
当大语言模型(LLM)成为各类AI应用的公共基础设施,我们越来越依赖通过云端API来调用这些强大的模型。然而,这种便捷的背后潜藏着一个现实的信任危机:你如何确认服务商真的在后台运行了他们所承诺的模型,而不是用一个更廉价、更低质的版本“偷梁换柱”?又如何保证他们报告的Token使用量是真实发生的,而非为了多收费而“注水”?
实际上,关于LLM服务“降智”的讨论在国内外多个开发者社区中已屡见不鲜。许多用户报告,在订阅服务一段时间后,模型的表现会莫名其妙地出现下滑[1,2]。同时,若服务商出于竞争策略,对特定用户群体提供差异化甚至低质量的服务[3],将进一步加剧黑盒AI服务的信任赤字。
针对这一系列问题,一项新的研究提出了一种名为IMMACULATE的审计框架。它巧妙地利用可验证计算技术,旨在证明黑盒API推理过程的正确性。借助该框架,用户可以在完全不接触模型内部信息的情况下,仅需付出约1%的额外系统开销,就能有效检测模型替换、过度量化以及Token虚报计费等违规行为。
背景:当LLM成为黑盒API服务
如今,绝大多数用户并不直接部署和运行大模型,而是通过OpenAI、Anthropic、Google等公司提供的云端API服务来获取模型能力。这种模式虽然便捷,但也带来了一个根本性的信任难题:你无法验证服务提供商是否如其宣称的那样,真实地执行了完整的模型推理。
从经济动机来看,服务商完全有理由通过各种手段降低成本或增加收入,例如:
- 模型替换(Model Substitution):用更小、更便宜的模型(比如用7B模型替代声称的70B模型)来响应请求。
- 过度量化(Aggressive Quantization):使用极低的计算精度(如INT4)来运行模型,牺牲精度以换取更快的速度和更低的硬件成本。
- Token过度计费(Token Overreporting):虚报比实际生成更多的Token使用量,从而向用户收取更高费用。
更棘手的是,这些“作弊”行为产生的结果往往在语义上仍然是正确的,只是整体质量(如创造性、逻辑性、细节丰富度)有所下降。普通用户很难单从输出文本中直接察觉异常。这也就是为什么社区中“模型变笨了”的直观感受会广泛流传。
那么,如何在不访问模型内部的情况下,验证LLM API是否被诚实执行呢?
方法概览:随机审计与可验证证明
IMMACULATE框架的核心技术基石之一是可验证计算。这项密码学技术允许服务器向客户证明其计算结果的正确性,而无需透露具体的计算过程或模型参数。然而,如果对每一次API请求都生成证明,其开销将高得无法承受。
