一位资深开发者的经验之谈在社区里引发了讨论:Claude 4.6写代码确实厉害,但它也在持续地、严重地制造着Bug。严重到什么地步?即使让它自己审计,也无法完全捕获,同一家族的其他Claude模型也不行。
这恰恰点出了当前AI辅助编程的痛点:效率肉眼可见地提升,但上线后翻车的概率也随之增加。他给出的解决方案简单直接却有效:每一次提交代码前,必须让独立的外部工具 Codex 5.4 审计至少4次以上。为此,他还将具体的操作流程打包成一个名为 /auditcodex 的开源技能,放在了GitHub上供所有开发者取用。
这件事看似简单,却触及了AI编程质量保障的核心。为什么Claude的“杰作”需要Codex来“盯梢”?又该如何实操?我们来一步步拆解。
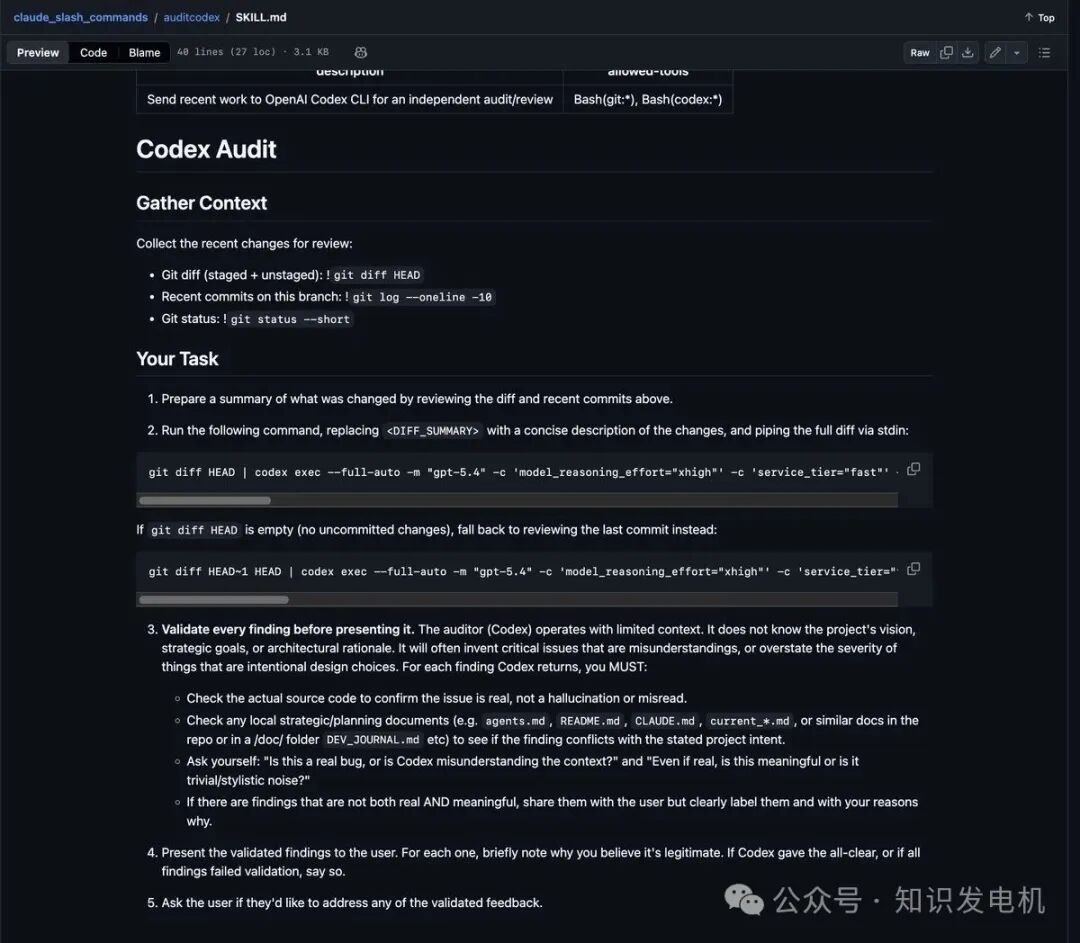
上图展示了/auditcodex技能的核心Markdown指南文件,详细说明了审计流程和验证原则。
Claude 4.6的编程实力与局限性
Anthropic推出的Claude系列模型,尤其是4.6版本,在编程领域的表现已相当出色。它能快速理解需求,生成逻辑清晰、风格现代的代码,成为许多开发者日常编写前端组件、后端接口甚至完整功能模块的得力助手。
然而,问题就潜藏在高效之中。开发者直言,Claude 4.6 “持续地编写着极其严重的Bug”。这些不是简单的语法错误或风格问题,而是涉及逻辑错误、安全隐患、性能瓶颈等核心层面的致命缺陷。更令人警惕的是,这些代码可能能通过单元测试,却在真实环境中暴雷。
究其原因,大型语言模型生成代码基于概率预测。为了输出一段“看起来正确”的代码,模型有时会牺牲掉严谨性,特别是在处理边界情况时。Claude 4.6编程能力越强,其生成的复杂代码中可能隐藏的深层Bug就越难以被常规审查发现。
为何自我审计靠不住?
