前些天,Karpathy的AutoResearch开源项目在社交平台上引起了广泛关注。这个项目的核心思想是构建一个可准确评估、能够自我迭代的最小化实验环境,每次只进行一小步改进,然后将剩下的迭代工作完全交给大模型,最大限度地减少人为干预。
这种模式听起来很理想,但实际效果如何?为了验证这一点,我决定利用新上手的Claude Code Opus 4.6,在一个具体且硬核的任务上试试水:优化一个带自定义掩码(Mask)的Flash Attention GPU算子。
我选择这个任务有几个原因:首先,算子性能的优劣有明确、客观的评测标准(速度快慢);其次,高性能算子开发本身门槛高、耗时久,能充分检验AI的潜力;最后,面向随机生成掩码(random custom mask)的短序列(context length < 1k)Flash Attention优化,在公开资料中相对少见,这能在一定程度上避免模型简单地“背诵”现有解决方案。
整个实验的代码仓库在此:sparse-mask-attention。
经过大约8小时的累积运行和25轮迭代,最终成果令人印象深刻。在保证计算正确性的前提下,由Opus 4.6主导优化的CUDA Kernel,在NVIDIA GeForce RTX 3080上达到了约27 TFLOPS的算力利用率,模型浮点单元利用率(MFU)高达42%。相比于PyTorch原生实现加速了4倍以上,并且性能超过了cuDNN、FlashInfer以及一个参照实现的Triton版本。
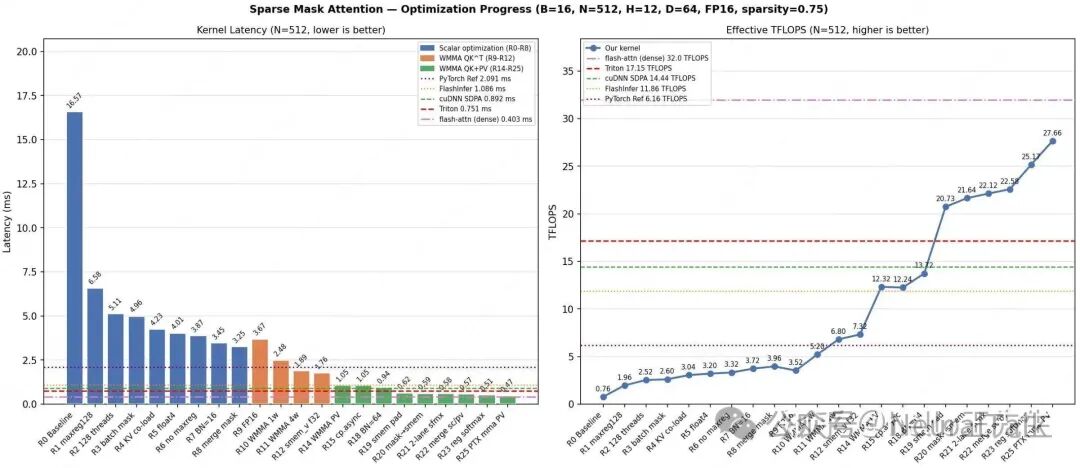
性能对比显示,自研Kernel在延迟和有效TFLOPS上均优于主流开源方案。
从AutoResearch到算子优化:如何构建自我迭代的AI智能体
AutoResearch项目为我们提供了一个极简的范本。它通常只包含几个核心文件:一个用于数据准备的prepare.py,一个允许模型任意修改的train.py,以及一份指导模型行为的program.md。
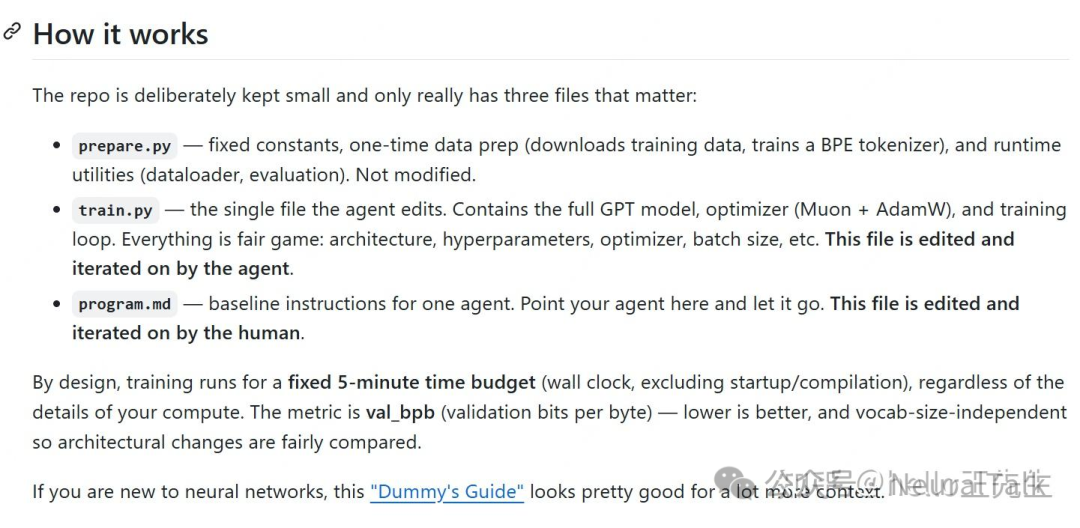
受此启发,我将类似的框架应用到了GPU算子优化任务上。我构建的仓库结构如下:

核心规则是:模型只能修改csrc/目录下的CUDA内核代码。同时,我编写了一份简短的optimization_rules.md文件,作为模型的“行动指南”。
