昨天处理了一个技术咨询案例,一位 Pigsty 用户反馈他的数据库出现了 XID Wraparound 故障。这个在 PostgreSQL 生态中“臭名昭著”的问题,近些年其实已经比较少见。但这次的故障原因颇为特别——竟然是因为使用了 TimescaleDB 的 Hypercore 存储引擎导致的。这是一个实验性的新存储引擎,并且已经在最近版本中被官方弃用并移除。
如果你正在使用这个新存储引擎,最好立即检查并回退到经典的 TimescaleDB 引擎与 PostgreSQL 原生表,避免数据库“原地爆炸”的风险。
Hypercore 是什么
TimescaleDB 是一个老牌的 PostgreSQL 扩展插件,也是 PG 生态中代码量最庞大的扩展之一(约20万行)。它提供了时序数据处理分析、列式存储、流式聚集、归档压缩、定时任务等一系列实用特性。
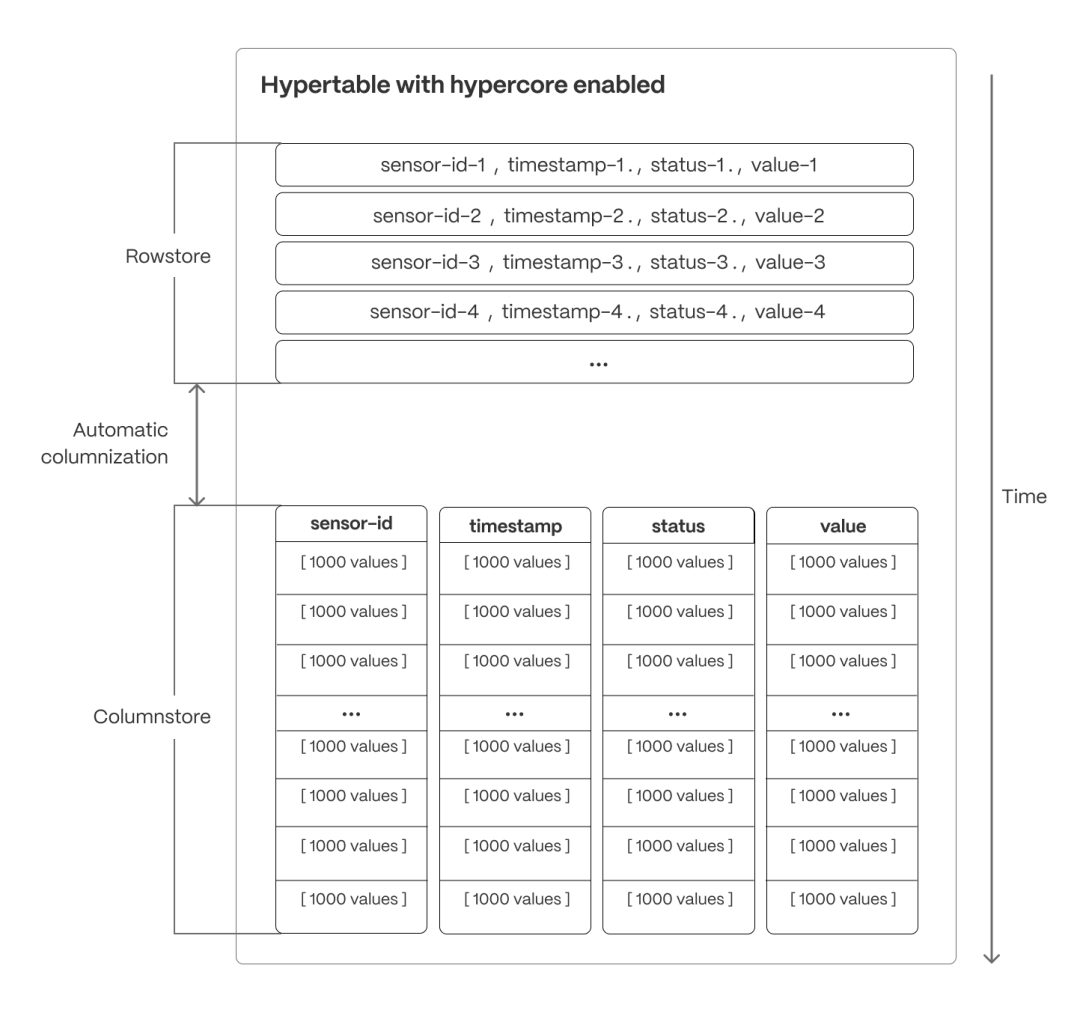
今年年初,TimescaleDB 推出了一个名为 Hypercore 的混合行列式存储引擎。它的设计目标是服务于实时分析场景,能够在行存和列存两种存储格式之间自动切换,以期同时满足高吞吐写入和快速分析查询的需求。具体来说,Hypercore 以行存形式接收最新的数据写入,保证低延迟;随着数据“冷却”不再频繁更新,系统会自动将其转换为列存格式进行压缩存储,从而加速聚合查询并节省存储空间。
CREATE TABLE crypto_ticks (
"time" TIMESTAMPTZ,
symbol TEXT,
price DOUBLE PRECISION,
day_volume NUMERIC
) WITH (
tsdb.hypertable,
tsdb.partition_column='time',
tsdb.segmentby='symbol',
tsdb.orderby='time DESC'
);
TimescaleDB 的经典引擎提出了 Hypertable 和 Chunk 的概念,这些表在底层仍是 PostgreSQL 的原生堆表,需要通过一系列函数 API 进行管理。而 Hypercore 则利用了 PostgreSQL 12 新引入的 TAM 接口,将其实现为一种新的表访问方法,并且支持为压缩数据使用 B-tree 二级索引来加速访问。从使用体验上看,它似乎更加“丝滑便利”,省去了手动管理行/列存转化、压缩/解压缩的负担。
然而,现实很骨感
当然,并非所有特性都像官方文档描述的那么美好。Hypercore 在 2025年1月23日发布的 2.18.0 版本中首次亮相,然而仅仅在 2.21.0 版本就被标记为弃用,随后在 2.22.0 版本中被直接移除,整个生命周期仅持续了半年多。
Removal of the hypercore table access method
We made the decision to deprecate the hypercore table access method (TAM) with the 2.21.0 release. Hypercore TAM was an experiment and it did not show the performance improvements we hoped for. It is removed with this release. Upgrades to 2.22.0 and higher are blocked if TAM is still in use.
