智谱在今年下半年密集发布了多款高质量模型。继7月的GLM-4.1V-Thinking、随后的GLM-4.5V以及10月的GLM-4.6之后,其在年末再次开源了目前最强的视觉模型:GLM-4.6V。
此次开源提供了两个尺寸版本:参数规模为106B的GLM-4.6V,以及仅为9B的GLM-4.6V-Flash。后者特别引人注目,因其对硬件要求较低,消费级显卡即可实现本地部署。根据官方评测,这两个版本在各自参数量级下,于多模态交互、逻辑推理及长上下文理解等任务上均达到了SOTA(当前最佳)水平。

GLM-4.6V支持高达128K的上下文窗口,可一次性处理约150页PDF文档、200页PPT或近一小时的关键帧视频序列。它不仅支持多模态输入(图文),还能进行多模态输出(图文并茂)。此外,模型还具备工具调用能力,在z.ai平台集成了多种实用工具。
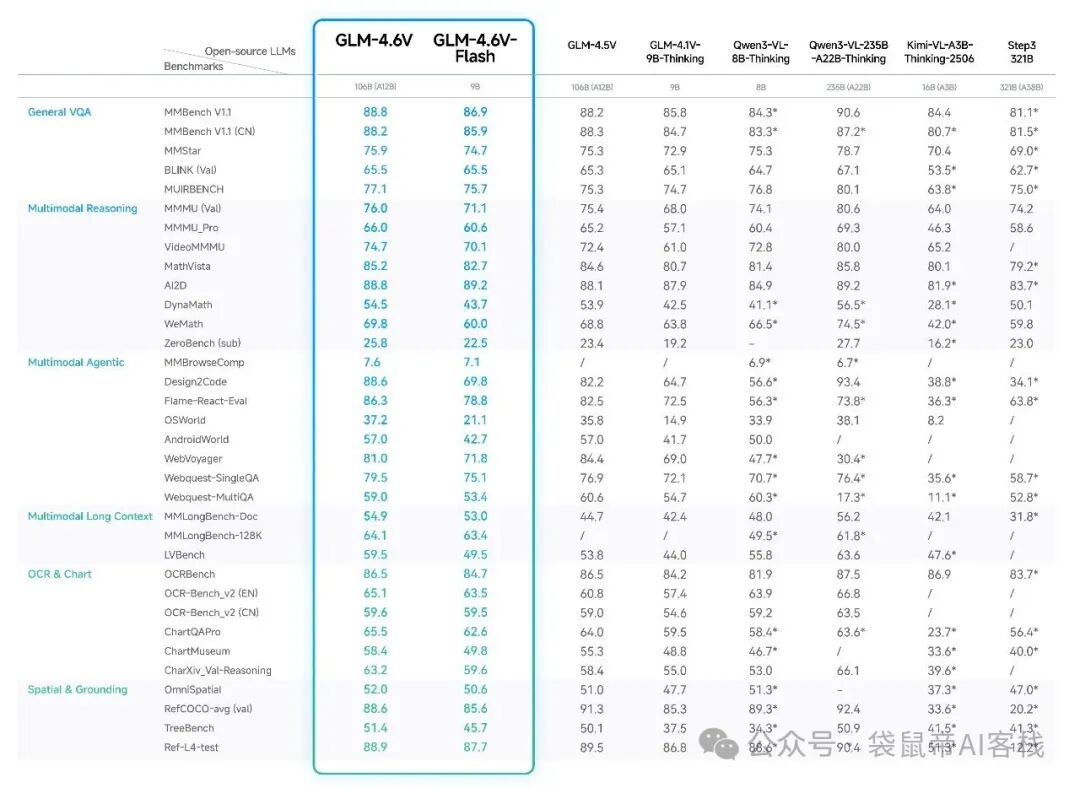
对于希望在本地运行视觉模型的开发者而言,9B的GLM-4.6V-Flash版本堪称当前的最佳选择。它无需昂贵的专业GPU,普通的游戏笔记本或公司配备的消费级显卡即可流畅运行,其综合表现已超越同级别的Qwen3-VL-8B模型。这对于注重数据隐私或需要在边缘设备部署AI应用的企业来说,是一个极具吸引力的解决方案。
一个典型的应用场景是工业质检。例如,在某生产线的末端安装摄像头,对传送带上的产品包装箱进行拍照,随后由部署在本地工控机上的视觉模型实时判断箱体是否有破损、封箱胶带是否完好。过去,这类应用可能受限于小模型的识别准确率,误判率较高。如今,采用GLM-4.6V-Flash这类高性能小模型,有望在同等硬件成本下大幅提升检测精度与效率。

