一、什么是线性结构?——先把“线性”两个字理解透
线性结构的本质是元素之间存在“一对一”的前后关系。
想象一列排队的人,除了第一个和最后一个,每个人都有且只有一个“前面的人”和一个“后面的人”。这正是线性结构的核心特征。
线性结构具备四大特点:
- 存在 唯一 的“第一个”元素。
- 存在 唯一 的“最后一个”元素。
- 除第一个元素外,每个元素有且仅有 一个直接前驱。
- 除最后一个元素外,每个元素有且仅有 一个直接后继。
常见的线性结构包括:数组、链表、栈、队列。它们的区别不在于“是不是线性的”,而在于 存储方式 和 操作规则 的不同。
二、数组——最“朴素”却最深刻的结构
2.1 数组的内存本质
数组是在 连续内存空间 中存放的一组 相同类型 的数据。
内存地址(假设起始地址为 1000,每个元素占 4 字节):
地址: 1000 1004 1008 1012 1016
值: [ 10 ] [ 20 ] [ 30 ] [ 40 ] [ 50 ]
索引: [0] [1] [2] [3] [4]
为什么数组的下标通常从 0 开始?
这并非随意的设计。计算机访问数组元素的地址计算公式是:元素地址 = 首地址 + 下标 × 每个元素的大小。
- 如果下标从 0 开始:
addr[i] = base + i × size,只需要一次乘法和一次加法。
- 如果下标从 1 开始:
addr[i] = base + (i-1) × size,多了一次减法运算。
在 CPU 层面,少一条指令就意味着少一个时钟周期。在大量访问操作时,这种差距会变得非常明显。
2.2 数组的核心操作与时间复杂度
| 操作 |
时间复杂度 |
原因 |
随机访问 a[i] |
O(1) |
直接通过地址公式计算,一步到位 |
| 尾部插入 |
O(1) |
直接在末尾写入 |
| 中间插入 |
O(n) |
插入点之后的所有元素都要后移一位 |
| 中间删除 |
O(n) |
删除点之后的所有元素都要前移一位 |
| 查找(无序) |
O(n) |
只能逐个遍历 |
| 查找(有序) |
O(log n) |
可以用二分查找 |
插入操作的内部过程(图解):
在位置 2 插入元素 25:
操作前: [ 10 | 20 | 30 | 40 | 50 | ]
↑ 插入位置
第1步: [ 10 | 20 | 30 | 40 | | 50 ] ← 50 后移
第2步: [ 10 | 20 | 30 | | 40 | 50 ] ← 40 后移
第3步: [ 10 | 20 | | 30 | 40 | 50 ] ← 30 后移
第4步: [ 10 | 20 | 25 | 30 | 40 | 50 ] ← 写入 25
关键点:必须从后往前移动,否则会覆盖数据。这是初学者最容易犯的错误。
2.3 动态数组的扩容机制
静态数组大小固定,而实际开发中常用的 ArrayList(Java)、vector(C++)、list(Python)都是 动态数组。
扩容的核心策略—— 倍增法 :
初始容量: 4
[1, 2, 3, 4] ← 满了!
扩容 → 新建容量为 8 的数组,拷贝旧数据:
[1, 2, 3, 4, _, _, _, _]
继续添加...
[1, 2, 3, 4, 5, 6, 7, 8] ← 又满了!
扩容 → 新建容量为 16 的数组...
为什么选择扩为 2 倍,而不是每次只增加 1 个位置?
- 如果每次只扩 1 个位置,插入 n 个元素需要拷贝
1+2+3+...+n = O(n²) 次。
- 采用 2 倍扩容,总拷贝次数约为
n + n/2 + n/4 + ... ≈ 2n = O(n)。
这就是 均摊分析(Amortized Analysis) 的经典案例:虽然单次扩容的代价是 O(n),但平均到每次插入操作上,其时间复杂度仅为 O(1)。
三、链表——用“指针”换“灵活”
3.1 为什么需要链表?