Since TAM's inception in 2.18.0, we learned that btrees were not the right architecture. Recent advancements in the columnstore, such as more performant backfilling, SkipScan, adding check constraints, and faster point queries, put the columnstore close to or on par with TAM without needing to store an additional index.
We apologize for the inconvenience this action potentially causes and are here to assist you during the migration process.
当然,官方的弃用公告并没有详细解释废弃该存储引擎的具体技术原因。不过,真实用户“踩雷”的案例让我明白了 WHY。这个存储引擎没有妥善处理垃圾回收机制,直接导致了 PostgreSQL 数据库因 XID Wraparound 而宕机。

具体故障案例分析
故障的大致过程是这样的:用户遇到了 XID 回卷故障,PostgreSQL 提示还剩约 300 万个事务 ID 即将回卷,随即进入保护模式并拒绝所有写入请求。此时,数据库仅支持只读负载,业务不得不降级为只读模式。
这个案例比较幸运,数据库进程仍在运行,可以执行只读 SQL。因此,第一步是立即抽取逻辑备份。检查后发现,数据库的“年龄”(xid 使用量)在几个月内增长到了近 20 亿(用户忽略了相关告警)。进一步定位发现,是几个 TimescaleDB Chunk 表的超高年龄撑起了整个集群的年龄。再一查,这几张表使用的正是 hypercore 存储引擎,对其执行 VACUUM 命令直接报错。
要解决这个问题,理论上删除(DROP)这些表或者直接修改系统元数据即可。但尴尬之处在于,PostgreSQL 已进入保护模式,禁止任何写入操作,最多只允许执行 VACUUM FREEZE —— 这就陷入了死循环。比起风险较高的魔改系统表,最可靠、最快速的恢复方案是:直接利用 Pigsty 快速拉起一个新的 PostgreSQL 集群,将 hypercore 表的 DDL 修改为 TimescaleDB 的经典表结构,然后通过 pg_dump | psql 将数据迁移过去。最终将业务流量切换到新集群,从而解决问题。
经验与教训
总的来说,这个案例再次警示我们:在生产环境引入新特性必须慎之又慎。像 hypercore 这类实验性的存储引擎,虽然在性能或易用性上可能带来一些亮眼的改进,但一旦在质量或安全性上存在关键缺陷,所有优点都将变得毫无意义。
对于存储引擎这种处于数据库系统核心、高复杂度的底层组件,我认为再小心也不为过。因为它们往往缺乏长时间、大规模运行的社区可靠性“认证”记录,许多深层次问题只有在复杂多变的真实生产场景中才会暴露。更重要的是,存储引擎的缺陷通常更可能直接威胁到数据完整性,其杀伤力与潜在风险远大于普通应用层特性的缺陷。(类似需要高度谨慎对待的扩展还包括:OrioleDB 内核、PG TDE 扩展等)。
关于数据库版本上新的节奏
因此,经常有人问我应该选择哪个 PostgreSQL 大版本。毕竟 PG 每年都会发布一个新的大版本。我的建议是:
- 对于大多数生产环境用户:使用上一个稳定大版本是比较稳妥的选择。例如,当 PG 18 刚发布时,当下最合适的版本可能是 PG 17。
- 对于有实力、愿意尝鲜的团队:建议在第二或第三个小版本(例如 18.1,18.2)发布后再开始使用。因为此时主要的生态扩展支持基本都已到位,三到六个月的时间也足以让大部分严重 Bug 充分暴露——当然也有例外(比如 PG 14.3 才被发现的索引损坏重大 Bug)。

当然,如果你的团队实力雄厚,有信心应对各种突发问题,也可以始终紧跟最新版本,享受所有新特性。比如,去哪儿网的李海龙(帅龙)就习惯在每个 PG 大小版本发布后,立即将生产环境全线升级。
我个人会相对保守(或者说“懒”)一些,通常会等一两个小版本发布后再进行大版本升级。目前 Pigsty 的策略也基本是等待新大版本发布约半年,等 TimescaleDB、Citus 这些重量级三方扩展都完成适配后,再将其提升为默认支持的大版本。
所以,很多朋友问我 Pigsty 什么时候支持 PG 18。实际上,半年前 Beta 版出来时就已经支持了。如果你没有用到那些尚未适配 PG 18 的扩展插件,现在就可以使用。但真要上生产,我觉得最好还是再等半年。毕竟,有时候“尝鲜吃螃蟹”,是真的会“拉肚子”的。想了解更多数据库运维与架构设计的实战经验,欢迎来云栈社区交流探讨。
References
[1] 超核访问方法的弃用: https://github.com/timescale/timescaledb/releases?page=1
[2] 2.18.0: https://github.com/timescale/timescaledb/releases/tag/2.18.0
[3] 列存储: https://www.timescale.com/blog/hypercore-a-hybrid-row-storage-engine-for-real-time-analytics
 发表于 2026-3-25 04:29:02
|
查看: 134|
回复: 0
发表于 2026-3-25 04:29:02
|
查看: 134|
回复: 0
