在人工智能技术爆发的这几年,一个有趣的现象是,当公众的目光聚焦于大模型的强大能力时,许多实际落地的AI应用却常常卡在一个看似基础但至关重要的环节:数据的检索与记忆。
你是否好奇,为什么智能客服能连贯记住之前的对话上下文?电商平台如何精准推荐“风格相似”的商品?企业知识库又如何从海量文档中瞬间定位到所需答案?这些能力的背后,都离不开一个共同的核心技术——向量数据库。
本文将对当前AI领域最主流的四款向量数据库:Milvus、Qdrant、Weaviate 和 pgvector 进行深度剖析,帮助你理解它们的核心原理、技术特点及适用场景。
一、为什么AI应用离不开向量数据库?
一个常见的疑问是:传统的关系型数据库不能存储向量吗?答案是肯定的,但关键在于无法进行高效检索。
向量数据库的核心原理
在深入具体产品前,花几分钟理解其核心概念至关重要。
1. 万物皆可向量化
想象一下,你需要用一组数字来描述一位朋友,可以是 [身高, 体重, 外向程度, 幽默感…]。AI模型则将一段文本、一张图片或一段音频,转化为由数百乃至数千个维度组成的“特征向量”,相当于为内容赋予了一个高维空间的数学坐标。
2. 相似度计算 = 寻找“邻近点”
向量数据库存储了所有内容的坐标点。当你发起查询时,它先将你的问题转化为坐标点,然后快速计算空间中距离最近的那些点。空间距离越近,内容的语义或特征就越相似。这就像在一幅浩瀚的星图中,快速定位离你最近的星球。
3. 索引:实现快速查找的“秘籍”
如果对每个向量都进行全量距离计算,数据量一大,速度将无法接受。因此需要“索引”——一种高效组织数据的高级目录。例如常见的HNSW(分层导航小世界)算法,它构建了一个多层次的关系网络,让你能通过少数几个“枢纽”快速跳转到目标附近,极大提升了搜索效率。
理解上述三点,你就掌握了向量数据库90%的工作原理。
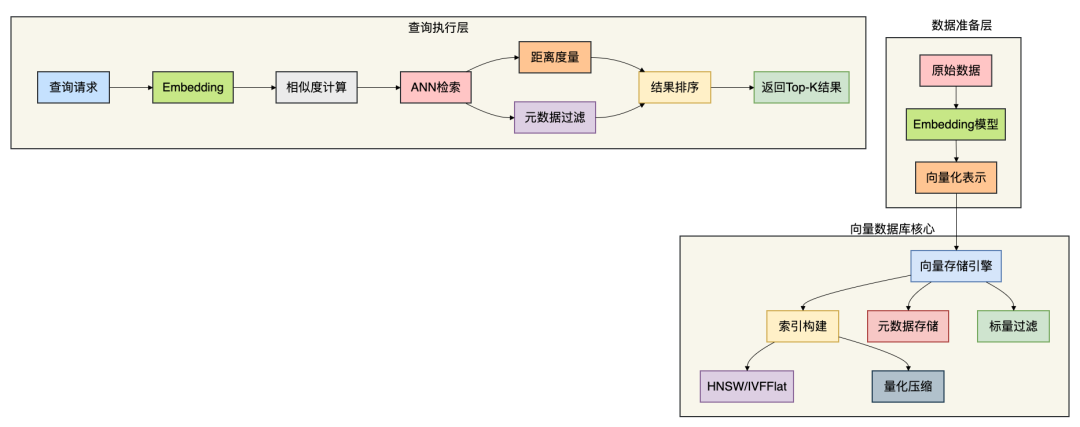
向量数据库的完整架构
下图清晰地展示了一个典型向量数据库的内部工作流程:
二、Milvus:开源领域的“性能怪兽”
2.1 项目概况
一句话定位:专为海量向量搜索设计的分布式数据库。
Milvus是LF AI & Data基金会的毕业项目,由Zilliz主导开发。经过多年迭代,它已成为开源向量数据库领域的标杆。
2.2 底层架构深度解析
Milvus采用存算分离的云原生架构,这是其核心设计亮点:
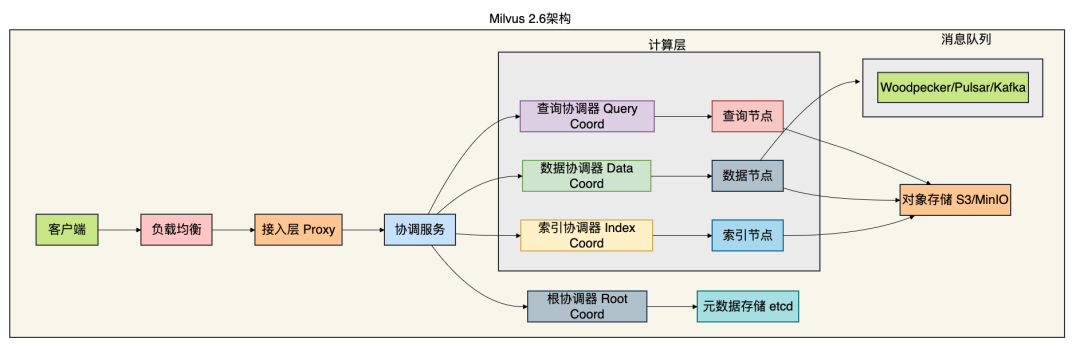
核心创新:三层存储架构
Milvus 2.6引入的三层存储架构是其显著的技术优势:
- 内存层:承载热数据,支持毫秒级查询响应。
- 本地SSD缓存:作为温数据缓存,加速重复访问请求。
- 对象存储(如S3):存放全量数据,保障低成本持久化。
