数值特征工程是机器学习模型训练中不可跳过的预处理环节。面对原始数据时,我们常常需要解决两个核心问题:特征的量纲差异和无处不在的异常值。
举个例子,年龄和薪资这两个特征,数值范围可能差了好几个数量级。如果不做任何处理,模型很可能仅仅因为薪资的数字更大,就错误地为其分配更高的权重,而完全忽略了年龄所蕴含的信息。
另一个常见问题是偏斜分布。许多特征的值会集中在一个很小的范围内,但同时存在少量极端值。比如一个表示“兄弟姐妹数量”的特征,绝大多数样本的值在0-2之间,但偶尔出现的8或10,会严重拉偏整个数据分布。有时我们可以直接丢弃这些极端样本,但在多数情况下,它们可能携带了真实且重要的信息,不能粗暴删除。
针对这些问题,数据预处理中常用到四种缩放方法:标准化(Standardization)、Robust缩放(Robust Scaler)、幂变换(Power Transformer)和归一化(Normalization)。接下来,我们用 Python 的 scikit-learn 内置的 California 住房数据集来逐一演示。我们将选取“Median Income”和“Population”这两个量级差异明显的特征进行分析。
from sklearn.datasets import fetch_california_housing
import pandas as pd
dataset = fetch_california_housing()
X_full, y_full = dataset.data, dataset.target
feature_names = dataset.feature_names
df = pd.DataFrame({
“MedInc”: X_full[:, 0],
“Population”: X_full[:, 4],
})
df.describe()
以下是该数据集部分特征的统计摘要:
+---------+------------+-------------+
| Metric | MedInc | Population |
+---------+------------+-------------+
| count | 20640 | 20640 |
| mean | 3.870671 | 1425.476744 |
| std | 1.899822 | 1132.462122 |
| min | 0.499900 | 3 |
| 25% | 2.5634 | 787 |
| 50% | 3.5348 | 1166 |
| 75% | 4.743250 | 1725 |
| max | 15.0001 | 35682 |
+---------+------------+-------------+
首先,我们来看看未经任何处理的原始数据是什么样的。下面的代码可以分别展示包含所有数据点和剔除异常值(取第0-99百分位)后的散点图。
import numpy as np
import matplotlib.pyplot as plt
X = X_full[:, [0,4]]
outlier_range = (0, 99)
cutoffs_median_inc = np.percentile(X[:, 0], outlier_range)
cutoffs_population = np.percentile(X[:, 1], outlier_range)
non_outliers = np.all(X > [cutoffs_median_inc[0], cutoffs_population[0]], axis=1) & np.all(
X < [cutoffs_median_inc[1], cutoffs_population[1]], axis=1
)
non_outlier_X = X[non_outliers]
non_outliers_Y = y_full[non_outliers]
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
fig.suptitle(‘Original Data’)
ax1.set_title(‘Full Data’)
ax1.scatter(X[:, 0], X[:, 1], c=y_full, cmap=‘viridis’)
ax1.set_xlabel(‘MedInc’)