而106B的GLM-4.6V版本,则定位为性能与私有化部署成本的平衡点。它不像数百B、上千B的巨型模型那样令绝大多数企业望而却步,对于有较强性能需求且必须将数据掌握在自己手中的团队,106B是一个经过努力可以实现的部署目标。
当然,如果对数据上云没有顾虑,直接调用智谱的API可以获得更优的速度和体验。目前,GLM-4.6V已可在z.ai上直接使用,也能以MCP(Model Context Protocol)的形式接入智能体(Agent)工作流,或作为基础视觉模型接入Claude Code。
核心能力实测
我们通过z.ai平台对GLM-4.6V进行了一系列能力测试。
1. 复杂图像识别:大合照找人
识别大合影中特定人物的位置一直是视觉模型的难点。我们将一张大型活动合影与一张个人自拍照同时提交给GLM-4.6V,模型成功地从第一排左起第三位准确找到了目标人物。这项能力在智能相册管理、安防监控等领域有很高的实用价值。
2. 图像搜索(Image Research)
模型内置的图像搜索功能对于内容创作者非常实用。例如,当要求其搜索“GEO(生成式引擎优化)”相关图片时,返回的结果精准且质量较高,能有效提升找图效率。
3. 文档与票据信息提取
模型在文档理解方面表现出色。无论是解读复杂的学术PDF(能正确处理文中的图片位置),还是识别车辆维修单等票据信息,都展现了极高的准确率,经逐字核对可达99.9%以上。
4. 视频内容理解
模型能够分析视频片段,理解剧情发展并识别角色情绪的细微变化,例如能捕捉到角色“湿润的眼眶”这样的细节。
本地集成与Agent实战
GLM-4.6V可以方便地集成到本地开发环境中。例如,通过修改Claude Code的settings.json配置文件,即可将其作为视觉模块接入:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "你的智谱开放平台apikey",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"API_TIMEOUT_MS": "3000000"
},
"model": "glm-4.6v"
}
配置完成后重启,你就拥有了一个具备“视觉”能力的本地智能体。我们为其布置了一个复杂的跨平台比价任务:使用Playwright MCP工具,在淘宝上找到500-1000元价位段销量第一的半入耳式蓝牙耳机,然后前往唯品会和京东搜索同款进行比价,并将最便宜的商品加入购物车。
在这个任务中,GLM-4.6V负责“看清”网页上的商品信息、型号和价格,Claude Code则负责整体任务规划和调度。两者协同成功完成了跨平台浏览、信息识别、逻辑比价和操作执行的全流程,尽管在初始的价格区间筛选步骤上略有疏漏,但整体完成度很高。
另一种高效的用法是,将GLM-4.6V作为专门的视觉MCP服务器,而让代码能力更强的GLM-4.6作为主模型来调度任务。通过以下命令添加MCP服务器:
claude mcp add -s user zai-mcp-server --env Z_AI_API_KEY=你的智谱apikey -- npx -y "@z_ai/mcp-server"
随后,在settings.json中将模型换回glm-4.6即可。这样,智能体就拥有了“眼睛”,可以执行诸如“分析视频中的网站页面与交互效果,并1:1复刻该网站”这类高度依赖视觉理解的任务。在实际测试中,模型成功识别了参考视频中的网页动效与交互,并生成了具有类似视觉效果的前端代码。
模型获取
GLM-4.6V相关资源已开源,您可以从以下地址获取:

总结
GLM-4.6V的开源为多模态AI的落地提供了更灵活的选择。9B的Flash版本降低了本地部署AI应用的门槛,让个人开发者和中小企业也能享受高性能视觉模型带来的便利。106B版本则在性能与部署成本间取得了良好平衡,适合对私有化有严格要求的企业场景。将此类模型与具体的Python业务逻辑相结合,能够切实解决产业中的实际问题,释放AI的生产力。
 发表于 2025-12-10 00:33:57
|
查看: 303|
回复: 0
发表于 2025-12-10 00:33:57
|
查看: 303|
回复: 0
