你是否也遇到过这样的烦恼:AI 助手在多个项目间反复横跳,实验性重构的记忆污染了稳定版本的上下文?传统的向量数据库方案不仅 Token 成本高昂,还缺乏版本追溯能力。 本文将深入剖析 Memoir——一个为 AI Agent 打造的层级化语义记忆系统。它用 Git 式版本控制替代了传统的向量数据库,以 O(log n) 的分层路径检索替代昂贵的向量运算,并通过 Prompt Caching 友好架构将每次记忆更新的 Token 成本降低 90%。文章覆盖从 ProllyTree 存储引擎、LLM 分类器、分支合并到密码学证明的完整技术栈,如果你正在寻找 AI Agent 记忆系统的优化方案,这篇内容值得一读。
目录
- 概述
- 1.1 项目背景
- 1.2 AI 记忆的三大痛点
- 1.3 Memoir 的核心答案
- 核心架构
- 2.1 四层架构总览
- 2.2 存储层:ProllyTree 与语义聚合
- 2.3 分类层:从语义模式到 LLM 智能分类
- 2.4 搜索层:单阶段与分层检索
- 2.5 服务层:分支、密码学与时序记忆
- 源码分析
- 3.1 ProllyTree 适配器:CWD 锁与键注册表
- 3.2 智能分类器:Prompt Caching 的工程实践
- 3.3 MemoryService 的五步存储管道
- 3.4 LangGraph 集成适配
- 功能详解
- 4.1 Git 风格版本控制
- 4.2 智能召回的分层搜索
- 4.3 时序与位置记忆(Memento)
- 4.4 密码学完整性与溯源
- 技术亮点
- 5.1 Prompt Caching 优先的分类器设计
- 5.2 语义路径聚合替代 UUID
- 5.3 CWD 锁定的 Rust 绑定适配
- 5.4 三级 Store 路径解析策略
- 实践指南
- 6.1 快速上手
- 6.2 Claude Code 插件集成
- 6.3 性能特征
- 总结
1. 概述
1.1 项目背景
Memoir 诞生于一个朴素但深刻的观察: AI Agent 的记忆管理本质上是一个版本控制问题,而非向量搜索问题。
传统的 AI 记忆方案(如向量数据库、CLAUDE.md 文件、临时草稿本)将记忆视为一个“追加型 blob”——没有版本历史、没有分支隔离、没有回滚能力。一次糟糕的会话注入的错误信息会永久污染后续所有的检索结果。当 Agent 同时处理多个项目时,实验性重构产生的记忆会污染稳定生产环境的上下文。
Memoir 另辟蹊径,将 Git 的工作方式引入 AI 记忆领域:分支(branch)、提交(commit)、合并(merge)、回滚(rollback),外加密码学完整性证明。它以层级化语义路径(profile.professional.skills.python)替代 UUID 键,以 O(log n) 的前缀检索替代昂贵的向量近似搜索。

1.2 AI 记忆的三大痛点
- 上下文污染:当你每次
git checkout 切换项目时,Agent 的记忆并不会感知分支切换——它会把实验性重构的认知模式,错误应用到稳定生产的热修复上。没有分支感知的记忆就像没有 .git 目录的代码。
- Token 租金:使用
CLAUDE.md 或 MEMORY.md 作为全局记忆存储是缓存杀手。每次微小的记忆更新都会使整个前缀缓存失效,迫使你为重新处理整个对话支付全额 Token 费用。这是固定成本,随记忆量线性增长。
- 记忆漂移:没有
memoir blame 或 memoir checkout,就无法审计是谁、在何时教会了 Agent 某条规则,也无法在不擦除整个存储的情况下回滚一条幻觉。记忆变成了代码的“全局变量反模式”——任何人都能修改,没人能追溯。
1.3 Memoir 的核心答案
Memoir 给出的答案不是“更好的向量搜索”,而是对这三个问题的系统性解答:
| 痛点 |
Memoir 方案 |
| 上下文污染 |
分支感知存储,按 store 路径(而非 git cwd)隔离记忆 |
| Token 租金 |
Prompt Caching 友好的分类器,静态前缀复用降低 90% 成本 |
| 记忆漂移 |
Git 风格版本控制 + blame/proof/checkout 完整审计链 |
Memoir 的底层是 ProllyTree——一种概率性 Merkle 树(Probabilistic Merkle Tree),提供 O(log n) 的前缀查找性能,配合 SHA-256 密码学哈希保证完整性。上层通过 LLM 驱动的分类器和搜索引擎将自然语言映射到层级语义路径,实现了“像操作代码一样操作记忆”的完整体验。
2. 核心架构
2.1 四层架构总览
Memoir 采用严格的清洁分层架构 ,每一层通过依赖注入解耦,确保良好的可测试性和可替换性:

- 存储层 (
src/memoir/store/):ProllyTree 适配器,实现 LangGraph BaseStore 接口,提供 Git 风格版本键值存储、记忆聚合和密码学完整性。
- 分类层 (
src/memoir/classifier/):语义分类器(1-5ms 快速模式匹配)和智能分类器(LLM 驱动,Prompt Caching 优化)。
- 搜索层 (
src/memoir/search/):LLM 驱动的智能搜索引擎,支持单阶段和分层检索两种模式。
- 服务层 (
src/memoir/services/):MemoryService、BranchService、CryptoService、StoreService 四大服务,提取可复用的业务逻辑。