数组的致命缺点是:插入和删除需要大量移动元素。
链表的设计思想是:放弃连续存储,用指针把分散的节点串起来,从而获得插入/删除的灵活性。
3.2 单链表的内部结构
每个节点包含两个部分:
┌──────────┬──────────┐
│ data │ next │ ← 一个节点
└──────────┴──────────┘
数据域 指针域(存储下一个节点的地址)
一个完整的单链表结构如下:
head
↓
┌──┬──┐ ┌──┬──┐ ┌──┬──┐ ┌──┬──────┐
│10│ ─┼───→│20│ ─┼───→│30│ ─┼───→│40│ NULL │
└──┴──┘ └──┴──┘ └──┴──┘ └──┴──────┘
3.3 链表的核心操作(深入指针变化)
插入操作 —— 在节点 A 后面插入新节点 X:
操作前: A ──→ B
第1步: X.next = A.next (X 先指向 B)
A ──→ B
X ──↗
第2步: A.next = X (A 再指向 X)
A ──→ X ──→ B
顺序不能反! 如果先执行 A.next = X,就丢失了 B 的地址,导致链表断裂。
删除操作 —— 删除节点 A 后面的节点 B:
操作前: A ──→ B ──→ C
操作: A.next = B.next (A 直接指向 C,跳过 B)
A ──→ C
B(变成孤立节点,等待回收)
3.4 单链表 vs 双链表 vs 循环链表
【单链表】只能向后遍历
head → [A] → [B] → [C] → NULL
【双链表】可以双向遍历,每个节点多一个 prev 指针
NULL ← [A] ⇄ [B] ⇄ [C] → NULL
【循环链表】尾节点指回头节点,形成环
head → [A] → [B] → [C] ─┐
↑ │
└───────────────────────┘
双链表的代价:每个节点多存一个指针,空间开销增大。
双链表的收益:删除当前节点时不需要知道其前驱节点,时间复杂度从 O(n) 降到 O(1)。
3.5 数组 vs 链表——一张表说清楚
| 维度 |
数组 |
链表 |
| 内存布局 |
连续 |
分散 |
| 随机访问 |
O(1),直接算地址 |
O(n),必须从头遍历 |
| 插入/删除 |
O(n),需要移动元素 |
O(1),只改指针(已知位置时) |
| 空间开销 |
只存数据 |
额外存指针 |
| 缓存友好 |
极好(连续内存,CPU 预取高效) |
差(地址跳跃,缓存命中率低) |
| 适用场景 |
频繁查询,少量增删 |
频繁增删,少量查询 |
实际工程中的真相:由于现代 CPU 强大的缓存机制,数组在大多数场景下的实际性能往往优于链表。链表的 O(1) 插入优势,常常被缓存失效带来的巨大开销所抵消。
四、栈——“后进先出”的两种实现方式
4.1 栈的抽象定义
栈是一种 限制操作位置 的线性结构:只允许在 栈顶(top) 进行插入(push)和删除(pop)。
┌─────┐
│ 3 │ ← 栈顶(top),最后进来,最先出去
├─────┤
│ 2 │
├─────┤
│ 1 │ ← 栈底(bottom),最先进来,最后出去
└─────┘
核心原则:LIFO(Last In, First Out)后进先出
4.2 实现方式一:顺序栈(基于数组)
用数组实现栈,需要一个变量 top 来记录栈顶位置。
初始状态(空栈):
top = -1
[ _ | _ | _ | _ | _ ]
push(10): top = 0
[10 | _ | _ | _ | _ ]
↑top
push(20): top = 1
[10 |20 | _ | _ | _ ]
↑top
push(30): top = 2
[10 |20 |30 | _ | _ ]
↑top
pop() → 返回 30: top = 1
[10 |20 | _ | _ | _ ]
↑top
核心代码逻辑:
// 入栈
void push(Stack *s, int value){
if( s->top == MAX_SIZE-1 ) {// 栈满判断
printf("栈溢出!");
return;
}
s->top++;// 栈顶指针先上移
s->data[s->top]=value;// 再存入数据
}
// 出栈
int pop(Stack *s){
if( s->top == -1 ) {// 栈空判断
printf("栈为空!");
return -1;
}
int value = s->data[s->top];// 先取出数据
s->top--;// 栈顶指针再下移
return value;
}
顺序栈的优缺点:
- 优点:实现简单,访问速度快(连续内存)。
- 缺点:需要预先分配固定大小,可能浪费空间或溢出。
4.3 实现方式二:链栈(基于链表)
用单链表实现栈,让头节点作为栈顶。
push(30) → push(20) → push(10) 后:
top
↓
