AI Agent 的记忆管理正面临三大结构性困境。其一,上下文污染:每次 git checkout 切换分支时,Agent 会把实验性重构模式套用到生产环境的热修复上,因为它的记忆不感知 Git 状态。其二,Token 地租:把 CLAUDE.md 或 MEMORY.md 当作全局记忆文件,每做一次微小更新就使整个前缀缓存失效,每次对话都需重新处理全量上下文。其三,记忆漂移:今天的 AI 记忆——CLAUDE.md、向量数据库、草稿本——本质上是一个只追加写入的 Blob 存储,一次糟糕的会话就能毒化后续所有检索结果,而你无法像 git blame 一样溯源“谁教会了 Agent 这条规则”,也无法在不擦除整个存储的前提下回滚一次幻觉。
Memoir 用一个核心设计回应这三个问题:把 Git 的版本控制模型搬到 AI 记忆层。它不是“又一个向量数据库”,而是一个以 Git 为底层、以语义层级路径为索引、以加密哈希保证完整性的记忆版本管理系统。
1.1 核心特性
- Git 式版本控制:对记忆进行分支、提交、合并和回滚,每次变更附带加密完整性校验
- 语义路径索引:用
profile.professional.skills.python 替代 UUID 键值,存储即分类
- O(log n) 层级查找:基于前缀树的快速检索,避免昂贵的向量相似度计算
- 记忆聚合:自动将相关记忆归并到语义节点下,形成可解释的知识结构
- 多搜索引擎:快速关键词搜索与 LLM 智能搜索可切换,按需选择延迟/精度平衡
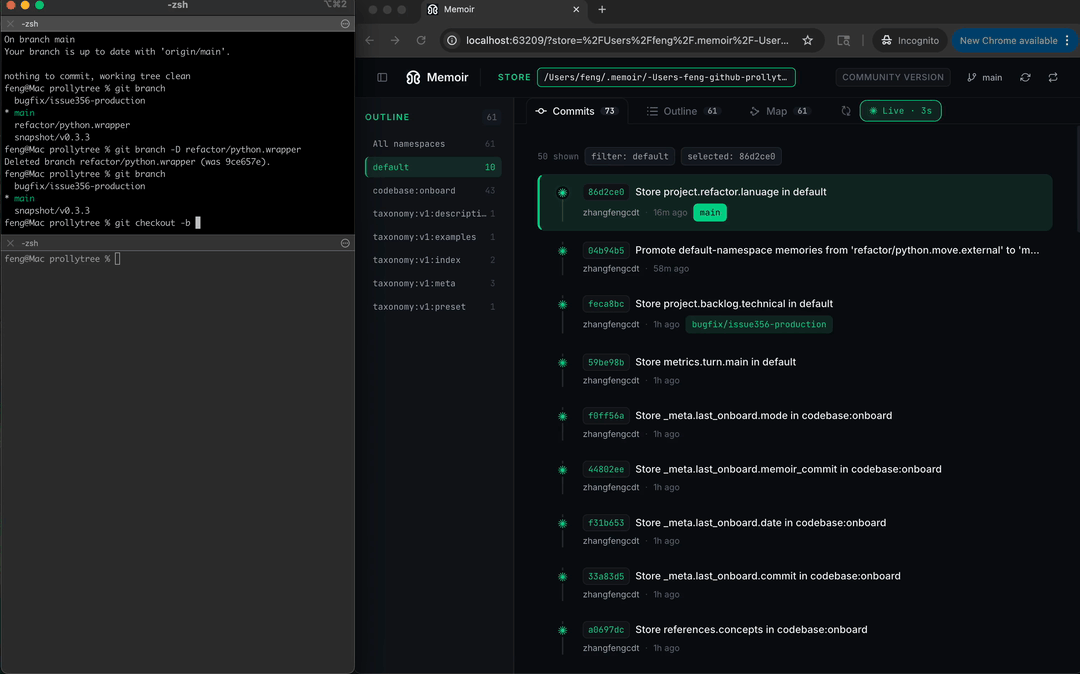
- 可视化浏览器:Tree、Graph、Timeline、Places 四种视图 + 7 维度统计面板
- 多 Agent 会话支持:多个 Agent 实例可共享同一记忆存储,命名空间隔离
- Claude Code 原生插件:自动注入上下文,自动捕获会话记忆,零配置接入
2. 环境准备与安装
基础环境需要 Python 3.10 或更高版本,以及 Git(用于版本控制功能)。
安装方式有三种,按推荐度从高到低排列:
