BogusControlFlow(虚假控制流,简称BCF)是一种从OLLVM(Obfuscator-LLVM)项目继承下来的经典代码混淆技术。它的核心思想很简单:针对一个基本块(basic block),在其前方创建一个内容相同但永远不会被执行到的克隆块,并在克隆块中加入一些垃圾指令来干扰反编译器的分析。
具体实现细节可以参考 OLLVM 的官方文档:https://github.com/obfuscator-llvm/obfuscator/wiki/Bogus-control-flow
本文主要基于 Polaris-Obfuscator 中该Pass的源码进行分析:
https://github.com/za233/Polaris-Obfuscator/blob/main/src/llvm/lib/Transforms/Obfuscation/BogusControlFlow.cpp
下面我们来逐函数解析其实现原理。
1. 克隆基本块 (cloneAlterBasicBlock)
BasicBlock *BogusControlFlow::cloneAlterBasicBlock(BasicBlock *BB) {
ValueToValueMapTy VMap;
BasicBlock *CBB = CloneBasicBlock(BB, VMap, "cloneBB", BB->getParent());
BasicBlock::iterator Iter = BB->begin();
for (Instruction &I : *CBB) {
for (unsigned i = 0; i < I.getNumOperands(); i++) {
Value *V = MapValue(I.getOperand(i), VMap);
if (V) {
I.setOperand(i, V);
}
}
SmallVector<std::pair<unsigned, MDNode *>, 4> MDs;
I.getAllMetadata(MDs);
for (std::pair<unsigned, MDNode *> pair : MDs) {
MDNode *MD = MapMetadata(pair.second, VMap);
if (MD) {
I.setMetadata(pair.first, MD);
}
}
I.setDebugLoc(Iter->getDebugLoc());
Iter++;
}
return CBB;
}
这个函数负责克隆一个基本块,并进行了相应的变量重命名以及元数据(metadata)的克隆。需要注意的是,此时克隆出来的块并未被修改或添加任何垃圾代码。
2. 拆分基本块
/* 将函数中的每个基本块按每 Size 条指令拆分成多个较小的块 */
void BogusControlFlow::splitBasicBlock(Function &F, unsigned Size) {
std::vector<Instruction *> SplitPoints;
for (BasicBlock &BB : F) {
unsigned Idx = 0;
for (auto Iter = BB.getFirstInsertionPt(); Iter != BB.end(); Iter++) {
Instruction &I = *Iter;
if (I.isTerminator()) {
continue;
}
if (Idx % Size == Size - 1) {
SplitPoints.push_back(&I);
}
Idx = (Idx + 1) % Size;
}
}
for (Instruction *I : SplitPoints) {
BasicBlock *BB = I->getParent();
BB->splitBasicBlock(I);
}
}
此函数的作用是将函数中每个较大的基本块,按照每 Size 条指令为单位,拆分成更小的块。这样做的目的是增加基本块的数量,为后续插入更多不透明谓词(opaque predicate)创造条件。
3. process 函数详解
process 函数是整个 Pass 的核心。首先,它在函数的入口处创建了两个变量 Var 和 Var0。
IRBuilder<> IRB(&*F.getEntryBlock().getFirstInsertionPt());
Value *Var = IRB.CreateAlloca(IRB.getInt64Ty());
Value *Var0 = IRB.CreateAlloca(IRB.getInt64Ty());
紧接着,生成了两个随机常量 Mod 和 X:
- $Mod = 0x100000000 - rand32()$
- $X = randPrime() \bmod Mod$
uint64_t Mod = 0x100000000 - getRand32();
// X is just a random prime % Mod
uint64_t X =
primes[getRandomNumber() % (sizeof(primes) / sizeof(primes[0]))] % Mod;
然后,将 Var 和 Var0 初始化为相同的值 X:
// Both Var and Var0 are set to X at the beginning of the function.
