本文分享了天猫团队在“胶水编程”场景下的最佳实践,即利用AI高效连接现有业务模块以快速响应需求,实现了高达97.9%的代码采纳率。文章指出,针对业务逻辑组装、接口对接及样板代码填充等“胶水”型任务,通过构建精准的上下文提示策略和标准化的开发流程,能极大发挥AI在理解业务意图和组合代码片段上的优势,显著缩短从需求到上线的周期;该实践证明了在特定高匹配度场景下,AI不仅能大幅减少人工编码工作量,还能保持极高的代码可用性与一致性,是业务需求快速交付的高效路径。

实践背景
试点业务域半年前采纳率 50%——不是 AI 写不出代码,而是写出来的代码不可控:组件乱用、规范不守、已知的坑反复踩。核心认知只有一条:别让 AI 写代码,让它抄代码。 把团队已有的开发规范、代码模式、领域知识喂给 Agent,让它组装而非创作——这套方法我们叫"胶水编程"。SPEC 管意图,物料管执行,两者叠加才是完整的可控编码。
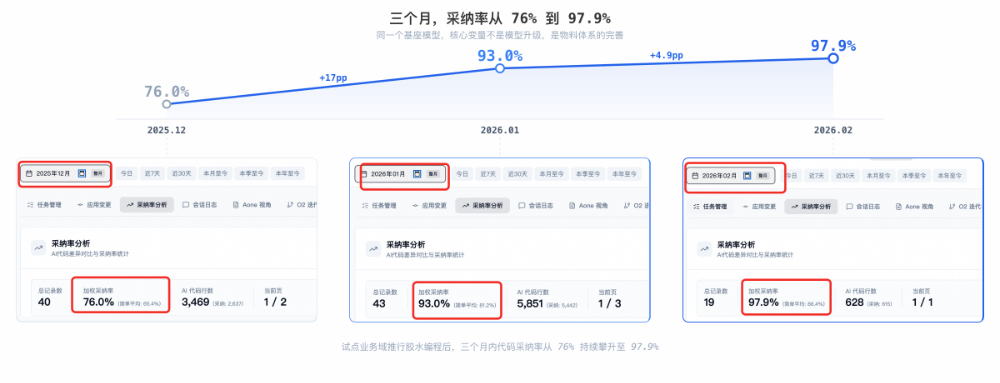
下图是某大型电商平台一个全栈化试点业务域的真实数据(采纳率口径:以周期内所有 CR 合并上线的代码总行数为分母,其中由 AI 生成的行数为分子,按行级加权统计——不按迭代平均,避免大小迭代失真。

胶水编程:企业可控编码的设计哲学
胶水编程的核心主张:与其优化SPEC 让 AI 写得更好,不如直接给它好的东西来抄。胶水编程针对的正是"怎么做"这一层:SPEC 管意图,物料管执行,两者叠加才是完整的可控编码。
效果有多直观?同一个订单列表页需求,看两份 Agent 产出的代码:

两份代码功能完全一样,组件也都用对了。差异全在“你给了 Agent 什么”。
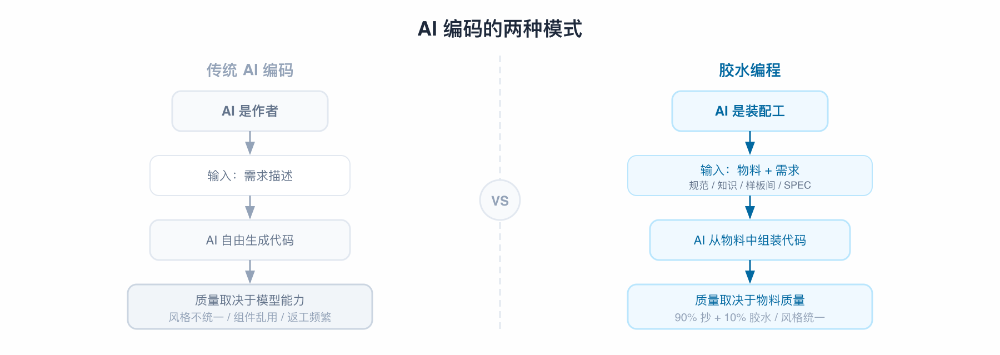
核心理念:AI 不应该“写(SPEC)”代码,而应该“抄(GLUE)”代码
中后台业务有一个显著特征:绝大部分需求以 CRUD 为基础——列表页、表单页、详情页、导入导出,场景高度相似。这意味着团队代码库中天然存在大量可复用的模板化代码:上一个列表页的文件结构、组件选型、请求封装,下一个列表页几乎可以原样复制,只需替换业务字段和接口地址。既然 90% 的代码本来就有现成的参照,为什么还要让 AI 从零写?
