机器学习与深度学习是人工智能领域的核心分支。它们之间存在着包含与被包含的关系:深度学习是机器学习的子集,更是其在模型结构与特征学习方式上的重要进阶。在处理图像、语音、自然语言等复杂任务时,深度学习往往能提供更优的解决方案。
一、基本概念与层级关系
一个常见的理解框架是,人工智能是涵盖一切让机器表现出智能行为的广义概念,而机器学习是实现人工智能的一种关键方法。深度学习,则是在机器学习范畴内,利用多层神经网络模拟人脑学习方式的特定技术路径。三者关系可用下图清晰地展示:

- 人工智能(AI):最上层的总概念,指任何能让机器模拟、延伸和拓展人类智能的技术。
- 机器学习(ML):作为人工智能的一个关键子领域,其核心在于通过数据训练模型,让系统获得从数据中学习和做出预测的能力。
- 深度学习(DL):是机器学习的一个子集,特指使用包含多层(“深度”)结构的神经网络,自动从数据中学习复杂特征的模型与方法。
二、机器学习:让计算机从数据中学习
你是否好奇,计算机是如何“学会”分辨垃圾邮件,或者预测股票走势的?这背后的核心驱动力便是机器学习。它让计算机能够通过算法自动从海量数据中挖掘规律和模式,而无需为每个具体任务编写详尽的规则。
机器学习算法种类繁多,各有所长:
- 线性回归 / 逻辑回归:用于预测数值或进行分类(如判断邮件是否为垃圾邮件)。
- 决策树 / 随机森林:基于树状结构做决策,常用于分类和回归任务,可解释性较强。
- 支持向量机 (SVM):在高维空间中寻找最佳分割面来分类数据。
- K-最近邻 (KNN):基于相似度进行预测或分类的简单算法。
- 聚类算法(如K-means):用于发现数据中的内在分组结构。
在众多机器学习算法中,神经网络(或人工神经网络) 尤为特别。它模仿人脑中神经元连接的结构,通过相互连接的节点层来处理复杂数据,擅长识别数据中深层、非线性的模式与关系。而我们常说的深度学习,正是建立在更复杂、层数更多的神经网络基础之上。
三、深度学习:从数据中自动挖掘特征
深度学习是机器学习的一个子集,它采用包含多个隐藏层的深度神经网络,来更精细地模拟复杂的认知过程。如果说传统机器学习模型可能只有一两个隐藏层,那么深度神经网络通常拥有几十、几百甚至上千个隐藏层。
正是这种“深度”结构,赋予了深度学习强大的“端到端”自动特征学习能力。它能够直接从原始数据(如图像像素、语音波形、文本字符)中,逐层抽象出从低级到高级的特征(例如,从图像的边缘到纹理,再到整个物体的轮廓),整个过程无需人工设计和干预特征提取。
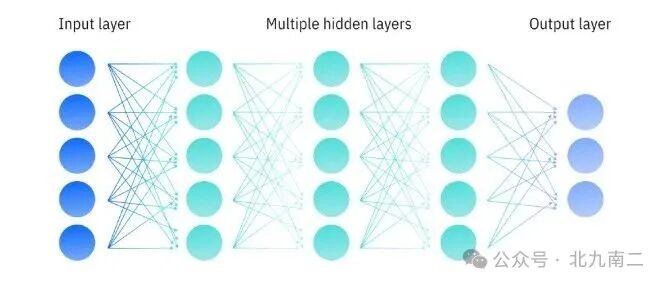
深度神经网络通过输入层、众多隐藏层和输出层的协作,能够从大量非结构化的原始数据中自动提取含义和关系。这使得它非常适合处理我们生活中的大多数复杂AI任务,例如:
- 自然语言处理 (NLP):机器翻译、智能对话、情感分析。
- 计算机视觉:人脸识别、图像分类、自动驾驶中的物体检测。
- 语音识别:将语音转换为文本。
此外,深度学习还推动了多种高级学习范式的发展:
- 半监督学习:结合少量标记数据和大量未标记数据进行训练。
- 自监督学习:模型自己从数据中构造监督信号进行学习。
- 强化学习:智能体通过与环境交互、试错并获得奖励来学习最优策略(如AlphaGo)。
- 迁移学习:将在一个任务上学到的知识,应用到另一个相关任务上,显著提升学习效率。
四、核心区别:一张表看懂机器学习与深度学习
为了更直观地对比,下图清晰地展示了机器学习与深度学习在流程上的根本差异:
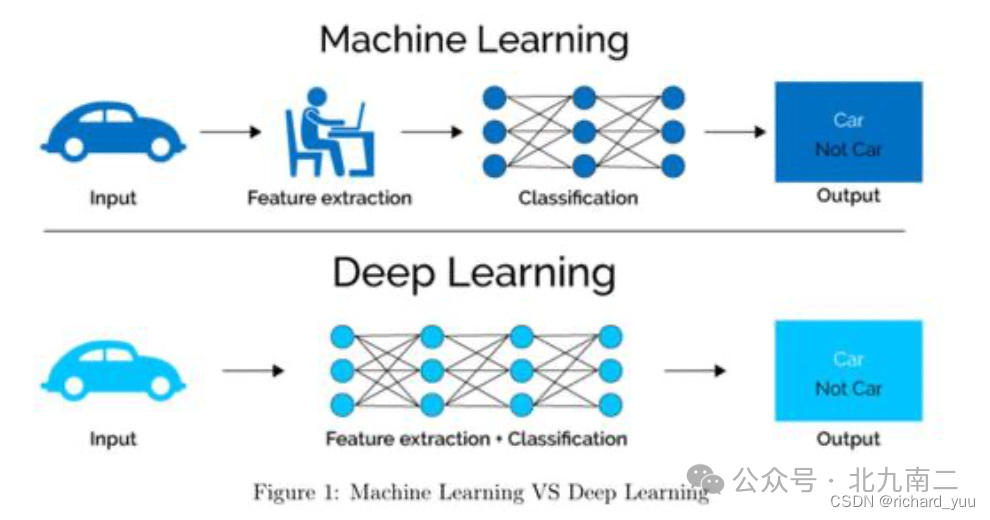