IRB.CreateStore(IRB.getInt64(X), Var);
IRB.CreateStore(IRB.getInt64(X), Var0);
接下来的部分是整个混淆算法的关键。我们先贴出代码,再进行分析:
std::vector<BasicBlock *> BBs;
for (BasicBlock &BB : F) {
// At the end of each basic block
IRB.SetInsertPoint(BB.getTerminator());
// a*x - b = x (mod m)
// (a - 1) * x = b (mod m)
uint64_t B = getRand32() % Mod;
uint64_t Inv = getInverse(X, Mod);
uint64_t A = ((B * Inv) % Mod + 1) % Mod;
Value *V = IRB.CreateLoad(IRB.getInt64Ty(), Var0);
IRB.CreateStore(
IRB.CreateURem(
IRB.CreateSub(IRB.CreateURem(IRB.CreateMul(IRB.getInt64(A), V),
IRB.getInt64(Mod)),
IRB.getInt64(B)),
IRB.getInt64(Mod)),
Var0);
BBs.push_back(&BB);
}
我们先来拆解生成的 IR 指令到底是什么:
%v = load i64, ptr %Var0
%mul = mul i64 A, %v
%rem1 = urem i64 %mul, Mod
%sub = sub i64 %rem1, B
%rem2 = urem i64 %sub, Mod
store i64 %rem2, ptr %Var
转换成高级语言,其计算公式为:
Var0 = ((A * Var0) % Mod - B) % Mod
这个公式究竟在计算什么?回顾生成 A 和 B 的步骤:
- $B = rand32() \bmod Mod$
- $A = ((B * Inv(X, Mod)) \bmod Mod + 1) \bmod Mod$
这两个经过精心构造的变量 A 和 B 满足以下关系:
$(A - 1) * X = B \bmod Mod$
其中,X 是任意一个小于 Mod 的数。将这个公式稍作变形,可得:
$A * X = (X + B) \bmod Mod$
将这个关系式代入到 Var0 的更新公式中,我们可以一步步推导:
Var0 = ((A * Var0) % Mod - B) % Mod
= (((Var0 + B) % Mod) - B) % Mod
= Var0 % Mod
= Var0

所以,实际上 Var0 的值永远不会改变,始终等于其初始值 X。上面那套复杂的计算,目的仅仅是让编译器和反编译器难以对其进行优化识别。
注意:此处实现存在一个潜在的 Bug。 上述推导在数学模运算下是正确的,但 IR 中使用的是无符号减法 (sub i64) 和无符号取模 (urem i64)。当 (A * X) % Mod < B 时,sub 指令会发生无符号下溢(underflow),结果会回绕到 $2^{64}$ 附近的一个大数,导致后续的 urem 操作不再等价于数学上的模运算。例如,取 Mod=11, X=3, B=8,数学上 $(-8) \bmod 11 = 3$,但在 uint64 运算下 0 - 8 = 2^{64} - 8,而 $(2^{64} - 8) \bmod 11 = 8 \neq 3$。这会导致不透明谓词不再恒为真,可能使程序陷入死循环。
接下来就是注入克隆块和不透明谓词的具体操作了:
for (BasicBlock *BB : BBs) {
if (isa<InvokeInst>(BB->getTerminator()) || BB->isEHPad() ||
BB->isEntryBlock()) {
continue;
}
BasicBlock *BodyBB =
BB->splitBasicBlock(BB->getFirstNonPHIOrDbgOrLifetime(), "bodyBB");
BasicBlock *TailBB =
BodyBB->splitBasicBlock(BodyBB->getTerminator(), "endBB");
BasicBlock *CloneBB = cloneAlterBasicBlock(BodyBB);
BB->getTerminator()->eraseFromParent();
BodyBB->getTerminator()->eraseFromParent();
CloneBB->getTerminator()->eraseFromParent();
