扩散语言模型一直是人工智能领域里一个备受关注的研究方向。与传统自回归模型逐个预测下一个词的方式不同,扩散模型在生成方式上更为灵活,也天生更适合并行建模。
然而,这条有潜力的路径上,将模型效果提升到实用水平并非易事。最近,一项来自华为诺亚方舟实验室的研究,将目光投向了训练过程中一个看似基础却一直被默认接受的设定:掩码(masking)究竟该怎么做? 其论文《Mask Is What DLLM Needs: A Masked Data Training Paradigm for Diffusion LLMs》挑战了现有的“平均用力”做法。

问题的核心:并非所有Token都同等重要
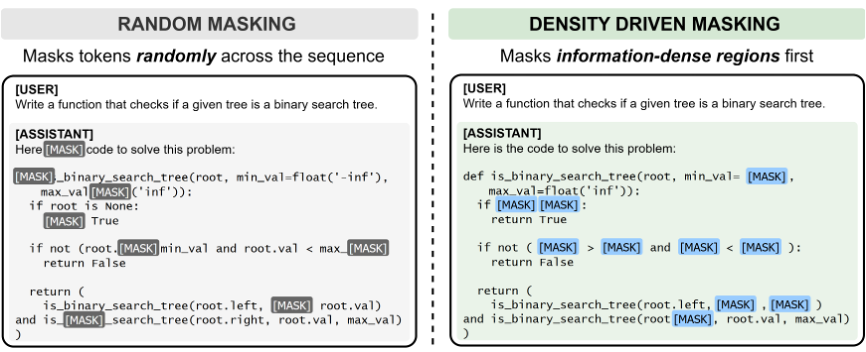
当前,许多离散扩散语言模型在训练时采用均匀随机掩码策略,即每个位置被遮盖的概率是相同的。这篇研究指出,这种做法存在“平均用力”的问题。在代码和数学推理这类结构化数据中,决定模型能否答对的关键信息往往只集中在少数几个位置(如代码中的条件判断、数学推导中的核心步骤),其重要性远高于连接词或格式字符。
信息在真实序列中的分布本来就是不均匀的,而随机掩码的“一刀切”策略,会迫使模型将部分优化资源浪费在非关键区域。简而言之,模型在学习时没能有效地区分主次。
研究的核心思想用一句话概括:既然不同Token的信息量不同,训练时就不应对它们一视同仁。
基于此,研究团队提出了一种更智能(Input Information Density Aware)的噪声调度策略。其做法直观且符合直觉:首先识别出样本中“信息密度高”的区域,然后在训练时优先遮盖这些区域,迫使模型学会恢复真正关键的部分。这类似于人类做填空题——补全一个逗号与补全一个核心结论的难度和意义截然不同。
方法论:先定位,再掩码
具体实现分为两个步骤:
第一步:识别高信息密度区域
研究团队首先设计了一套规则,从代码和数学数据中提取出关键信息区域。对于代码,这可能是函数名、条件表达式等;对于数学,则可能是关键的运算步骤。这些被识别出的区域会在原始序列中被高亮标记,作为后续噪声调度的参考。
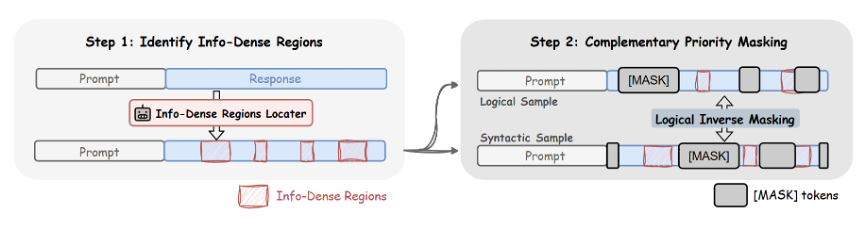
第二步:互补优先级掩码
在真正的掩码阶段,序列被分为两类区域:高信息密度的“优先区域”和其他“普通区域”。优先区域会被赋予更高的掩码概率,而普通区域的掩码概率则较低。同时,整体掩码比例依然受控,确保噪声调度的稳定性。
这个设计的精髓在于,它将训练难点导向了真正值得学习的地方。模型被反复要求重建的,不再是随机缺失的片段,而是决定代码逻辑或数学推理是否成立的关键部分。
精巧设计:互补掩码防止“偏科”
如果仅仅优先掩码关键区域,可能会引发另一个担忧:模型会不会变得只擅长“解题”而忽略了语言结构和上下文连贯性?
