 400:**
```json
{
"error": "标题不能为空" | "标题长度不能超过100字符"
}
```
### 2. 获取待办列表
**GET /api/todos**
**Query Parameters:**
- `filter`: "all" | "active" | "completed"(默认 "all")
- `sort`: "newest" | "oldest"(默认 "newest")
**Response 200:**
```json
{
"todos": [
{
"id": "uuid",
"title": "string",
"completed": boolean,
"createdAt": "ISO8601",
"updatedAt": "ISO8601"
}
],
"total": number,
"activeCount": number,
"completedCount": number
}
```
### 3. 更新待办状态
**PATCH /api/todos/:id**
**Request Body:**
```json
{
"title": "string, 可选, 1-100 字符",
"completed": "boolean, 可选"
}
```
**Response 200:** 更新后的 Todo 对象
**Error Response 404:**
```json
{
"error": "待办事项不存在"
}
```
### 4. 删除待办
**DELETE /api/todos/:id**
**Response 204:** No Content
**Error Response 404:**
```json
{
"error": "待办事项不存在"
}
```
## 前端页面规范
### 页面结构
1. **Header**: 应用标题 + 待办统计(总数/已完成/未完成)
2. **Input 区域**: 输入框 + “添加” 按钮
3. **Filter 区域**: 全部/进行中/已完成 切换标签
4. **Todo 列表**: 每条待办包含:
- 复选框(切换完成状态)
- 标题文字(完成的有删除线)
- 编辑按钮
- 删除按钮
5. **Footer**: 清空已完成按钮
### 交互行为
* 输入框回车或点击“添加”创建待办
* 点击复选框切换完成状态
* 双击待办文字进入编辑模式
* 编辑模式下回车保存,ESC 取消
* 点击删除按钮确认后删除
* 切换 filter 标签实时更新列表
## 技术栈
* 后端: [Node.js](https://yunpan.plus/f/58-1) + Express + SQLite
* 前端: React + TypeScript + Tailwind CSS
* 测试: Jest + React Testing Library
第二步:让 AI 生成代码
接下来,将这份完整的规范提交给 Claude、Cursor 或 GitHub Copilot 等 AI 编码助手,并给出指令:
“请根据上面的规范,为我生成完整的 Todo 应用代码,包括后端 API 和前端页面。”
AI 将基于规范生成:
- 数据库模型与迁移脚本
- Express 路由和控制器逻辑
- React 组件树与状态管理代码
- 基础的 Tailwind CSS 样式
第三步:人工审阅与迭代优化
AI 生成的代码可能并非完美,常见问题包括:
- 边界条件处理不够周全
- 某些错误场景的响应被遗漏
- 缺乏性能优化考虑
这时,你需要回到规范这一源头。补充或修正规范中的细节描述,然后让 AI 根据更新后的规范重新生成代码。
例如,你发现 AI 生成的代码没有对用户输入进行 XSS 防护,那么就在规范中增加安全要求章节:
## 安全要求
- 所有用户输入在存储和渲染前必须进行 XSS 过滤。
- API 响应头必须设置 `Content-Type: application/json; charset=utf-8`。
- 实现基础的接口限流:每个 IP 地址每分钟最多允许 100 次请求。
随后,再次指示 AI 基于包含安全要求的新规范来调整代码。
第四步:从规范生成测试用例
规范中清晰的 Given/When/Then 结构,可以非常方便地转换为自动化测试。AI 也能协助完成这部分工作。
// 基于规范生成的测试示例
describe('Todo API', () => {
describe('POST /api/todos', () => {
it('应该创建待办并返回 201', async () => {
// Given: 用户提交了有效的待办标题
const title = '学习 SDD';
// When: 调用创建 API
const response = await request(app)
.post('/api/todos')
.send({ title });
// Then: 返回 201 和创建的待办对象
expect(response.status).toBe(201);
expect(response.body.title).toBe(title);
expect(response.body.completed).toBe(false);
});
it('标题为空时返回 400 错误', async () => {
// Given: 标题为空
// When: 调用创建 API
// Then: 返回 400 错误
});
});
});
第五步:应对需求变更
一段时间后,产品经理提出新需求:“需要增加优先级功能,高优先级的待办事项要排在列表前面。”
传统做法:开发者需要手动在数据库模型、API、前端逻辑等多个地方修改代码,容易遗漏,引发 Bug。
SDD 做法:
- 修改规范:在
Todo 实体中增加 priority: 'high' | 'medium' | 'low' 字段,并同步更新相关的 API 接口规范和前端页面交互逻辑。
- 让 AI 重新生成:将更新后的规范交给 AI,让它基于新规范生成或修改所有受影响的代码文件。
- 运行测试验证:执行现有的测试套件,确保新增功能没有破坏原有逻辑。
在 SDD 模式下,规范是唯一的真相源。你只需在一处(规范)进行修改,AI 便会帮你将变更同步到所有相关的代码中。
SDD 并非万能银弹
尽管 SDD 前景广阔,但它也有其适用边界和需要注意的问题。
不适用或需谨慎使用的场景:
- 探索性开发:当需求极其模糊,需要快速原型验证和试错时,先写详细规范可能反而拖慢节奏。
- 遗留系统改造:对于没有规范文档的历史代码库,从头构建规范的代价可能很高。
- 极度复杂的业务逻辑:有时,用代码本身来表达复杂逻辑比用规范描述更直接,强行编写规范可能事倍功半。
实践中需要注意的问题:
- 规范编写的成本:编写高质量、无歧义的规范本身需要时间和技巧,对于极其简单的功能可能得不偿失。
- 规范质量决定上限:如果规范本身模糊、矛盾或不完整,那么 AI 生成的代码质量也无法保证。
- 潜在的创新瓶颈:过度依赖 AI 生成模式化代码,可能会抑制开发者在架构和实现上的创新思考。
最佳实践建议:
- 对核心业务逻辑、稳定模块采用 SDD,以确保其长期质量和可维护性。
- 对实验性功能,可先用传统模式快速迭代,待其稳定和明确后,再补充规范,将其纳入 SDD 流程。
- 将规范视为活的文档,建立与代码同步更新的机制,杜绝“写一次就扔”的情况。
总结与展望
SDD 是 AI 辅助编程时代水到渠成的一种范式演进。其本质是,开发者将一部分“编写指令(代码)”的工作,转变为了“编写更精确的元指令(规范)”的工作,而将指令的具体执行交给了 AI。
从模糊的 PRD 到精确的 Spec,从“描述做什么”到“定义怎么做”,从“人编写每一行代码”到“AI 根据规范生成代码”,这代表了软件开发模式的深刻变化。
目前,SDD 仍处于早期发展阶段,相关工具和社区最佳实践都在快速演进中。但“规范即代码”的理念及其在提升开发效率、保证软件质量方面的潜力已经十分清晰。如果你还没有尝试过,不妨从一个像 Todo 应用这样的小项目开始,体验一下“先写规范,后出代码”的全新工作流。你可能会发现,有时候,写好规范比直接写代码更让人省心。关于更多开发模式与架构的讨论,欢迎在云栈社区与更多开发者交流。
 发表于 2026-3-20 11:57:39
|
查看: 200|
回复: 0
发表于 2026-3-20 11:57:39
|
查看: 200|
回复: 0