系统基于LRU(最近最少使用)算法智能预测数据访问模式,动态调整数据在层级间的流动。生产环境测试表明,其缓存命中率超过90%,能显著降低87%的存储成本和25%的计算支出。例如,一个10TB的数据集,月均成本可从约3000美元降至400美元。
2.3 混合搜索能力
Milvus最新版本内置了优化的BM25全文检索引擎,支持向量语义搜索与关键词精确匹配的混合查询:
import io.milvus.client.MilvusClient;
import io.milvus.param.*;
import io.milvus.param.collection.SearchParam;
import io.milvus.grpc.SearchResults;
import io.milvus.grpc.SearchResultData;
// 初始化客户端
MilvusClient client = new MilvusClient(ConnectParam.newBuilder()
.withHost("localhost")
.withPort(19530)
.build());
// 构建搜索请求
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName("docs")
.withVectorFieldName("embedding")
.withVectors(Collections.singletonList(queryVector))
.withMetricType(MetricType.COSINE)
.withTopK(10)
.withExpr("category == 'AI'") // 标量过滤
.build();
SearchResults results = client.search(searchParam);
List<SearchResultData> resultData = results.getResults().getFieldsDataList();
实测数据显示,Milvus的BM25检索速度比Elasticsearch快4-7倍,索引体积仅为原始文本的1/3。
2.4 优缺点分析
优点:
- 分布式架构,可水平扩展至千亿级向量。
- 丰富的索引类型:HNSW、IVF、DiskANN、GPU加速的CAGRA等。
- 完善的混合搜索能力:向量 + 全文 + 标量过滤。
- 开源免费,社区非常活跃。
缺点:
- 部署运维复杂,依赖etcd、对象存储、消息队列等多个组件。
- 学习曲线较陡峭,需深入理解其存储和索引概念。
- 对中小规模应用来说可能显得“过重”。
适用场景:
- 超大规模图像/视频检索系统。
- 基因序列分析。
- 大型互联网平台的推荐系统。
- 企业级RAG(检索增强生成)应用。