IMMACULATE的聪明之处在于其核心思想:无需验证所有请求,只需对少量随机选取的请求进行审计,就足以威慑和检测大规模的系统性违规。
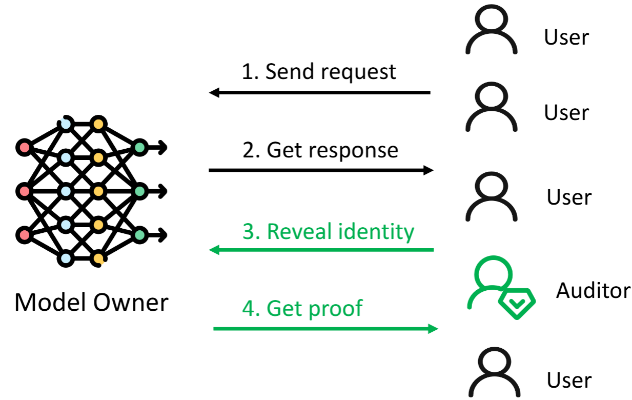
图1:IMMACULATE工作流程。审计者伪装成普通用户发送请求,并在事后要求服务端对随机选中的请求提供可验证的计算证明。
其工作流程可以概括为以下几步:
- 用户(包括伪装成普通用户的审计者)正常向LLM API发送请求。
- 服务端返回生成的文本内容及声称的Token使用量。
- 审计者事后随机选择一部分历史请求,要求服务端提供这些请求的可验证计算证明。
- 服务端为被选中的请求生成证明。
- 审计者验证证明,并根据统计指标判断服务端在整个审计周期内的执行是否可信。
这一设计基于一个简单的经济逻辑:如果服务商想通过违规行为获取可观的经济收益,就必须在足够大比例的请求上实施作弊。因此,通过对少量请求进行随机抽样审计,就能以很高的概率发现系统性违规的存在。
关键技术:Logit距离分布
将可验证计算应用于大语言模型推理,面临一个现实挑战:GPU推理的数值非确定性。即使在相同的模型和输入下,由于浮点误差、并行计算调度等因素,不同次运行产生的具体数值可能存在微小差异。
此外,LLM的推理过程混合了两种计算:连续计算(如注意力机制、MLP前馈网络)和离散决策(如从概率分布中采样下一个token)。连续计算受数值误差影响,具有非确定性;而离散决策在输入确定时,输出是确定的。在自回归生成中,前期连续计算中微小的偏差可能导致后续离散决策路径完全分叉,这使得传统的、“逐token完全复现”的验证方法几乎不可行。
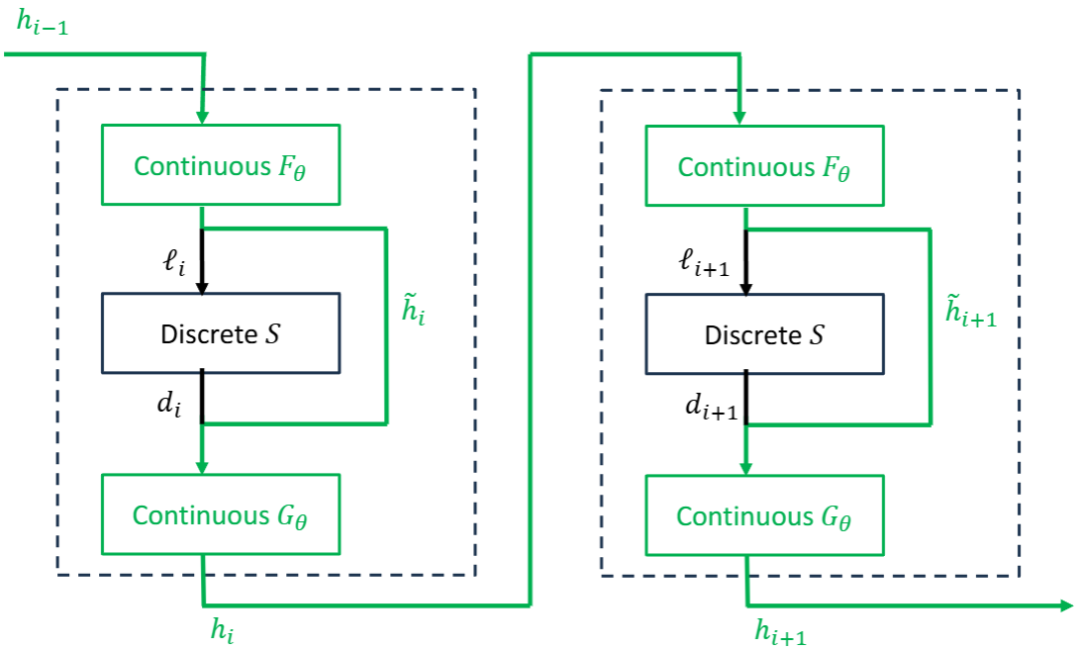
图2:LLM推理可被视为连续计算与离散决策的交错。固定离散决策序列后,可以比较连续部分输出的差异。
IMMACULATE巧妙地利用了模型的结构特性:固定离散决策路径,仅审计连续计算的偏差。具体来说,在审计时,服务端不仅需要提供最终输出文本的证明,还需要提供生成过程中每一步的“离散决策”(即实际被选中的token ID)序列。
审计者拿到这个序列后,可以在一台可信的、拥有原始模型副本的机器上,以完全相同的离散决策路径“重放”推理过程。然后,比较服务端模型与本地参考模型在每一步产生的logits向量之间的距离。大量请求积累下来,就形成了一个Logit距离分布。
核心思想在于:我们不要求每次推理的logits完全一致,而是关注实际部署模型与参考模型之间logits偏差的统计分布特征。
- 如果系统诚实运行:偏差仅来源于GPU固有的数值误差,其分布会稳定且集中在一个很小的范围内。