# 1. 推荐:uv tool 持久安装(速度最快,环境隔离)
uv tool install memoir-ai
# 2. 即用即走:无需安装,临时运行
uvx --from memoir-ai memoir --help
# 3. 通用方案:传统 pip 安装
pip install memoir-ai
如果你还没有 uv,用一行命令安装:
curl -LsSf https://astral.sh/uv/install.sh | sh
PyPI 上的分发包名为 memoir-ai(memoir 名称已被占用),但导入时仍使用 import memoir,CLI 命令仍为 memoir。
验证安装是否成功:
memoir --version
或者用 Python 验证:
import memoir
print(f"Memoir version: {memoir.__version__}")
2.1 版本选择与依赖说明
从 v0.1.7 开始,litellm(LLM 路由库)已成为默认依赖,因此 recall(语义搜索)和 remember(自动分类)开箱即用。此前版本需要手动安装 memoir-ai[litellm] 额外项。
可选依赖扩展:
pip install 'memoir-ai[tui]' # 终端 UI(基于 Textual)
pip install 'memoir-ai[langmem]' # ProllyTreeMemoryStoreManager(LangMem 兼容层)
pip install 'memoir-ai[all]' # 全部扩展
Docker 用户可以直接构建镜像:
docker build -t memoir .
docker run -v $(pwd)/data:/app/data memoir
3. 快速上手
以最常见的“创建记忆仓库 → 写入记忆 → 语义搜索 → 可视化浏览”链路为例:
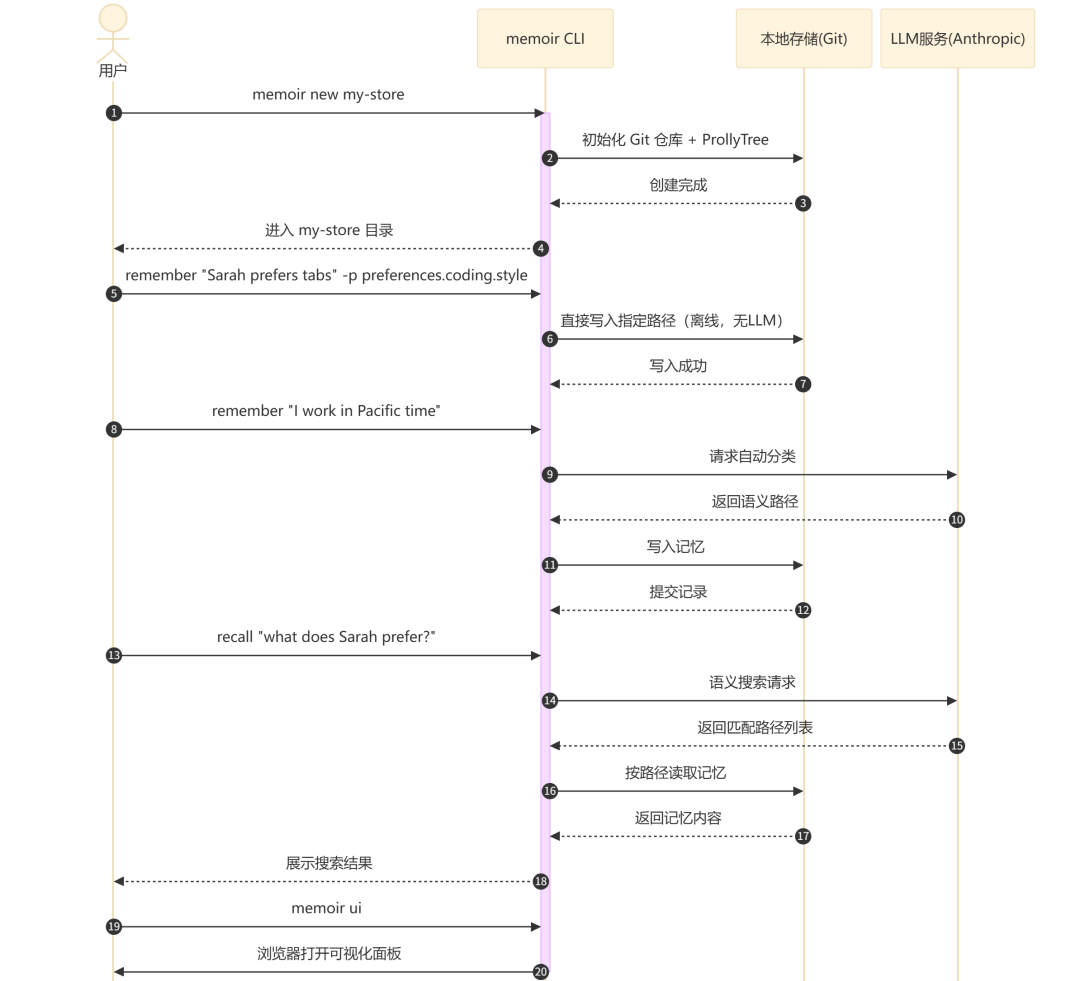
以下命令演示上述完整流程:
# 1. 设置 API 密钥(Memoir 默认使用 Anthropic Claude Haiku 4.5)
export ANTHROPIC_API_KEY="sk-..."
# 2. 创建记忆仓库
memoir new my-memoir-store
cd my-memoir-store
# 3. 使用显式路径存储(离线操作,不消耗 LLM Token)
memoir remember "Sarah prefers tabs and 2-space indents" -p preferences.coding.style
# 4. 使用自动分类存储(需要 API Key,LLM 自动选择语义路径)
memoir remember "I work in Pacific time"
# 5. 按路径直接读取(离线,毫秒级响应)
memoir get preferences.coding.style
# 6. 自然语言语义搜索(LLM 驱动)
memoir recall "what does Sarah prefer?"
# 7. 打开可视化浏览器
memoir ui
4. 功能操作详解
4.1 记忆存储与检索
Memoir 提供三级检索管道,按查询的开放程度选择:
memoir get — 精确路径查找
当你明确知道记忆的语义路径时,使用 get 命令实现 <10ms 的离线查找。支持批量查询:
# 单条查询
memoir get preferences.coding.style
# 批量查询
memoir get preferences.coding.style profile.professional.skills
# 指定命名空间
memoir --json get preferences.coding.style -n default
memoir recall — 自然语言语义搜索
核心搜索入口,接受自然语言查询并返回排序结果。支持两种搜索模式:
# 单阶段模式(默认):一次 LLM 调用,通常 500-800ms
memoir recall "我的测试环境配置是什么?"