三、Qdrant:Rust构建的“可组合”搜索引擎
3.1 项目概况
一句话定位:让工程师可以完全掌控检索流程的现代化向量引擎。
2026年3月,Qdrant宣布完成5000万美元B轮融资,市场对“可组合向量搜索”理念的认可度可见一斑。
3.2 核心设计理念
Qdrant的核心理念是可组合性。它认为,生产级AI系统需要比“存储向量并返回最近邻”更精细的控制能力:
“生产级AI系统需要一个搜索引擎,其中检索的每个方面——如何索引、如何评分、如何过滤、如何平衡延迟与精度——都是可组合的决策。” —— André Zayarni, Qdrant CEO
3.3 架构解析
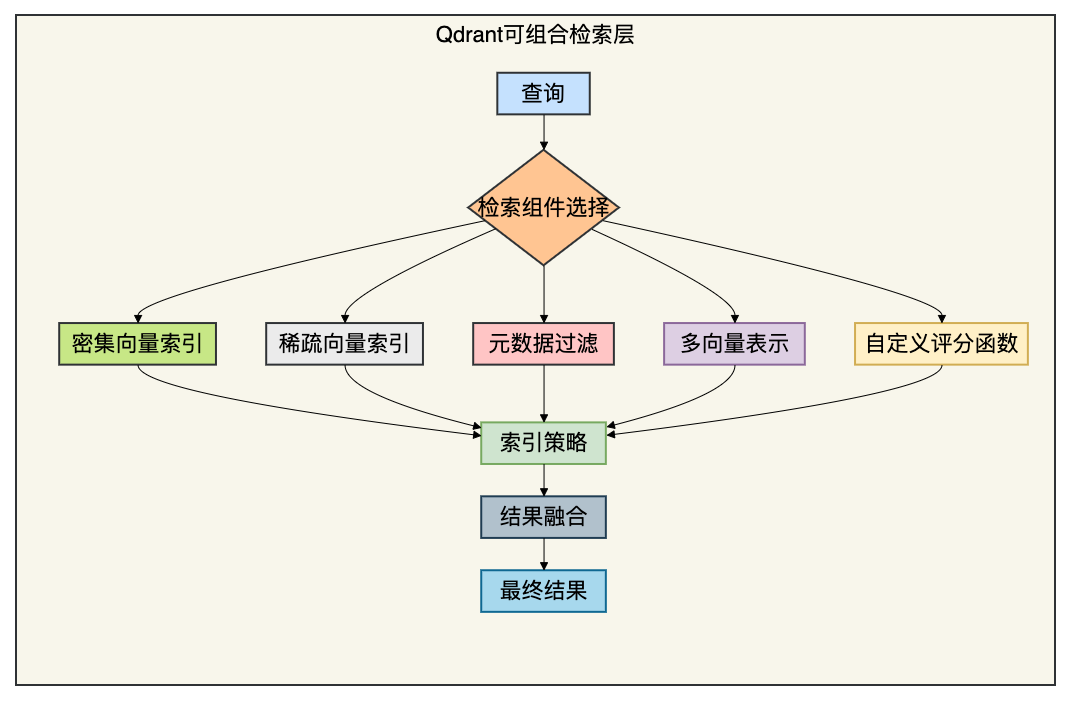
技术亮点:
- Rust语言开发:保障内存安全与零成本抽象,性能卓越。
- 精确控制:工程师可明确选择检索组件,精确调控相关性、延迟和成本。
- 多向量支持:支持密集向量和稀疏向量的混合使用。
3.4 代码示例
import io.qdrant.client.QdrantClient;
import io.qdrant.client.grpc.Points;
import io.qdrant.client.grpc.Collections;
// 初始化客户端
QdrantClient client = new QdrantClient(
QdrantGrpcClient.newBuilder("localhost", 6334, false).build()
);
// 创建集合
Collections.VectorParams vectorParams = Collections.VectorParams.newBuilder()
.setSize(768)
.setDistance(Collections.Distance.Cosine)
.build();
client.createCollectionAsync("products",
Collections.CreateCollection.newBuilder()
.setVectorsConfig(Collections.VectorsConfig.newBuilder()
.setParams(vectorParams).build())
.build()
).get();
// 插入数据时支持丰富的元数据
Points.PointStruct point = Points.PointStruct.newBuilder()
.setId(Points.PointId.newBuilder().setNum(1).build())
.addAllVector(FloatVector.asList(0.1f, 0.2f, ...))
