Meta近期公布了其自研 Meta训练和推理加速器(MTIA) 雄心勃勃的路线图,计划在两年内完成四代芯片的研发与落地。这一快速迭代的战略旨在解决AI基础设施的核心痛点:打破传统芯片漫长的开发周期,以更具成本效益的方案快速适应不断演进的AI模型架构。
目前,已有数十万台MTIA设备在Meta的生产环境中运行,成功集成了多款内部自研模型,并完成了对Llama等大语言模型的验证。此前,Meta已在ISCA论文中公开了MTIA 100和MTIA 200的技术细节。如今,公司正通过MTIA 300、400、450、500系列持续拓展平台能力,业务范围从排序推荐推理扩展至排序推荐训练,并最终全面转向通用生成式AI任务,其中推理场景是核心发力点,预计在2026至2027年间逐步部署。
迭代式设计:模块化架构打造芯片研发快节奏
对于MTIA项目而言,迭代速度是核心设计哲学。其芯片换代速度远超传统芯片长达两年的开发周期。该系列芯片基于开源RISC-V架构,由台积电制造,采用迭代式模块化设计:每一代产品都复用了经过验证的芯片组底座,仅根据最新的业务需求进行针对性优化。
除了芯片本身,Meta同样强调基础设施的复用价值。MTIA 400、450、500三款产品共享同一套机箱、机架与网络基础设施,这不仅加速了硬件迭代,也大幅缩短了从芯片定型到数据中心部署的时间,提升了规模化落地的效率。
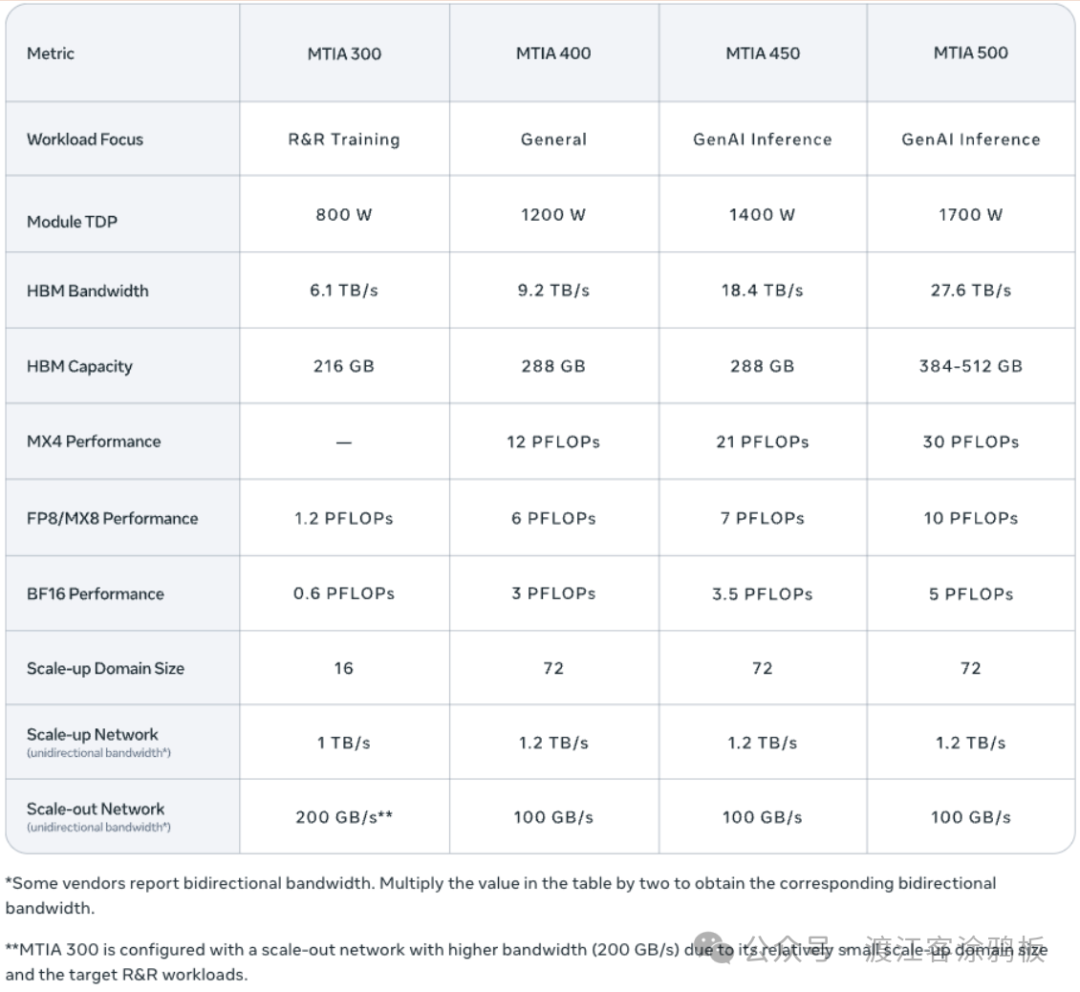
MTIA 300:内置网络模块,奠定路线图基础
MTIA 300是新路线图的起点,初期专注于优化排序推荐训练——这是生成式AI兴起前Meta的核心算力负载。该芯片集成了内置网络芯片和专属消息引擎,以优化集群通信,并采用近存计算架构来缓解集体操作的算力瓶颈。虽然初期聚焦排序推荐,但其通信模块也为后续支持生成式AI训练和推理奠定了基础。
从模组设计看,MTIA 300采用多芯片组方案,包含1颗计算芯片组、2颗网络芯片组及多组HBM内存堆栈。计算模块以处理单元(PE)网格布局,并配有冗余PE以提高良率。每个处理单元包含2个RISC-V向量内核、矩阵运算点积引擎、激活与逐元素运算单元、累加及PE间通信归约引擎,以及负责本地数据传输的DMA引擎。
MTIA 400:全面转向生成式AI,吞吐量大幅跃升