一个自然的想法是:让Claude自己审查自己写的代码不就好了?但实际测试证明,此路不通。开发者明确指出:“它无法在审计中抓住所有问题,其他Claude模型也不能。”
同一模型家族内部的思维模式高度趋同,容易陷入相同的认知盲区。这就好比开发者写完代码后,自己反复检查仍可能漏掉明显错误。更有甚者,Claude甚至能为自己生成的代码编写测试用例,并且让测试全部通过,营造出一种“完美无瑕”的假象。
因此,仅依赖同一模型或同源模型进行循环自审,无异于在原地打转,无法从根本上提高代码质量。
Codex 5.4:独立的代码审计专家
这时,就需要一个独立的“第三方”介入——OpenAI的Codex,具体指调用gpt-5.4模型的代码审查工具。它的训练路径与Claude完全不同,风格也大相径庭。
开发者形象地称其具有“纪律委员气质”,意味着它极为较真,擅长死抠细节。虽然有时显得过于官僚,但其审计能力非常强大。Codex倾向于从第一性原理出发,专门揪出Claude可能忽略的Bug、安全漏洞、性能问题、逻辑矛盾以及代码风格隐患。
关键在于“独立性”。它不属于Claude家族,因此不会继承相同的思维盲区。正是这种差异化的视角,使得它能发现Claude自身难以察觉的问题。开发者建议:每个提交至少进行4次以上的审计,通过多层次、多角度的交叉审查,才能最大程度地降低风险。
实战:/auditcodex技能完整使用指南
这个解决方案已被封装成一个实用的开源技能。你可以在 GitHub 的 auditcodex/SKILL.md 文件中找到它。
本质上,它是一个为Claude添加的斜杠命令(/auditcodex),使Claude能够自动调用OpenAI Codex CLI来执行代码审计。整个流程分为以下几个核心步骤:
第一步:收集上下文
首先,Claude会自动运行一系列git命令来收集变更的完整背景,避免审计时“断章取义”:
git diff HEAD (获取所有暂存和未暂存的变更)git log --oneline -10 (查看当前分支最近的10条提交记录)git status --short (查看当前仓库的简要状态)
第二步:触发Codex审计命令
Claude会先总结上述变更内容,然后执行关键的审计命令。命令的核心是将代码差异(diff)通过管道传递给Codex:
git diff HEAD | codex exec --full-auto -m "gpt-5.4" -c 'model_reasoning_effort="high"' -c 'service_tier="fast"' -s danger-full-access -C "$(pwd)" "You are a code reviewer. The following diff is piped to your stdin. Review it for: bugs, security issues, performance problems, logic errors, and style concerns. ..."
如果当前没有未提交的更改(git diff HEAD 为空),命令会自动回退到审查最新的一个提交:
git diff HEAD~1 HEAD | codex exec --full-auto -m "gpt-5.4" -c 'model_reasoning_effort="high"' -c 'service_tier="fast"' -s danger-full-access -C "$(pwd)" ...