.putPayload("category", Points.Value.newBuilder()
.setStringValue("electronics").build())
.putPayload("price", Points.Value.newBuilder()
.setDoubleValue(299.99).build())
.putPayload("in_stock", Points.Value.newBuilder()
.setBoolValue(true).build())
.build();
client.upsertAsync("products", Collections.singletonList(point)).get();
// 带复杂过滤条件的检索
Points.SearchPoints searchPoints = Points.SearchPoints.newBuilder()
.setCollectionName("products")
.addAllVector(FloatVector.asList(queryVec))
.setLimit(10)
.setFilter(Points.Filter.newBuilder()
.addMust(Points.Condition.newBuilder()
.setField("category")
.setMatch(Points.Match.newBuilder()
.setKeyword("electronics").build()).build())
.addMust(Points.Condition.newBuilder()
.setField("price")
.setRange(Points.Range.newBuilder()
.setLte(500.0).build()).build())
.build())
.build();
Points.SearchResponse response = client.searchAsync(searchPoints).get();
3.5 优缺点分析
优点:
- Rust开发,内存占用低,性能极致。
- 可组合设计,赋予工程师对检索流程前所未有的控制力。
- 支持密集/稀疏向量混合检索。
- 轻量级部署,资源消耗小。
缺点:
- 生态系统规模相对Milvus较小。
- 分布式功能的成熟度不及Milvus。
- 中文技术资料相对较少。
适用场景:
- 对延迟要求极高的实时推荐系统。
- 资源受限的边缘AI设备部署。
- 需要精细控制检索逻辑的生产系统。
- 中小规模的高精度检索场景。
四、Weaviate:混合搜索的“多面手”
4.1 项目概况
一句话定位:既能做向量搜索,又能做关键词搜索的“全能型”数据库。
Weaviate是一个开源向量数据库,以其独特的混合搜索能力和友好的GraphQL接口著称。它内置多种AI模型,可自动完成数据的向量化。
4.2 核心架构
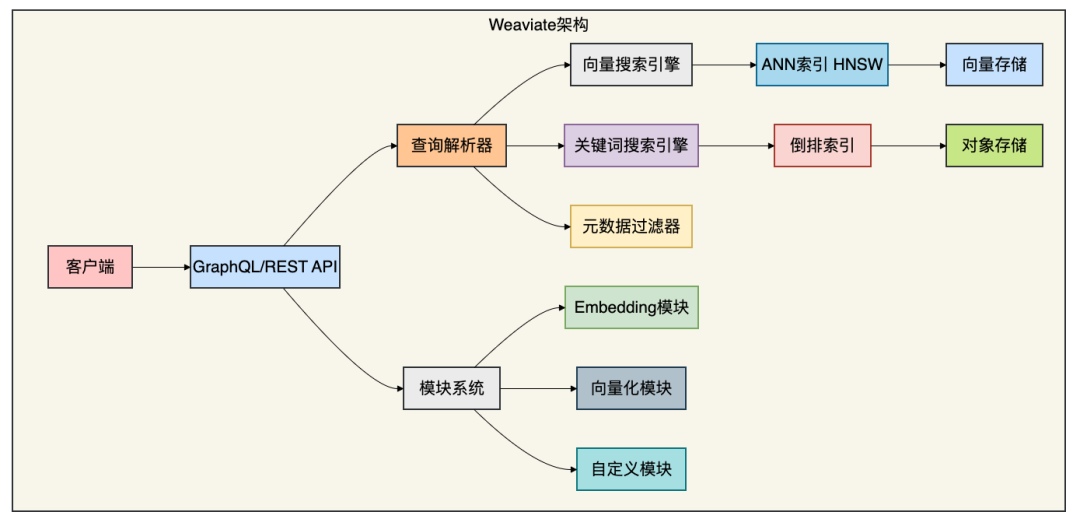
4.3 混合搜索实战
Weaviate的杀手锏是混合搜索——同时执行向量搜索(找语义相似的)和关键词搜索(找字面匹配的),从而得到更精准的结果:
# GraphQL混合搜索查询
{
Get {
