Simon Willison,Django框架的联合创始人,最近系统性地总结了他使用AI编程工具一年多的实战经验,写成了一份《Agentic Engineering Patterns》指南。
这并非简单的入门教程,而是一套关于如何高效指挥Claude Code、Codex这类AI编程智能体进行开发的深度方法论。理解并运用这些模式,或许能让你手中的工具效能翻倍。
什么是 Agentic Engineering?
Simon给出的定义是:使用AI编程智能体来开发软件的实践。
这里的关键词是“智能体(Agent)”,而非“副驾驶(Copilot)”。两者的核心区别在于自主性:Copilot是你写一行它补一行,而Agent是你给定一个目标,它会自主规划、编写代码、执行验证,并循环此过程直到任务完成。
Simon的原话一针见血:
“Agent在循环中运行工具来达成目标。”
Claude Code、Codex、Gemini CLI都属于这类Agent。它们的核心能力不仅仅是“生成代码”,更在于执行代码。能执行,才能验证;能验证,才能迭代。
那么,在智能体时代,程序员的价值何在?Simon的观点很直接:写代码从来不是软件工程师的核心工作,想清楚该写什么代码才是。 任何一个软件问题都有数十种解法,我们的价值在于导航这些选项,为当前场景找到最合适的路径。
这不是Vibe Coding吗?
Simon专门澄清了这一点。Vibe Coding是Karpathy在2025年提出的概念,核心是“让AI写代码,你忘记代码的存在就好”。
Simon的态度是:Vibe Coding可以用于快速原型验证,但不能用于生产开发。 Agentic Engineering与Vibe Coding的本质区别在于,前者要求你审查结果、验证质量,并将代码提升到可生产级别。简而言之,一个是让AI自由发挥,一个是让AI在规则框架内高效工作。
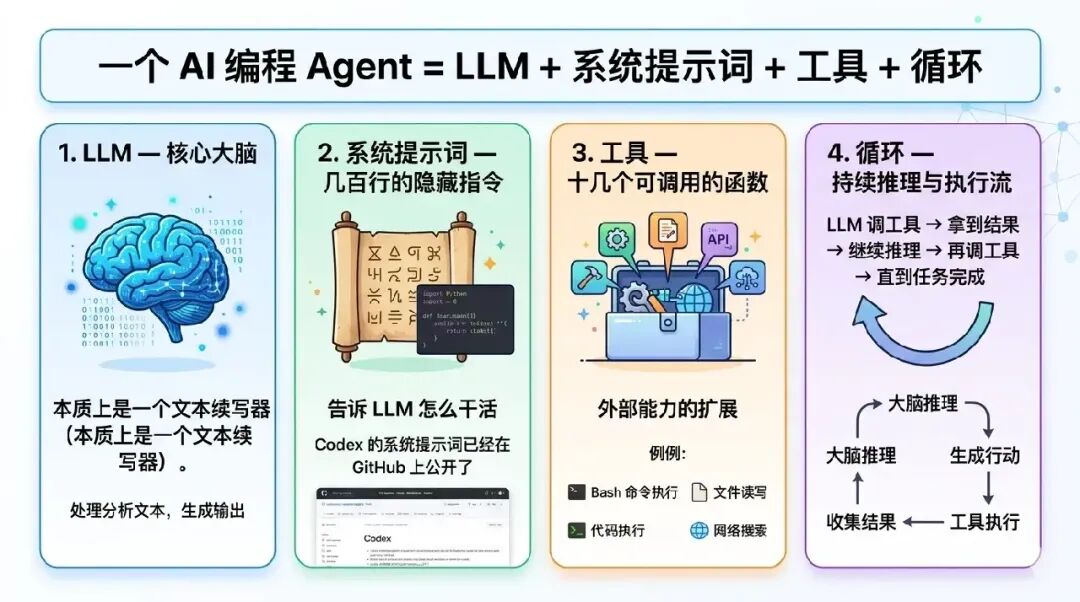
AI编程智能体的底层构成
很多人天天使用Claude Code,却不清楚其底层工作原理。Simon的拆解非常清晰:
一个AI编程智能体 = LLM(大语言模型) + 系统提示词 + 工具集 + 执行循环。
- LLM — 核心大脑,本质上是一个强大的文本续写器。
- 系统提示词 — 长达数百行的隐藏指令,告诉LLM如何扮演代码助手的角色(例如,Codex的系统提示词已在GitHub开源)。
- 工具 — 十几个可调用的外部函数,例如执行Bash命令、读写文件、运行代码、进行网络搜索等。
- 循环 — 智能体运作的核心流程:LLM思考后调用工具 → 获取工具执行结果 → 基于结果继续推理 → 再次调用工具 → 如此循环直至任务完成。
此外,还有两个容易被忽略但至关重要的技术细节:
- LLM是无状态的:每次调用都是一次全新的开始。你所感受到的“对话连续性”,实际上是软件将整个对话历史作为上下文重新输入给模型。因此,对话轮次越多,成本越高,且模型处理长上下文的能力会下降,这就凸显了上下文管理的重要性。
- Token缓存能节省成本:大多数服务提供商对重复出现的“前缀Token”收费更低。Claude Code的设计会刻意避免修改历史对话内容——这并非偷懒,而是为了保持缓存命中率,从而为用户省钱。
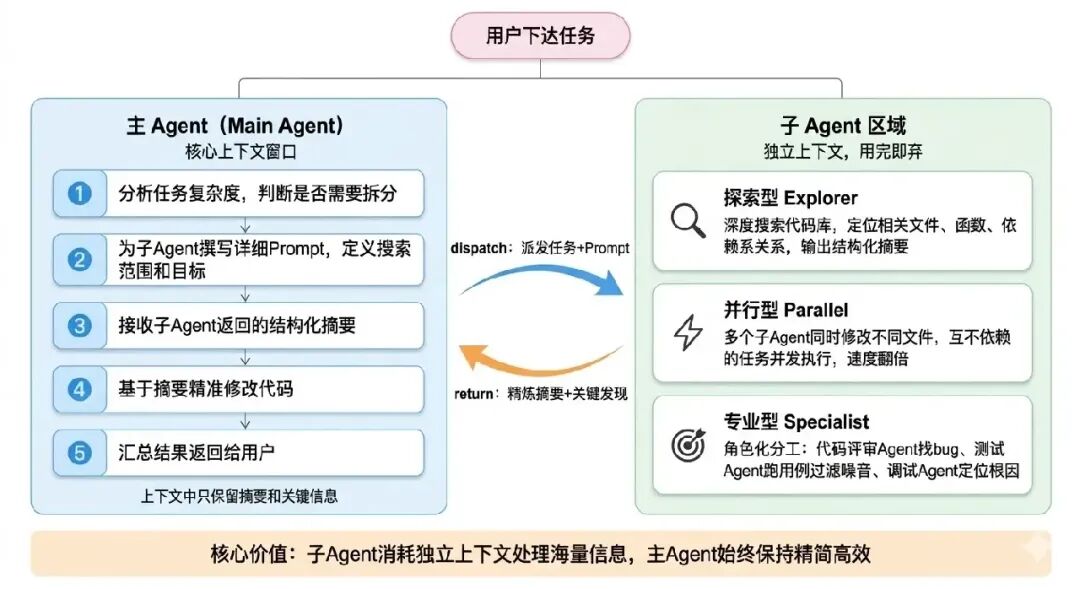
子Agent:Claude Code最被低估的能力
什么是子Agent?
子Agent是主Agent派出去执行特定子任务的“分身”。每个子Agent拥有独立的上下文窗口,完成任务后将精炼的结果返回给主Agent。
为何需要子Agent?因为上下文是最昂贵且有限的资源。尽管LLM的上下文窗口可能高达100万Token,但实践中超过20万Token后输出质量就会显著下降。子Agent机制允许消耗独立的上下文来处理信息密集的子任务,从而保持主Agent上下文的精简与高效。
实战案例:Claude Code如何使用子Agent
Simon分享了一个真实场景:他让Claude Code修改其博客的diff展示功能,增加字符级高亮。
Claude Code的第一步并非直接动手编码,而是派发了一个探索型(Explore)子Agent去摸底。它自动生成了如下Prompt给子Agent:
找到这个Django博客中实现diff视图的代码。我需要找到:
- 渲染diff的模板(找带红/绿背景的HTML/CSS)
- 生成diff的Python代码(找difflib的用法)
- 跟diff渲染相关的JavaScript
- diff视图的CSS样式
彻底搜索templates/、static/、blog/目录。
关键词搜 “diff”、“chapter”、“revision”、“history”、“compare”。
子Agent运行几秒后,将相关文件路径、代码位置、关键函数全部整理成结构化摘要返回。主Agent在获得这份“地图”后,才精准地开始修改代码。
Simon对此评价道:模型为自己编写的Prompt质量相当不错。 它深知如何高效地指导另一个智能体。
三种子Agent的实战用法
- 探索型子Agent:如上例所示。当主Agent需要理解一个陌生代码库或查找分散的信息时,派一个子Agent去探索并返回摘要,避免主上下文被无关细节污染。
- 并行子Agent:当需要修改多个互不依赖的文件时,可以指令Agent派发多个子Agent并行工作,从而大幅提升任务速度。可以尝试这样的Prompt:
用子Agent并行找到并更新所有受这个改动影响的模板文件。
- 专业子Agent:为子Agent分配特定“角色”,发挥其专项优势:
- 代码评审Agent — 专门审查代码,寻找潜在Bug和设计缺陷。
- 测试运行Agent — 专门执行测试套件,并将冗长的测试输出过滤、摘要后返回(极为实用)。
