AI 工程的重点,在过去三年里经历了两次明显的跃迁。
2023至2024年,焦点是提示工程(Prompt Engineering),我们研究如何更有效地与大模型对话。2025年,重心转向了上下文工程(Context Engineering),核心变成了精算该给模型“喂”哪些信息。
站在2026年的当下,当各家大模型的能力逐渐趋同,决定一个AI Agent能否真正落地、稳定完成繁重工作的关键,不再是模型本身,而是 Harness。
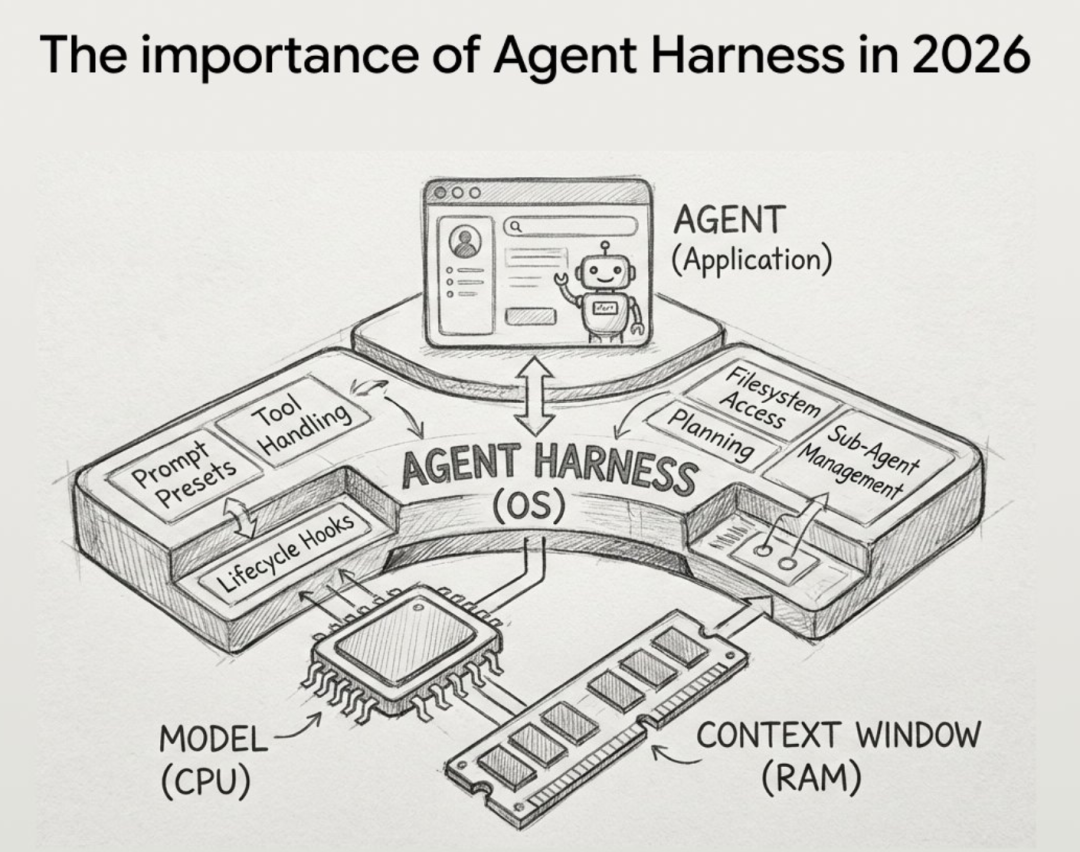
Harness 直译是“马具”。你可以把强大的 AI 智能体想象成一匹野性难驯的骏马。Harness 不提供动力,但它能牢牢掌控方向、稳住步伐,让这匹烈马既能全力奔驰,又始终行走在正确的道路上。在云栈社区的开发者讨论中,这类基础设施的重要性正被反复提及。
前Hugging Face工程师Philipp Schmid在其博客《The importance of Agent Harness in 2026》中给出了定义:Agent Harness 是包裹在 AI 模型周围、专门用于管理长期任务的基础设施。它并非智能体本身,而是位于 Agent Framework 之上的更高层架构,提供了预设提示词、工具调用的标准化处理、生命周期钩子,以及开箱即用的规划、文件系统访问、子智能体管理等能力。
今天我们要深入了解的,正是字节跳动推出的一个代表性 Harness 项目——DeerFlow 2.0。它将第一代的 Deep Research 框架直接升级为 Super Agent Harness,通过有机组织子智能体(sub-agents)、记忆(memory)和沙箱(sandbox),并配合可扩展的技能(skills),旨在让智能体能够处理几乎任何复杂任务。该项目发布后迅速登顶 GitHub Trending 榜首,目前 Stars 数已突破 47.3k。
项目地址:https://github.com/bytedance/deer-flow/tree/main
项目介绍
DeerFlow 的全称是 Deep Exploration and Efficient Research Flow,最初只是一个专注于深度研究的框架。但在社区的实际使用中,它的能力边界被不断拓展——从数据流水线搭建、PPT生成,到仪表盘构建与内容自动化生产,应用场景越来越广。
因此,字节团队决定彻底重构,推出了 DeerFlow 2.0。
DeerFlow 2.0 是一个开箱即用、具备高度扩展能力的 super agent harness。它基于 LangGraph 和 LangChain 构建,借助沙盒环境、长期记忆、工具集、技能模块、子智能体以及消息网关,可以处理从几分钟到几小时的不同复杂度任务。
其核心能力可以拆解为以下几个部分:
(1) Skills 与 Tools
DeerFlow 内置了研究、报告生成、幻灯片制作、网页生成、图文视频创作等多种 skills。这些技能可以一键添加、替换或组合,并支持按需渐进加载,避免浪费 tokens。工具(Tools)同样是可插拔的,网页搜索、内容抓取、文件操作、Bash 命令执行一应俱全,还能通过 MCP Server 或 Python 函数进行无限扩展。
(2) Sub-Agents (子智能体)
面对复杂任务,DeerFlow 会自动进行拆解。主智能体可以根据需要动态拉起子智能体,每个子智能体都拥有独立的上下文、工具集和终止条件,并且能够并行执行。最终,由主智能体汇总所有子任务的结果。这正是 DeerFlow 能够处理长达数小时任务的关键。
(3) Sandbox 与文件系统——给Agent一台“电脑”
每个任务都在隔离的 Docker 容器(沙箱)中运行,拥有完整的文件系统,包括 skills、workspace、uploads、outputs 等目录。智能体可以在其中读写和编辑文件、执行 bash 命令和代码,甚至查看图片。整个过程都在沙箱内完成,具备可审计性和隔离性,不同会话之间互不干扰。
(4) Context Engineering
子智能体的上下文完全隔离,避免了相互干扰。更重要的是,DeerFlow 能够自动对中间结果进行总结、压缩和持久化,确保在运行超长任务时不会“爆”上下文窗口,从而稳定地跑完整个复杂流程。
(5) 长期记忆
DeerFlow 支持跨会话积累个人偏好、写作风格、常用技术栈等信息。这些记忆(memory)默认保存在本地,控制权始终掌握在用户手中。
此外,它还支持与 Claude Code 直接交互、内置了 Python Client、兼容多种模型,并集成了智能搜索与抓取工具 InfoQuest。
使用方法
(1) 克隆 DeerFlow 仓库