# 分层下钻模式:2-3 次 LLM 调用,更窄的提示词,典型 1-2s
memoir recall "我的测试环境配置是什么?" --mode tiered
# 指定命名空间和结果上限
memoir recall "meeting notes" -n calendar -l 5
# 设置相关性阈值(0.0-1.0)
memoir recall "programming languages" --threshold 0.5
--json 输出会暴露每阶段的性能观测数据,对 Agent 调用方和自动化脚本极为友好:
memoir --json recall "testing setup" --mode tiered \
| jq '.memories[0].metadata | {mode, step_timings}'
memoir summarize — 分类法结构巡检
纯计算操作,不调用 LLM,用于了解记忆仓库的布局结构:
# 全仓概览
memoir summarize
# 仅显示分类结构,限定命名空间
memoir summarize taxonomy -n default
# 按 glob 模式匹配键
memoir summarize --keys "preferences.*"
# 顶层前缀直方图(L1 概览)
memoir summarize --depth 1
# glob + 深度组合:preferences.* 下的 L2 拆分
memoir summarize --keys "preferences.*" --depth 2
检索命令选择指南:
| 场景 |
推荐命令 |
原因 |
| 知道确切路径 |
memoir get |
离线,<10ms |
| 自然语言查询 |
memoir recall |
LLM 理解语义 |
| 大规模仓库查准 |
memoir recall --mode tiered |
分层下钻减少遗漏 |
| 查看仓库结构 |
memoir summarize |
纯计算,无 LLM |
| Agent 脚本编程 |
summarize + get 组合 |
避免嵌套 LLM 调用 |
4.2 版本控制与分支管理
Memoir 的版本控制能力是其区别于所有其他记忆系统的核心特性。它不仅记录记忆内容的变化,还支持 Git 原生的分支、提交、合并和时间旅行。
分支操作命令一览:
# 创建新分支(隔离实验性记忆修改)
memoir branch create experiment_new_classifier
# 切换到指定分支
memoir branch checkout experiment_new_classifier
# 查看所有分支
memoir branch --help # 列出可用子命令
# 合并分支
memoir branch merge experiment_new_classifier
# 时间旅行:回到历史任意提交点
memoir branch checkout <commit-hash>
# 查看分支间差异
memoir branch diff main experiment_new_classifier
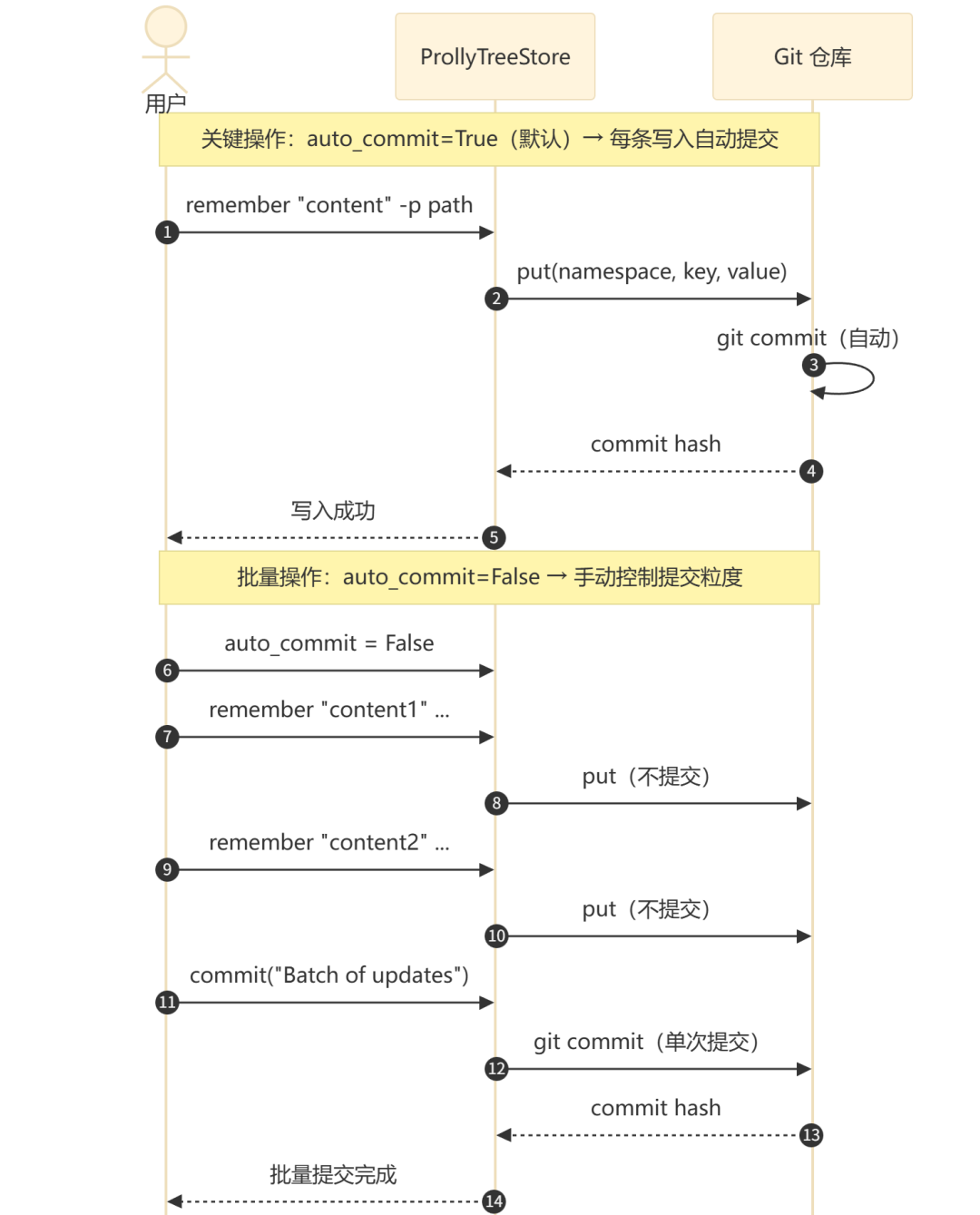
细粒度提交控制(Python SDK):
from memoir.store.prolly_adapter import ProllyTreeStore
# 传统模式:每次操作自动提交(默认,向后兼容)
store = ProllyTreeStore(path="./store", auto_commit=True)
store.put(namespace, key, value) # 立即自动提交
# 批量模式:手动控制提交粒度
store = ProllyTreeStore(path="./store", auto_commit=False)
store.put(namespace, key1, value1) # 不提交
store.put(namespace, key2, value2) # 不提交
store.put(namespace, key3, value3) # 不提交
commit_hash = store.commit("批量导入用户偏好") # 一次提交
# 混合模式:关键操作即时提交,批量操作延迟提交
store.auto_commit = True
store.put(namespace, critical_key, value) # 立即提交
store.auto_commit = False
store.put(namespace, batch_k1, v1)
store.put(namespace, batch_k2, v2)
store.commit("批量常规更新")