ax1.set_ylabel(‘Population’)
ax2.set_title(‘Non-outlier Data’)
ax2.scatter(non_outlier_X[:, 0], non_outlier_X[:, 1], c=non_outliers_Y, cmap=‘viridis’)
ax2.set_xlabel(‘MedInc’)
ax2.set_ylabel(‘Population’)
plt.show()
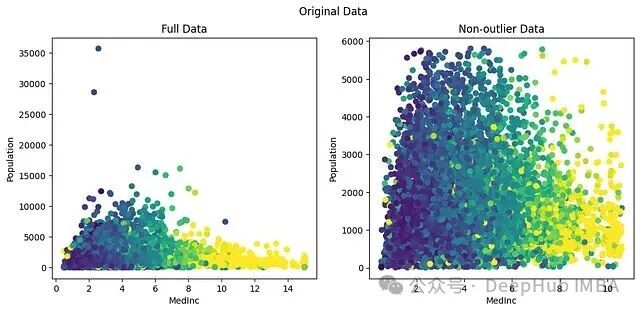
从图中可以直观看到,Population 特征中存在大量远离主体的高值点,这就是典型的异常值。
下面,我们分别来看看这四种技术如何变换数据,以及它们各自的适用场景。
标准化(Standardization)
标准化的目标是把数值特征变换到零均值、单位方差的尺度上。试想一下,年龄相差10岁,收入相差5万,这对于模型来说,收入的“信号”远比年龄“响亮”得多。标准化通过公式 $z = (x — \mu) / \sigma$(其中 $\mu$ 是均值,$\sigma$ 是标准差)将所有特征映射到均值为0、标准差为1的分布中,使得不同特征的数值落到同一个可比较的区间内。
标准化后的特征,与那些对输入分布有正态假设的算法契合度较高,例如线性回归、逻辑回归、支持向量机(SVM)以及主成分分析(PCA)等降维方法。
在 scikit-learn 中,对应的实现是 StandardScaler。
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler()
standardized_x = standard_scaler.fit_transform(X)
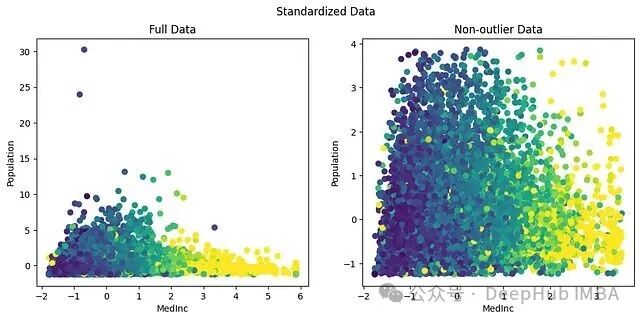
从结果看,原始数据中 Population 的范围在0到35k,MedInc 在0到14。标准化后,两个特征的主体数据落到了可比较的范围:MedInc 大约在 [-2, 4],Population 大约在 [-1, 4]。
然而,标准化有一个明显的弱点:它对异常值极其敏感。从上图可以看出,最大值虽然被缩放了,但异常值的存在拉高了整体均值,导致大部分数据被挤压到一个相对狭窄的区间内。标准化只改变数值的尺度,不改变分布的形状。数据原本是偏斜的,标准化之后依然偏斜。如果你正在处理涉及大量数据的项目,或者对模型效率有更高要求,可以关注我们社区 云栈社区 中关于计算力与数据处理的讨论。
Robust 缩放(Robust Scaler)
RobustScaler 可以看作是标准化的一个“鲁棒”变体。它的核心区别在于,它使用中位数代替均值,使用四分位距(IQR,即第75百分位数减去第25百分位数)代替标准差。标准化在面对极端异常值时会被“带偏”,而 IQR 只关注中间50%的数据,少数极端值对它几乎没有影响。注意,异常值本身并不会被移除,但它们对缩放中心与范围的影响被降到了最低。
from sklearn.preprocessing import RobustScaler
robust_scaler = RobustScaler(quantile_range=(25.0,75.0),
with_scaling=True, with_centering=True, unit_variance=True)
robust_x = robust_scaler.fit_transform(X)
默认的分位数范围 (25, 75) 意味着我们忽略了两端各25%的极端数据,这正是“鲁棒”一词的来源。
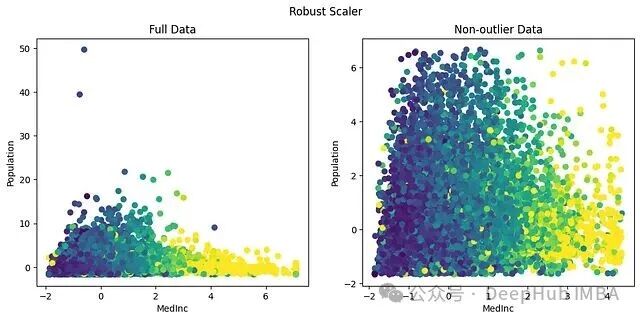
从图中可以看到,两个特征的主体数据落在了更合理且相近的区间:MedInc 在 [-2, 5],Population 在 [-2, 6]。
StandardScaler 和 RobustScaler 都能把特征拉到可比较的尺度上,但它们都无法根本性地消除异常值带来的分布偏斜。要解决形状问题,我们需要引入非线性变换。
现实世界中的数据,如收入、房价,常常呈现一种“重尾”分布:大量值集中在较低区间,同时存在少数极大的异常值。在线性模型中,一个极端异常值就像跷跷板一端的重物,足以把整条拟合线拽偏。即使在神经网络中,单个极端值带来的梯度冲击也可能引发训练的不稳定。