[10] → [20] → [30] → NULL
push 操作 = 头插法
pop 操作 = 删除头节点
核心代码逻辑:
// 入栈(头插法)
void push(LinkStack *s, int value) {
Node *newNode = malloc(sizeof(Node));
newNode->data = value;
newNode->next = s->top;// 新节点指向原栈顶
s->top = newNode;// 更新栈顶
}
// 出栈(删除头节点)
int pop(LinkStack *s){
if(s->top == NULL) {
printf("栈为空!");
return -1;
}
Node *temp = s->top;
int value = temp->data;
s->top = temp->next;// 栈顶下移
free(temp);// 释放旧栈顶
return value;
}
链栈的优缺点:
- 优点:不存在溢出问题(动态分配内存)。
- 缺点:每个节点多占一个指针的空间,且频繁的
malloc/free 有性能开销。
4.4 两种实现方式的对比
| 维度 |
顺序栈(数组) |
链栈(链表) |
| 空间分配 |
静态,需预设大小 |
动态,按需分配 |
| 栈满情况 |
可能溢出 |
不会溢出(内存够就行) |
| 空间效率 |
可能浪费(预分配多了) |
每个节点多一个指针 |
| 时间效率 |
push/pop 均 O(1) |
push/pop 均 O(1),但有 malloc 开销 |
| 实际选择 |
大多数场景首选 |
栈大小完全不可预测时使用 |
4.5 栈的经典应用——括号匹配问题
问题: 判断字符串 "({[]})" 中的括号是否匹配。
解题思路:
遍历字符串,遇到左括号就入栈,遇到右括号就与栈顶匹配:
字符串: ( { [ ] } )
第1步: '(' → 入栈 栈: [ ( ]
第2步: '{' → 入栈 栈: [ ( { ]
第3步: '[' → 入栈 栈: [ ( { [ ]
第4步: ']' → 栈顶是'['匹配 → 出栈 栈: [ ( { ]
第5步: '}' → 栈顶是'{'匹配 → 出栈 栈: [ ( ]
第6步: ')' → 栈顶是'('匹配 → 出栈 栈: [ ](空)
遍历结束,栈为空 → 括号匹配!
三种不匹配的情况:
- 右括号多了:遇到右括号时栈已经空了。
- 左括号多了:遍历结束后栈不为空。
- 类型不匹配:右括号与栈顶的左括号类型不对应。
4.6 栈的经典应用——表达式求值
将中缀表达式 3 + 4 × 2 转换为后缀表达式 3 4 2 × + 并求值:
使用两个栈:运算符栈 + 输出队列
扫描: 3 → 直接输出 输出: 3 运算符栈: []
扫描: + → 入运算符栈 输出: 3 运算符栈: [+]
扫描: 4 → 直接输出 输出: 3 4 运算符栈: [+]
扫描: × → 优先级 > 栈顶+ 输出: 3 4 运算符栈: [+ ×]
所以直接入栈
扫描: 2 → 直接输出 输出: 3 4 2 运算符栈: [+ ×]
结束 → 依次弹出运算符 输出: 3 4 2 × + 运算符栈: []
后缀表达式求值(只用一个栈):
扫描: 3 4 2 × +
3 → 入栈 栈: [3]
4 → 入栈 栈: [3, 4]
2 → 入栈 栈: [3, 4, 2]
× → 弹出4和2,算4×2=8,入栈 栈: [3, 8]
+ → 弹出3和8,算3+8=11,入栈 栈: [11]
结果 = 11
五、队列——“先进先出”与循环队列
5.1 队列的基本概念
入队(enqueue) 出队(dequeue)
↓ ↓
┌────┬────┬────┬────┬────┐
│ E │ D │ C │ B │ A │ → A 先出
└────┴────┴────┴────┴────┘
队尾(rear) 队头(front)
核心原则:FIFO(First In, First Out)先进先出
5.2 循环队列——解决“假溢出”
普通数组实现队列会遇到“假溢出”问题:队头前的空间被浪费,无法利用。
初始: front=0, rear=0
[ _ | _ | _ | _ | _ ]
入队3个: front=0, rear=3
[ A | B | C | _ | _ ]
出队2个: front=2, rear=3
[ _ | _ | C | _ | _ ]
↑front
前面两个位置浪费了!再入队3个就“满”了,但实际还有空位。
循环队列的解决方案:让队尾指针 rear 在到达数组末尾后绕回到头部!使用取模运算实现循环:rear = (rear + 1) % MAX_SIZE。
┌───┐
┌──│ 0 │──┐
│ └───┘ │
┌───┐ ┌───┐
│ 4 │ │ 1 │
└───┘ └───┘
│ ┌───┐ │
└──│ 3 │──┘
└───┘
│
┌───┐
│ 2 │
└───┘
关键问题:如何区分“队满”和“队空”?