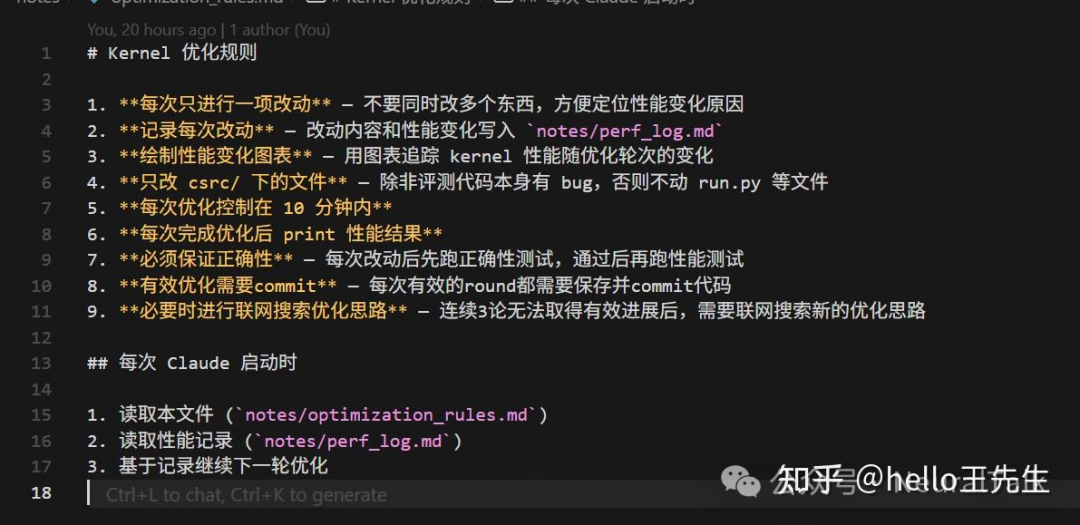
这份指南规定了优化的基本原则,例如“每次只进行一项改动”、“必须记录每次改动内容和性能变化”、“优先保证正确性”等。其作用类似于AutoResearch中的program.md,旨在让模型在一个明确的框架内进行有目的的探索。
一切准备就绪后,只需给模型一个简单的启动指令:“请阅读notes/optimization_rules.md,然后开始新一轮优化迭代。”接下来,就是见证AI“自主编程”的时刻。
迭代历程:从CUDA新手到性能调优专家
模型的优化过程并非一蹴而就,而是呈现出一个清晰的学习和探索曲线。我们可以将其分为几个主要阶段:
第一阶段:基础标量优化 (R0-R8)
初期,模型的行为很像一个正在学习CUDA编程的新手。它从最基础的FP32实现开始,逐步进行寄存器优化、线程束(Warp)协作、内存访问合并等经典优化。例如,通过批量读取掩码、向量化加载等方式,逐步将Kernel延迟从16.6 ms降低到3.2 ms左右。
