扫描版的PDF书籍,直接塞进电子阅读器常常是一场灾难:杂乱的页眉页脚、断裂的表格、消失的脚注,以及根本不存在的目录,让阅读体验大打折扣。
尤其是那些珍贵的旧书、学术文献或技术手册,往往只有扫描版。难道我们只能忍受这种糟糕的体验吗?其实不然,一个专注于解决此问题的开源工具已经出现。
今天要介绍的就是 PDF Craft。它是一款专为扫描版书籍设计的本地转换工具,基于强大的 DeepSeek OCR 引擎,能够精准提取正文、智能过滤页眉页脚等干扰元素,并输出结构清晰、排版完整的 Markdown 或 EPUB 文件,整个过程完全在本地运行,无需网络。
扫描PDF转换的痛点何在?
扫描版PDF的本质是一系列图片的堆砌。使用普通的OCR工具进行转换,往往会得到一堆混乱的文本:页眉、页脚、页码全部混入正文,脚注里的插图不翼而飞,跨页表格被生生截断。
转换成 EPUB 时,问题更加凸显:没有可点击的目录导航,复杂的数学公式变成乱码,原有的排版逻辑完全丢失。这对于需要精读的学术书籍、技术文档或古籍来说,几乎无法直接使用。
市面上的很多工具之所以解决不了这些问题,要么是因为依赖云端服务,对隐私和离线场景不友好;要么是OCR引擎过于简单,缺乏对文档逻辑结构的识别能力。而 PDF Craft 从设计之初就瞄准了“扫描书籍”这个细分但棘手的场景。
PDF Craft 的核心优势是什么?
它的强大之处在于其技术栈和设计理念:
- 强大的OCR内核:依托于 DeepSeek 的 OCR 模型,对表格、数学公式等复杂版面元素的识别准确率很高。
- 全本地化运行:从 PDF 解析、OCR 识别到格式生成,整个流水线均在本地完成,支持 GPU(CUDA)加速,速度快且保护隐私。
- 智能结构理解:能够自动分析文档结构,实现:
- 精确提取正文,有效过滤页眉、页脚、页码等噪音。
- 完整保留元素,妥善处理脚注、图片、表格,确保内容不丢失。
- 自动生成目录,在输出 EPUB 时构建可导航的书籍结构。
- 简洁的API:提供非常友好的 Python 接口,几行代码即可完成复杂转换。
从 v1.0.0 版本开始,PDF Craft 彻底移除了对 LLM 的依赖,实现了纯粹的本地方案,转换速度更快。如果你仍需要旧版(v0.2.8)的LLM辅助校对功能,可以回滚安装。项目还提供了在线的演示站点(https://pdf.oomol.com/),你可以直接上传PDF体验效果,无需安装任何软件。
如何安装与配置?
想要在本地使用,需要先满足一些基础环境要求:Python 3.10+,用于解析PDF的 Poppler 工具,以及可选的 NVIDIA GPU 和 CUDA 环境(用于加速OCR)。
CUDA 环境安装(推荐,转换速度更快)
- 检查你的 NVIDIA 驱动和 CUDA 版本,在终端运行
nvidia-smi 查看。
- 根据 CUDA 版本安装对应的 PyTorch(请以 PyTorch 官网最新指令为准):
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
- 安装 pdf-craft 包:
pip install pdf-craft
- 安装 必须的 Poppler:
- Ubuntu/Debian:
sudo apt-get install poppler-utils
- macOS:
brew install poppler
- Windows: 下载二进制压缩包,将其
bin 目录添加到系统的 PATH 环境变量中。
CPU 版本安装(仅用于开发或测试)
如果你的机器没有 NVIDIA GPU,可以安装 CPU 版本的 PyTorch:
pip install torch torchvision --index-url https://download.pytorch.org/whl/cpu
pip install pdf-craft
同样,也需要按照上述方法安装 Poppler。
安装完成后,可以进行简单验证:
import torch
print('CUDA available:', torch.cuda.is_available())
如果输出 True 则表示 GPU 可用。检查 Poppler 是否在 PATH 中,可以运行 pdfinfo -v。
常见问题:如果遇到错误提示找不到 Poppler,请确认其路径已加入系统 PATH。建议使用 Python 虚拟环境(如 venv 或 conda)进行安装,以避免包依赖冲突。
动手实践:代码示例
环境配置妥当后,就可以用几行 Python 代码开始转换了。
转换为 Markdown
将扫描 PDF 转换为带图片的 Markdown 文件非常简单:
from pdf_craft import transform_markdown
transform_markdown(
pdf_path="input.pdf", # 你的扫描PDF路径
markdown_path="output.md", # 输出的Markdown文件
markdown_assets_path="images" # 提取的图片存放目录
)
你还可以通过参数进行精细控制,例如:ocr_size="gundam"(最高质量,默认),dpi=300,includes_footnotes=True 保留脚注,ignore_pdf_errors=True 遇到错误时继续执行。
转换为带目录的 EPUB
生成适用于电子阅读器的 EPUB 文件是更实用的功能:
from pdf_craft import transform_epub, BookMeta, TableRender, LaTeXRender
transform_epub(
pdf_path="input.pdf",
epub_path="output.epub",
book_meta=BookMeta(
title="书名",
authors=["作者"],
publisher="出版社",
language="zh"
),
ocr_size="gundam",
includes_cover=True,
table_render=TableRender.HTML, # 表格采用HTML渲染
latex_render=LaTeXRender.MATHML, # 公式转为MathML格式
inline_latex=True, # 同时保留内联LaTeX源码
toc_assumed=True # 假设PDF中存在目录页,并自动识别
)
需要注意的是,transform_epub 方法默认假设源PDF中存在目录页并尝试自动识别,而 transform_markdown 则无此假定。
首次运行时,OCR模型会自动从 Hugging Face 下载。对于生产环境,建议提前预下载模型:
from pdf_craft import predownload_models
predownload_models(models_cache_path="models")
如需完全离线运行,在调用转换函数时添加参数 local_only=True 即可。
效果究竟如何?