两者的条件在代码上看起来都是 front == rear!
解决方案:牺牲一个存储单元作为标志。
- 队空条件:
front == rear
- 队满条件:
(rear + 1) % MAX_SIZE == front
队空: 队满(差一个位置):
front front
↓ ↓
[ _ | _ | _ | _ | _ ] [ _ | D | E | F | G ]
↑ ↑
rear rear
front == rear (rear+1)%5 == front
六、矩阵——二维数据的存储艺术
6.1 矩阵的存储方式
一个 3×4 的矩阵在逻辑上是二维的,但计算机内存是一维的线性排列。如何映射?
逻辑矩阵:
列0 列1 列2 列3
行0 [ 1 2 3 4 ]
行1 [ 5 6 7 8 ]
行2 [ 9 10 11 12 ]
行优先存储(C/C++/Java/Python 列表等):
内存顺序: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
← 第0行 → ← 第1行 → ← 第2行 →
地址公式: addr[i][j] = base + (i × 列数 + j) × size
例: addr[1][2] = base + (1×4 + 2)×4 = base + 24
列优先存储(Fortran/MATLAB 等):
内存顺序: [1, 5, 9, 2, 6, 10, 3, 7, 11, 4, 8, 12]
← 第0列→ ← 第1列 → ← 第2列 → ←第3列→
地址公式: addr[i][j] = base + (j × 行数 + i) × size
为什么这很重要? 遍历矩阵时,按照其存储顺序访问(行优先存储就按行遍历)能大幅提升 CPU 缓存的命中率,性能可能提升 数倍。
6.2 特殊矩阵的压缩存储
对称矩阵(a[i][j] == a[j][i]):利用其对称性,只存储下三角(或上三角)部分,空间减半。
原矩阵: 只存下三角:
[1 2 3] [1]
[2 5 6] → [2, 5]
[3 6 9] [3, 6, 9]
一维数组: [1, 2, 5, 3, 6, 9]
映射公式: k = i(i+1)/2 + j (当 i ≥ j 时)
稀疏矩阵(大部分元素为 0):用三元组表存储,只记录非零元素的位置和值。
原矩阵 (4×5):
[0 0 3 0 0]
[0 0 0 0 0]
[0 0 0 0 7]
[0 2 0 0 0]
三元组表:
(行, 列, 值)
(0, 2, 3)
(2, 4, 7)
(3, 1, 2)
只存储 3 个三元组,而不是 20 个元素!
6.3 稀疏矩阵的十字链表
当稀疏矩阵需要频繁修改(增删非零元)时,三元组表的插入删除效率低下。十字链表是更灵活的选择。
每个非零元素是一个节点,同时处于两条链上:
- 行链表:同一行的所有非零元素串成一条链。
- 列链表:同一列的所有非零元素串成一条链。
col0 col1 col2 col4
↓ ↓ ↓ ↓
row0: ─────────────→(0,2,3)────→ NULL
↓
row2: ──────────────────────→(2,4,7)→ NULL
↓
row3: ────→(3,1,2)──→ NULL NULL
↓
NULL
七、图——非线性结构的核心
7.1 图的基本概念
图是由 顶点(Vertex) 和连接顶点的 边(Edge) 组成的非线性结构。