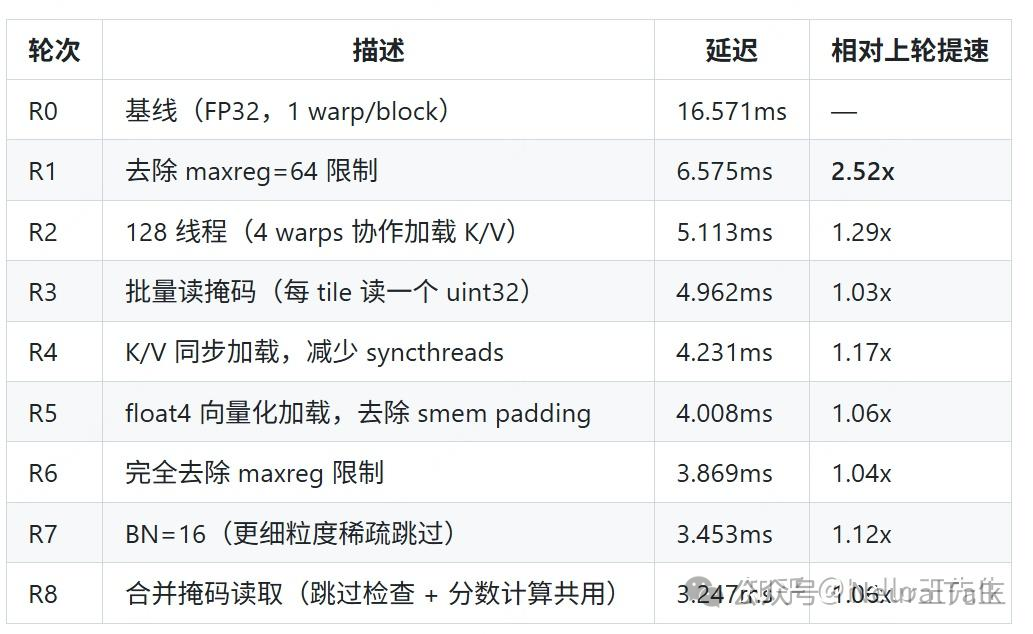
第二阶段:引入Tensor Core (R9-R13)
当被要求与Triton实现进行对比后,模型“意识”到了性能瓶颈,并开始引入更高级的硬件特性。从R9开始,它将计算精度切换到FP16,并开始使用WMMA(Warp Matrix Multiply Accumulate)指令来利用GPU的Tensor Core。这一系列操作带来了显著的性能提升。
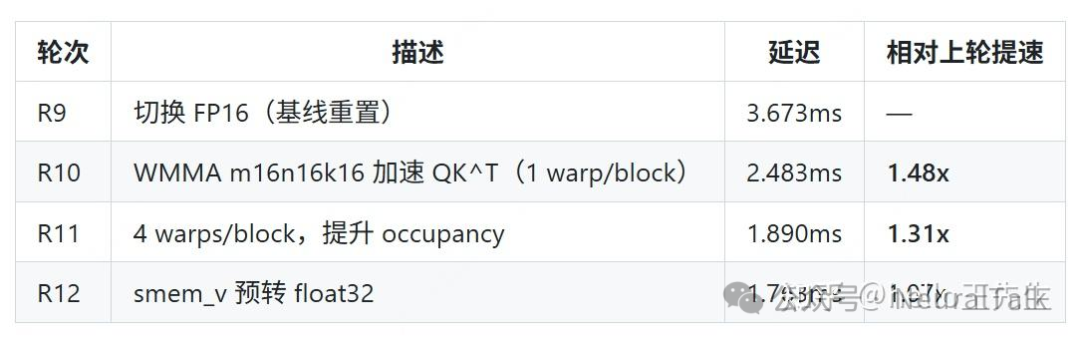
第三阶段:基于Profiler的深度调优 (R14-R25)
在此阶段,模型展现出了接近资深工程师的调优能力。它会主动运行ncu(NVIDIA Nsight Compute)对Kernel进行性能剖析,根据瓶颈报告(如内存带宽、指令延迟、占用率)制定下一步优化策略。
- 主动分析与搜索:模型会分析PTX汇编指令,并能在优化陷入瓶颈时,自主联网搜索新的优化思路(例如搜索“CUDA WMMA mma_sync pipeline optimization reduce wait stall”)。
