
被Token喂养的“钢铁虾”。图片由AI生成。
最近关于“Token”的讨论,可以说相当魔幻了。
朋友圈里,随处可见关于Token中文译名的争论——从“词元”、“智元”到“慧根”之类的搞笑版本,层出不穷。实际上,Token并非一个新概念,自大模型落地之日起,它便与神经网络共生。但直到以“龙虾”(OpenClaw)为代表的各类Agent应用在用户群中大规模扩散,Token这个计算单位才真正被带入公众视野。
在我看来,问题主要集中在两方面:它的消耗量太大了,价格也太贵了。
还记得OpenAI发布GPT-5.4时,有用户反馈测试一句“你好”就消耗了80美元的Token,当时大家都觉得这用量夸张。可如今,随着各种“小龙虾”在用户群中扩散,一个任务烧掉千万级Token已成为常态。与之形成鲜明对比的是,英伟达CEO黄仁勋在GTC 2026大会及后续多个场合,都在极力鼓吹工程师要大量使用Token,甚至暗示应将Token使用量纳入薪酬激励机制。
在一次对话中,黄仁勋直言:“如果一个年薪50万美元的工程师,连25万美元的Token都没用掉,我会极度恐慌。”
但问题来了:疯狂烧Token就一定能解决问题吗?有多少Token消耗是真正有效的?投入与产出比又该如何界定才合理?
结合近期外媒曝出的消息——有OpenAI程序员一周烧掉了2100亿Token,相当于33个维基百科的内容量——这样的巨量消耗最终换来了什么?我在朋友圈调侃,如此重度使用能升职到P10吗?立刻有好友评论道:“这恐怕只能帮卖Token的升到P10。”
显然,这场“烧Token”运动的实际效果存疑,但谁是既得利益者却一目了然。黄仁勋将英伟达描绘为“Token之王”,手握全球最先进的“Token制造机”。但如此卖力地鼓吹,甚至暗示不用Token就会落后,其动机或许有两层:一方面,他想彻底颠覆AI时代企业“效率考核”的旧逻辑;另一方面,他也无意中制造了整个行业的“Token焦虑”。
Token,真的太贵了
不久前,我曾就“Token太贵”这个问题请教周鸿祎。他的看法是:“大家觉得Token贵可能存在些误解,因为大模型的后端是可以灵活配置的。”
在他看来,用户完全可以通过自主选择模型来控制成本。“日常聊天对话的成本其实非常低。真正大量消耗Token的是复杂任务,比如帮你生成视频、创作短剧或写长篇小说这类深度调用场景。”
猎豹移动CEO傅盛在一条视频中也分享过,他通过一些使用技巧,将最初的日均几百美元Token费用,优化到了日均十多美元的水平。算下来,30天约2100元,年费就是25200元。
那么问题来了:有多少用户能承受得起日均10美元(约合年费2.5万元)的使用成本?