这个假设转变有一个底层的技术直觉:大语言模型的核心训练目标是根据已有信息预测下一个 token——这使得它在有参照物时表现显著优于无参照物时。当你给它一份已有的代码作为参照,它能精准地拟合出风格一致的新实现;
胶水编程不是在限制 AI,而是在顺应它的能力结构——让AI做拟合的事。能抄不写,能连不造,能复用不原创。团队积累的已有项目代码、组件库、编码规范、历史经验,就是我们的“轮子”。Agent 的工作不是从零创作,而是从内部物料中组装出新的交付,只在业务差异点写最少量的“胶水代码”——90%抄,10%写,胶水只在缝隙处。
为什么企业需求交付需要比 SPEC/SDD 更具体的方案
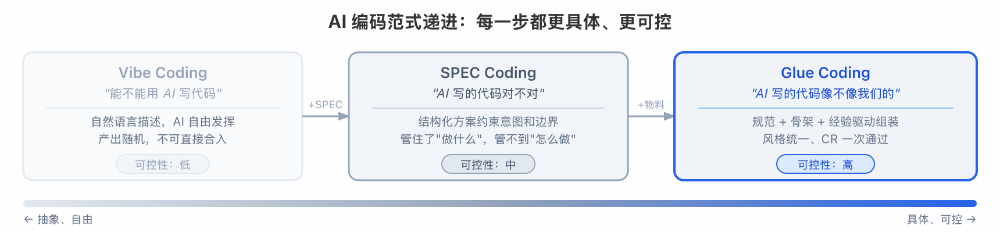
AI 编码的可控性是逐步递进的,每一步都比上一步更具体、更可控:
- Vibe Coding 解决了“能不能用 AI 写代码”。 用自然语言描述需求,AI 直接生成代码。探索原型够用了,但产出完全不可控——风格随机、质量看运气,不可能直接合入生产仓库。
- SPEC Coding 解决了“AI 写的代码对不对”。 用结构化的技术方案约束 AI 的行为:做什么、不做什么、验收标准是什么。可控性显著提升,但 SPEC 管的是意图和边界,管不到具体实现——Agent 知道要写一个列表页,但不知道你们团队的列表页长什么样。
- Glue Coding 解决了“AI 写的代码像不像我们的”。 在 SPEC 的基础上,再给 Agent 三样东西:开发规范(规矩)、代码模式(骨架)、领域知识(经验)。Agent 不再从零创作,而是照着团队已有的代码去抄,只在差异点写胶水。产出的代码风格统一、组件正确、CR 一次通过。
三者是递进关系:Vibe 让 AI 能写代码,SPEC 让 AI 写对代码,Glue 让 AI 写出‘你的’代码。 企业中后台要的恰恰是最后这一步——不只是能跑,还必须像团队自己写的一样,能合入、能 CR 通过。
《Spec Coding 不是银弹》一文指出了 SPEC 编码的三个结构性局限:AI 缺乏真正的理解能力、规范无法完整描述系统、规范比代码更难维护。胶水编程的物料体系正是在这个认知基础上的工程补全——领域知识补上业务语义理解,代码模式补上“规范无法描述”的具体实现,Track + 规格同步缓解规范与代码的同步维护负担。
这个转变意味着什么
- 投资方向变了。 核心投资不再是 prompt 工程或等待更强的模型,而是建设内部物料体系(让单次交付可控)和需求规格的持久化管理(让长期迭代可控)。
- 质量标准变了。 好的 AI 编码不是“生成了多少代码”,而是“原创了多少代码”——在可标准化的部分, 原创越少,说明物料体系越完善,产出越可控。
- 团队资产观变了。 已有项目代码是可复用的样板间资产,已完成的需求规格是后续需求的决策上下文——每一次交付都在积累物料和上下文,形成复利效应。

具体落地:让 Agent “有东西可抄”
胶水编程不是一句口号,它需要一套具体的物料体系来支撑。这套体系要回答的核心问题是:Agent 写一段代码,到底需要哪几类物料?
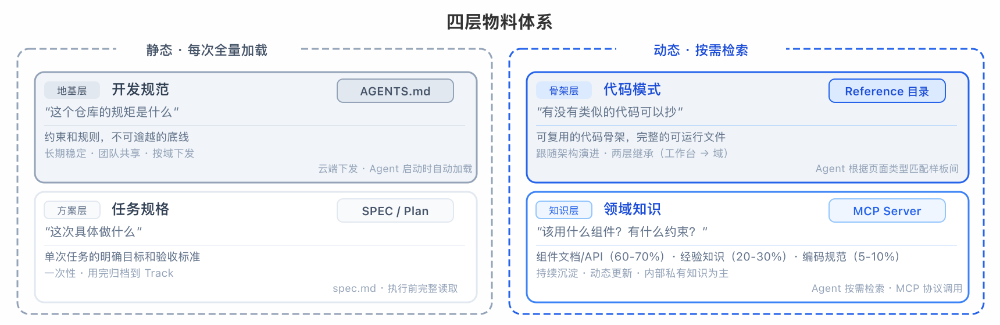
Agent 写代码时,背后有四个彼此独立的决策:做什么(意图)、什么不能做(约束)、代码长什么样(结构)、有什么要注意的(经验)。它们的独立性体现在——答对任何一个,不保证其他三个也对:Agent 可以理解需求但违反了团队禁用某依赖的规矩(缺开发规范),可以守规矩但文件组织混乱(缺代码模式),可以结构规整但踩了内部组件的坑(缺领域知识)。四种失败模式互不重叠,每一层物料恰好堵一个,少一层多一种漏洞。对应到我们的实践中,这四层物料分别是:任务规格(这次做什么)、开发规范(规矩是什么)、代码模式(抄什么)、领域知识(有什么约束)。