IRB.SetInsertPoint(BB);
if (getRandomNumber() % 2) {
Value *Cond = IRB.CreateICmpEQ(IRB.CreateLoad(IRB.getInt64Ty(), Var),
IRB.CreateLoad(IRB.getInt64Ty(), Var0));
IRB.CreateCondBr(Cond, BodyBB, CloneBB);
} else {
Value *Cond = IRB.CreateICmpNE(IRB.CreateLoad(IRB.getInt64Ty(), Var),
IRB.CreateLoad(IRB.getInt64Ty(), Var0));
IRB.CreateCondBr(Cond, CloneBB, BodyBB);
}
IRB.SetInsertPoint(BodyBB);
if (getRandomNumber() % 2) {
Value *Cond = IRB.CreateICmpEQ(IRB.CreateLoad(IRB.getInt64Ty(), Var),
IRB.CreateLoad(IRB.getInt64Ty(), Var0));
IRB.CreateCondBr(Cond, TailBB, CloneBB);
} else {
Value *Cond = IRB.CreateICmpNE(IRB.CreateLoad(IRB.getInt64Ty(), Var),
IRB.CreateLoad(IRB.getInt64Ty(), Var0));
IRB.CreateCondBr(Cond, CloneBB, TailBB);
}
IRB.SetInsertPoint(CloneBB);
IRB.CreateBr(BodyBB);
}
具体的控制流图(CFG)变换有些复杂,但变换后的结构可以参考下图:
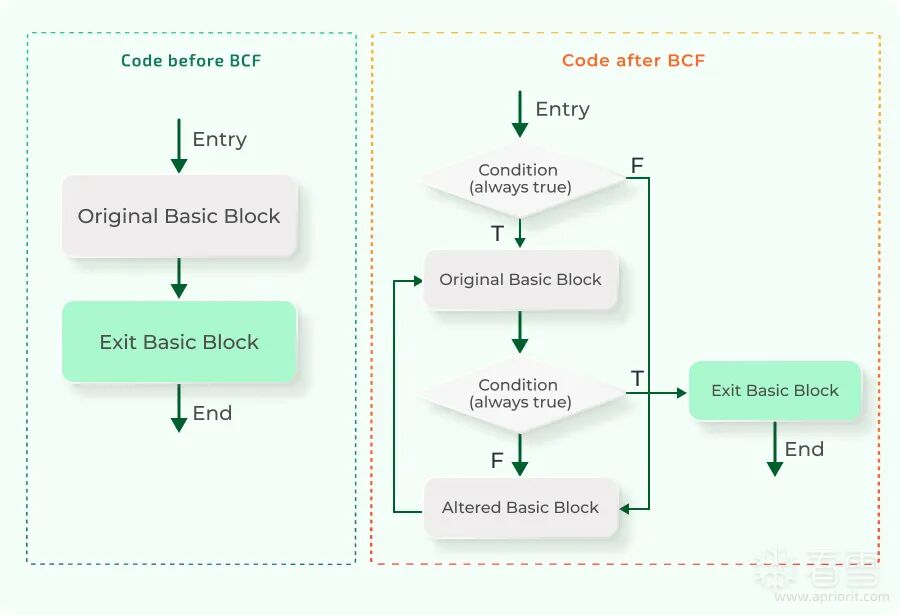
(图片来源: https://www.apriorit.com/dev-blog/obfuscating-code-to-secure-android-apps)
不过,反混淆的核心始终在于识别并消除不透明谓词。只要能通过优化将谓词判断化简为恒真或恒假,反编译器自然就会将死代码块(dead block)剪枝掉。
BogusControlFlow2 分析
在 Polaris-Obfuscator 源码中,实际上存在两个 BogusControlFlow Pass:BogusControlFlow 和 BogusControlFlow2。我们刚才分析的是较为复杂的新版本,而 BogusControlFlow2 则是一个更为简单、经典的版本(早期 OLLVM 使用的便是此类)。
Value *createBogusCmp(BasicBlock *insertAfter) {
// if((y < 10 || x * (x + 1) % 2 == 0))
Module *M = insertAfter->getModule();
LLVMContext &context = M->getContext();
GlobalVariable *xptr = new GlobalVariable(
*M, Type::getInt32Ty(context), false, GlobalValue::CommonLinkage,
ConstantInt::get(Type::getInt32Ty(context), 0), "x");
GlobalVariable *yptr = new GlobalVariable(
*M, Type::getInt32Ty(context), false, GlobalValue::CommonLinkage,
ConstantInt::get(Type::getInt32Ty(context), 0), "y");
IRBuilder<> builder(context);
builder.SetInsertPoint(insertAfter);
LoadInst *x = builder.CreateLoad(Type::getInt32Ty(context), xptr);
LoadInst *y = builder.CreateLoad(Type::getInt32Ty(context), yptr);
Value *cond1 =
builder.CreateICmpSLT(y, ConstantInt::get(Type::getInt32Ty(context), 10));
Value *op1 =
builder.CreateAdd(x, ConstantInt::get(Type::getInt32Ty(context), 1));
