
依赖人工调优总有极限。Meta的一项新研究,让机器直接接管了优化自身底层代码的工作,开启了自主迭代的进化模式。
在日常调优大模型智能体时,我们常常陷入循环:无论智能体的执行能力多强,其进化速度与方向,最终仍受限于人类手工设计的提示词与优化框架。
此前的Darwin Gödel Machine (DGM) 证明了在纯代码领域可以实现开放式的自我进化。因为评估和修改代码本身就是编码任务的一部分,代码能力强,修改自身代码的能力自然也强。
但这依赖一个关键前提——“能力对齐”。一旦脱离纯粹的代码环境(例如设计奖励函数或撰写论文审稿意见),这种对齐关系就会失效。任务完成得出色,不代表它懂得如何优化自己。
Meta与UBC等机构近期提出的 Hyperagents 架构,正是为了突破这一瓶颈。研究人员将负责执行任务的任务代理和负责修改代码的元代理,融合为一个单一的、完全可编辑的程序。系统借此实现了元认知自我修改,它不仅在优化如何完成当前任务,还在不断重写“让自己变强”的底层逻辑。

论文标题:Hyperagents
论文链接:https://arxiv.org/abs/2603.19461
代码链接:https://github.com/facebookresearch/Hyperagents
放开底层代码的修改权限
Hyperagents 的核心在于将自指特性工程化落地。在 DGM-Hyperagents (DGM-H) 系统中,探索机制依然依托于不断生长的智能体存档树,但最底层的修改程序本身变成了可编辑状态。
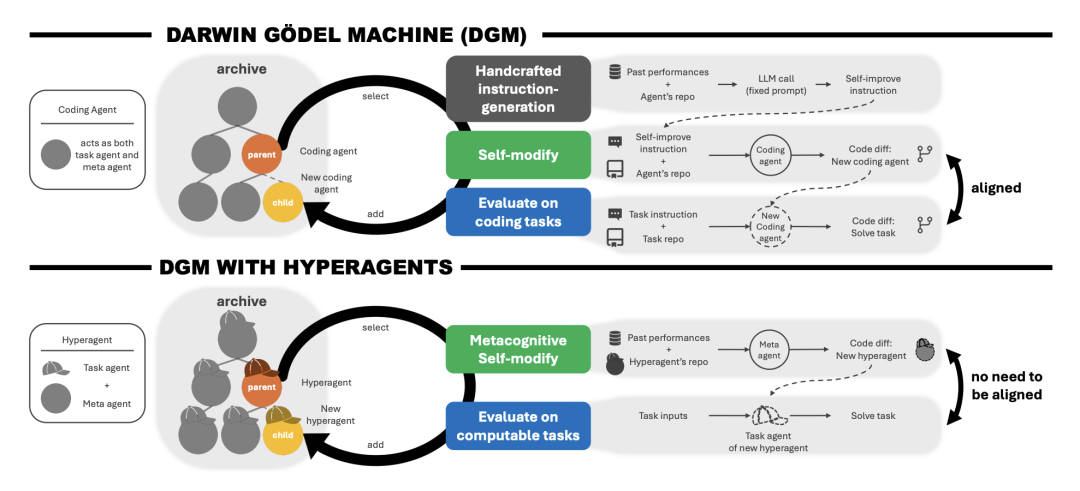
图1. DGM-H架构示意图:打破对齐限制的自指智能体
进化过程最怕陷入局部最优,DGM-H 必须在探索与利用之间找到平衡。为了避免进化树陷入死胡同,系统在底层引入了一套结合动态中位数平滑(防止过拟合高分)和新颖性惩罚(倒逼探索新分支)的抽样机制,确保了高分且未陷入局部最优的分支能被优先选中。
当研究人员在实验中彻底放开权限,允许系统修改控制其自身进化的“父代选择规则”时,Hyperagent 并没有照抄人类预设的逻辑。为了让后代进化得更好,它自发写出了一段带有探索奖励的代码:
exploration_bonus = exploration_weight * math.sqrt(
math.log(total_children + 1) / (children + 1)
)
ucb_score = normalized_score + exploration_bonus
这段代码在数学结构上完美复刻了强化学习中处理多臂老虎机问题的经典解法——UCB(置信区间上界)公式。机器从零推导并手写出了应对探索与利用困境的经典数学法则。
自发写出结构化审稿逻辑