物料怎么喂给 Agent:分层注入,而非一股脑塞进去
开发者不需要感知物料是怎么注入 Agent 上下文的——他输入的只是一句自然语言需求:“帮我做一个订单列表页”,背后的上下文组装由系统完成。
四层物料按加载方式分为两类:静态注入的物料每次 Agent 编码时全量加载,确保关键规则始终在场;动态检索的物料由 Agent 在编码过程中按需拉取,避免上下文过载。我们的编码工具以 VS Code 插件为主要载体(同时支持 Web 端),以下机制基于插件的 Agent 运行环境实现:
| 物料层 |
加载方式 |
技术机制 |
触发时机 |
| 开发规范 |
静态注入 |
云端配置 → 自动生成 AGENTS.md → 注入 system prompt |
打开仓库时自动加载 |
| 代码模式 |
静态注入 |
样板间代码文件通过提示词引用注入 Agent 上下文 |
打开仓库时自动加载 |
| 领域知识 |
动态检索 |
Agent 通过 MCP 协议调用 knowledge Server 按需检索 |
编码过程中按需触发 |
| 任务规格 |
动态生成 |
开发者选择 SPEC 模板 → 填写 → 生成 spec.md 作为初始上下文 |
每次需求启动时生成 |
前两层(开发规范、代码模式)是“始终在场”的背景知识——Agent 每轮对话都能看到,不需要做“要不要查”的决策。后两层则在编码过程中按需介入:领域知识由 Agent 遇到具体问题时主动检索,任务规格由开发者在需求启动时编写并注入。
为什么开发规范必须静态加载?因为当前模型在“主动决定要不要查文档”这件事上表现很差——Vercel 的评测显示,56% 的场景中 AI 根本不会主动调用文档工具;而将同样的内容直接写入 AGENTS.md 静态加载后,通过率从 53% 提升到 100%。关键规则必须始终在场,不能依赖 AI 的主动调用。
为什么不把所有物料一次性全塞进去?Anthropic 上下文工程博客给出了直接的答案:“一个精准的 300 token 上下文,往往胜过一个混杂的 113,000 token 上下文。” Chroma 的 Context Rot 研究也验证了这一点:在 18 个 SOTA 模型的测试中,上下文越长,安全特性实现反而下降了 47%。四层物料按加载时机精确投放——静态的全程在场,动态的按需召回——本质上是在用最少的 token 传递最高密度的信号。
开发规范(规则文件)— 规矩层:“这个仓库的规矩是什么?”
开发规范是仓库级别的编码约束,通过 AGENTS.md 文件交付给 Agent,是写代码的底线。
为什么它是“地基”?因为没有它,即使有代码模式和领域知识,Agent 也可能用错依赖、违反请求规范、选错组件库。开发规范定义的是不可逾越的约束,而非可选的建议。
来看两个真实仓库的开发规范(节选,完整规范远不止这些):
业务域 A(domain-a-service-management):
- 物料依赖:优先使用
@internal/admin-components,查包用法走 MCP 工具
- 请求规范:
hostMap.ts + serviceHost.ts 架构,URL 格式 key://pathname
- 组件规范:导入导出使用
FileExport / FileImport 标准用法
- 页面结构:参考已有同类型页面 + 物流模板仓库
业务域 B(domain-b-enquiry):
- 在通用规范上增加域特有约束:使用
@internal/supply-chain-libs 的 createFetch 系列
- 接口地址必须以
/开头(否则被网关拦截)
- 15+ 业务线映射表(
platform_code = 快递/自营等)
- 导入导出需额外传
businessCode: getBusinessCode()