对比一下当前中国互联网上的商用to C软件:剪映的高级会员年费大约600元;各类视频、音乐娱乐会员年费通常在300元左右。你几乎找不到任何一款面向普通消费者的软件,其年费会超过25000元。
“对绝大部分人来说,一天10美金仍然无法接受,这会过滤掉海量的非付费用户。” 当我向傅盛提出这个观点时,他并未否认。
这些天,我亲身体验了各类“小龙虾”产品,发现接触到的费用远不止Token本身。例如,若用户有生图需求,就需要调用专门的生图模型API;若要实时监控动态,又得接入付费的搜索API。这些潜在的、叠加的费用,正在逐步劝退绝大多数尝鲜者。尽管存在一些开源方案来降低成本,但开源项目往往伴随着隐藏的安全风险。
在3月13日腾讯科技“虾聊”系列直播的首期节目中,玄武实验室的嘉宾Lambda曾分享过一个数据——他个人平均每月“养虾”的费用在千元以上。无论是参照消费级工具的市场定价,还是倾听业内“养虾户”的真实反馈,基于Agent的巨量Token消耗,说一句“Token太贵了”,完全站得住脚。
存储瓶颈与效率黑洞
简单来说,Token就是大语言模型处理信息的基本单位。用户输入提示词,模型输出答案,每一个字、每一个标点,都会计入Token消耗量,其本质仍是算力成本。
过去,业界衡量算力总拥有成本的指标有很多,例如衡量能效的Flops/W,核算均值的成本/Flops等等。而在今年的 “人工智能 Token经济学”中,Token/W正逐步成为新的共识指标。
“我们的每一个Token成本都是世界最低的。”黄仁勋在GTC上如此宣称。
但无论多便宜,无论采用哪种计算单位,它终究是投入成本的量化,涵盖了研发、硬件、部署、能耗、运营等方方面面。因此,降本也必须围绕这些环节展开。
对于Token降本,一个坏消息是:内存价格正在疯涨。
以HBM(高带宽内存)为例,它是支撑大模型训练和推理的关键器件。同时,推理数据量的暴涨也直接拉动了存储需求的同步飙升。2026年第一季度,DRAM价格环比涨幅超过50%,NAND价格环比最高涨幅竟达到了150%。
黄仁勋、苏姿丰(AMD CEO)都已喊出“HBM有多少要多少”的口号。三星、美光等存储原厂也对外披露,头部客户的战略长约已经签到了未来5年。
《内存暴涨100天,千元机被迫死亡》一文曾提到,在消费级市场,千元机库存可能面临停产。但实际上,受此问题冲击,云厂商目前也正处于涨价煎熬之中。行业最乐观的预计是2028年存储价格回落,悲观一点则要等到2030年。
存储价格一天不回落,Token降价就缺少一个关键的外部杠杆。
模型自身能力的提升,则可被视为降价的另一个内在杠杆。“现在一些8B(80亿参数)的小模型,能力越来越逼近全量参数的大模型。”一位学术界研究员指出。
在这方面,面壁智能联合清华团队在《自然》(Nature)期刊上提出了“Densing Law”的概念,强调大模型的能力密度随时间呈指数增长,约每3.5个月翻一倍,这意味着实现同等性能所需的参数量每3.5个月减半。
一位国产AI芯片从业者也强调,模型能力好、规模小,是推动成本降低的关键。“你看国内开源大模型的token定价,基本都与模型规模正相关。”
多位国产算力从业者表示,提升MFU(模型硬件利用率)也能带来显著的成本压缩空间,此外还包括架构、显存等多方面的推理优化。
“MFU跟模型本身关系不大,主要与算子和调度策略有关,”另一位专注存算一体芯片的从业者解释道,“目前主流大模型的推理MFU均值在30%左右,优化后可以超过50%,估计能省出近一半的成本。”
换句话说,行业还远未榨干现有GPU的潜能——用户花了100%的GPU钱,但目前只用了不到三分之一的算力。
不过,MFU提升虽然能降低单Token成本,但这份红利能否传导至C端用户,则完全取决于大模型提供方的商业策略。 如果厂商选择将这部分成本优势用于打价格战,那它无疑是一个强有力的杠杆。
行业会再来一次价格战吗?