- 核心层 (
src/memoir/core/):ProllyTreeMemoryStoreManager(LangMem 兼容管理器)、ProfileMemento、TimelineMemento、LocationMemento。
2.2 存储层:ProllyTree 与语义聚合
存储层的核心是 ProllyTreeStore(src/memoir/store/prolly_adapter.py),它实现了 LangGraph 的 BaseStore 接口。存储层只负责存取,分类由上层处理。
# 存储层仅负责存取,不进行分类
from memoir.store.prolly_adapter import ProllyTreeStore
store = ProllyTreeStore(
path="./memory_store",
enable_versioning=True,
auto_commit=True,
cache_size=10000
)
与传统方案将每条记忆单独存储在 UUID 键下不同,Memoir 采用语义聚合 策略:
# 传统方案
uuid-1234-5678 -> "我在 TechCorp 工作"
uuid-9876-5432 -> "我是软件工程师"
uuid-1111-2222 -> "我有5年编码经验"
# Memoir 方案
profile.professional.occupation -> {
"memories": [
{"content": "我在 TechCorp 工作", "confidence": 0.95},
{"content": "我是软件工程师", "confidence": 0.87},
{"content": "我有5年编码经验", "confidence": 0.82}
],
"count": 3,
"last_updated": "2024-01-15"
}
相同语义路径下的记忆被聚合为一个 AggregatedMemory 对象,通过 store_memory_async 方法写入时自动合并。这样做的好处显而易见:一次路径检索即可获取该语义节点下的所有相关记忆,无需多次向量搜索。
存储层还有两个值得关注的工程细节:
_CwdLockedTree 代理:ProllyTree 的 Rust 绑定在每次操作时都使用当前工作目录(cwd)来定位 git 仓库——而不仅仅在构造时。_CwdLockedTree 包装器在每次方法调用前 chdir 到存储路径,调用后恢复原始 cwd,解决了跨工作目录调用的“Not in a git repository”错误。- 键注册表:由于 ProllyTree 在某些模式(如内存模式)下不支持键枚举,适配器维护了一个键注册表来跟踪所有已写入的键,使
search 等需要遍历的操作成为可能。这在 开源实战 中是一个非常值得借鉴的适配器模式实践。
2.3 分类层:从语义模式到 LLM 智能分类
分类层包含两个实现:
SemanticClassifier (src/memoir/classifier/semantic.py):基于 LLM 的分类器,将分类 Prompt 精心设计为“静态前缀 + 动态内容”结构,最大化 Prompt Caching 命中率。分类缓存使用 SHA-256 内容哈希作为键。IntelligentClassifier (src/memoir/classifier/intelligent.py):更高级的分类器,额外处理“记忆价值判断”——决定内容是否值得存储。它定义了 ClassificationAction(SKIP/CLASSIFY/EXPAND/USE_PARENT)和 MemoryAction(SKIP/STORE/REPLACE/APPEND/MERGE)两套枚举,执行多阶段管道:模式匹配 -> LLM 分类 -> 动态扩展。
from memoir.classifier.intelligent import IntelligentClassifier
classifier = IntelligentClassifier(
llm=llm,
confidence_thresholds={
"high": 0.8, # 自动存储
"medium": 0.5, # 待审核
"low": 0.0 # 拒绝阈值
}
)
分类器使用置信度阈值 三级策略:
- 高置信度(>0.8):自动存储到分类路径。
- 中置信度(0.5-0.8):标记待审核。
- 低置信度(<0.5):触发动态分类扩展或使用父路径降级。
2.4 搜索层:单阶段与分层检索
搜索层 IntelligentSearchEngine(src/memoir/search/intelligent.py)支持两种检索模式:
mode="single"(默认):一次 LLM 调用从完整路径清单中选择相关路径。对于中小规模存储(<1000 条记忆),延迟最低。mode="tiered"(分层):多阶段下钻:
- L1 直方图:统计一级路径分布。
- L1 挑选:LLM 从一级路径中选择。
- L2 挑选(条件触发):当单个 L1 前缀超过 40 个键时触发。
- 精确键匹配:最终路径选择。
分层模式每一步的 Prompt 更窄、更精确,在存储规模增长时扩展性更好。

流程执行说明:
- 步骤1-2:用户通过自然语言查询,搜索引擎首先从 ProllyTree 获取命名空间下所有键的列表。