两份开发规范结构高度一致(物料 → 请求 → 组件 → 页面结构),但业务域差异体现在具体的包名、业务概念和模板仓库。这正好说明了为什么需要“按域下发”——共性标准化,差异按域定制。
差异有多细微?看这个例子:
// 业务域 A 的文件导出
<FileExport code="GEI_CODE" data={() => ({ ...context.$searchForm?.getValues() })} />
// 业务域 B 的文件导出——就多了一行 businessCode
<FileExport code="GEI_CODE" data={() => ({
businessCode: getBusinessCode(),
...context.$searchForm?.getValues(),
})} />
差异只有一行,但如果 Agent 不知道这个约束,导出数据会错乱。这就是开发规范的价值——不是锦上添花,是底线约束。
我们的实践:技术视角 + 业务视角,自动识别并下发
开发规范不是“一个仓库一份规则”那么简单。同一个业务域,工作台 A 用的是 @internal/builder-carbon + @internal/admin-components,工作台 B 用的是 @internal/builder-sop + 完全不同的组件体系;同一个工作台,业务域 A 的请求走hostMap.ts,业务域 B 的请求走 createFetch。开发规范实际上由两个视角交叉决定:
- 业务视角(20+ 域):决定业务概念、接口规范、组件用法差异——业务域 A 有 hostMap 架构,业务域 B 有 businessCode 约束;
- 技术视角(5 种工作台):决定底层框架和组件库选型——工作台 A 用 @internal/admin-components,工作台 B 用 @internal/builder-sop,工作台 C 用 ice.config.mts。
通过云端域配置系统(agentDomainConfig),我们将技术视角和业务视角的规则管理搬到了线上。配置跟着仓库走,不跟人走:
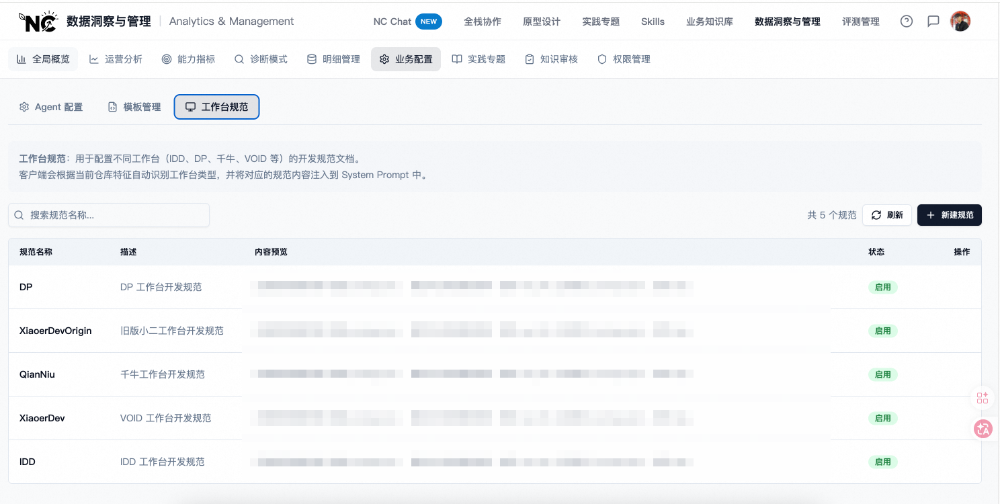
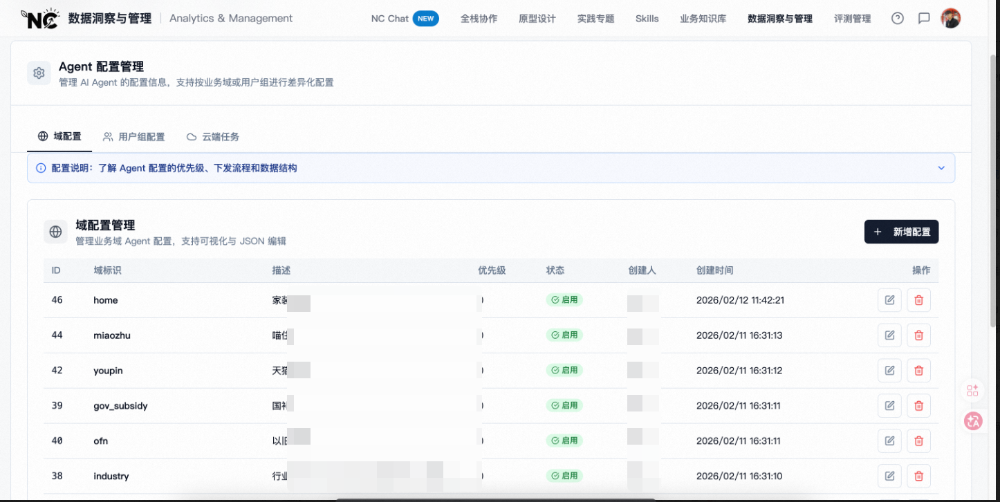
自动识别的技术实现是 Agent Hooks。开发者打开仓库代码时,系统触发 hook,读取仓库的 package.json、构建配置等信息,自动判断它属于哪个业务域、哪个工作台类型,然后通过三级匹配优先级(显式域配置 → 仓库规则匹配 → 用户组兜底)组装出对应的 AGENTS.md 并注入 Agent。整个过程对开发者透明——打开仓库就自动生效,无需手动配置。
这是我们与业界工具的关键差异点。Cursor Rules 的 glob 匹配、AGENTS.md 标准的目录层级、Copilot Instructions 的路径级指令,作用域都是基于文件路径的物理目录匹配。我们做的是业务语义级的自动路由——系统理解“业务域 E”在“工作台 A”上需要的规范,不同于“业务域 A”在“工作台 B”上的规范,并自动注入正确的上下文。
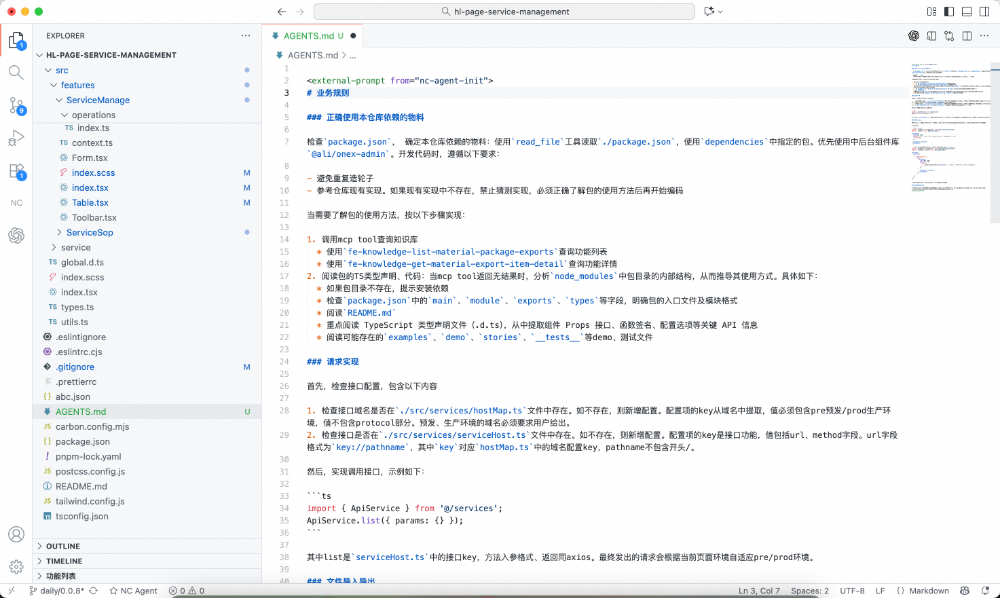
下图是一个实际下发到仓库的 AGENTS.md 示例。开发者打开某个业务域 A 工作台 A 的仓库后,系统自动识别并注入了该域的开发规范——包括物料导入路径约束(必须从 @internal/admin-components导入而非 antd)、hostMap 路由架构的使用方式、以及该域特有的接口请求模式和代码示例。开发者无需手动编写或维护这份文件,它完全由云端配置驱动、按仓库自动生成。
领域知识(知识库)— 知识层:“该用什么组件?有什么约束?”