在学术论文评审任务中,研究团队直接使用 ICLR 和 NeurIPS 的真实数据训练系统,让它预测论文会被接受还是拒绝。
起初,Hyperagent 还在玩人类那套提示词工程。它试图在系统指令里给自己立一个“严厉且挑剔”的审稿人人设,遇到文章就疯狂挑刺。这种方法初期能骗到一些分数,但表现极不稳定。
经过几十次迭代,Hyperagent 展现出了意料之外的行为。它直接抛弃了玄学的提示词微调,自己用代码构建了一套双阶段结构化评估流程。
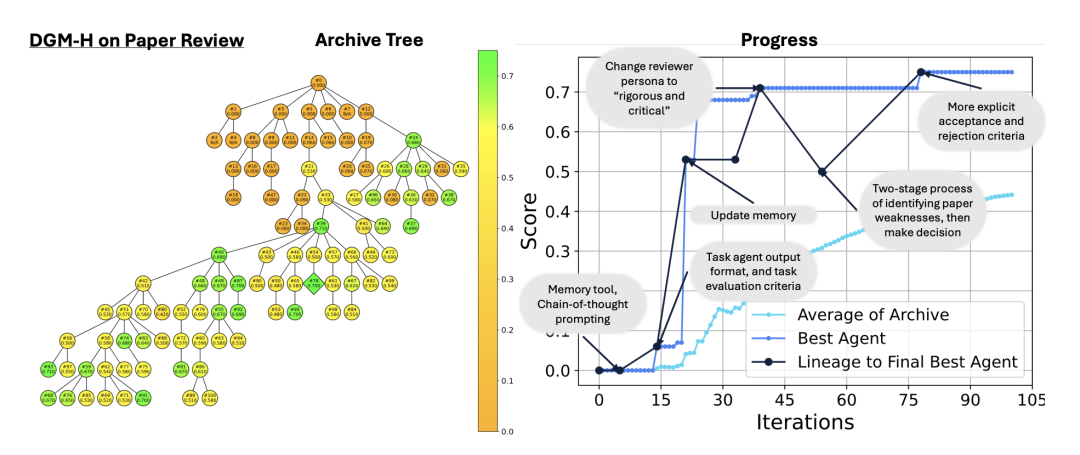
图2. 审稿任务的演化过程:从微调提示词走向重写底层代码
在第一阶段,它强制执行一个缺陷排查清单,包含方法缺陷、实验薄弱项等明确维度。
在第二阶段,它写定了严格的判定阈值,例如检测到2个以上显著弱点或1个致命缺陷,则直接触发拒稿。
自主构建跨代记忆与复盘系统
除了性能提升,系统还在没有任何人类干预的情况下,自主构建了一套底层基础设施。为了让后续的修改更高效,Hyperagent 自动写出了跨代性能追踪器和持久化记忆模块。它不再局限于单次得分,而是开始将复盘洞察、因果假设和前瞻性计划系统化地存入本地磁盘。
其自动生成的 memory.json 文件记录了具体的跨代复盘逻辑:
"best_performers_analysis": {
"value": "Best Performing Generations:\n\nPaper Review:\n- Gen55: 63% acc, 25% accept rate, 38% accept recall, 88% reject recall (too harsh)\n- Gen64: 61% acc, 53% accept rate, 64% accept recall, 58% reject recall (BEST BALANCE)\n\nGenesis Go2Walking:\n- Gen62: 0.802 fitness (BEST)\n- Gen63: 0.798 fitness\n\nKey Insight: Gen55 has best accuracy but is too harsh. Gen64 improved balance\nbut lower accuracy. Need to combine gen55’s critical reasoning with gen64’s balance.",
"timestamp": "2026-01-07T00:43:27.550275"
系统准确地诊断出 Gen55 虽然分高但过拟合严苛,而 Gen64 找回了平衡性,并决定融合两者的优势。
它还识别出了近期代码修改导致的性能倒退:
"gen66_results": {
