现在的 AI Agent 常常需要处理诸如长对话、多步推理或交互式网页导航这类复杂任务,这就要求它们不仅能记住过去的经验,更要能高效地复用这些经验。
然而,当前主流的记忆系统大多还停留在“日志文件”的模式:不断累积原始的交互轨迹,使用时再从这一大堆文本里捞出几个片段。时间一长,记忆库只会无限膨胀,噪声增多,最终迅速挤占Agent那宝贵的上下文窗口。
这就形成了一个悖论:AI Agent 虽然拥有了前所未有的“记忆量”,却依然难以有效地利用这些记忆。真正对决策至关重要的,往往不是完整的交互流水账,而是从这些记录中沉淀下来的核心知识。
举个例子,在为用户做商品推荐时,Agent 真正需要记住的是“用户偏好有机咖啡”这样的偏好,而不是反复阅读整段聊天记录;在一个新网站购物时,Agent 需要的也不是重放看过的每一个页面,而是掌握“如何搜索、筛选、最终下单”的通用策略。
因此,AI Agent 记忆问题的核心挑战,其实不在于“存更多”,而在于以能突出决策相关信息的方式来组织记忆。
由UIUC与清华大学等机构联合提出的 PlugMem,正是为了应对这一挑战。它提出了一种任务无关(task-agnostic)的通用记忆模块,其核心思想是将智能体的原始经验转化为结构化、可复用的知识。PlugMem 摒弃了将记忆视为扁平文本来检索的做法,转而借鉴认知科学,构建一个以知识为中心的记忆表示体系。

论文链接: https://arxiv.org/abs/2603.03296
代码链接: https://github.com/TIMAN-group/PlugMem
认知科学通常将记忆区分为三类:对具体事件的回忆、对抽象事实的知识、以及对技能或策略的掌握。事件提供了背景,但有效的决策更依赖于从事件中抽象出的事实与技能。这一视角启发我们重新思考 AI agent 的记忆设计应如何演进。
PlugMem 正是基于此,将对话、文档、网页轨迹等异构的交互记录,转化为了结构化的知识单元。这些单元更紧凑、更易复用,并且与决策目标直接对齐。
PlugMem 的核心架构:结构、检索、推理
PlugMem 的整个流程主要由三个核心组件协同完成:
- 结构化模块:负责将原始的情景经验标准化,并从中提取两类关键知识:命题式知识(facts,如“用户偏好有机咖啡”)与处方式知识(skills,如“如何搜索并筛选商品”)。这些知识单元会被组织成一个结构化的记忆图谱。
- 检索模块:它不再检索冗长的文本块,而是直接检索与当前任务在语义上最对齐的知识单元。高层概念与用户意图作为“路由信号”,帮助系统快速定位最相关的内容。
- 推理/压缩模块:对检索到的知识进行进一步推理和压缩,将其提炼为简洁、可直接用于指导当前任务的指令,再交给底层的AI Agent使用。这极大地提升了上下文窗口的利用效率。
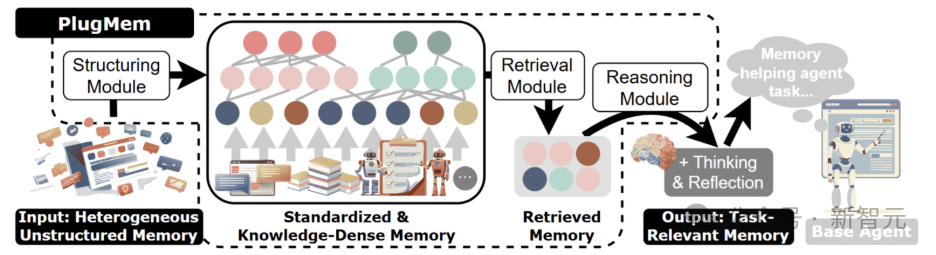
PlugMem 将异构的智能体经验组织为以知识为中心的记忆图谱,从而实现更高效的结构化检索与推理。
PlugMem 与传统 GraphRAG 系统的关键区别在于其“记忆访问单元”。传统方法通常索引文本片段或实体,而 PlugMem 则以知识单元(命题与处方)作为基本构件。这样的设计减少了冗余,提升了信息密度,并最终提高了检索的精度。
一个能跨任务迁移的通用记忆模块
许多现有的记忆系统往往是为特定基准任务(如对话、知识问答、网页导航)精心定制的。这类任务特定模块在单一场景下可能表现优异,但一旦更换任务,往往就需要重新设计。