store.auto_commit = True # 恢复自动提交
4.3 可视化浏览器(UI)
Memoir 内置了一个基于 D3.js 的 Web 可视化浏览器,提供四种视图和一个 7 维度统计面板。
启动方式:
# 连接到已有仓库
memoir ui /path/to/store
# 启用语义搜索(UI 的命令输入支持自然语言搜索)
memoir ui /path/to/store --usellm
# 自定义端口(默认 8080)
memoir ui /path/to/store --port 8081
服务器绑定在 http://localhost:8080 并自动打开浏览器。在启动 Shell 中按 Ctrl-C 停止服务。
UI 布局:
页面由三个固定区域和一个浮动命令输入框组成:
| 区域 |
功能 |
| 顶部栏(左) |
分支选择器,切换当前分支 |
| 顶部栏(中) |
当前连接的仓库路径 |
| 顶部栏(右) |
视图切换器:Tree / Graph / Timeline / Places |
| 主画布 |
渲染当前选中的视图 |
| 底部命令输入 |
输入 / 打开斜杠命令菜单,纯文本触发搜索 |
四种视图:
| 视图 |
内容 |
适用场景 |
| Tree |
层级文件夹式记忆路径树 |
深入了解某个分类、确认语义路径存在 |
| Graph |
力导向节点图,边连接父子路径 |
一瞥之下理解仓库组织、发现过宽或孤立分类 |
| Timeline |
按时间排序的提交历史,可展开查看差异 |
回顾最近活动、审计两个时间点之间的变化 |
| Places |
按位置元数据分组记忆 |
跨项目/仓库的记忆汇总 |
/stats 统计面板:
在命令输入框中输入 /stats 会打开一个 7 标签页的模态窗口:
| 标签页 |
内容 |
| Overview |
顶层计数:总记忆数、提交数、分支数、命名空间数 |
| Codebase |
codebase:onboard 快照(通过 /memoir:onboard 填充时) |
| Tree Structure |
每层分类树的深度、分支因子、叶节点数量 |
| Version Control |
每个分支的提交数、合并历史、HEAD 位置 |
| Performance |
分类和搜索延迟、缓存命中率 |
| Classification |
记忆在分类体系中的分布 |
| Content Analysis |
每条记忆的大小、Token 数、内容类型分析 |
4.4 Python SDK 编程接口
对于需要编程式接入的场景,Memoir 提供了完整的 Python SDK。
初始化组件:
import os
from memoir.llm import get_llm
from memoir.store.prolly_adapter import ProllyTreeStore
from memoir.classifier.intelligent import IntelligentClassifier
from memoir.search.intelligent import IntelligentSearchEngine
from memoir import ProllyTreeMemoryStoreManager
# 配置 LLM
os.environ["ANTHROPIC_API_KEY"] = "your-api-key-here"
llm = get_llm(model="claude-haiku-4-5", temperature=0)
# 创建存储层
store = ProllyTreeStore(
path="./memory_store",
enable_versioning=True
)
# 创建智能分类器
classifier = IntelligentClassifier(
llm=llm,
confidence_thresholds={
"high": 0.8,
"medium": 0.5,
"low": 0.0
}
)
# 创建搜索引擎
search_engine = IntelligentSearchEngine(llm=llm, store=store)
# 组装记忆管理器
memory_manager = ProllyTreeMemoryStoreManager(
prolly_store=store,
classifier=classifier,
search_engine=search_engine
)
存储与搜索记忆:
# 存储记忆(自动分类)
await memory_manager.store_memory(
content="I work as a senior software engineer at TechCorp",
namespace="user123",