Value *op2 = builder.CreateMul(op1, x);
Value *op3 =
builder.CreateURem(op2, ConstantInt::get(Type::getInt32Ty(context), 2));
Value *cond2 =
builder.CreateICmpEQ(op3, ConstantInt::get(Type::getInt32Ty(context), 0));
return BinaryOperator::CreateOr(cond1, cond2, "", insertAfter);
}
这个版本生成的不透明谓词 if((y < 10 || x * (x + 1) % 2 == 0)) 明显简单许多,不涉及模逆运算。有趣的是,在 Pipeline.cpp 中,实际被注册为 Pass 的是 BogusControlFlow2,而我们之前分析的那个更复杂的 BogusControlFlow 反而没有被使用。
else if (pass == "bcf") {
FunctionPassManager FPM;
FPM.addPass(BogusControlFlow2());
MPM.addPass(createModuleToFunctionPassAdaptor(std::move(FPM)));
}
混淆效果示例
对一个由 Csmith 生成的测试程序进行 BCF 混淆后,得到的代码片段如下(注意,这里使用的仍是简单的 BogusControlFlow2):
if (iVar4 == 0) {
if (y.12 < 10 || ((x.11 + 1) * x.11 & 1U) == 0) goto LAB_001012af;
do {
local_28->f0 = 1;
LAB_001012af:
local_28->f0 = 1;
} while (9 < y.14 && ((x.13 + 1) * x.13 & 1U) != 0);
}
if (y.16 < 10 || ((x.15 + 1) * x.15 & 1U) == 0) goto LAB_0010132a;
反混淆方案原型设计
反混淆的核心在于识别并消除不透明谓词。我们可以将流程设计为以下几步:
- 收集(Collect):利用基于数据依赖图(DDG)的后向切片(backward slicing),收集所有影响分支判断条件(guard)的指令。
- 合并(Merge,可选):有时一个复杂的不透明谓词在编译后可能被拆分成多个独立条件进行判断,需要将它们合并。在测试样本中暂未遇到此情况,可跳过。
- 求解(Solve):使用符号执行对收集到的谓词条件进行求解,得到优化后的判断结果。对于 BogusControlFlow,结果应为恒真(True)或恒假(False)。
- 修补(Patch):对二进制文件进行打补丁,消除不透明谓词对反编译器的影响。
但在具体实现时,每一步都会面临挑战:
- 收集:需要精确判定哪些代码结构需要收集。对于间接调用(IndirectCall),遍历所有调用点即可;但对于BogusControlFlow,理论上需要收集所有分支判断,工作量更大。
- 求解:利用符号执行沿着切片路径执行到分支处,检查守卫(guard)是否只能取一个值。由于不透明谓词恒真或恒假,我们可以利用这一点进行判定。
- 修补:将条件跳转直接替换为无条件跳转,这一步相对简单。
以下是一个基于 angr 框架实现的原型代码简述:
第一步:定位所有条件分支
首先需要找到目标函数中所有的条件分支指令。在 VEX IR 中,条件分支对应的基本块其默认出口为 Ijk_Boring 类型,且内部包含一个同样为 Ijk_Boring 类型的 Exit 语句。
def find_branches(proj, func):
result = []
for block_addr in func.block_addrs:
block = proj.factory.block(block_addr)
irsb = block.vex
if irsb.jumpkind == 'Ijk_Boring' and any(
isinstance(s, pyvex.stmt.Exit) and s.jumpkind == 'Ijk_Boring'
for s in irsb.statements
):
branch_insn = block.capstone.insns[-1]
result.append(branch_insn.address)
return result
第二步:后向切片
对每个条件分支指令,利用 angr 的数据依赖图进行后向切片,收集所有影响该分支守卫的指令。
def backward_slice_from(proj, cfg, ddg, target_insn_addr):