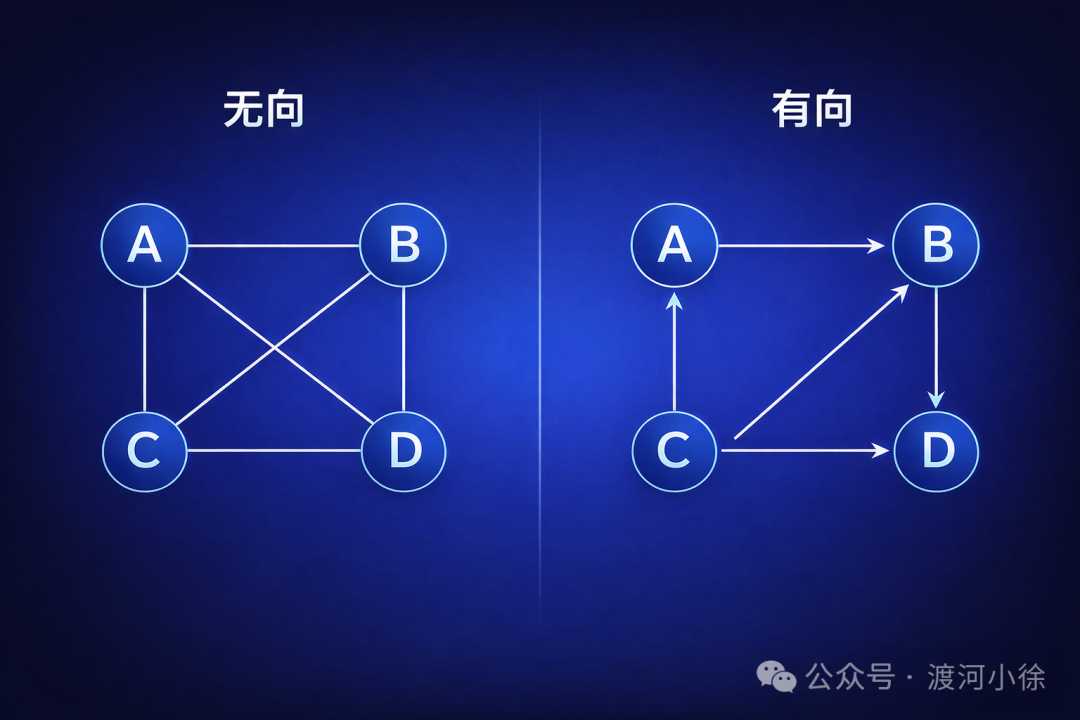
关键术语:
- 度:与一个顶点相连的边数(有向图分 入度 和 出度)。
- 路径:从一个顶点到另一个顶点经过的边序列。
- 连通:两个顶点之间存在路径。
- 权:边上的数值(如距离、费用、容量等)。
7.2 图的存储方式一:邻接矩阵
用一个 n×n 的二维数组(矩阵)表示,matrix[i][j] = 1 表示顶点 i 和 j 之间有边(对于带权图,存储权值)。
图: 邻接矩阵:
A ── B A B C D
| | A [0, 1, 1, 0]
C ── D B [1, 0, 0, 1]
C [1, 0, 0, 1]
D [0, 1, 1, 0]
特点分析:
- 空间复杂度:O(V²),V 为顶点数。
- 判断两点是否相连:O(1),直接查表。
- 获取某顶点的所有邻居:O(V),需要扫描一整行。
- 适用场景:稠密图(边很多),稀疏图使用会浪费大量空间。
7.3 图的存储方式二:邻接表
为每个顶点维护一个链表(或数组),存储所有与它直接相连的顶点。
图: 邻接表:
A ── B A → [B] → [C]
| | B → [A] → [D]
C ── D C → [A] → [D]
D → [B] → [C]
特点分析:
- 空间复杂度:O(V + E),E 为边数。
- 判断两点是否相连:O(degree),需要遍历链表。
- 获取某顶点的所有邻居:O(degree),直接遍历链表即可。
- 适用场景:稀疏图(边较少),是更节省空间的选择。
7.4 图的遍历——BFS 与 DFS
DFS(深度优先搜索) —— “一条路走到黑”
使用栈(递归则利用系统调用栈)实现。
图: A ── B
| / |
| / |
C ── D
DFS 从 A 出发:
访问 A → 访问 B(A的邻居)→ 访问 C(B的邻居)→ 访问 D(C的邻居)
访问顺序: A → B → C → D
内部递归过程(隐式栈):
dfs(A): 标记A已访问
→ dfs(B): 标记B已访问
→ dfs(C): 标记C已访问(A已访问跳过)
→ dfs(D): 标记D已访问(B已访问跳过)
→ 所有邻居都已访问,回退
BFS(广度优先搜索) —— “层层推进”
使用队列实现。
BFS 从 A 出发:
第1层: 访问 A 队列: [B, C]
第2层: 访问 B, 访问 C 队列: [D](B的邻居D,C的邻居已访问)
第3层: 访问 D 队列: []
访问顺序: A → B → C → D
内部队列过程:
队列: [A]
出队A,将A的未访问邻居B、C入队 → 队列: [B, C]
出队B,将B的未访问邻居D入队 → 队列: [C, D]
出队C,无未访问邻居 → 队列: [D]
出队D,无未访问邻居 → 队列: []
| 对比 |
DFS |
BFS |
| 数据结构 |
栈(递归用系统栈) |
队列 |
| 空间复杂度 |
O(V)(最深路径长度) |
O(V)(最宽层的宽度) |
| 适用场景 |
路径搜索、拓扑排序、检测环 |
最短路径(无权图)、层次遍历、广播 |
7.5 经典图算法——最短路径
Dijkstra 算法(单源最短路径) 核心思想:
贪心策略:每次从未确定最短路径的顶点中,选取距离源点最近的那个,然后用它来更新其所有邻居的距离。
示例图(带权):
A --1-- B --3-- D