metadata={"source": "conversation", "confidence": 0.95},
auto_classify=True
)
# 记忆将自动分类到语义路径,例如:
# profile.identity.name.first
# profile.demographics.age
# profile.professional.occupation.role
# 自然语言搜索
results = await memory_manager.search_memories(
query="What is the user's job?",
namespace="user123"
)
for result in results:
print(f"Found: {result.content}")
print(f"Path: {result.id}")
5. 配置与定制
5.1 基础配置
环境变量:
| 变量 |
作用 |
必需 |
ANTHROPIC_API_KEY |
Anthropic API 密钥(默认使用 Claude Haiku) |
是(使用 LLM 功能时) |
MEMOIR_LLM_MODEL |
设置默认使用的 LLM 模型 |
否 |
MEMOIR_STORE |
默认仓库路径,避免每次传 -s |
否 |
MEMOIR_JSON |
设为 1 则全局输出 JSON 格式 |
否 |
MEMOIR_QUIET |
设为 1 则抑制非必要输出 |
否 |
OPENAI_API_KEY |
OpenAI API 密钥(使用 GPT 模型时) |
否 |
模型选择优先级(从高到低):
- 最高:
--model 命令行参数
- 其次:
MEMOIR_LLM_MODEL 环境变量
- 最后:默认值
claude-haiku-4-5
模型覆盖示例:
# 单次调用使用 GPT-4o-mini(需要 OPENAI_API_KEY)
memoir recall "..." --model gpt-4o-mini
# 全局切换为 Sonnet
export MEMOIR_LLM_MODEL=claude-sonnet-4-5
# 使用本地 Ollama 模型
export MEMOIR_LLM_MODEL=ollama/llama3
5.2 高级配置与扩展
自定义分类置信度阈值:
classifier = IntelligentClassifier(
llm=llm,
confidence_thresholds={
"high": 0.9, # 高置信度直接存储
"medium": 0.7, # 中等置信度标记审查
"low": 0.0 # 低于此值拒绝分类
}
)
自定义分类体系(Markdown 数据源):
from memoir.taxonomy.loader import TaxonomyLoader
from memoir.taxonomy.markdown_source import MarkdownTaxonomyDataSource
loader = TaxonomyLoader(store=store)
loader.load_from_source(
MarkdownTaxonomyDataSource("/path/to/medical_taxonomy.md")
)
缓存大小调优:
# 默认 10,000 条,可根据内存环境调整
store = ProllyTreeStore(
path="./memory_store",
cache_size=50000 # 提升至 5 万条
)
全局 CLI 标志:
| 标志 |
效果 |
-s, --store <PATH> |
覆盖仓库路径(优先于 MEMOIR_STORE) |
--json |
所有子命令输出机器可读 JSON |
-q, --quiet |
抑制非必要输出 |
-v, --verbose |
启用详细日志 |
6. 使用技巧与最佳实践
- 显式路径优先于自动分类:如果你明确知道一条记忆应该放在哪个路径下,使用
-p 参数显式指定,既节省 Token 又保证分类准确性
- 关键记忆即时提交,批量更新延迟提交:利用
auto_commit 开关实现混合提交策略,既保证关键变更不丢失,又保持 Git 历史的整洁
- 使用命名空间隔离多用户/多项目:每个用户或项目使用独立命名空间(如
user123、project-alpha),避免记忆交叉污染
- 调试前先创建分支:在排查问题或尝试修复前,用
memoir branch create debug_xxx 创建调试分支,修改满意后再合并回主分支
- 定期用
summarize 巡检分类体系:通过 memoir summarize --depth 1 快速了解记忆分布是否均衡,避免某些路径过度膨胀
- 机器可读场景始终加