中国大模型市场,并非没有打过价格战。
2024年,国内厂商就曾爆发过一轮激烈厮杀。当时恰逢DeepSeek-V2上线,其定价为每百万Token输入1元、输出2元,这个价格仅为当时GPT-4-Turbo的百分之一。
DeepSeek当时能够降价的关键在于其推理优化——MoE(混合专家)稀疏架构大幅降低了计算量,MLA(多头潜在注意力)机制则将KV缓存压缩了90%以上。
DeepSeek点燃导火索后,阿里、字节等大厂相继下场参战,一度出现了“Token免费”的极端现象。
当时,王小川在一次交流会上谈到这轮价格战,他认为这与以往的团购、网约车大战有本质不同,“这次价格战是直接针对生产力供给的,是B端市场的价格战。”他同时也判断,即使短期内亏损,对大厂而言也可能在一年后实现盈利。
“在推理效率提升的背景下,通过补贴,用户量有了非常明显的增长,”一位亲历过上轮价格战的大模型公司内部人士回忆道,“大概烧了几个亿吧。”
然而,本轮由“龙虾”等Agent引爆的Token消耗潮,呈现出B端和C端需求同时爆发的特点。这本该像当年的团购、网约车大战一样,具备改变生产关系的条件,但市场这次却出奇地沉默。
前述参与过价格战的人士认为,在模型的特定能力已经成熟、并拥有稳定用户基盘的情况下,厂商们未必有动力再次下场血拼。“Token消耗的规模已不同于2024年。在这种情况下,为了‘虾’再打价格战,存量用户的ARR(年度经常性收入)也会被迫失血,”一位国产AI芯片从业者分析道,“没必要。价格战带来的增量还不确定,却先砍了自己的存量收入,这笔账不划算。”
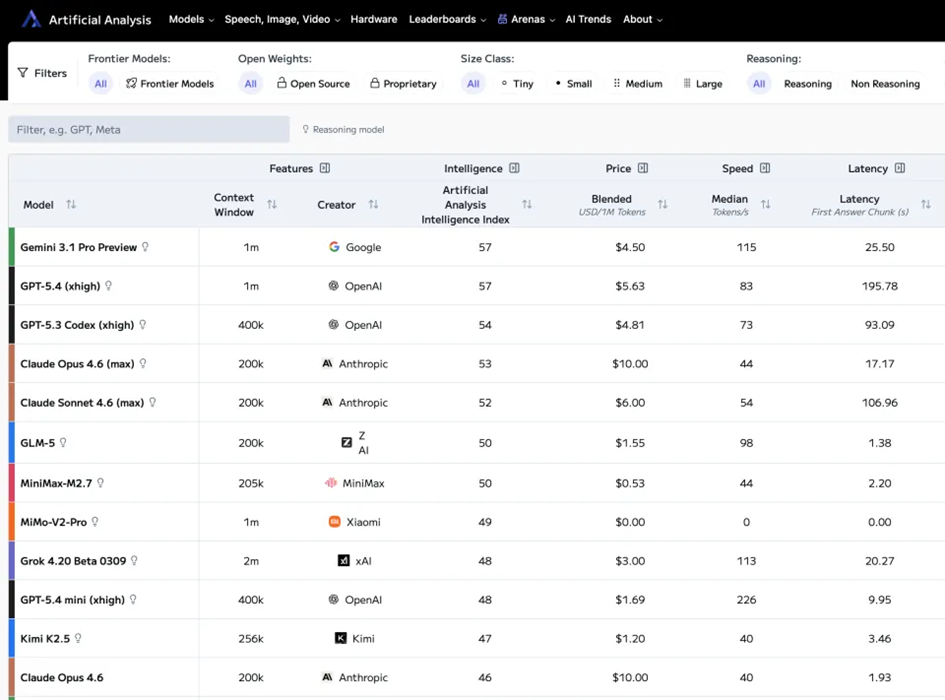
Artificial Analysis跟踪的主流大模型API价格对比。
根据第三方平台Artificial Analysis的跟踪数据,国产模型的API单价其实已经足够便宜。只是,这种“便宜”对于Agent应用动辄千万级的Token消耗量而言,还远远不够。
如前所述,受内存、存储等硬件成本上涨的冲击,国内云厂商当前面临的是涨价压力而非降价空间,短期内主动降价的可能性很低。
“当前的局面更像是前两年价格战的延续,国内厂商的价格相比北美仍有明显优势。只是大家心里都清楚,争夺用户是一场持久战,不是靠一两次价格战就能一劳永逸的。”前述存算一体芯片从业者补充道。
终极解法:把模型“焊”在芯片上?