PowerTransformer 的做法是压缩分布的长尾,将异常值拉近数据主体,从而把偏斜分布整形为接近正态分布的形状。异常值的信息得以保留,但它们不再以极端的数值扭曲模型。在 scikit-learn 中,QuantileTransformer 也能达到类似效果。
我们先通过箱线图直观感受一下 Population 特征的“长尾”。
import seaborn as sns
plt.figure(figsize=(12, 4))
sns.boxplot(x=df[‘Population’], color=‘skyblue’)
plt.title(‘Box Plot of Population (Visualizing Outliers)’)
plt.xlabel(‘Population Value’)
plt.axvline(1425, color=‘orange’, linestyle=‘—‘, label=‘Mean: 1425’)
plt.legend()
plt.show()
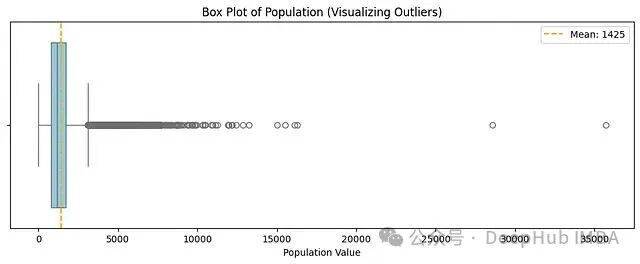
箱体对应的是数据主体(IQR范围),右侧那一长串散点就是可能“掀翻跷跷板”的极端 Population 值。现在,我们对 Population 应用 PowerTransformer。
from sklearn.preprocessing import PowerTransformer
pt = PowerTransformer(method=‘yeo-johnson’)
pt_transformed = pt.fit_transform(X[:,[1]])
绘制变换前后的直方图对比:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
sns.histplot(standardized_x[:,1], ax=ax1, kde=True)
ax1.set_title(“Before: Standardized Population (Skewed)”)
ax1.set_xlabel(“Value”)
sns.histplot(pt_transformed[:,0], ax=ax2, kde=True)
ax2.set_title(“After: PowerTransformed Population (Normal-like)”)
ax2.set_xlabel(“Transformed Value”)
plt.tight_layout()
plt.show()
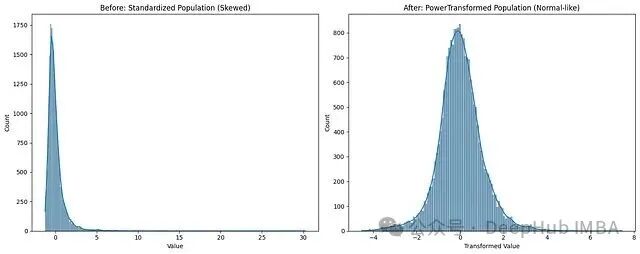
效果非常明显!PowerTransformer 把原本严重右偏的分布变换成了接近对称的钟形曲线。我们再看变换前后的箱线图对比:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
sns.boxplot(x=standardized_x[:,1], ax=ax1)
ax1.set_title(‘Standardized Population\n(Scale changed, outliers remain)’, fontsize=13)
ax1.set_xlabel(‘Z-Score’)
sns.boxplot(x=pt_transformed[:,0], ax=ax2)
ax2.set_title(‘PowerTransformed Population\n(Shape changed uniform tails)’, fontsize=13)
ax2.set_xlabel(‘Transformed Value’)
plt.tight_layout()
plt.show()
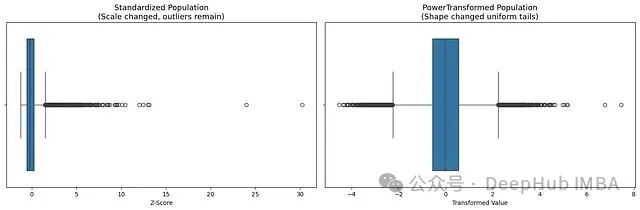
左图(标准化后)中,数据分布跨度依然很大,异常值明显。右图(幂变换后),箱体基本居中,两侧须线变得对称。这意味着,在线性回归等模型中,单个极端异常值带来的巨大平方误差被显著平滑,模型可以更专注于拟合数据的主体部分。
归一化(Normalization)
归一化通常指将所有数据重新缩放到 [0, 1] 的固定范围内。这对于 K 近邻(KNN)、支持向量机(使用RBF核)等基于距离的算法至关重要,因为特征的绝对大小会直接影响距离计算。在神经网络中,归一化还能帮助缓解梯度消失问题,将输入值控制在多数激活函数的敏感区间内。