--json:Agent 调用、脚本管道、性能基准测试时,使用 --json 输出确保可解析性
- 时间旅行先在分支上验证,再决定是否合并:
memoir branch checkout <commit> 回到历史状态后,先创建新分支进行修复,确认无误后再合并到主线
- 借助标准 Git 工具辅助审计:Memoir 仓库底层是标准 Git 仓库,你可以在仓库目录中直接使用
git log、git diff、git show 等命令查看记忆演变历史
- 迁移现有向量数据库时注意命名空间规划:将旧系统的每条记录通过
remember() 重放时,设计好命名空间映射方案,避免所有数据挤在同一个命名空间
7. 常见问题与故障排除
Q: 安装后运行 memoir 提示命令未找到
检查 uv tool list 或 pip list 确认 memoir-ai 已安装。如果使用 uv,确保 ~/.local/bin 在 PATH 中。
Q: 运行 memoir recall 时报 LLM 错误
检查 ANTHROPIC_API_KEY 或 OPENAI_API_KEY 环境变量是否正确设置。可以用 env | grep API_KEY 验证。
Q: 记忆分类不准确怎么办
有三种修正方式:
- 使用
-p 参数手动指定路径
- 调整
confidence_thresholds 提高 LLM 分类门槛
- 通过
memoir forget <path> + memoir remember "..." -p <正确路径> 手动迁移
Q: 仓库占用空间过大
定期清理旧版本和已废弃的分支。由于 Memoir 使用 ProllyTree 的结构化共享存储,相似记忆不会重复占用空间。如果仍需压缩,可用标准 Git 命令 git gc 回收垃圾。
Q: 如何备份和恢复
三种策略:
- Git 备份:在仓库目录中添加 remote 并 push 所有分支
- 导出重放:用
store.export_namespace() 导出到 JSON,在新仓库中重放
- 文件系统备份:用
rsync 在仓库未写入时复制整个目录
恢复时只需 memoir new <restored_path> 或直接用 memoir connect <backup_path> 连接备份。
Q: 是否可以与传统向量数据库共存
可以。Memoir 不排斥向量数据库。对于需要高密度语义匹配的场景,可以将 Memoir 作为结构化记忆层、向量数据库作为非结构化检索层,两者互补。
Q: Git 命令行操作会破坏数据吗
虽然底层是标准 Git 仓库,直接使用 git commit 或 git reset 可能破坏 Memoir 的数据一致性。建议只读使用(git log、git show、git diff),写入操作始终通过 Memoir 的 CLI 或 SDK。
8. 实战案例
案例一:用时间旅行调试 Agent 分类错误
场景:你的文本分类 Agent 将“I love Python programming”错误分类到 personal.hobbies.python,实际应为 profile.professional.skills.python。
传统做法的问题:需要重建全部记忆数据(数小时),或编写复杂测试用例。无法精确复现导致错误的记忆快照。
Memoir 方案(分钟级解决):
# 0. 在发现 Bug 时,先创建检查点保护当前状态(可选但推荐)
memoir branch create bug_snapshot
# 1. 通过 time-travel 回到历史上的已知正常状态
# (假设你之前为关键操作节点创建了分支)
memoir branch checkout before_classification_bug
# 2. 在正常状态上创建调试分支,安全实验
memoir branch create debug_python_fix
# 3. 分析当时记忆状态
memoir recall "python programming professional" --mode tiered
# 4. 发现根因:存在冲突记忆 “programming is hobby”
# 修正:移除错误分类,写入正确记忆
memoir forget personal.hobbies.python
memoir remember "Python programming is a professional skill" \
-p profile.professional.skills.python
# 5. 验证修复后切回主线并合并
memoir branch checkout main
memoir branch merge debug_python_fix
案例二:Claude Code 代码建议偏差排查