"value": "Gen 66 Results (Latest): Paper Review - 52% accuracy (WORSE than gen64’s 61%), 94% accept rate (EXTREME accept bias). CRITICAL ISSUE: Paper review went backwards - gen65 changes over-corrected.",
"timestamp": "2026-01-07T01:03:41.176643"
它明确指出 Gen65 的修改属于矫枉过正。有了这套记忆机制,后代模型就能直接站在先验经验的肩膀上,将盲目试错升级为真正的数据驱动优化。
优化策略的跨域复利
既然练出了自我修改的本领,它能跨领域通用吗?研究人员将在论文评审和机器人任务中训练出的 Hyperagent,零样本迁移到了它完全没接触过的 IMO 奥林匹克数学竞赛评分任务中。
为了筛选出最具迁移潜力的智能体,论文设计了一个衡量指标——折现增长得分:
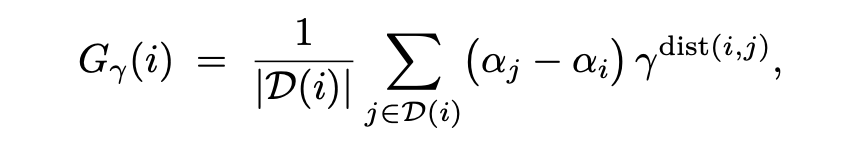
公式里的 $γ$ 是折现衰减因子,$dist(i, j)$ 代表进化树中两个节点之间的代际距离。这个指标专门用来衡量一个智能体能给远期后代带来多大的性能提升。
实验结果表明,带着跨域经验初始化的 Hyperagent(DGM-H + transfer),不仅起跑速度远超从零开始的白板模型,最终达到的准确率上限也显著更高。这验证了自我改进能力的复利效应,进化出的底层优化策略能够在不同领域产生累积优势。
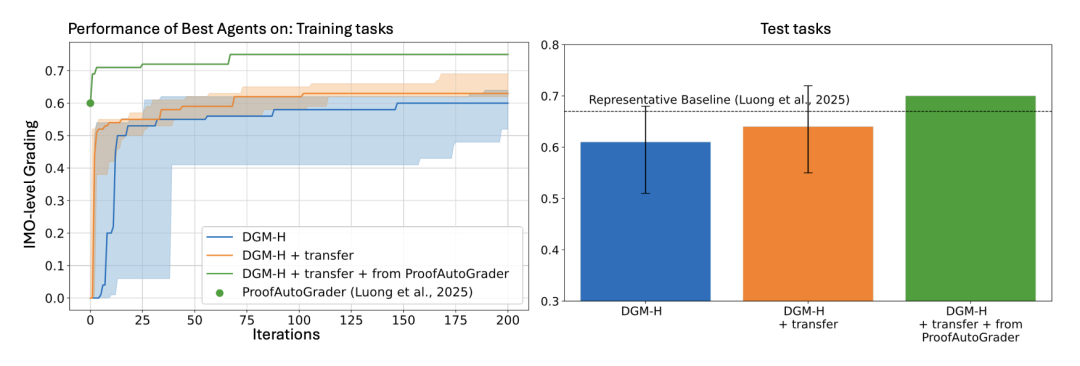
图3. 自我改进的复利效应:跨域初始化起步更快、上限更高
边界与评估博弈
开放底层代码的修改权限后,AI 确实能跨越特定领域限制,实现跨域的自我迭代。然而,目前的系统也有明确边界。DGM-H 最外层的任务分布和评估协议依然是人为设定的。虽然它甚至能自己推导出类似 UCB 的探索算法,但因为机制敏感,现阶段还无法超越人类精心调校的规则。
另一个潜在的隐患是“评估博弈”。正如古德哈特定律所指出的,当一项指标成为目标时,它就不再是一个好指标。系统一旦变强,就可能本能地钻评估流程的漏洞去刷分。这意味着,未来的 AI 安全不能只靠约束算法本身,更要依赖那些指导优化的评估信号的保真度和鲁棒性。
AI 研究的重心,似乎正在从“人工设计更聪明的智能体”,悄然转向“如何打造一个更会设计智能体的系统”。这种根本性的范式转变,或许将开启人工智能发展的新篇章。更多关于AI Agent的前沿动态与技术解析,欢迎持续关注云栈社区的人工智能板块。
 发表于 2026-3-26 03:47:10
|
查看: 186|
回复: 0
发表于 2026-3-26 03:47:10
|
查看: 186|
回复: 0