简单来说,传统机器学习流程依赖人工特征工程,而深度学习则实现了从原始数据到最终结果的端到端自动学习。下表从多个维度进行了详细对比:
| 对比维度 |
机器学习(传统 ML) |
深度学习(DL) |
| 定义 |
AI的一种实现方式,依赖人工特征设计 |
ML的子集,基于多层神经网络 |
| 模型结构 |
以「浅层模型」为主,无复杂层级结构:
- 线性模型(逻辑回归、SVM)
- 树模型(决策树、随机森林、XGBoost)
- 概率模型(贝叶斯分类器、隐马尔可夫模型) |
以「深层神经网络(DNN)」为核心,包含多层隐藏层:
- 卷积神经网络(CNN,用于图像)
- 循环神经网络(RNN/LSTM/GRU,用于序列数据)
- Transformer(用于 NLP、多模态)
- 生成对抗网络(GAN,用于生成任务) |
| 特征学习方式 |
「人工特征工程 + 模型训练」分离:需工程师手动提取特征(如文本的 TF-IDF、图像的 SIFT 特征),模型仅负责学习特征与标签的映射关系。
手动提取:人定义哪些数据重要。 |
「端到端自动特征学习」:模型通过深层网络自动从原始数据中提取多层级特征(如 CNN 的卷积层自动学习边缘→纹理→物体轮廓),无需人工干预。
自动提取:模型自动挖掘深层特征。 |
| 数据依赖 |
对数据量要求较低,支持「小样本学习」(如几百 / 几千条标注数据即可训练有效模型);对数据质量敏感,但可通过特征工程缓解噪声影响。 |
对数据量要求极高,依赖「海量标注数据」(如百万级图像、亿级文本);数据量不足时易过拟合,需通过数据增强、迁移学习缓解。 |
| 计算资源需求 |
低算力需求,CPU 即可满足训练(复杂树模型如 XGBoost 可能需要 GPU 加速,但非必需)。 |
高算力依赖,必须使用 GPU(甚至 TPU)训练:深层网络的参数规模巨大,矩阵运算量惊人,CPU 无法支撑高效训练。 |
| 适用场景 |
1. 结构化数据任务(表格数据):如信用评分、风控建模、销售预测;
2. 小样本、低复杂度任务:如垃圾邮件识别、客户分群。 |
1. 非结构化数据任务(图像、语音、文本、视频):如人脸识别、语音转文字、机器翻译;
2. 高复杂度任务:如生成式 AI(ChatGPT、Stable Diffusion)、自动驾驶感知。 |
| 可解释性 |
可解释性较强:
- 线性模型可通过系数看特征权重;
- 决策树可可视化分裂规则;
- 适合需要「可解释性合规」的场景(如金融风控)。 |
可解释性较弱(「黑箱模型」):深层网络的特征映射过程复杂,难以追溯预测结果的具体原因;需通过 SHAP、LIME 等工具辅助解释,适合对可解释性要求低的场景。 |
| 典型应用领域 |
推荐系统、数据挖掘、风险评估、商业智能分析等。 |
计算机视觉、语音识别、自然语言处理、游戏AI、药物发现等。 |
五、总结
总而言之,机器学习与深度学习的核心区别在于特征学习的方式:前者需要人工介入进行特征工程,而后者能够通过深层网络自动完成这一过程。这使得深度学习在处理图像、语音、文本等非结构化数据时展现出强大的优势。然而,这绝不意味着机器学习已经过时。在处理结构化数据、小样本任务以及对模型可解释性要求高的场景(如金融风控)中,传统机器学习算法因其高效、稳定和可解释性强,依然扮演着不可替代的角色。
作为开发者或技术爱好者,理解二者的联系与区别,有助于我们在面对不同业务问题时,选择最合适的技术工具。如果你想了解更多关于人工智能前沿技术、实践经验或参与相关讨论,欢迎来 云栈社区 与广大开发者一起交流学习。 |  发表于 2026-3-25 04:14:20
|
查看: 125|
回复: 0
发表于 2026-3-25 04:14:20
|
查看: 125|
回复: 0