- 步骤3-6:搜索引擎对键按层级分组聚合(L1 直方图),然后调用 LLM 选择最相关的一级路径前缀。
- 步骤7-9:对筛选后的键再次按次级分组,若单前缀超过 40 个键则触发 L2 LLM 调用进一步缩窄范围。
- 步骤10-11:用筛选出的精确路径从存储中取值并返回结果。
2.5 服务层:分支、密码学与时序记忆
服务层将核心业务逻辑从 UI 处理器中提取出来,供 CLI、TUI、SDK 和 HTTP 处理器共享。
MemoryService:实现记忆的 5 步存储管道(初始化 -> 分类 -> 存储 -> 时间线处理 -> 位置处理)。BranchService:管理 Git 分支操作(列表、检出、合并、差异比较、时间旅行)。CryptoService:密码学证明生成、验证和 blame 溯源。StoreService:存储创建、连接和状态管理。
3. 源码分析
3.1 ProllyTree 适配器:CWD 锁与键注册表
ProllyTreeStore(src/memoir/store/prolly_adapter.py)是整个系统的数据根基。它实现了 LangGraph 的 BaseStore 接口,同时封装了 ProllyTree(Rust 绑定)和 VersionedKvStore 两个底层引擎。
class ProllyTreeStore(BaseStore):
def __init__(self, path, enable_versioning=True, auto_commit=True, cache_size=10000):
self.path = Path(path)
self.path.mkdir(parents=True, exist_ok=True)
# 版本化模式需 .git 目录存在
if enable_versioning and not (self.path / ".git").exists():
raise FileNotFoundError(
f"Not a memoir store: {self.path}"
)
if enable_versioning:
data_dir = self.path / "data"
data_dir.mkdir(exist_ok=True)
# VersionedKvStore 的 Rust 绑定在每次操作时使用 cwd
# 来定位 git 仓库——不仅是构造时
import os
saved_cwd = os.getcwd()
try:
os.chdir(str(self.path))
_raw_tree = VersionedKvStore(str(data_dir))
finally:
os.chdir(saved_cwd)
self.tree = _CwdLockedTree(_raw_tree, self.path)
else:
self.tree = ProllyTree("memory")
_CwdLockedTree 是解决 Rust FFI 边界问题的一个精巧设计:
class _CwdLockedTree:
def __init__(self, tree, store_path):
object.__setattr__(self, "_tree", tree)
object.__setattr__(self, "_store_path", str(store_path))
def __getattr__(self, name):
attr = getattr(self._tree, name)
if not callable(attr):
return attr
def _wrapped(*args, **kwargs):
saved = os.getcwd()
try:
os.chdir(self._store_path)
return attr(*args, **kwargs)
finally:
os.chdir(saved)
return _wrapped
这个包装器拦截所有对底层树对象的方法调用,在每次调用前 chdir 到存储路径,调用后恢复。它能覆盖 28+ 个调用点,比手动注释每个公共方法更统一也更安全。object.__setattr__ 用于绕过 __getattr__ 的递归风险。
键注册表是另一个权衡设计:
def _populate_key_registry(self):
try:
if hasattr(self.tree, "scan"):
for key_bytes, _ in self.tree.scan():
self._keys.add(key_bytes.decode("utf-8"))
elif hasattr(self.tree, "list_keys"):
for key_bytes in self.tree.list_keys():
self._keys.add(key_bytes.decode("utf-8"))
except Exception as e:
logger.warning(f"Could not populate key registry: {e}")
由于 ProllyTree 在非版本化模式下不提供键枚举 API,适配器在启动时尝试填充键注册表,并在每次 put 时追加新键。这使得 search() 方法在两种模式下都能工作。
3.2 智能分类器:Prompt Caching 的工程实践
IntelligentClassifier(src/memoir/classifier/intelligent.py)是一个值得仔细研究的模块。它的 classify_input 方法执行了一条完整的多阶段 LLM 管道:
class IntelligentClassifier:
def __init__(self, llm, taxonomy_version=TaxonomyVersion.GENERAL,
confidence_thresholds=None, ...):
self.taxonomy = LLMIterativeTaxonomy(llm=llm)
self._action_cache = {}
self._prompt_template = self._load_prompt_template()
async def classify_input(self, content, metadata=None, return_prompt=False):
# 第1步:记忆价值判断
is_worthy, action = await self._check_memory_worthiness(content, metadata)
# 第2步:执行分类或跳过
result = await self._perform_classification(content, metadata, action)
# 第3步:处理低置信度
if result.confidence_level == ClassificationConfidence.LOW:
result = await self._handle_low_confidence(content, metadata, result)
# 第4步:决定存储策略
memory_action, result = await self._decide_memory_action(
content, metadata, result
)
# 第5步:提取结构化元数据
result = await self._extract_structured_metadata(content, metadata, result)
return result
这条管道的工作流为:

流程执行说明:
- 步骤1-3:分类器首先通过 LLM 判断内容是否值得作为记忆存储,不值得的内容直接返回 SKIP。
- 步骤4-6:对于值得记忆的内容,调用 LLM 将内容分类到语义路径,返回一个或多个路径及置信度评分。
- 步骤7-11:若置信度低于阈值(如 <0.5),触发动态分类扩展——向
LLMIterativeTaxonomy 请求候选扩展路径,获取新路径后重新分类。
- 步骤12-13:决定最佳存储策略——新记忆直接存储、已有记忆则更新或合并、冗余记忆则追加。
- 步骤14-15:从内容中提取结构化事件,供 Memento 模块进一步处理。
分类器中 Prompt Caching 的关键设计在于分类模板的结构:STATIC_SECTION 包含完整的分类树结构和示例(>2048 个 token,达到 Haiku 的最小缓存阈值),DYNAMIC_SECTION 只包含变化的上下文和待分类内容。这样每次分类只需要为动态部分付费。
3.3 MemoryService 的五步存储管道
MemoryService.remember() 方法实现了记忆存储的完整管道。但当调用者通过 path 参数提供了预分类路径时,整个 LLM 分类链会被跳过——这是一个重要的延迟优化:
async def remember(self, content, namespace="default", path=None, paths=None):
# 路径预提供分支——跳过全部 LLM 调用
if provided_paths:
keys = provided_paths
key = keys[0]
confidence = 1.0
reasoning = f"Path provided by caller; classifier skipped: {keys}"
else:
# 完整 LLM 分类管道
classifier = self._get_classifier()
result = await classifier.classify_input(content, metadata=...)
key = result.path or "context.current.session"
keys = [key] if not result.paths else result.paths
timeline_events = result.timeline_events
location_events = result.location_events
# 第3步:存储(支持多路径写入)
for storage_key in keys:
siblings = [k for k in keys if k != storage_key]
memory_item["related_keys"] = list(siblings)
store.put(namespace_tuple, storage_key, memory_item)
# 第4步:时间线处理
if timeline_events:
await timeline_memento.apply_timeline_events(timeline_events, ...)
# 第5步:位置处理
if location_events:
await location_memento.apply_location_events(location_events, ...)