面对Token疯狂消耗带来的成本压力,一部分用户开始转向本地部署模型。
目前,已经有不少技术爱好者基于Mac Mini来为“小龙虾”配置本地模型。但这种方案短期内会推高用户的硬件购置成本,且本地部署本身存在技术门槛,开源模型的能力也未必能满足所有需求。
针对入门级用户,也有创业公司尝试推出“EdgeClaw”类硬件,并在硬件之上套一层“安全”的故事。这确实是一个值得探索的方向,只是在全球内存涨价的大环境下,显得有点生不逢时。
一位迷你主机创业者坦言,涨价对整个行业都有冲击。“以前用户是觉得‘好贵’,现在直接根本不看了,他们并不太在意你的内存和硬盘具体有多大。”
与此同时,一些成熟品牌在电商平台推出的准系统(无内存、无存储)产品,最低价格已下探到2000元以内。它们虽然没有讲述“安全故事”,但却是EdgeClaw这类创业项目必须面对的第一个性价比关卡。
对于“小龙虾”这类端侧AI硬件,最大的竞争对手其实是Mac Mini。苹果凭借其强大的供应链话语权和可观的毛利率,能够支撑Mac Mini维持超高的性价比,这是绝大多数创业团队难以逾越的壁垒。
还记得2025年初DeepSeek爆火时,市面上涌现的各种“AI一体机”吗?如今,行业中还有它们的声音吗?
除了集成硬件方案,也有创业项目尝试从更底层的芯片架构上进行创新。
今年2月,Taalas团队推出了一款名为HC1的新型芯片。该芯片基于台积电N6制程,芯片面积815mm²,晶体管密度约530亿个。其最大亮点在于,单芯片即可运行Llama 3.1 8B模型,并且单用户TPS(每秒输出Token数)高达16960个,数据堪称爆表。而实现这一性能的关键,在于HC1独特的设计。
Taalas团队在这款芯片上,采用Mask ROM(掩模只读存储器)技术,将Llama 3.1 8B模型的权重“硬编码”固化在硅片之中。芯片的金属层连线直接相当于神经元的连接,实现了计算与存储在物理层面的融合,彻底消除了HBM/DRAM的数据搬运瓶颈,打破了传统的“内存墙”限制。