最常用的方法是 Min-Max 缩放,公式为:$x\_{norm} = (x — x\_{min}) / (x\_{max} — x\_{min})$。然而,它有一个致命弱点:对异常值极度敏感。想象一下,如果数据中有一个10亿美元的收入(异常值),它会被映射为1,而其余所有正常收入可能都被压缩到接近0的狭窄区间内,数据内部的细微差异被彻底抹平。
让我们看看它对当前数据集的效果:
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler()
normalized_x = min_max_scaler.fit_transform(X)
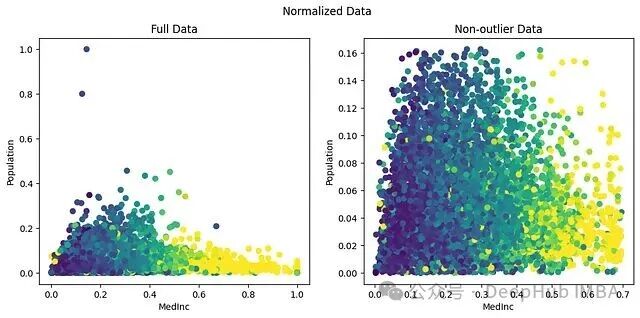
结果触目惊心:Min-Max 缩放把 Population 的最大值(35k)映射为1.0,而几乎全部数据都被挤压到了 0-0.16 的狭窄区间内。数据有意义的分辨率几乎丧失殆尽。
因此,归一化最适合的场景是输入特征的边界已知且固定,最典型的例子就是 RGB 图像的像素值,其取值范围恒定在 [0, 255]。
方法总结与选用指南
下表汇总了四种缩放器的核心适用场景:
.----------------------.---------------------------.-------------------------------------------------------.
| Issue | Best Tool | Why? |
:----------------------+---------------------------+-------------------------------------------------------:
| Different Scales | StandardScaler | Makes features comparable. |
:----------------------+---------------------------+-------------------------------------------------------:
| Heavy Skew | Power/QuantileTransformer | Normalizes the distribution shape. |
:----------------------+---------------------------+-------------------------------------------------------:
| Extreme Outliers | RobustScaler | Uses Median and IQR, unaffected by marginal outliers. |
:----------------------+---------------------------+-------------------------------------------------------:
| Neural Network Input | Min-Max Scaler | Matches the "expected" range of neurons. |
'----------------------'---------------------------'-------------------------------------------------------'
最后,使用这些缩放器时有一条必须遵守的铁律:fit() 方法只能在训练数据上调用一次。
.fit():计算所需的统计量(均值、标准差、最小值、最大值等)。.transform():使用已计算的统计量对数据进行变换。
无论是在测试集还是未来线上的新数据,都只能调用 .transform()。如果在测试集上再次调用 .fit(),就等于发生了数据泄露,模型性能评估将变得毫无意义。在部署模型时,训练好的缩放器(及其参数)也必须和模型一起打包上线。
希望这篇对比能帮助你在实际机器学习项目中,更准确地为数据选择“合身”的预处理方法。更多数据处理与模型优化的实践讨论,欢迎在技术社区 云栈社区 交流。
 发表于 2026-3-23 04:02:45
|
查看: 122|
回复: 0
发表于 2026-3-23 04:02:45
|
查看: 122|
回复: 0