为此,研究引入了扩散模型训练中常用的互补掩码(Complementary Masking) 技术。对于同一条训练样本,除了生成一个基于优先级的掩码,还会生成其逻辑上的互补掩码。这样,一份数据就衍生出两种训练视角:
- 视角A(优先掩码):重点关注恢复逻辑骨架和关键推理步骤。
- 视角B(互补掩码):更多地保留关键信息,让模型专注于学习语法、结构和上下文流畅度。
这种结合实现了“1+1>2”的效果。它避免了模型学习目标的单一化,承认一个优秀的语言模型既要擅长推理,也要善于组织语言。论文将这种效果描述为基于信息密度的解耦学习,即把一条数据中的不同学习目标拆分开来。
实验结果:无需改动模型结构即可提升性能
实验以LLaDA-2.0-mini为基础模型,在代码和数学数据上进行训练,并在HumanEval、MBPP、GSM8K、MATH500四个基准上进行评估。

结果显示,相比于标准的随机掩码基线,该方法将平均性能提升了约4个百分点。这个提升幅度看似不大,但意义显著——因为它没有修改模型的主干结构,也未增加复杂的额外模块,唯一的变化是噪声调度策略。这证明,仅通过更合理地分配训练信号,扩散语言模型本身仍有大量潜力可挖。
深度洞察:力度与效率的平衡
研究中的几个消融实验提供了更深层的洞察。
1. Soft Masking 优于 Hard Masking
直觉上可能会认为,既然关键区域重要,就应该将它们全部遮盖(Hard Masking),迫使模型专注于学习。但实验结果恰恰相反。确定性的Hard Masking反而会损害性能,带概率的Soft Masking效果更好。
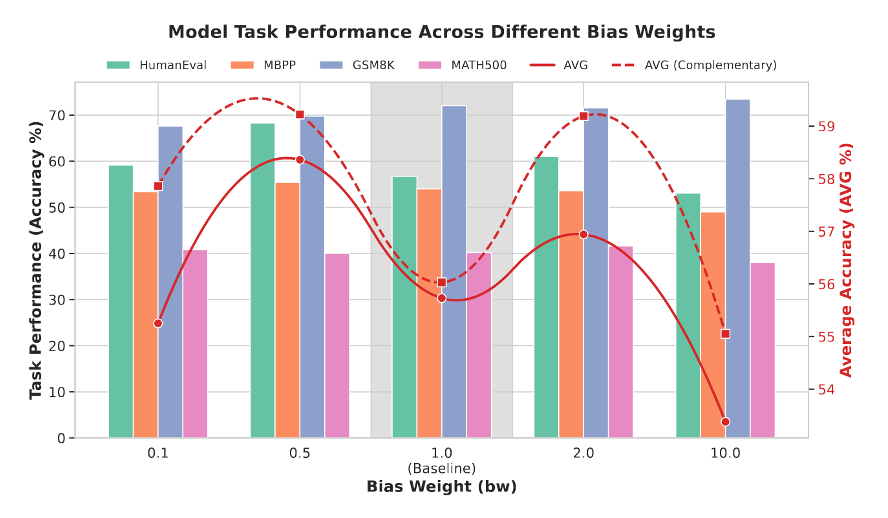
解释是合理的:代码和数学中的关键信息通常是连续出现的(如一段逻辑判断)。如果硬性地将整块区域全部遮盖,会在扩散训练中制造一个连续的“内容黑洞”,导致局部上下文崩溃(contextual collapse),使训练失稳、梯度难以控制。Soft Masking保留了随机性,避免每次都掏空关键部分,优化过程更为平滑。这再次印证了深度学习中“方向正确比力度激进更重要”的原则。
2. 高效的数据利用:少量处理,显著收益
另一个实用发现是该方法的数据效率。研究团队并未要求对所有训练数据进行离线的信息密度提取。
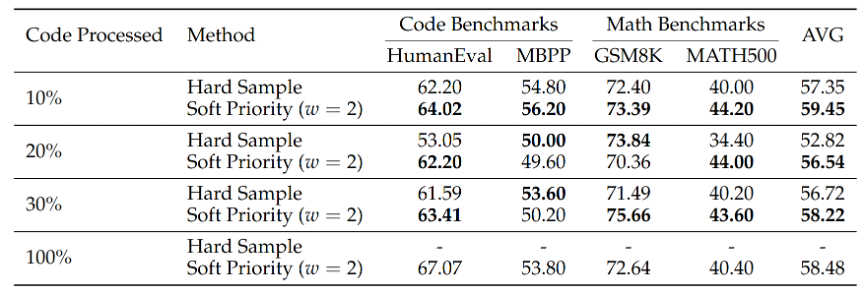
实验表明,仅对10%的代码数据进行处理,就能将平均成绩从55.32显著提升至59.45。继续增加处理比例,性能提升会趋于饱和;当比例达到100%时,数学推理的表现反而会下降。这可能是因为过多的代码结构先验挤占了模型在其他领域的泛化能力。这一发现非常重要,它表明该方案并非高成本、重工程的选择,而是可以通过在少量数据上引入结构化先验,来显著提升基础扩散模型的性能。
结语:重新审视训练逻辑本身
这项工作的价值不仅在于提出了一种新的掩码数据训练范式,更在于它触及了一个根本问题:扩散语言模型应该如何分配其学习注意力?
过去的研究往往聚焦于模型架构、采样策略或推理机制。这篇文章则提醒我们,模型学习什么、在何处用力,本身就决定了其最终的学习效果。对于高度依赖加噪/去噪过程的扩散语言模型而言,掩码策略并非配角,它在很大程度上定义了训练逻辑本身。
论文也指出,当前的信息密度提取流程仍是离线和启发式的。未来的方向包括:基于抽象语法树的规则提取、基于模型置信度的自适应提取,或引入对抗学习思想构建端到端可学习的掩码模块。你可以在开源实战板块找到更多关于前沿模型实现与调优的讨论。
如果这些方向得以推进,这项研究的意义将超越“一个有效的小改动”,而是为扩散语言模型指明了一种更具系统性的训练思路:先让模型学会分辨什么值得优先学习,而非急于让它学会所有东西。
这项研究也体现了智能与数据云领域通过优化训练流程来挖掘现有模型潜力的重要趋势。对更多前沿技术动态和深度解读感兴趣,欢迎持续关注云栈社区。
 发表于 2026-3-23 04:53:34
|
查看: 219|
回复: 0
发表于 2026-3-23 04:53:34
|
查看: 219|
回复: 0