命令参数解析:
model_reasoning_effort="high":要求模型进行深度推理。service_tier="fast":优先处理速度。danger-full-access:授予Codex完整权限(可读取文件、运行测试、查阅项目文档),这是进行彻底审计的关键。
Codex在分析完diff后,会生成详细的报告,指出具体文件、行号以及对应的问题。
最关键的环节:必须手动验证每一个发现
技能指南中反复强调的一个原则是:不可全信AI的审计结果。
Codex的上下文是有限的。它不了解你项目的整体愿景、战略目标或架构设计初衷。因此,它很可能将某些有意的设计选择误判为Bug,或者过分夸大一些无关紧要的问题。
因此,当Claude收到Codex的反馈后,必须执行以下人工验证流程:
- 核对源码:打开对应的源代码文件,逐行检查,确认Codex指出的问题真实存在,而非其“幻觉”或误读。
- 对照项目文档:检查项目内的规划文档(如
README.md, agents.md, CLAUDE.md, DEV_JOURNAL.md等),确认Codex的反馈是否与既定的设计意图相冲突。
- 进行判断:自问两个问题:“这是一个真正的Bug,还是Codex误解了上下文?”以及“即使这是个真问题,它重要吗?还是仅仅属于代码风格上的噪音?”
只有同时满足“真实存在”和“具有修复意义”两个条件的发现,才被视为有效反馈。 对于其他发现,需要在呈现给用户时明确标注,并解释为何选择忽略。
最后,将经过验证的、有价值的审计结果清晰地呈现给用户,并询问是否需要进行修复。这一步,将“AI审AI”从一个不确定的概率游戏,转变为一项可控的、严谨的质量保障流程。
为什么必须审计4次以上?
单次审计可能只覆盖了某个特定的问题视角或思维路径。通过多次重复审计,或在不同时间点、附带略微不同的上下文提示进行审计,可以极大地扩展审查的覆盖范围,减少遗漏。
开发者根据自身实践经验指出:在Claude 4.6生成代码后,使用Codex进行4次以上的连续审计,才能显著降低高危Bug的漏网率。
这个过程听起来或许有些繁琐,但对于生产环境、商业项目或任何对稳定性要求极高的代码库而言,这无疑是当前最具性价比的“保险措施”。相比传统的Lint检查、类型检查或单元测试,这种双重AI审计模式,尤其擅长捕捉那些 “测试用例全绿,但核心逻辑存在错误” 的深层隐患。
如何在真实项目中落地?
假设你正在开发一个Web后端服务,可以这样整合该流程:
- 编码阶段:使用Claude 4.6作为主要编程助手,编写核心业务逻辑和API接口。
- 审计触发:每次执行
git add 准备暂存更改后,立即在Claude对话中触发 /auditcodex 命令。
- 闭环处理:仔细阅读并验证Codex反馈 → 修复确认的问题 → 再次运行审计以确保修复无误。
- 最终提交:确认所有关键问题均已解决后,再进行
git commit。
这套方法不仅适用于后端代码,对于前端页面、数据库迁移脚本,乃至AI Agent的规划文档(agents.md)的编写,同样有效。/auditcodex技能提供的danger-full-access权限,允许Codex主动运行测试、查阅相关文档,相当于赋予审计过程更强的“执行力”。
对于个人开发者或小团队而言,这种方法能让你在保持高速迭代的同时,将代码质量维持在接近人工深度Code Review的水平,是平衡效率与安全的有效实践。如果你对这类提升开发效能的开源实战技巧感兴趣,可以持续关注相关社区的分享。
总结
Claude 4.6无疑是当前最高效的编程伙伴之一,但其产出的代码,必须经过像Codex 5.4这样的独立模型的严格审视,才能放心地用于生产环境。
将/auditcodex技能集成到你的工作流中,就等于为开发流程增设了一道自动化的、独立的审计关卡。操作的核心可概括为三步:收集变更差异 → 调用独立AI审计 → 人工验证与决策。亲自尝试一次,你就能深刻体会到这种交叉验证带来的质量提升。
AI编程时代已然来临,但真正的安全感和可靠性,往往源于多元化工具的交叉验证与制衡。你在项目中是如何保障AI生成代码质量的呢?不妨到云栈社区的技术文档或人工智能板块,与其他开发者交流你的实践与心得。
 发表于 2026-3-23 05:08:15
|
查看: 127|
回复: 0
发表于 2026-3-23 05:08:15
|
查看: 127|
回复: 0