场景:用户反馈 Claude Code 反复建议 React 而非 Vue,怀疑记忆中存在框架偏见。
Memoir 方案:
# 1. 创建调试分支,隔离实验不影响主 Agent
memoir branch create debug_react_bias
# 2. 检索前端框架相关记忆
memoir recall "frontend framework preferences"
# 3. 确认根因:Agent 从 React 重型仓库中学到了偏见
# 修复:写入用户偏好
memoir remember "User prefers Vue.js for this project" \
-p preferences.frontend.framework
# 4. 验证修复效果后合并
memoir branch checkout main
memoir branch merge debug_react_bias
关键收益:整个排查-修复过程在主分支零风险的环境下完成,可回滚,可复现。
案例三:多 Agent 协作场景的记忆隔离
场景:同一项目中,编码 Agent 和测试 Agent 共享部分知识但需要独立记忆空间。
Memoir 方案:
# 共享仓库,不同命名空间
# 编码 Agent
await memory_manager.store_memory(
content="API schema uses snake_case",
namespace="coding_agent",
auto_classify=True
)
# 测试 Agent
await memory_manager.store_memory(
content="Test fixtures in fixtures/ directory",
namespace="test_agent",
auto_classify=True
)
# 跨命名空间的共识记忆(两个 Agent 都需要的)
await memory_manager.store_memory(
content="Project deadline: 2026-06-30",
namespace="shared",
auto_classify=True
)
9. 总结
- Memoir 不是“又一个向量数据库”,而是以 Git 版本控制为底层的 Agent 语义记忆系统,解决了上下文污染、Token 浪费和记忆漂移三大结构性痛点
- 安装极简:
uv tool install memoir-ai,CLI 即开即用;Claude Code 用户可零配置通过插件市场安装
- 核心操作闭环:
remember(存储)→ recall(搜索)→ ui(可视化),三条命令覆盖日常使用
- 版本控制能力(分支、提交、合并、时间旅行)是 Memoir 区别于所有现有 Agent 记忆方案的根本特征,它让记忆调试从“数小时重建”变为“毫秒级切换”
- Python SDK 采用依赖注入架构(Store → Classifier → SearchEngine → Manager),每一层可独立替换和扩展
- 适用场景:正在构建 AI Coding Agent 且遭遇记忆问题、需要可审计可回滚的记忆管理、需要多 Agent 共享记忆但保持隔离
- 不适用场景:纯非结构化语义搜索(向量数据库更合适)、不需要记忆历史版本追踪的简单场景
参考文献
[1] Memoir GitHub 仓库: https://github.com/zhangfengcdt/memoir
[2] Memoir 官方文档: https://zhangfengcdt.github.io/memoir/
[3] Memoir 快速入门指南: https://zhangfengcdt.github.io/memoir/quickstart/
[4] Memoir CLI 参考文档: https://zhangfengcdt.github.io/memoir/cli/
[5] Memoir 安装指南: https://zhangfengcdt.github.io/memoir/installation/
[6] Memoir 架构文档: https://zhangfengcdt.github.io/memoir/architecture/
[7] Memoir UI 文档: https://zhangfengcdt.github.io/memoir/ui/
[8] Memoir 示例文档: https://zhangfengcdt.github.io/memoir/examples/
[9] Memoir FAQ: https://zhangfengcdt.github.io/memoir/faq/
 发表于 2026-5-11 18:32:53
|
查看: 95|
回复: 0
发表于 2026-5-11 18:32:53
|
查看: 95|
回复: 0