值得注意的设计决策:多路径写入时,每个 blob 的 related_keys 字段记录了同批次写入的其他路径——这让语义搜索可以跨路径关联相关记忆。
3.4 LangGraph 集成适配
LangGraphMemoryStore 实现了 LangGraph 的 BaseStore 接口,使 Memoir 可以作为 LangGraph Agent 的即插即用记忆后端:
class LangGraphMemoryStore(BaseStore, BaseIntegration):
def __init__(self, config=None, llm=None):
# 自动创建存储、初始化分类树、设置分类器和搜索引擎
self._init_storage() # ProllyTreeStore
self._init_taxonomy_loader() # 加载/初始化分类树
self._init_taxonomy() # fixed / iterative / intelligent
self._init_search() # IntelligentSearchEngine + MemoryManager
它支持三种分类模式:fixed(固定分类树,约 200 个路径)、iterative(LLM 驱动的动态扩展)、intelligent(完整的智能分类管道)。通过 abatch/asearch/aput/adelete 等标准接口暴露功能。
4. 功能详解
4.1 Git 风格版本控制
Memoir 的核心创新是将 Git 的操作模型完整映射到记忆管理:
# 创建存储
memoir new my-store && cd my-store
# 显式路径存储(离线,无需 LLM)
memoir remember "Sarah prefers tabs and 2-space indents" -p preferences.coding.style
# 自动分类存储(需要 LLM API Key)
memoir remember "I work in Pacific time"
# 路径读取(离线)
memoir get preferences.coding.style
# 语义搜索(LLM 驱动)
memoir recall "what does Sarah prefer?"
分支与合并操作如下:
memoir branch experiment # 创建实验分支
memoir checkout experiment # 切换到实验分支
memoir remember "Testing new classifier config" -p context.experiment.config
memoir checkout main # 切回主分支
memoir merge experiment main # 合并实验分支
memoir diff experiment main # 对比分支差异

流程执行说明:
- 步骤1-3:用户切换到实验分支后,所有记忆操作都被隔离在该分支中。
- 步骤4-6:在实验分支中存储的记忆被 VersionedKvStore 通过 Git commit 记录,获得密码学哈希标识。
- 步骤7-9:切回主分支后,实验分支的记忆不可见——就像代码分支隔离一样。
- 步骤10-12:合并操作将实验分支的记忆变更应用到主分支,支持 ours/theirs/skip 三种冲突解决策略。
4.2 智能召回的分层搜索
分层搜索是 Memoir 在规模化场景下的核心优势。当存储中有数千条记忆时,单次 LLM 调用处理完整路径清单会受限于上下文窗口和处理延迟。分层搜索将问题分解为递进式的决策步骤:
- L1 直方图:统计所有一级路径分布,如
profile:150, preferences:80, context:40。
- L1 挑选:LLM 从一级路径中选出最相关的 2-3 个前缀。
- L2 直方图:统计筛选后键的二级路径分布。
- L2 挑选(条件触发):仅当某个 L1 前缀下有超过 40 个子键时,才发起 L2 LLM 调用。
- 精确匹配:最终用筛选出的路径前缀调用
store.get。
这种设计在小型存储中退化为单阶段搜索(mode="single"),在大型存储中自动启用分层下钻(mode="tiered"),实现了自适应的性能平衡。
4.3 时序与位置记忆(Memento)
Memoir 在核心记忆之上提供了三个结构化的记忆类型——Memento:
ProfileMemento:管理个人档案信息,自动从对话中提取和更新用户画像。TimelineMemento:管理时间线事件,支持时间旅行查询。LocationMemento:管理空间/地理位置相关的记忆。
这些 Memento 由 IntelligentClassifier 在 classify_input 管道的第 5 步自动提取,无需用户显式调用。
4.4 密码学完整性与溯源
Memoir 利用 ProllyTree 的 Merkle 树结构提供密码学级别的完整性保证:
# 生成某条记忆的密码学证明
memoir proof preferences.coding.style
# 验证证明
memoir verify <proof_b64> preferences.coding.style
# 查看变更历史
memoir blame preferences.coding.style
CryptoService 通过 store.tree.generate_proof(key) 获取 Merkle 包含证明,以 base64 编码返回。blame 通过 store.get_key_history() 调用 VersionedKvStore.get_commits_for_key() 获取每次提交的作者、时间戳和消息——就像 git blame 一样。
5. 技术亮点
5.1 Prompt Caching 优先的分类器设计
Memoir 的分类器将分类 Prompt 模板设计为两段式结构:
- STATIC_SECTION:包含完整的分类树层级(约 200 个路径)和分类示例。在 Anthropic API 中,这部分内容长度超过 2048 tokens,满足 Prompt Caching 的最小阈值,一旦缓存命中,成本降低 90%。
- DYNAMIC_SECTION:仅包含变化的上下文信息和待分类的原始内容。
self.classification_template = """[STATIC_SECTION_START]
You are a semantic memory classifier...