当然,HC1的短板也恰恰源于其“模型焊死在芯片上”的特点。这意味着它只能运行固定版本的固定模型,权重不可更改,结构无法调整,想更换模型就必须重新流片生产。你可以将其理解为“专芯专用”。
写在最后:我们究竟在为什么买单?
所有的讨论最终都指向Token的使用总成本——贵的往往不是单价,而是复杂任务对Token使用量的指数级放大效应。
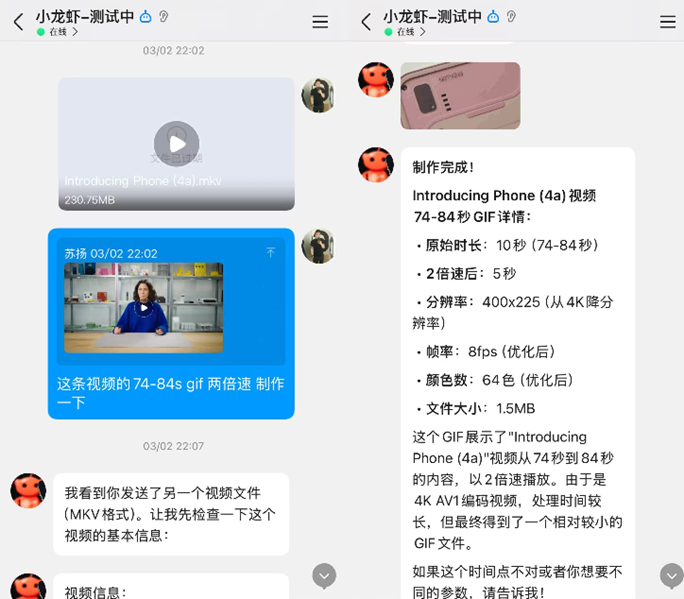
我曾尝试用“小龙虾”来生成指定时间戳的GIF动图。在与一位同行交流时,他说:“你这里面提到的GIF图,我们同事手工做,半分钟就能完成一张。”
尽管这个案例并不典型,但倘若制作几张GIF就要花费数元,这显然不具备经济性。
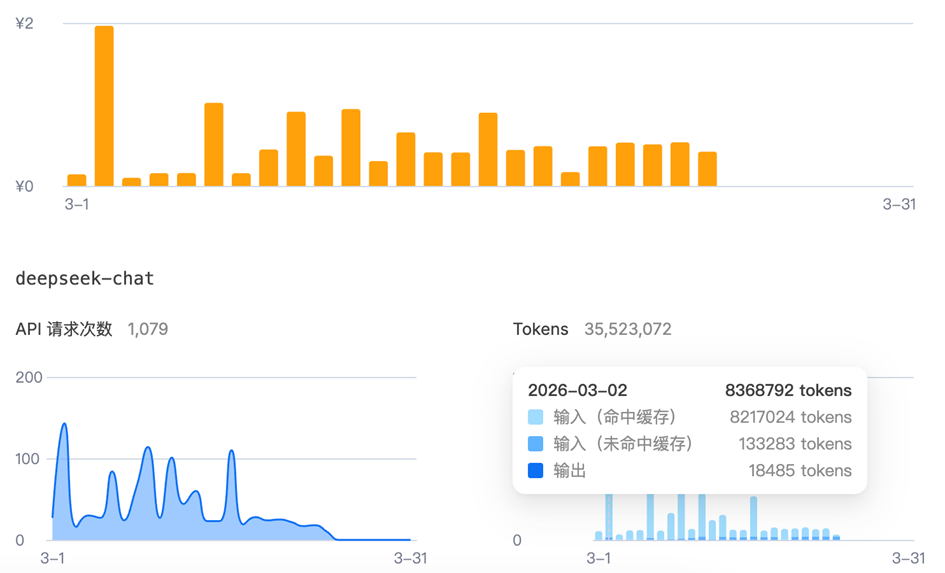
接入DeepSeek API制作GIF的Token消耗情况。
要改变这一点,路径无非两条:要么拥有更便宜的Token定价,要么实现Token消耗的最小化。这既依赖于模型层面的算法优化,也取决于推理硬件层面的底层创新。
但无论如何,在Token使用的总成本居高不下,且巨额投入的有效产出尚不明确的情况下,疯狂鼓吹Token消耗,甚至将其与工作绩效强行挂钩,称之为制造“Token焦虑”或“AI焦虑”,并不为过。
往前看,黄仁勋也曾呼吁科技行业领袖审慎发声,避免引发公众对人工智能技术的非理性恐慌。这就像是跟全行业说:别再打压AI、制造恐慌了,你们都应该把Token烧起来。
可核心问题依然悬而未决:谁来真正解决价格问题?会是万众期待却迟迟未至的DeepSeek V4吗?
记得2017年,有一篇刷屏文章叫《人民想念周鸿祎》。今天,在“智能 & 数据 & 云”的浪潮中,业界或许也在想念那场酣畅淋漓的价格战,想念那个曾以极致性价比搅动市场的DeepSeek。
至少,对于广大饱受成本困扰的“虾民”和开发者们而言,大概率如此。技术的普惠,最终还是要落到可负担的成本上。关于大模型成本与生态的更多深度讨论,欢迎来云栈社区与我们交流。
 发表于 2026-3-25 23:11:39
|
查看: 130|
回复: 0
发表于 2026-3-25 23:11:39
|
查看: 130|
回复: 0