Product(
hybrid: {
query: "wireless headphones with noise cancellation"
alpha: 0.5 # 平衡向量搜索和关键词搜索的权重
vector: [0.1, 0.2, ...] # 可选:直接提供查询向量
}
limit: 10
) {
name
description
price
_additional {
score
explainScore
}
}
}
}
Alpha参数是关键:alpha=1表示纯向量搜索,alpha=0表示纯关键词搜索,中间值则对两者结果进行加权融合。
4.4 模块化设计
Weaviate的模块系统允许用户轻松切换不同的AI模型:
# docker-compose.yml
version: '3.4'
services:
weaviate:
image: semitechnologies/weaviate:1.36.0
environment:
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'text2vec-openai'
ENABLE_MODULES: 'text2vec-openai,text2vec-cohere,qna-openai'
OPENAI_APIKEY: ${OPENAI_APIKEY}
2026年3月发布的Weaviate 1.36版本引入了HFresh向量索引(预览版)、Server-side Batching、Object TTL等新特性。
4.5 优缺点分析
优点:
- GraphQL接口,对前端开发者极为友好。
- 内置多种AI模型,开箱即用。
- 混合搜索能力在业界处于领先地位。
- 模块化设计,支持功能插拔。
缺点:
- 在超大规模(十亿级以上)场景下,性能需要精细调优。
- 社区规模小于Milvus。
- 中文资料相对有限。
适用场景:
- 需要结合关键词和语义搜索的企业知识库。
- 公司内部的智能搜索引擎。
- 快速构建AI应用原型。
- 涉及文本、图像等多模态的搜索场景。
五、pgvector:PostgreSQL的“AI扩展包”
5.1 项目概况
一句话定位:为老朋友PostgreSQL赋予AI向量搜索能力。
pgvector是PostgreSQL的一个开源扩展,它将向量搜索能力无缝集成到这个全球最流行的关系型数据库中。
5.2 为什么选择pgvector?
一个直接的问题:为什么要在关系数据库里做向量搜索?答案很简单——如果你的技术栈已经基于PostgreSQL,那么pgvector几乎是零成本上手的最佳选择。
-- 安装扩展
CREATE EXTENSION vector;
-- 创建带向量列的表
CREATE TABLE items (
id bigserial PRIMARY KEY,
content text,
embedding vector(768) -- 768维向量
);
-- 创建HNSW索引加速查询
CREATE INDEX ON items USING hnsw (embedding vector_cosine_ops);
-- 向量相似度查询
SELECT * FROM items
ORDER BY embedding <=> '[0.1, 0.2, ...]'