AVAILABLE TAXONOMY STRUCTURE:
{taxonomy_structure} # ~200个路径,固定不变
{examples} # 固定示例
CLASSIFICATION GUIDELINES:...
[STATIC_SECTION_END]
[DYNAMIC_SECTION_START]
{context_info} # 每次变化
{classification_hints} # 动态提示
MEMORY CONTENT TO CLASSIFY:
{memory_content} # 每次变化
[DYNAMIC_SECTION_END]"""
这是面向 LLM 服务成本的精细化工程——不仅是“把分类做对”,更是“用最小成本做对”。
5.2 语义路径聚合替代 UUID
传统方案使用 uuid -> memory 映射,每条记忆独立存储。Memoir 使用 semantic_path -> AggregatedMemory 映射:
- 同一个语义节点下的多条记忆被聚合为一个对象,减少了存储条目数。
- 检索时一次路径读取即可获取该节点下所有记忆,无需遍历。
- 支持记忆计数、首次/最后时间戳等元信息。
这本质上是用确定性层级索引 替代概率性向量索引。一个简单的路径前缀查找 profile.professional.skills 就能返回该用户的所有技能——不需要 ANN(近似最近邻)算法的 (k) 次向量距离计算。
5.3 CWD 锁定的 Rust 绑定适配
ProllyTree 的底层 Rust 绑定在每次操作 时都使用当前工作目录来定位 git 仓库。_CwdLockedTree 代理以 Python 的 __getattr__ 机制拦截所有方法调用,在每次调用前透明地 chdir 到正确路径。这个设计不需要修改 Rust 绑定,不引入额外依赖,且覆盖了所有未来新增的方法,是一种非常聪明的“造轮子”式解决方案。
5.4 三级 Store 路径解析策略
Memoir 的 CLI 入口采用明确的三级路径解析,没有任何隐式的全局默认值:
-s / --store 命令行标志(优先级最高)。MEMOIR_STORE 环境变量(每个 shell session)。- 当前工作目录(让
cd <store> && memoir ... 自然工作)。
项目文档明确说明了为什么没有 ~/.config/memoir/config.json 的全局默认值:它容易导致跨项目工作时出现“错误存储的陈旧默认值”引发的数据错乱问题。删除全局默认值是一个防御性的设计决策。
6. 实践指南
6.1 快速上手
安装和基本使用:
# 安装
pip install memoir-ai
# 设置 API Key(默认使用 claude-haiku-4-5)
export ANTHROPIC_API_KEY="sk-..."
# 创建记忆存储
memoir new my-memoir-store
cd my-memoir-store
# 存储记忆
memoir remember "我习惯用 VS Code,主题是 Monokai" -p preferences.tools.editor
memoir remember "我的主要编程语言是 Python 和 Rust"
# 搜索记忆
memoir recall "我平时用什么编辑器?"