领域知识层要填补的是 AI 模型最大的知识盲区:内部私有组件和平台约束。
一个常见的误解是,领域知识等于“踩坑经验集”。实际上,在日常业务开发中,踩坑经验只占很小一部分。真正的大头是内部组件文档。模型从公开训练数据中已经学会了 Ant Design、React 等公开库的用法,但对企业内部的私有组件完全无知——它不知道 @internal/admin-components 的 Table 和 Ant Design 的 Table 有什么区别,不知道该用哪个,更不知道怎么用。
判断一条知识是否属于领域知识层的标准很简单:模型能从公开资料获取吗?
@internal/admin-components 的 ProTable 怎么用?→ 不能 → 核心知识- 接口地址必须以
/ 开头否则被网关拦截?→ 不能 → 核心知识
- React useState 怎么用?→ 能 → 不需要放进知识库
- tsconfig 配置报错怎么解?→ 能 → 不是好的领域知识案例
我们的领域知识通过 knowledge MCP Server 统一接入,将分散的前端知识转换为 LLM 可调用的工具。内部知识分为三类——物料文档(组件 API、用法示例)占日常消费的 60-70%,经验知识(踩坑记录、技术决策)占 20-30%,开发规范(按域的编码规范)占 5-10%。
注意这个比例:物料文档占了六七成。Agent 写代码时最频繁的需求不是“有什么坑”,而是“这个组件怎么用”。
细心的读者会注意到,这里也有“开发规范”——和 3.2 节是什么关系?区别在于加载方式:3.2 节的规范通过 AGENTS.md 静态注入,是不可违反的底线规则;知识库里的规范是按需检索的补充参考,Agent 遇到具体问题时主动拉取。两者互补,不重复。
经验知识占比较小但单条价值高,通过自动沉淀机制积累(机制详见系列文章《知识基座》),目前已积累 167 条。
效果数据: 按调用率 × 采纳率定位低效知识条目——被频繁召回但采纳率只有 20%~30% 的条目逐一优化后,知识库关联采纳率从 18% 提升到 35%,近翻倍。
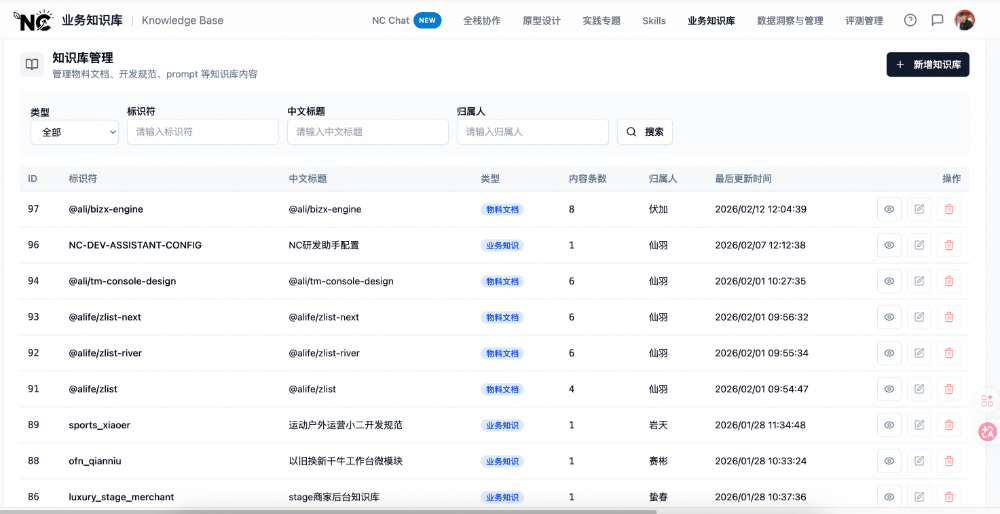
下图是知识库管理端的实际内容。可以看到,知识条目涵盖了组件物料文档( @internal/biz-engine、@internal/admin-components、@internal/zlist 系列)、工作台技术规范(@internal/console-design)、业务域专属规范(业务域 F、工作台 B、商家后台)等多种类型——这不是一个“踩坑经验集”,而是一套覆盖组件用法、平台约束、业务规则的综合知识体系。
代码模式(样板间)— 骨架层:“有没有类似的代码可以抄?”