LIMIT 10;
5.3 数据类型和索引
pgvector支持多种向量数据类型,满足不同场景:
| 数据类型 |
精度 |
最大维度 |
典型场景 |
| vector |
单精度浮点(4字节) |
≤16,000 |
传统Embedding |
| halfvec |
半精度浮点(2字节) |
≤16,000 |
高维Embedding,省内存 |
| bit |
二进制位 |
≤64,000 |
二进制哈希,图像特征 |
| sparsevec |
稀疏向量 |
≤16,000非零 |
TF-IDF特征,超高维稀疏 |
5.4 距离函数
pgvector提供了丰富的距离度量函数:
-- 欧几里得距离(L2)
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]';
-- 内积(负值,越大越相似)
SELECT * FROM items ORDER BY embedding <#> '[3,1,2]';
-- 余弦距离
SELECT * FROM items ORDER BY embedding <=> '[3,1,2]';
-- 曼哈顿距离(L1)
SELECT * FROM items ORDER BY embedding <+> '[3,1,2]';
-- 汉明距离(二进制)
SELECT * FROM items ORDER BY bit_vec <~> '101010';
-- Jaccard距离
SELECT * FROM items ORDER BY bit_vec <%> '101010';
5.5 索引类型
pgvector主要支持IVFFlat和HNSW两种索引:
| 索引类型 |
构建速度 |
查询速度 |
内存占用 |
适用场景 |
| IVFFlat |
快 |
中等 |
低 |
中大规模数据集 |
| HNSW |
慢 |
极快 |
高 |
低延迟要求场景 |
5.6 优缺点分析
优点:
- 无需引入新数据库,无缝复用现有PostgreSQL运维体系与经验。
- 完美支持ACID事务,这是专用向量数据库通常不具备的。
- SQL语法,学习成本几乎为零。
- 向量数据可与关系数据无缝关联查询。
缺点:
- 处理海量、超高维向量时,绝对性能不如专用数据库。
- 支持的索引类型相对较少。
- 不适合纯粹的、大规模向量检索场景。
适用场景:
- 已在PostgreSQL的中小型AI应用上增加向量搜索能力。
- 需要严格事务保证的AI业务。
- 希望用SQL统一管理关系数据和向量数据。
- 快速在现有系统上验证和增加AI能力。
六、四大向量数据库对比与选型
6.1 功能特性对比
| 维度 |
Milvus |
Qdrant |
Weaviate |
pgvector |
| 定位 |
分布式向量数据库 |
可组合搜索引擎 |
混合搜索数据库 |
PostgreSQL扩展 |
| 开发语言 |
Go/C++ |
Rust |
Go |
C |
| 架构模式 |
存算分离 |
一体化 |
模块化 |
嵌入式 |
| 索引类型 |
HNSW/IVF/DiskANN/CAGRA |
HNSW |
HNSW |
IVFFlat/HNSW |
| 混合搜索 |
✅ BM25+向量 |
✅ 稀疏+密集 |
✅ 关键词+向量 |
❌ 需应用层实现 |
| 分布式 |
✅ 原生分布式 |
⚠️ 集群版收费 |
✅ 支持 |
❌ 依赖PG本身 |
| ACID事务 |
❌ |
❌ |
❌ |
✅ 完美支持 |
| 易用性 |
⭐⭐ |
⭐⭐⭐ |
⭐⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
| 性能(大规模) |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐⭐ |
⭐⭐⭐⭐ |
⭐⭐⭐ |
| 社区活跃度 |
极高 |
高 |
高 |
极高 |
6.2 如何选型?