| ↗
4 2
| ↗
C -------
从A出发:
初始: dist[A]=0, dist[B]=∞, dist[C]=∞, dist[D]=∞
第1轮: 选A(dist=0)
更新B: min(∞, 0+1) = 1
更新C: min(∞, 0+4) = 4
dist = [A:0, B:1, C:4, D:∞]
第2轮: 选B(dist=1,未访问中最小)
更新D: min(∞, 1+3) = 4
dist = [A:0, B:1, C:4, D:4]
第3轮: 选C(dist=4)
更新D: min(4, 4+2) = 4(不更新)
dist = [A:0, B:1, C:4, D:4]
最终: A到各点最短距离: B=1, C=4, D=4
八、解题方法论——数据结构题的通用思路
8.1 选择数据结构的决策树
需要什么操作?
│
├─ 频繁随机访问 → 数组
├─ 频繁插入删除 → 链表
├─ 后进先出 → 栈
├─ 先进先出 → 队列
├─ 快速查找 → 哈希表 / 二叉搜索树
├─ 元素间有层次关系 → 树
└─ 元素间有多对多关系 → 图
8.2 常见题型与解题模式
模式一:双指针法(数组/链表)
- 场景:有序数组求两数之和、合并两个有序数组。
- 方法:一个指针从头(L),一个从尾(R),根据和的大小或条件移动指针。
[1, 3, 5, 7, 9] 目标和 = 10
↑L ↑R → 1+9=10 → 找到!
模式二:快慢指针法(链表)
模式三:单调栈
- 场景:找每个元素右边/左边第一个比它大/小的元素。
- 方法:维护一个栈内元素单调递增或递减的栈。
数组: [2, 1, 4, 3]
处理2: 栈空,入栈 栈: [2]
处理1: 1<2,入栈 栈: [2, 1]
处理4: 4>1,弹出1,结果1→4 栈: [2]
4>2,弹出2,结果2→4 栈: []
入栈4 栈: [4]
处理3: 3<4,入栈 栈: [4, 3]
结束: 栈中剩余元素没有更大的右边元素
九、总结——一张图串联所有知识
数据结构
│
┌──────────────────┼─────────────────┐
│ │ │
线性结构 树形结构 图结构
│ │ │
┌─────┼─────┐ 二叉树 邻接矩阵
│ │ │ B树 邻接表
数组 链表 受限结构 堆 十字链表
│ │ │
│ │ ┌──┴──┐
│ │ 栈 队列
│ │ │ │
│ │ │ 循环队列
│ │ │
│ │ ├─ 顺序栈(数组实现)
│ │ └─ 链栈(链表实现)
│ │
│ ├─ 单链表
│ ├─ 双链表
│ └─ 循环链表
│
├─ 静态数组
└─ 动态数组
核心思维:
- 没有最好的数据结构,只有最合适的 —— 根据主要的操作需求(增、删、改、查、遍历)来选择数据结构。
- 时间和空间总是在做交换 —— 哈希表用空间换时间,压缩存储用时间换空间,理解这种权衡是优化的关键。
- 理解底层才能做出正确选择 —— 知道数组为什么快(缓存友好)、链表为什么灵活(指针跳转),才能在实际工程中做出最优决策。
希望这份全面的解析能帮助你建立起清晰的数据结构知识体系。理解原理后,多加练习才能融会贯通。如果你在学习过程中有任何疑问或心得,欢迎来云栈社区与更多开发者交流探讨。
 发表于 2026-3-24 05:25:05
|
查看: 124|
回复: 0
发表于 2026-3-24 05:25:05
|
查看: 124|
回复: 0
