“做一个 AI Agent”——这个需求大概已经躺在不少人的待办列表里了。但翻看资料时,我们常会感到困惑:学术论文门槛太高,而营销文案又往往浮于表面。至于“Agent内部到底如何运转、该关心哪些环节”这类实操问题,却鲜有系统性的解答。
这篇文章希望填补这一空白。我们将从用户输入“帮我订机票”开始,一步步拆解Agent内部的工作流程,看看从接收到指令再到最终执行,中间到底发生了什么。通过理解Chain-of-Thought、ReAct和工具调用这三种核心机制是如何协作的,你或许能更清晰地规划自己的Agent项目。
第一部分:打破“黑盒”
设想一个最简单的场景:用户发出一条指令,AI Agent接收后,给出答案或执行一个动作。在向领导或客户做演示时,我们展示的流程往往就是这样:
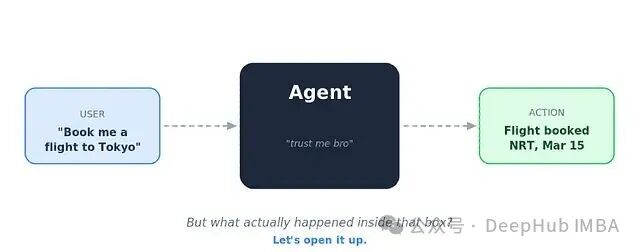
这种“黑盒”展示在Demo阶段没问题。但一旦要将其投入实际产品,麻烦就来了。系统迟早会出现故障,而如果你无法描绘其内部流程,就无从调试、无法定位问题根源、更无法制定有效的验收标准。
画不出Agent的内部流程,就没法调试、没法圈定范围、也没法写验收标准。“黑盒”是我们的敌人。
第二部分:思维链 (Chain-of-Thought)
打开黑盒,最简单的架构便是Chain-of-Thought (CoT)。模型接收到输入后,会将问题分解成一系列推理步骤,然后像链条一样,一个接一个地顺序执行,直到得出最终结论。在这个过程中,没有工具调用,也没有外部请求,只有纯粹的、串行的“内心戏”。
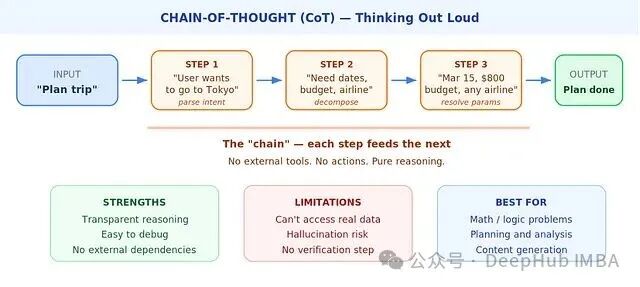
“链”是这里的核心概念。每一步的推理,都以前一步的输出作为上下文:第二步知道第一步的结论,第三步则建立在前两步之上。模型本质上是在跟自己对话,并沿途留下可以被回溯的逻辑痕迹。
这种架构的优点是显而易见的:透明(每个推理步骤都可读)、快速(无外部API调用,延迟低)、经济(通常只需一次扩展输出的LLM调用)。但它也有明显的局限性:模型无法访问训练数据及当前对话上下文之外的任何实时信息。
当答案完全蕴含在已有的上下文窗口中时,Chain-of-Thought是最佳选择。一旦任务需要获取实时数据——比如股票报价、日历查询或数据库检索——纯CoT就无能为力了。
第三部分:ReAct (Reasoning + Acting)
ReAct,即“推理(Reasoning)+ 行动(Acting)”,正是为了弥补CoT的短板而生。它允许模型在推理过程中与外部世界进行交互。流程不再是直线式的“想完再答”,而是形成了一个循环:思考 -> 执行动作 -> 观察结果 -> 带着新信息重新思考。
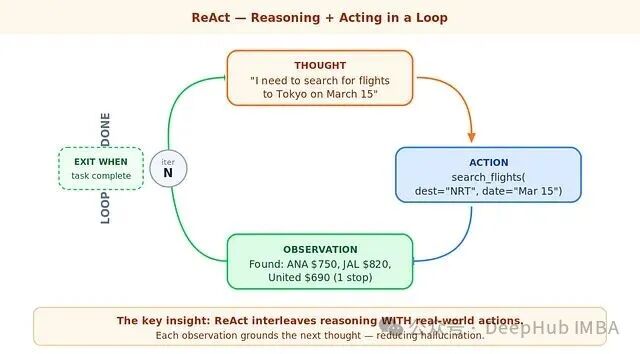
正是这套架构让AI Agent产生了所谓的“魔法感”。模型不再仅仅是凭空制定一份旅行计划——它会去搜索航班、读取返回的结果、注意到最低价有一次中转、然后判断用户可能更偏好直飞,进而重新搜索直飞航班。每一次对真实世界的观察,都将下一轮的思考“锚定”在事实之上,而非模型的想象。
优势是显著的:每一轮迭代都用真实数据替换了可能的臆测;Agent能够根据中间发现及时调整策略;完整的“Thought-Action-Observation”链路本身就是一份清晰的决策日志。但代价也随之而来:每多一轮循环,就多一次工具调用带来的延迟;迭代次数越多,循环跑偏或在某个步骤失败的风险也越大。
循环迭代次数是最关键的调优参数之一。设得太少,Agent可能还没完成任务就提前放弃了;设得太多,Token消耗和预算会一起飙升。建议从5次左右的上限开始,再根据实际线上数据进行调整。
工具,是将一个聊天机器人升级为真正AI Agent的关键分界线。通过接入工具,LLM可以搜索网页、查询数据库、发送邮件、甚至运行代码。但必须明确一点:LLM本身并不直接“动手”,它只负责“动脑”——生成一个结构化的调用请求(通常是JSON格式),然后交由一个独立的“执行器”去处理。