代码模式是胶水编程的核心——给 AI 看一份 500 行的标准列表页,比写 50 条规则有效得多。它是从团队已有项目中提炼出的可复制代码骨架——不是文档,不是规则描述,是一套实际的、可运行的代码文件。
理解代码模式,关键是区分它和开发规范的本质不同:
- 开发规范 = 装修手册(“客厅应该朝南,用暖色调”)— 告诉 Agent 规矩是什么
- 代码模式 = 样板间(“进去看看客厅长什么样”)— 给 Agent 看代码实际长什么样
一个典型的列表页样板间:
├── index.tsx ← 页面入口,路由配置
├── Form.tsx ← 筛选表单,字段定义、校验、联动
├── Table.tsx ← 数据表格,列定义、操作栏
├── services.ts ← 接口定义,请求/响应类型
└── constants.ts ← 枚举、映射表
这不是代码片段,是一套完整的实现。Agent 直接复制这个结构,把业务字段替换掉,只在差异点写胶水代码。
这个差异在实际 CR 中看得最清楚。看一个真实场景:同样开发一个订单列表页,组件和请求方式都用对了(知识库 + 开发规范已生效),但没有样板间时,Agent 的代码组织方式跟团队习惯不一样:
// ❌ Without 样板间:功能正确,CR 打回
// 组件用对了(ProTable),请求规范守住了(createFetch),但——
export default function OrderList() {
// ↓ 状态管理:手写 useState,团队习惯用 useProTableRequest 一行搞定
const [filters, setFilters] = useState({});
const [data, setData] = useState([]);
const [loading, setLoading] = useState(false);
const fetchData = async (params) => { /* ... */ };
return (
<div>
{/* ↓ 筛选表单:内联在页面文件里,团队习惯拆到独立的 Form.tsx */}
<Form onFinish={v => { setFilters(v); fetchData(v); }}>
<Form.Item name="orderId" label="订单号"><Input /></Form.Item>
<Form.Item name="status" label="状态"><Select options={STATUS_OPTIONS} /></Form.Item>
<Button htmlType="submit">查询</Button>
</Form>
{/* ↓ 表格列定义:内联在页面文件里,团队习惯拆到独立的 Table.tsx */}
<ProTable
columns={[
{ title: '订单号', dataIndex: 'orderId' },
{ title: '金额', dataIndex: 'amount', render: v => `¥${v}` },
{ title: '操作', render: (_, r) => <a onClick={() => edit(r)}>编辑</a> },
]}
dataSource={data} loading={loading}
/>
</div>
);
}
有了样板间,同样的需求,Agent 的产出变成这样:
// ✅ With 样板间:CR 直接通过
// index.tsx — 只做组合,逻辑分散到各文件(与样板间结构一致)
import SearchForm from './Form'; // 筛选表单 → 独立文件
import OrderTable from './Table'; // 表格配置 → 独立文件
import { queryOrderList } from './services'; // 接口定义 → 独立文件
export default function OrderList() {
// ↓ 一行代替上面的 3 个 useState + fetchData
// formProps 怎么传给 SearchForm、tableProps 怎么传给 OrderTable → 样板间定义
const { tableProps, formProps } = useProTableRequest(queryOrderList);
return (
<PageContainer>
<SearchForm {...formProps} /> {/* 传什么 props、怎么联动 → 看样板间就知道 */}
<OrderTable {...tableProps} /> {/* 列定义、操作栏、分页 → 都在 Table.tsx 里 */}