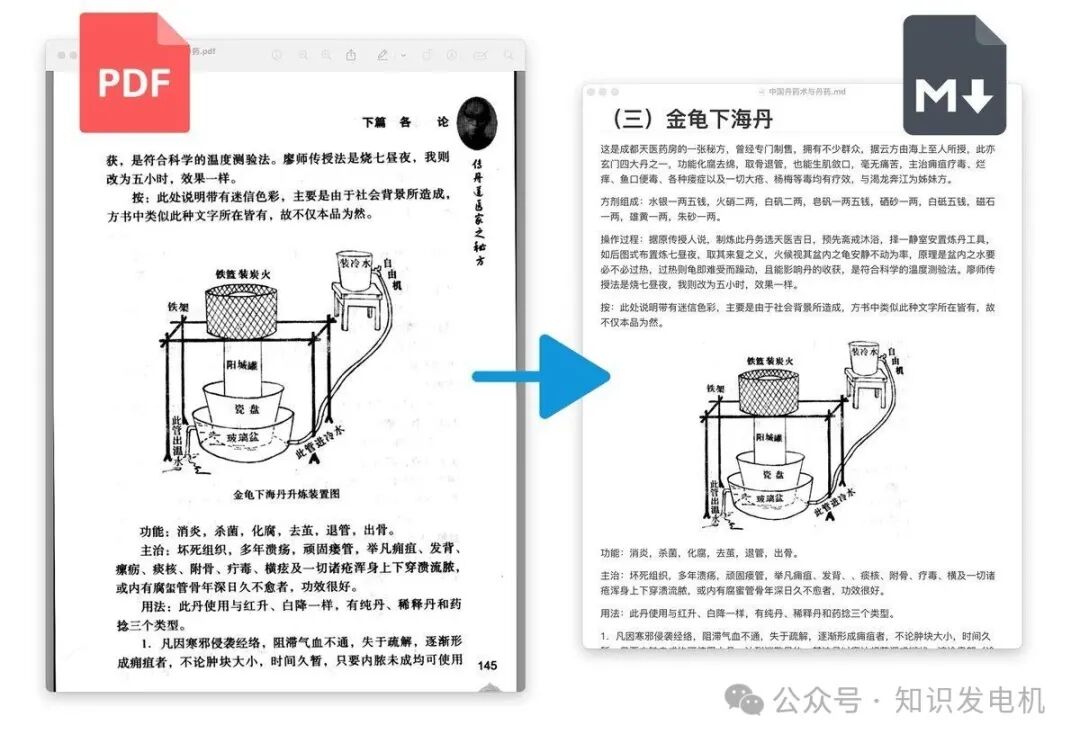
从官方示例(如上图)可以看到实际效果。左侧是原始的扫描PDF页面(包含页眉、复杂示意图),右侧是转换后的 Markdown 渲染结果。
转换后的文本干净整洁,复杂的图表(例如示例中的“炼丹装置示意图”)被完整保留并嵌入,段落结构清晰。即使是像中医古籍这样包含特殊符号、手绘插图和复杂版式的文献,PDF Craft 也能较好地处理,将无用的页眉页脚信息过滤掉,只留下核心内容。
它的应用场景非常明确:个人藏书数字化、古籍或历史文献的电子化归档、学术论文合集整理等。对于动辄数百页的大部头书籍,在 GPU 加速下也能高效处理。
小结
PDF Craft 显著降低了将扫描版 PDF 转换为高质量电子书(尤其是 EPUB)的技术门槛。其本地、免费、注重内容结构完整性的特点,非常适合注重隐私、有大量离线转换需求的阅读爱好者、研究者和资料整理者。
你可以通过其 开源实战 项目地址(https://github.com/oomol-lab/pdf-craft)了解更多详情、报告问题或参与贡献。建议先访问其在线演示站体验效果,如果觉得好用,再部署本地版本。
如果你也有那么几本“压箱底”的扫描版好书想要在电纸书上畅快阅读,不妨试试 PDF Craft。转换效果出色的开源项目值得我们的支持,记得去 GitHub 给它点个 Star,鼓励开发者持续迭代。在 云栈社区 的开发者板块,你也能发现更多类似的有趣工具和技术讨论。
 发表于 2026-3-23 05:05:44
|
查看: 238|
回复: 0
发表于 2026-3-23 05:05:44
|
查看: 238|
回复: 0