# ... 获取包含目标指令的CFG节点 ...
# ... 在VEX IR中找到所有Exit语句(即守卫)...
# ... 在DDG中找到对应的种子节点 ...
# 从种子节点开始,沿DDG的反向边进行BFS,收集所有相关节点
visited = set()
queue = deque(seed_nodes)
slice_cls = set()
while queue:
cl = queue.popleft()
if cl in visited:
continue
visited.add(cl)
slice_cls.add(cl)
for pred in ddg.graph.predecessors(cl):
queue.append(pred)
return slice_cls
第三步:符号执行求解
对切片收集到的指令路径进行符号执行,判断分支守卫是否为不透明谓词。
def analyze_branch_guard(proj, slice_cls, branch_block_addr):
# ... 沿切片路径进行符号执行 ...
# 到达分支基本块后,再执行一步,观察产生的后继状态数量
succs = simgr.active[0].step()
if len(succs.successors) == 1:
# angr已具体化守卫值,直接判断恒真/恒假
# 比较解析出的地址与Exit语句目标地址
...
else:
# 守卫为符号化,用约束求解器检查其可满足性
guard = succs.successors[0].history.jump_guard
solver = simgr.active[0].solver
can_be_true = solver.satisfiable(extra_constraints=[guard])
can_be_false = solver.satisfiable(extra_constraints=[claripy.Not(guard)])
if can_be_true and not can_be_false:
return 'always_true', guard
elif can_be_false and not can_be_true:
return 'always_false', guard
else:
return 'symbolic', guard # 真实分支,非不透明谓词
第四步:二进制修补
一旦确认为不透明谓词,即可生成补丁。策略是:在切片指令中找到一段连续的、足够长的区域放置无条件跳转指令(jmp),跳转到正确的目标地址;切片中的其余指令全部用 NOP (0x90) 填充。
def build_slice_patch(proj, slice_cls, target_addr, insn="jmp"):
# 收集切片中所有指令的地址和大小
# 找到一段连续区域(>=5字节,用于放置jmp rel32)
# 在该区域头部汇编jmp指令,剩余空间及切片其他指令全部填充NOP
...
主流程
将上述步骤串联起来,遍历函数中的所有条件分支,识别不透明谓词并生成补丁,最后统一应用到二进制文件。
proj, main_func, cfg, ddg = load_everything(TARGET_BINARY, ...)