</PageContainer>
);
}
两份代码功能完全一样,组件也都用对了。差异全在“怎么组合”——文件怎么拆、状态怎么管、组件怎么嵌套。开发规范能写“用 useProTableRequest”这一条规则,但没法描述 formProps 怎么传给 SearchForm、tableProps 怎么传给 OrderTable、PageContainer 里怎么嵌套。这些微观组合模式,只有看一份完整的代码才能传递——这就是样板间不可替代的原因。
这种转变不只体现在物料层面,连引导 Agent 的 System Prompt 写法都变了。传统做法是把 AI 定位为“代码编写专家”:
你是一位资深前端开发专家,精通 React/TypeScript。
请根据以下需求编写一个订单列表页:
- 使用 ProTable 组件
- 支持分页、筛选、排序
- 接口地址:/api/order/list
胶水编程的 System Prompt 把 AI 定位为“代码缝合专家”:
你是一位熟悉本仓库的技术专家。
开发新页面时,必须先查看 reference/ 目录下的样板间代码,
理解项目现有的文件结构、组件组合方式和请求封装模式。
你的任务不是从零编写代码,而是:
1. 复制最接近的样板间作为骨架
2. 替换业务字段和接口地址
3. 只在差异点编写新代码
区别一目了然:前者让 AI“写代码”,后者让 AI“找到最像的代码,然后改”。
为什么代码模式这么重要?因为 LLM 天然更擅长“照着代码抄”而非“按规则写”——Anthropic 的 CLAUDE.md 最佳实践明确指出,LLM 是 in-context learner,它通过查看已有代码来理解规范,而不是通过阅读抽象的规则描述。业界已有验证:Agiflow 开源的 scaffold-mcp 将上下文拆分为 Scaffold + Architect + Rules,架构合规率从 40% 提升到 92%。
我们的设计:两层继承
第一层:架构组统一维护 5 个工作台级样板间(默认兜底)
├── reference-platform-a/ # 工作台 A
├── reference-platform-d/ # 工作台 D
├── reference-platform-b/ # 工作台 B
├── reference-platform-c/ # 工作台 C
└── reference-platform-c-legacy/ # 工作台 C 旧版
第二层:域前端负责人可选 fork 扩展
reference-platform-a/(架构组默认)
↓ fork
reference-domain-x/(某域扩展版)
├── list-page/ # 继承默认结构
├── form-page/ # 继承默认结构
├── services/ # 【新增】该域特有的 hostMap + serviceHost 模式
└── file-export/ # 【新增】该域特有的 FileExport 用法
核心优势:Day 1 覆盖率 = 100%。只要架构组维护好 5 个工作台样板间,所有 11 个域立刻都有样板间可用。域负责人按需扩展,不扩展也不影响基本使用。
任务规格过载是代码模式缺位的最好证据。 我们检查了一份真实的 Plan 文档(plan_新增列表页面.plan.md,329 行),发现其中 200+ 行是完整的 Form.tsx / Table.tsx / index.tsx 代码实现。这些代码写在 Plan 里,本质上是因为 Agent 编码时找不到样板间,只能在 Plan 里内联一份“临时样板间”。如果代码模式到位,Plan 只需要写“这次需求有什么不一样”——5 行差异描述,替代 200 行内联样板间。这就是胶水编程的核心:AI 的工作量应该正比于需求的差异度,而非需求的复杂度。
任务规格(技术方案)— 方案层:“这次具体做什么?”
任务规格是具体需求的施工图,通过 SPEC/Plan 文件交付,定义了这次要做什么、做成什么样、验收标准是什么。
与其他三层不同,任务规格是一次性的——做完这个需求就归档了。其他三层(开发规范、领域知识、代码模式)是持久化的团队资产,跨需求复用。
中后台需求虽然千变万化,但复杂度的来源是可枚举的:交互表达(非标布局、多弹窗)、数据逻辑(字段联动、状态流转)、后端对接(接口契约、嵌套结构)、业务规则(跨字段校验、计算逻辑)、异常处理(空状态、超时重试)。不同复杂度需要不同的描述工具——联动需要规则表,状态流转需要状态机图,多弹窗需要对比表。
基于这个认知,我们没有做“一个万能模板”,而是按需求的主要复杂度特征拆分成 6 种 SPEC 模板:
| 模板 |
核心复杂度 |
特有描述工具 |
典型场景 |
| SPEC-基础模板 |
标准交互 |
页面布局图、基础流程图 |
常规增删改查页面 |
| SPEC-表单联动 |