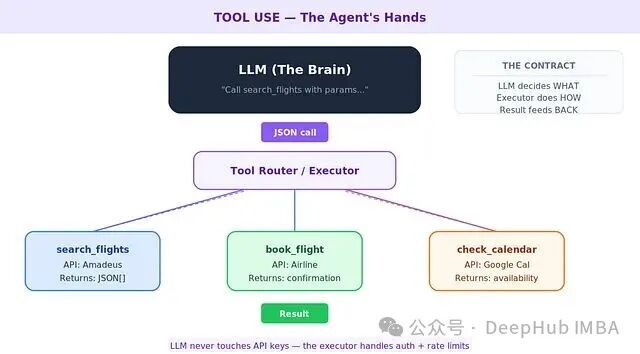
这种职责分离至关重要。LLM负责决策(选择哪个工具、传递什么参数);执行器负责执行(调用函数、处理鉴权、管理速率限制、格式化返回结果)。执行结果再回传给LLM,供其进行下一步推理。
这样一来,LLM永远不会直接接触敏感的API密钥或凭证。系统提示词中对工具的描述,本质上是一份写给AI看的“产品说明书”。描述写得好坏,直接决定了LLM的选择是否正确——垃圾进,垃圾出。同时,每一次工具调用本身都是一个潜在的故障点:网络超时、鉴权失败、返回格式异常,都可能导致整个流程中断。
工具描述本质上是写给AI看的产品文案。撰写时,想象一个聪明但极度较真的新人在阅读:这个工具是做什么的?在什么场景下该用它?它会返回什么?什么时候不该用它?——这些都要清晰无误地交代清楚。
那么,在工具调用的过程中,Chain-of-Thought还在发挥作用吗?答案是肯定的。CoT与工具使用并非互斥,而是协同关系。CoT是让工具调用正确发生的“推理引擎”。LLM在输出JSON调用请求之前,往往会在一个内部或“隐藏”的CoT草稿区进行推理:“用户要订去东京的机票,我需要先确认日期,然后调用search_flights工具。” 先想清楚(CoT),再动手(工具调用)。而ReAct所做的,正是将“想”和“做”这两步串联成一个可循环的流程。
早期,我们可能需要手动在系统提示词里写上“think step-by-step”来迫使模型进行推理。现在,许多前沿模型——如OpenAI的o1系列、Anthropic的最新版Claude、Google的Gemini——已经将这种分步推理能力原生嵌入架构,在决定输出或调用工具前,会自动进行内部推演。
第五部分:如何选择你的架构?
那么,在实际项目中,我们究竟该选择哪种架构呢?在生产环境中,成熟的AI Agent几乎都是混合了上述多种架构元素的综合体。但其中主导的模式,将直接决定系统的延迟、成本和故障特征,因此选择至关重要。
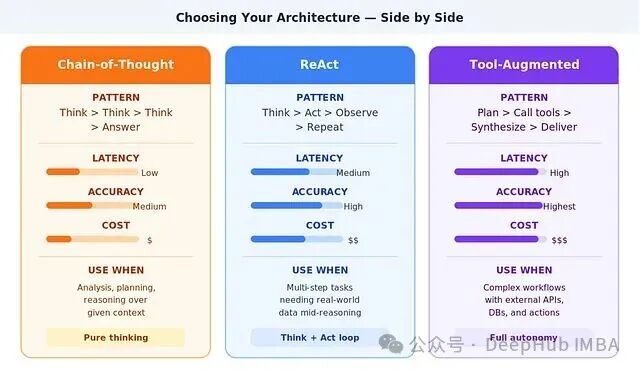
一个简单的规律是:自主性越高,准确性和能力通常越好,但延迟、成本和潜在的出错面也同步上升。一个仅做文档摘要的CoT Agent,又快又省;而一个需要横跨航班、酒店、租车等多个API完成预订的“工具增强型”Agent,能力强大,但代价也高。
在选择时,可以遵循一个逐步升级的思路:
- 从纯CoT开始:如果你的任务是对已有的、自包含的上下文进行推理(如分析、总结、规划),且不需要外部信息,那么纯Chain-of-Thought是最简单高效的选择。
- 引入ReAct:当Agent在推理过程中需要获取外部实时数据来辅助决策或验证事实时(如查询天气、股价),加入只读工具,切换到ReAct模式。
- 采用工具增强架构:当Agent必须执行具有现实后果的操作时(如下单、发送邮件、修改数据库),就需要使用读写工具,走上完全的工具增强路线。
核心原则是:选择能够解决问题的、最简单的架构。 工具随时可以后续添加,但由复杂架构带来的系统复杂性和用户期望,一旦形成就难以缩减。
核心思维模型
最后,我们可以用一个思维模型来概括这一切:“一个AI Agent,本质上就是一个带有特定目标的循环——而我们的工作,就是决定这个循环拥有多大的自主权,以及它应该在何时终止。”
这句话几乎概括了所有架构决策。Chain-of-Thought是只有一轮“思考”的循环;ReAct在循环里加入了“行动”;而工具增强型Agent则为这个循环装上了触及并改变外部世界的“手”和“脚”。每一个关于架构的选择,归根结底都是在调控这个循环的自主权边界和终止条件。
希望这篇从AI Agent基础架构入手的解析,能帮助你更好地理解其内部机制,从而在设计和实现自己的Agent时,做出更明智的决策。如果你想与其他开发者交流更多关于智能体开发的心得,欢迎来云栈社区看看。
 发表于 2026-3-28 05:02:10
|
查看: 129|
回复: 0
发表于 2026-3-28 05:02:10
|
查看: 129|
回复: 0