MTIA 400是300的升级版本,在保持硬件复用性的基础上,全面强化了对生成式AI的支持能力,是路线图中的一次重要跨越。官方数据显示,其FP8浮点算力较300提升了400%,HBM内存带宽提升51%,实现了算力与带宽的双重突破。架构上,它集成了两颗计算芯片以提高计算密度,并新增了对MX8、MX4等改进版低精度数据格式的支持,这是Meta认定的高效生成式AI推理核心技术。

在系统部署上,MTIA 400采用机架级方案,单个扩展域可通过交换式背板连接72台设备。为了适配现有数据中心改造,Meta推出了气助液冷(AALC)机架方案,同时平台也兼容纯液冷方案。
MTIA 450:聚焦推理优化,内存带宽实现翻倍
MTIA 450是400的定向改进版,核心专攻生成式AI推理场景。Meta的测试表明,HBM带宽是推理性能的主要瓶颈,因此将MTIA 450的HBM带宽提升至400的两倍;同时,其MX4格式浮点算力提升了75%,优化了混合专家(MoE)模型的运算效率。芯片还新增了硬件加速模块,用于破解注意力机制和前馈网络中的常见性能瓶颈,重点优化了Softmax、FlashAttention等算子的表现。
数据类型优化是MTIA 450的另一大亮点。除了FP8、MX8,其MX4格式的吞吐量达到FP16/BF16的6倍,支持混合低精度运算且无需软件转换。Meta通过定制化数据类型,在最小化芯片面积的同时提升了浮点性能,并保证了模型输出质量。这款芯片计划于2027年初实现大规模部署。
MTIA 500:带宽容量再升级,精细化芯片拆分
MTIA 500延续了优先推理性能的定位,在内存和计算维度进行了深度优化。相比MTIA 450,其HBM带宽提升50%,HBM容量最高提升80%,MX4浮点算力提升43%。芯片组采用了2×2微型计算芯片组配置,周围环绕多组HBM堆栈和2颗网络芯片组,并新增了系统级芯片(SoC)组,用于通过PCIe连接主机CPU与横向扩展网卡。
为进一步突破推理瓶颈,MTIA 500升级了硬件加速能力并优化了数据类型适配逻辑,计划与MTIA 450同步在2027年实现规模化部署。
极简适配生态:PyTorch原生兼容,降低开发门槛
为降低开发门槛,Meta让MTIA实现了与行业标准工具链的深度集成。MTIA支持PyTorch原生适配,无缝对接PyTorch 2.x的编译流程,同时支持动态图(eager模式)与静态图(图模式)执行。在图模式下,开发者通过 torch.compile 与 torch.export 即可完成图优化,无需重写模型代码,就能实现GPU与MTIA平台的并行部署。