下面的决策流程图可以为你提供一个清晰的选型起点:
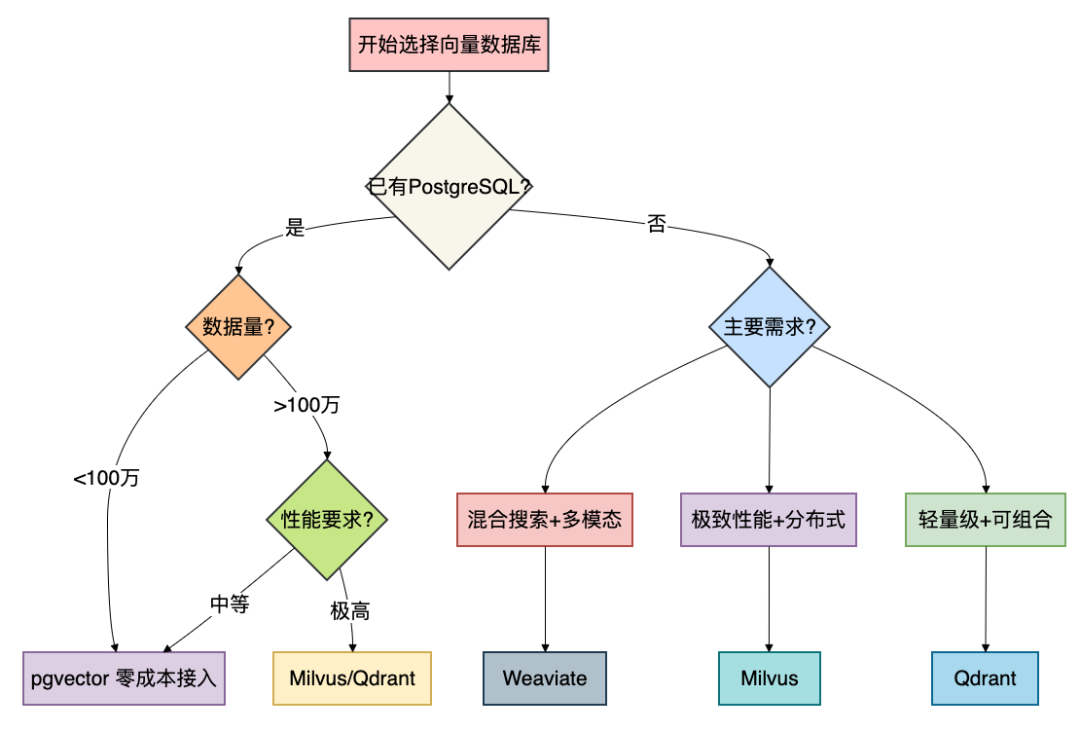
6.3 实战场景建议
场景1:企业知识库RAG系统
推荐: Weaviate
理由: 混合搜索能力出色,关键词+语义双路召回,结果更精准。
配置: 使用GraphQL API,利用其开箱即用的Embedding模块。
场景2:电商商品推荐系统
推荐: Qdrant
理由: 延迟极低,支持复杂的商品属性过滤,可精确控制检索逻辑。
配置: 利用payload存储商品品类、价格等元数据,结合过滤条件进行检索。
场景3:海量图像/视频内容检索
推荐: Milvus
理由: 分布式架构可线性扩展,支撑千亿级向量,支持GPU加速。
配置: 使用DiskANN索引处理超大规模数据,利用三层存储架构控制成本。
场景4:在现有PostgreSQL系统中增加AI能力
推荐: pgvector
理由: 零成本接入,无需引入新组件,保证业务数据的ACID特性。
配置: 在现有表中增加vector列,创建HNSW索引,通过SQL直接进行相似度查询。
总结
向量数据库已成为构建现代AI应用不可或缺的基础设施。通过本文的对比分析,我们可以得出以下结论:
- Milvus 是海量数据与极致性能场景的首选,其分布式架构和创新的存储设计能有效平衡成本与规模。
- Qdrant 为追求极致控制力和高性能的团队量身定制,其可组合设计让工程师能深度优化检索链路。
- Weaviate 在混合搜索领域表现出色,尤其适合需要结合语义与关键词检索的应用,对前端开发者友好。
- pgvector 是PostgreSQL生态的最佳补充,为已有系统快速增加AI能力提供了最平滑的路径。
没有“最好”的向量数据库,只有“最适合”你当前场景的选择。 在做决策前,建议先明确几个关键问题:
- 数据规模:是十万级、百万级,还是十亿级?
- 性能要求:需要毫秒级响应,还是秒级可接受?
- 现有技术栈:是否已深度依赖PostgreSQL或其他数据库?
- 团队能力:是否具备分布式系统的运维经验?
希望这篇深度对比能为你在AI应用开发的道路上提供有价值的参考,助你做出更明智的技术选型。
 发表于 2026-3-24 04:53:27
|
查看: 136|
回复: 0
发表于 2026-3-24 04:53:27
|
查看: 136|
回复: 0