- 调试Agent — 专注于定位Bug的根本原因。
Simon也提醒了一点:切勿过度设计。 子Agent的核心价值是优化上下文使用,而非构建复杂的微服务式智能体编排系统。保持简单直接。
Red/Green TDD:AI编程的质量守护神
Simon提到,他在Claude Code中使用频率最高的一句指令是:
Use red/green TDD
仅仅六个单词,所有主流模型都能理解其完整含义:
- Red(红) — 先编写测试用例,并确认测试运行失败(红色)。这验证了测试本身是有效的,而非一个永远通过的“空测试”。
- Green(绿) — 再编写最小化的实现代码,让测试通过(绿色)。
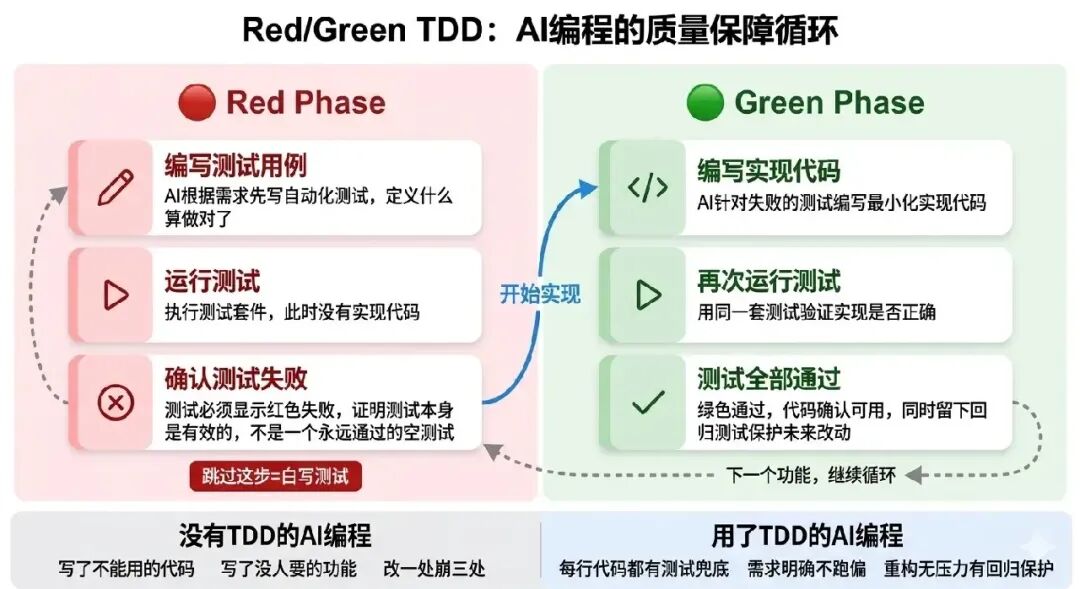
为什么测试驱动开发(TDD)与AI编程如此契合?因为它完美解决了AI辅助开发中的两个高频痛点:
- AI写出了无法运行或不符合预期的代码。
- AI实现了一堆偏离实际需求的功能。
TDD通过测试先行,明确定义了“何为正确”。AI可以依据这个清晰的标准进行迭代,从而产出更可靠的结果。切记,“红”阶段不可省略,否则你可能写了一个毫无约束力的测试,失去了TDD的核心价值。
实用Prompt策略清单
Simon在指南末尾分享了一些日常使用的Prompt策略,颇具启发性:
- 限制技术选型:在前端原型开发中,他会在Claude项目的自定义指令中明确禁止使用React,因为React需要构建步骤,而他的目标是生成可直接复制粘贴到静态托管的代码。
- 划定AI协作边界:在文章写作中,他允许AI协助校对拼写和语法,但所有包含第一人称“我”的观点性、叙述性文字必须亲自撰写。这条原则确保了内容的个人色彩与真实性。
- 善用模型特长:他发现Claude Opus在编写图片Alt文本上“品味独到”,能自动识别图表中最值得在描述中强调的关键数据。
总结
这份指南最大的价值,并非在于传授某个特定工具的操作技巧,而在于提供了一套与AI智能体协同工作的思维框架。
许多人使用Claude Code仍停留在“帮我写个函数”的初级阶段。通过学习子Agent的并行探索、TDD驱动的迭代闭环,你会意识到这些工具能承载的协作深度远超想象。关键在于,你能否像一位经验丰富的架构师那样,有效地指挥它们。
Simon有一句话说得极为深刻:LLM本身不会从过去的错误中学习,但基于LLM构建的智能体可以——前提是我们主动更新指令和工具,以反映我们不断积累的经验。
这不正是“授人以渔”吗?工具会快速迭代更新,而正确的方法论才是持久的生产力。如果你对这类Python与AI结合的深度实战内容感兴趣,欢迎在云栈社区继续交流探讨。
 发表于 2026-3-23 01:10:29
|
查看: 147|
回复: 0
发表于 2026-3-23 01:10:29
|
查看: 147|
回复: 0