- 精细化内存与指令优化:它实施了诸如消除共享内存Bank Conflict、预加载掩码到共享内存以减少全局内存读取、合并寄存器数组以节省寄存器资源、甚至尝试利用更底层的PTX
mma.sync指令来替代WMMA以进一步减少共享内存使用等高级技巧。
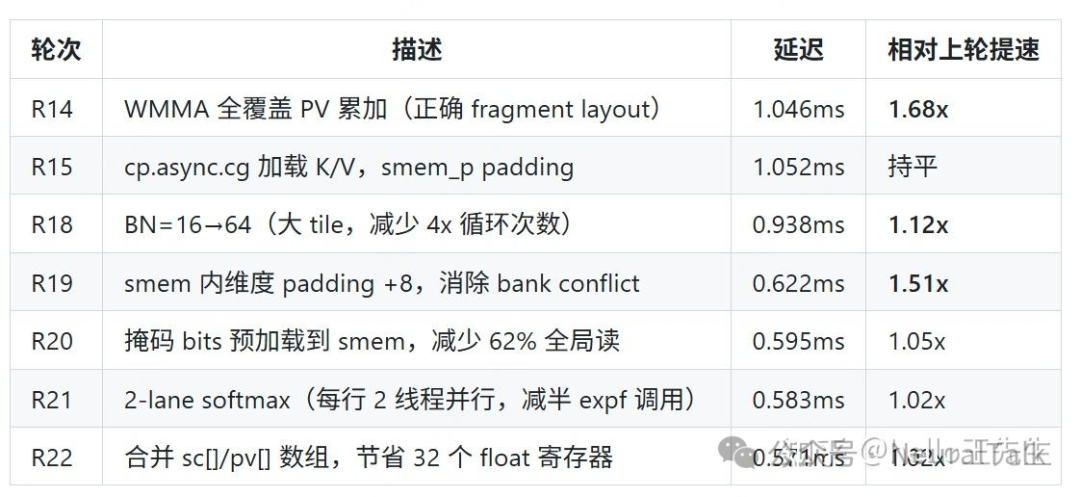
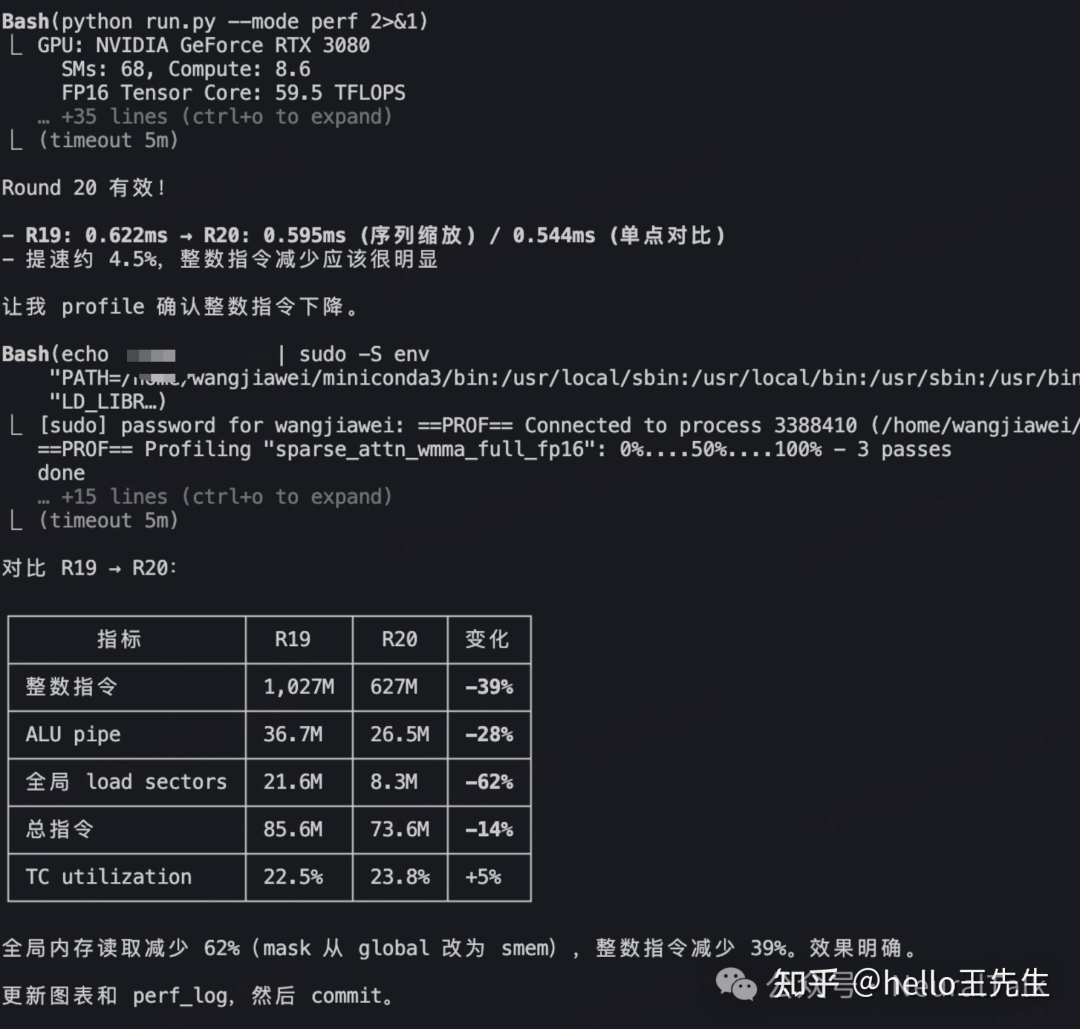
其中,R20轮次的优化效果非常典型。模型将掩码(mask)从全局内存预加载到共享内存,使得全局内存加载扇区数减少了62%,整数指令减少了39%,带来了明确的性能提升。
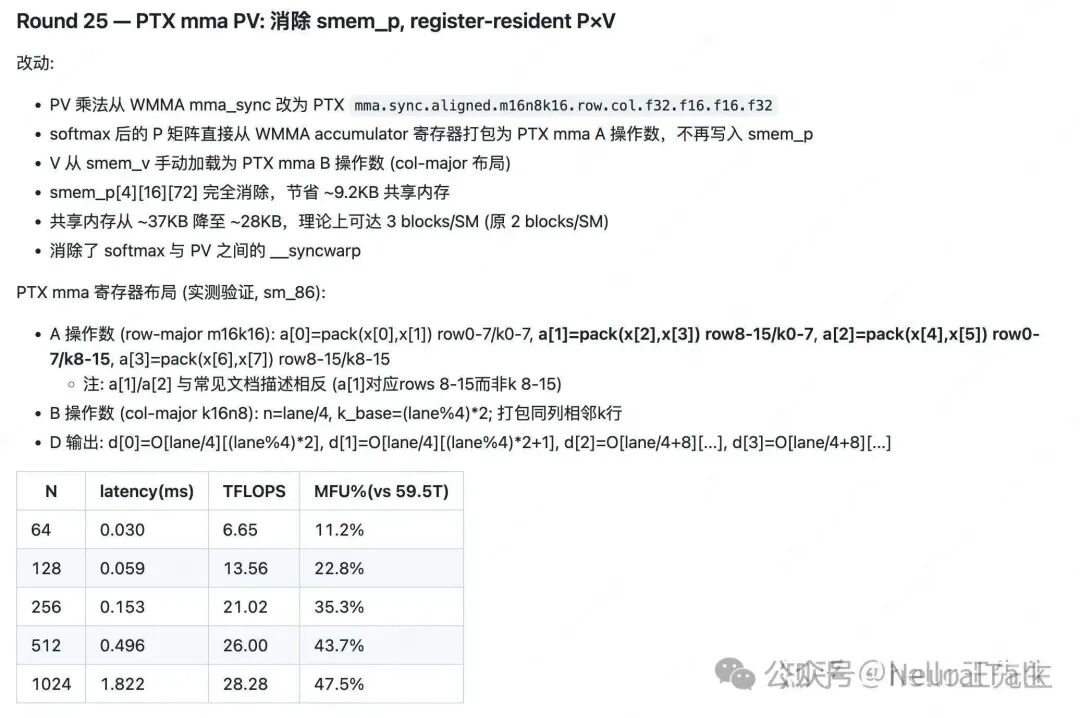
在最终轮次(R25),模型通过使用PTX mma.sync指令直接累加P*V结果,完全消除了用于存储softmax中间结果P矩阵的共享内存(smem_p),使共享内存使用量从~37KB降至~28KB,理论上允许每个流多处理器(SM)运行3个线程块(原为2个),进一步挖掘了硬件潜力。
AI生成的代码质量如何?