git clone https://github.com/bytedance/deer-flow.git
cd deer-flow
(2) 生成本地配置文件
在项目根目录(deer-flow/)执行:
make config
这个命令会基于示例模板,在 config/ 目录下生成本地配置文件 config.yaml。
(3) 配置要使用的模型
编辑 config.yaml 文件,至少需要定义一个模型。以下是一个配置示例:
models:
- name: gpt-4 # 内部标识
display_name: GPT-4 # 展示名称
use: langchain_openai:ChatOpenAI # LangChain 类路径
model: gpt-4 # API 使用的模型标识
api_key: $OPENAI_API_KEY # API key(推荐使用环境变量)
max_tokens: 4096 # 单次请求最大 tokens
temperature: 0.7 # 采样温度
- name: openrouter-gemini-2.5-flash
display_name: Gemini 2.5 Flash (OpenRouter)
use: langchain_openai:ChatOpenAI
model: google/gemini-2.5-flash-preview
api_key: $OPENAI_API_KEY # 这里 OpenRouter 依然沿用 OpenAI 兼容字段名
base_url: https://openrouter.ai/api/v1
(4) 为已配置的模型设置 API key
编辑项目根目录下的 .env 文件,填入对应的 API 密钥。
TAVILY_API_KEY=your-tavily-api-key
OPENAI_API_KEY=your-openai-api-key
# 如果配置使用的是 langchain_openai:ChatOpenAI + base_url,OpenRouter 也会读取 OPENAI_API_KEY
# 其他 provider 的 key 按需补充
INFOQUEST_API_KEY=your-infoquest-api-key
(5) 运行应用
推荐使用 Docker 运行。
-
开发模式(支持热更新,挂载源码):
make docker-init # 拉取 sandbox 镜像(首次运行或镜像更新时执行)
make docker-start # 启动服务(会根据 config.yaml 自动判断 sandbox 模式)
-
生产模式(本地构建镜像,并挂载运行期配置与数据):
make up # 构建镜像并启动全部生产服务
make down # 停止并移除容器
服务启动后,访问地址为:http://localhost:2026
(6) Claude Code 集成
借助 claude-to-deerflow 技能,可以直接在 Claude Code 里与正在运行的 DeerFlow 实例交互。无需离开终端,就能下发研究任务、查看状态、管理对话线程。
安装这个 skill:
npx skills add https://github.com/bytedance/deer-flow --skill claude-to-deerflow
然后确保 DeerFlow 服务已经启动,在 Claude Code 里使用 /claude-to-deerflow 命令即可开始交互。
完整的使用步骤和更详细的配置,请参考项目官方文档:https://github.com/bytedance/deer-flow/blob/main/README_zh.md#%E5%BF%AB%E9%80%9F%E5%BC%80%E5%A7%8B
Harness 崛起:AI 从“能聊”走向“能干”
过去的竞争,往往围绕着谁的模型参数更多、谁的单点能力更令人惊艳。而未来的分水岭,很可能取决于谁能打造出更成熟、更强大的 Harness 体系 —— 谁能让 AI Agent 在真实的业务场景中稳定、可靠地连续运转;谁能在隔离与开放、灵活与安全之间,找到工程上的最优平衡点。
从提示工程到上下文工程,再到如今的 Harness,这条演进路径的本质,是从“教模型如何理解人类”迈向“为模型构建一个可执行、可信赖、可长期运转的数字世界”。当越来越多像 DeerFlow 2.0 这样的 Super Agent Harness 走向成熟和普及,AI 将真正进化为能理解、会规划、可执行、敢交付、长期负责的成熟生产力形态。
 发表于 2026-3-27 01:52:29
|
查看: 142|
回复: 0
发表于 2026-3-27 01:52:29
|
查看: 142|
回复: 0