- 如果存在违规:例如使用了不同架构的模型或进行了过度量化,其计算输出的偏差分布会显著扩大或产生整体偏移。
通过统计LDD的尾部概率(即出现大偏差的概率),审计系统就能有效识别出异常的模型执行行为。
实验结果:高效检测与低开销
研究团队在包括LLaMA3在内的多个模型上进行了测试。实验结果表明,对于单个审计请求:
- 对模型替换攻击(如用7B模型顶替70B模型)的检测率超过90%。
- 对过度量化攻击(如使用过低精度)的检测率可达1%–10%。
在更现实的随机审计场景下,理论分析显示,仅需约3000次审计请求,就能以高概率检测到服务端的系统性违规行为。
更重要的是,IMMACULATE带来的系统开销极低:
- 在流行的vLLM推理引擎中,由于证明只在极少数被审计的请求上生成,其对系统吞吐量的影响小于1%。
- 计算证明本身的开销也仅在触发审计时产生,不影响绝大多数正常请求的响应速度。
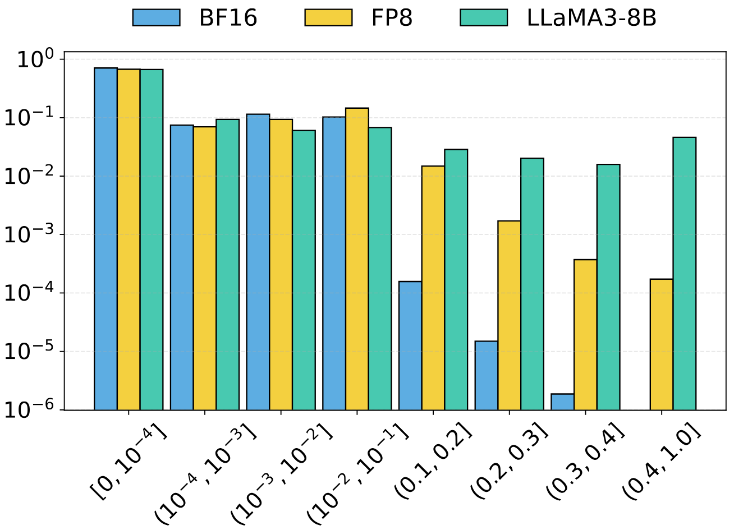
图3:LLaMA3-70B模型在不同量化精度(BF16/FP8)下的Total Variation距离分布对比。违规配置(如过度量化)会导致分布尾部出现明显差异。
这些数据证明了该框架具备现实部署的可行性,能够在不过度增加成本的前提下,为LLM API服务提供一层重要的可信保障。
总结与展望
IMMACULATE框架为黑盒LLM API的可信审计提供了一条创新且实用的路径。它通过结合随机化审计策略、可验证计算密码学技术以及新颖的Logit距离分布统计指标,实现了无需信任硬件、无需模型白盒访问的可靠验证。
这项研究揭示,大规模AI服务的透明性与可信度问题,完全可以通过轻量级、低开销的密码学与统计方法得到显著改善。随着AI即服务(AIaaS)模式的普及,如何建立有效的监督与信任机制将成为关键。类似IMMACULATE这样的工作,正是构建未来可信AI基础设施的重要基石,相关的讨论和实践也已在云栈社区等技术论坛中展开。
参考资料:
[1] https://mp.weixin.qq.com/s/cHhdltxUJ3fDka7oR8I06Q
[2] https://mp.weixin.qq.com/s/6JZrbE16k4qmF0pK-kpGRA
[3] https://www.zhihu.com/question/2009482926241382805/answer/2009814668114428352
 发表于 2026-3-24 07:11:28
|
查看: 182|
回复: 0
发表于 2026-3-24 07:11:28
|
查看: 182|
回复: 0