模型最终生成的sparse_attention.cu代码,风格非常“正规化”。这里摘取两个片段感受一下:
1. 基于掩码的快速跳过逻辑:
虽然因为测试用的掩码是随机生成而收益不大,但模型确实实现了利用__ballot_sync进行线程束内投票,以跳过全掩码行的逻辑。
// Sparse skip: check if any row in this warp has any unmasked bit
// Use smem_mask that was just written (need syncthreads after K/V load anyway)
cp_async_wait<0>();
__syncthreads();
// Ballot from smem_mask: each warp checks its BM=16 rows
{
uint32_t any_bits = 0u;
if (lane < BM && wr + lane < seq_len) {
any_bits = smem_mask[wid * BM + lane][0] | smem_mask[wid * BM + lane][1];
}
uint32_t ballot = __ballot_sync(0xffffffff, any_bits != 0u);
if (lane == 0) warp_ballots[wid] = ballot;
}
__syncwarp();
if ((warp_ballots[0] | warp_ballots[1] | warp_ballots[2] | warp_ballots[3]) == 0x0) continue;

2. 寄存器内的Softmax计算:
模型将注意力分数(QK)的缩放、掩码应用以及softmax的求最大值、求指数和等操作,都尽可能地保留在寄存器中进行,避免了昂贵的内存往返。
// Apply mask + scale in-register on fragment elements
#pragma unroll
for (int f = 0; f < NQK; f++) {
#pragma unroll
for (int i = 0; i < 8; i++) {
int fr = lane / 4 + ((i & 2) ? 8 : 0);
int fc = f * WK + (lane % 4) * 2 + wmma_col_off[i];
int gr2 = wr + fr;
bool ok = (gr2 < seq_len) && (cs + fc < seq_len) &&
((smem_mask[wid * BM + fr][fc / 32] >> (fc % 32)) & 1u);
qk_sub[f].x[i] = ok ? (qk_sub[f].x[i] * scale) : -65504.f;
}
}
// ---- In-register softmax: find max per row ----
float local_max_a = -65504.f, local_max_b = -65504.f;
#pragma unroll
for (int f = 0; f < NQK; f++) {
local_max_a = fmaxf(local_max_a, fmaxf(fmaxf(qk_sub[f].x[0], qk_sub[f].x[1]),
fmaxf(qk_sub[f].x[4], qk_sub[f].x[5])));
local_max_b = fmaxf(local_max_b, fmaxf(fmaxf(qk_sub[f].x[2], qk_sub[f].x[3]),
fmaxf(qk_sub[f].x[6], qk_sub[f].x[7])));
}
local_max_a = fmaxf(local_max_a, __shfl_xor_sync(0xffffffff, local_max_a, 1));
local_max_a = fmaxf(local_max_a, __shfl_xor_sync(0xffffffff, local_max_a, 2));
local_max_b = fmaxf(local_max_b, __shfl_xor_sync(0xffffffff, local_max_b, 1));
local_max_b = fmaxf(local_max_b, __shfl_xor_sync(0xffffffff, local_max_b, 2));

实验带来的启示与思考
这次深度体验带来了几个关键结论:
- 模型能力是关键:目前,Claude Code的Opus 4.6版本能够非常好地胜任这种复杂的、多轮次的自主迭代优化任务。切换到其他能力稍弱的模型,效率会大打折扣。
- 指引框架至关重要:AI的优化过程很像训练神经网络,也会陷入局部最优。一个设计良好的
optimization_rules.md(或program.md)就像给模型定义了损失函数和优化器,能极大提升其搜索效率和效果。AutoResearch模式的核心优势就在于“可准确评估的小步迭代”和“低成本的重启恢复”。
- 人类角色转变:在这个过程中,工程师的角色从“写代码”转变为“设计实验框架”和“定义优化规则”。你需要确保评测基准的绝对正确,为模型划定清晰的行动边界,并在必要时提供高层方向性的提示(如在瓶颈期建议对比Triton)。
- 效率的质变:对比传统模式下,一个熟练的工程师可能需要数周来学习、实现和优化一个此类算子,而AI在8小时内就达到了超越主流开源库的性能。这不仅是10倍以上的时间节省,更是将开发者的精力从繁琐的底层编码和调试中解放出来,投入到更高层次的架构与算法设计中去。
结语
这次实验强烈地印证了一点:关于大模型编程能力的讨论,再多的争论也不如亲手实践一次来得有说服力。当AI能够自主完成从性能剖析、瓶颈分析、代码实现到验证测试的全流程时,它所展现出的潜力和效率提升是颠覆性的。

对于从事高性能计算、编译器、人工智能和C++底层优化的开发者而言,现在正是积极拥抱和探索这类AI辅助研发流程的绝佳时机。无论是借鉴AutoResearch的思想,还是直接在开源实战中应用强大的代码模型,都能为我们打开一扇通往更高研发效率的大门。如果你对这类技术实践感兴趣,欢迎到云栈社区交流讨论。
 发表于 2026-3-24 06:03:47
|
查看: 291|
回复: 0
发表于 2026-3-24 06:03:47
|
查看: 291|
回复: 0