PlugMem 选择了一条不同的路径:它被设计成一个即插即用(Plug-and-Play)的通用记忆骨架,可以直接接入不同的 AI Agent 中,而无需针对具体任务进行专门修改。研究团队使用同一个模块、保持实现不变,在三个异构的基准上进行了评测:长程对话式问答、基于维基百科的多跳知识检索,以及交互式网页决策任务。
实验结果表明,PlugMem 在三种截然不同的任务设置下都稳定提升了任务表现,其性能超过了通用的检索方法以及多种为任务专门设计的记忆方案。更关键的是,这些性能提升是在向 Agent 的上下文窗口中注入显著更少token的前提下实现的。
用“效用”而非“大小”衡量记忆
仅仅看任务准确率,并不能完全反映一个记忆系统的核心能力。一个好的记忆模块必须在“为决策提供的效用”和“占用的上下文成本”之间做出精妙的权衡。
为此,PlugMem 的研究工作引入了一个基于信息论的评估指标,用以度量记忆系统每消耗一个 token,能为决策带来多少相关的信息增益。直观地说,这个指标衡量的是:记忆模块产生的记忆 token 能让 AI Agent 对采取正确行动的信心增加多少?然后再将这一增益按记忆长度进行归一化。
在“效用-成本”的坐标空间中,PlugMem 稳定地处于更具优势的位置:在更低的 token 成本下,获得了更高的决策效用。
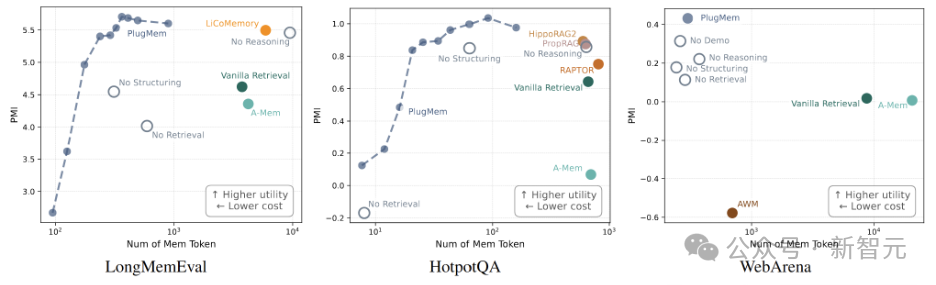
在多种基准测试上,PlugMem 都能在更小的记忆预算下提供更高的决策相关效用。
这些结果有力地支持了一个结论:将经验转化为知识,远比直接检索原始交互日志更紧凑、信息密度更高。
性能超越任务特定设计
乍看之下,一个任务无关的通用记忆模块,其性能能超过为某个基准量身定制的方法,似乎有些反直觉。但 PlugMem 的实验结果恰恰表明,决定性能的关键因素往往不是特定 Benchmark 的启发式技巧,而是对“决策相关知识”的有效抽取与检索。
没有检索,记忆只是静态的存储;没有结构化的知识,检索就缺乏精度。PlugMem 将以下三件事解耦并协同工作:结构化决定了“可被检索的内容是什么”,检索决定了“记忆是否真的能帮助决策”,而推理/压缩则确保“能以更低的成本被 Agent 利用”。
PlugMem 也并不试图取代所有任务特定的技巧。它更像是一个强大的通用记忆底座,上层依然可以叠加任务适配层。实验也显示,在 PlugMem 的基础上再加入任务特定的启发式方法,往往还能进一步提升效果,二者呈现出良好的互补性。
迈向智能体的“可复用知识基础设施”
当 AI Agent 向着更长程、更自主的能力迈进时,其记忆系统也需要从被动的存储,进化为主动的知识基础设施。智能体应当能够积累可跨任务、跨环境迁移的事实与策略,让知识得以复用,从而缓解冷启动问题,并支持更强的泛化能力。
PlugMem 是朝这个方向迈出的坚实一步。它以认知科学为设计灵感,将“知识”作为复用的基本单位,并证明了任务无关的记忆在效率与能力上同时可行的可能性。
更广义地看,这项工作提示了一个重要的视角转变:与其一味追求在更长的上下文中检索更多内容,不如致力于将经验表示为一种天然可复用的形式。随着智能体能力的不断扩展,一个可扩展、可迁移的记忆系统将成为关键的基础设施;而这种以知识为中心的记忆体系,很可能是构建下一代更强大、更高效智能体的重要基石。
在像云栈社区这样的技术论坛中,关于如何构建更高效、更通用的AI Agent架构的讨论一直很热烈,PlugMem 的研究无疑为此提供了一个极具启发性的新思路。
参考资料: https://arxiv.org/abs/2603.03296
 发表于 2026-3-22 03:24:15
|
查看: 193|
回复: 0
发表于 2026-3-22 03:24:15
|
查看: 193|
回复: 0