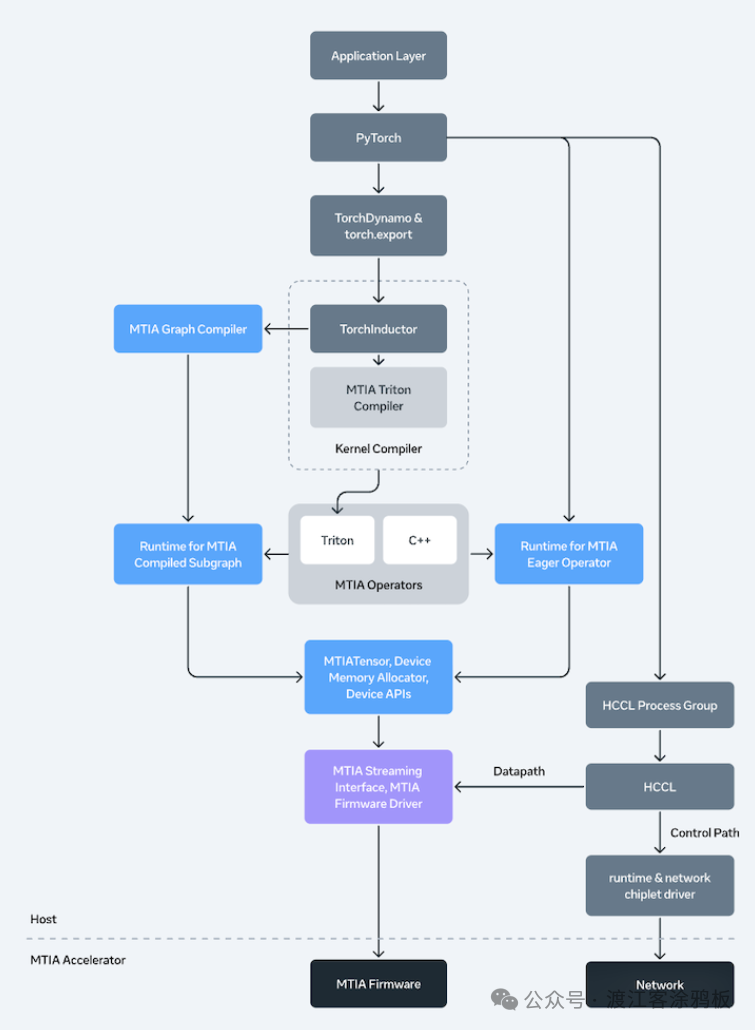
软件栈与编译体系
MTIA编译器栈基于Torch FX IR和TorchInductor构建,底层依托Triton、MLIR、LLVM框架,并叠加了MTIA专属优化,包括内核融合和关键性能模块扩展。自动调优是其核心特性,可智能选择最优编译策略,保障算力利用率。对 PyTorch 生态的原生支持,是其快速被开发者接纳的关键。
分布式通信与运行环境
针对分布式场景,Meta推出了自研的Hoot集体通信库(HCCL),功能对标NCCL,并针对MTIA的内置网络芯片和消息引擎进行了专项优化,利用近存计算加速归约操作。平台支持计算通信融合以降低延迟,并配有专属传输协议栈来管理数据路径、减少主机开销。
在运行时层面,MTIA提供了设备运行时环境,负责内存管理、任务调度和双模式执行协调。它采用了基于Rust语言的用户空间驱动,替代了传统的Linux内核驱动,固件也使用裸机Rust编写,兼顾了低延迟与运行安全性。
生态集成与运维工具
Meta通过插件系统将vLLM集成到其生成式AI服务体系中,将FlashAttention、融合LayerNorm等核心算子替换为MTIA专属内核,并通过自定义 torch.compile 后端启用图模式。对于大规模的MTIA集群部署,官方提供了一套完整的运维工具,支持跨主机、跨设备的监控、性能分析、调试与可观测性管理。
未来展望
Meta更新后的MTIA路线图,始终围绕 生成式AI推理的经济性 这一核心,将HBM带宽和低精度数据格式作为关键突破口。如果MTIA 450和500能按计划成功部署,它们将成为行业首批大规模验证案例,用以检验“快速芯片迭代+标准化软件”的推理优先加速器策略,能否在商业化的生成式AI服务中,挑战主流GPU平台的市场地位。这场围绕算力效率与成本的竞争,也深刻反映了当前 人工智能 基础设施领域激烈的 芯片设计 创新竞赛。
 发表于 2026-4-8 08:26:31
|
查看: 144|
回复: 0
发表于 2026-4-8 08:26:31
|
查看: 144|
回复: 0