branches = find_branches(proj, main_func)
all_patches = []
for branch_addr in branches:
slice_cls = backward_slice_from(proj, cfg, ddg, branch_addr)
kind, guard = analyze_branch_guard(proj, slice_cls, block_addr)
if kind in ('always_true', 'always_false'):
# 确定正确的跳转目标,生成补丁
patch_target = taken_addr if kind == 'always_true' else fall_addr
all_patches.append(build_slice_patch(proj, slice_cls, patch_target, insn='jmp'))
if all_patches:
apply_patches(all_patches, TARGET_BINARY, OUTPUT_BINARY)
反混淆效果评测
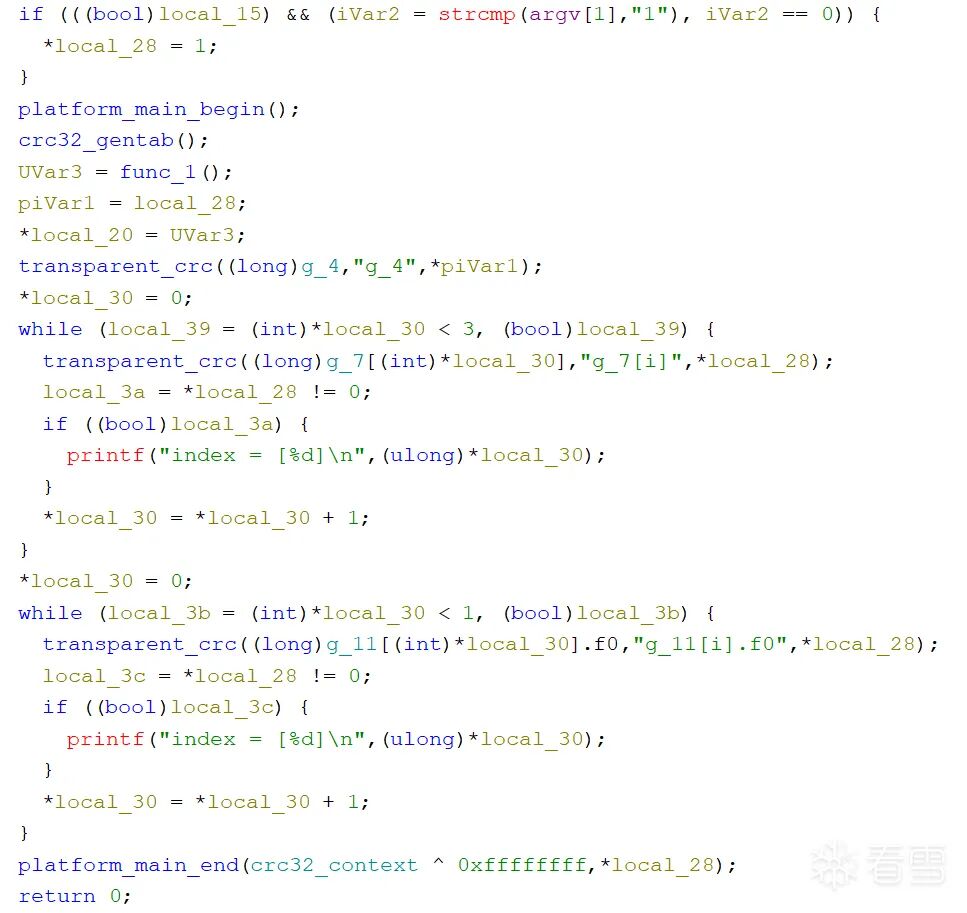
下图展示了反混淆前后的代码对比。混淆后的代码充满了复杂且无意义的分支和循环结构,而经过我们原型工具处理后的代码,逻辑变得清晰可读。
混淆后的反汇编代码(片段):

反混淆并Patch后的C代码(片段):
当前方案的局限性
- 谓词复杂度:目前实现对于
x*(x+1) % 2 == 0 这类简单的不透明谓词效果很好,但对于更复杂的构造(如基于模逆运算的方案),可能需要更强大的约束求解能力。
- 切片连续性假设:修补阶段假设在后向切片中存在一段连续的指令区域来放置
jmp 指令。虽然实践中大多成立,但理论上可能存在指令极度碎片化的情况。
- 性能与路径爆炸:对大型二进制文件进行全函数、全分支的符号执行和切片分析,可能面临路径爆炸和性能问题,需要进一步的优化。
总结
本文深入剖析了 Polaris-Obfuscator 中 BogusControlFlow 混淆技术的实现原理,重点揭示了其通过构造数学恒等式来生成不透明谓词的核心机制,并指出了代码中可能存在的整数下溢Bug。同时,我们提出并实践了一套基于后向切片和符号执行的反混淆方案原型,成功移除了混淆引入的虚假控制流,恢复了代码的原始逻辑。这项工作为理解和对抗此类控制流混淆提供了清晰的思路和可行的技术路径。
完整的原型实现代码位于:https://github.com/Taardisaa/DePolaris

 发表于 2026-3-26 00:05:28
|
查看: 162|
回复: 0
发表于 2026-3-26 00:05:28
|
查看: 162|
回复: 0