# 打开 Web UI 可视化管理
memoir ui
如果不指定路径,Memoir 会自动调用 LLM 将内容分类到最合适的语义路径。显式指定路径(-p)则完全离线,无需 API 调用。
6.2 Claude Code 插件集成
在 Claude Code 会话中,一键安装:
/plugin marketplace add zhangfengcdt/memoir
/plugin install memoir@memoir
如果系统有 uv,插件会自动通过 uvx --from memoir-ai memoir 解析——无需手动 pip install。安装 uv 只需一行:
curl -LsSf https://astral.sh/uv/install.sh | sh
插件会注册 SessionStart、UserPromptSubmit 和 Stop 三个钩子,自动注入项目上下文和捕获会话记忆。
6.3 性能特征
| 操作 |
延迟 |
说明 |
| 语义搜索 |
0.1-1ms |
基于路径前缀的确定性查找 |
| 智能搜索(单阶段) |
100-500ms |
含 1 次 LLM 调用 |
| 智能搜索(分层) |
150-800ms |
含 1-2 次 LLM 调用,随规模扩展更好 |
| 模式分类 |
1-5ms |
基于缓存的快速模式匹配 |
| LLM 分类 |
100-500ms |
含 Prompt Caching 优化 |
| 存储操作 |
20-30ms |
一次键值写入 |
| 版本控制操作 |
50-100ms |
含 Git commit 写入 |
存储已测试至 100 万条记忆,路径深度支持最多 8 级,命名空间层面支持水平扩展。
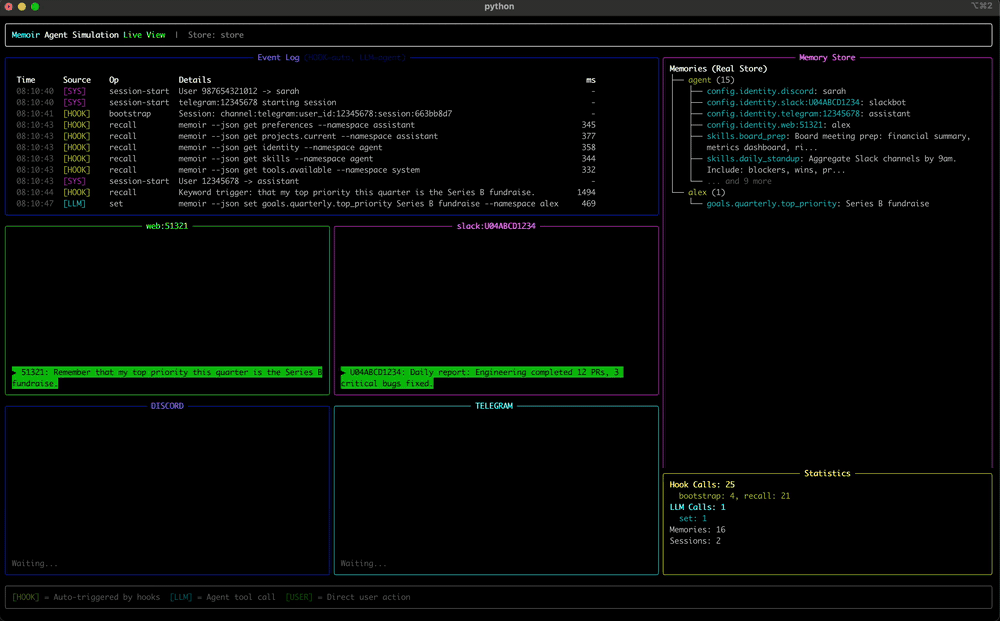
7. 总结
Memoir 的核心理念是将 AI Agent 记忆从“不透明的向量 blob”转变为“可审计、可分支、可合并的版本化资产”。它的技术栈展示了几个重要的设计决策:
- 用确定性替代概率性:O(log n) 的层级路径检索替代 O(n) 的向量近似搜索,在绝大多数 Agent 记忆场景下足够好,且避免了向量搜索的语义漂移。
- 用版本控制解决记忆污染:分支隔离、提交历史、blame 溯源——这些 Git 原语直接映射到记忆管理的需求。
- 用 Prompt Caching 优化成本:分类器模板的静态/动态分离设计,将每次分类的 LLM 成本降低 90%。
- 用聚合替代拆分:语义路径下的记忆聚合减少存储条目、加速检索、支持批量上下文注入。
Memoir 当前处于 Alpha 阶段(v0.2.0),明确面向 Coding Agent 使用场景优化。对于正在构建 AI Agent 系统、受困于记忆管理的开发者来说,它提供了一套比向量数据库更透明、比文件模式更结构化、比临时草稿更可靠的第三选择。你可以在其 GitHub 仓库 中了解更多。
参考文献
[1] Memoir GitHub 仓库: https://github.com/zhangfengcdt/memoir
[2] Memoir 官方文档: https://zhangfengcdt.github.io/memoir/
[3] Memoir PyPI: https://pypi.org/project/memoir-ai/
[4] ProllyTree 项目: https://github.com/rust-python/prollytree
[5] LangGraph BaseStore 接口: https://langchain-ai.github.io/langgraph/reference/store/
 发表于 2026-5-11 18:26:04
|
查看: 126|
回复: 0
发表于 2026-5-11 18:26:04
|
查看: 126|
回复: 0