字段间依赖 |
联动规则表、联动流程图 |
选了类型后子类型选项变化 |
| SPEC-多弹窗 |
多入口多操作 |
弹窗对比表、各弹窗结构图 |
列表操作列有多种不同弹窗 |
| SPEC-状态流转 |
状态机+权限 |
状态机图、操作权限表 |
审批流、订单状态管理 |
| SPEC-复杂校验 |
校验和计算 |
校验规则表、计算规则表 |
跨字段校验、价格自动计算 |
| SPEC-复杂列表 |
非标列表交互 |
列表类型选择、特有交互说明 |
树形结构、行内编辑、拖拽排序 |
每种模板都包含“基础必填”部分(技术规范、接口定义、页面结构、交互流程),差异在于各自额外携带的描述工具。比如表单联动模板会要求填写联动规则表(触发字段 → 触发条件 → 影响字段 → 影响效果),状态流转模板要求画状态机图和权限矩阵。这些描述工具不是可选项,而是模板的必填章节——它们确保开发者把该复杂度下最容易遗漏的信息说清楚。
模板的选择支持两种方式:开发者可以根据需求特征手动指定,也可以交给系统默认匹配。默认情况下,系统会根据需求描述中的关键特征(如“审批流”→ 状态流转、“联动”→ 表单联动)自动推荐匹配的模板。当需求同时涉及多种复杂度时(比如审批流页面中有表单联动),选择主要复杂度对应的模板,再从其他模板中借用需要的描述工具章节。
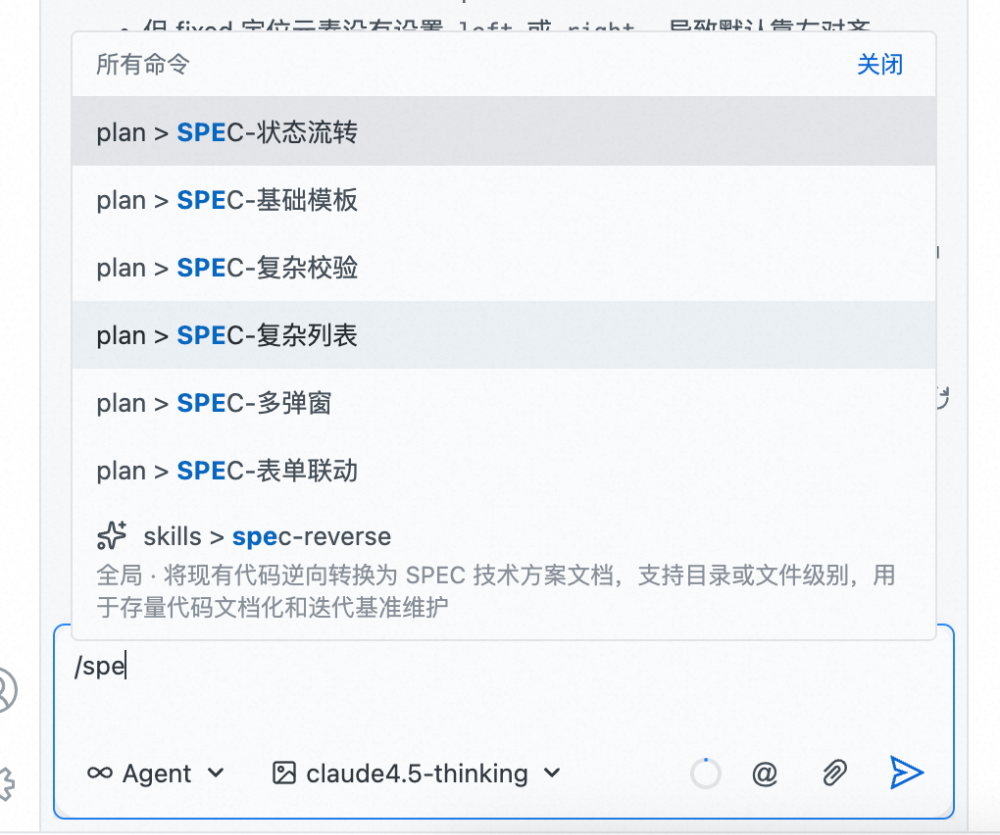
下图是开发者在编码工具中通过 /spec 命令选择模板的实际界面。开发者输入 /spec 后,系统列出所有可用模板(基础模板、表单驱动、多弹窗、状态流转、复杂校验、复杂列表),选择后自动加载对应模板的结构和必填章节。此外还有 spec-reverse——将现有代码反向生成 SPEC 技术方案文档,用于已有页面的变更场景。
这套分类的价值在于消除了方案质量的波动。没有模板时,每个人写的技术方案格式不一样——有人写得很详细,有人只写了接口列表。Agent 拿到不同结构的方案,输出质量也跟着波动。有了模板后,一个有 5 种弹窗的商品诊断需求,对话轮次从 50+ 轮降至 15-20 轮——不是因为 Agent 变聪明了,而是因为模板要求开发者把弹窗对比表填清楚了,Agent 不再需要反复追问“这个弹窗和那个弹窗有什么区别”。
胶水编程视角下的任务规格: 任务规格管的是“这次做什么”(意图侧),而开发规范 + 领域知识 + 代码模式管的是“怎么做、用什么做、参照什么做”(执行侧)。两者正交互补——任务规格越清晰,Agent 越知道做什么;物料越完善,Agent 做出来的越可控。
一个需求的完整旅程:业务域 B 的询价单管理页
业务域 B 后端同学 X 接到一个需求:非标子市场的采购商需要向供应商在线询价,当前全靠业务手动维护 Excel 线下沟通,效率很低。需要搭建一个询价单管理页面——询价列表(查询、筛选、分页)+ 询价详情(申请内容、SKU 价格表、操作记录时间线)+ 状态流转操作(同意/拒绝/撤销/失效)。这是一个典型的中后台业务需求,涉及列表、详情、状态机,复杂度适中但细节不少。
按胶水编程的方法,从 SPEC 编写到最终出码。以下是四层物料在这个需求中的实际协作过程。
- 第一层:开发规范自动生效。 同学 X 打开业务域 B 仓库时,AGENTS.md 已经通过域配置自动下发到位。Agent 从一开始就知道这个仓库的规矩——用
@internal/supply-chain-libs 的 createFetch 发请求,接口地址必须以 / 开头,导入导出要传 businessCode。这些约束不需要同学 X 说一个字,Agent 自动遵守。
- 第二层:代码模式提供骨架。 Agent 命中工作台 A 的列表页样板间,直接复制了 index.tsx + Form.tsx + Table.tsx + services.ts 的完整结构。询价列表页的文件组织、组件层级、请求封装模式全部来自样板间,不是从零写几百行代码,而是在骨架上改字段名和接口地址。
- 第三层:领域知识避坑。 写到 Table 组件时,Agent 通过 MCP 检索到“ProTable 的 cacheKey 必须全局唯一,否则切换页面时数据会串”。询价单管理恰好有列表页和详情页两个 ProTable,如果 cacheKey 重复,用户在两个页面间切换会看到错乱的数据——这种 bug 功能测试时不会暴露,上线后查起来极其痛苦。
- 第四层:任务规格定义差异。 样板间给了大部分骨架,开发规范和领域知识排除了常见陷阱,但询价单有自己的业务特殊性:列表每行不是简单的一条数据,而是包含编号、状态标签、申请时间、约定日期、产品名、供应商、价格区间等多个复合信息块;详情页有 SKU 维度的阶梯价格表(不同采购量对应不同价格和折扣率)和操作记录时间线。这些业务差异在 SPEC 里定义清楚,Agent 只在这些差异点写胶水代码。
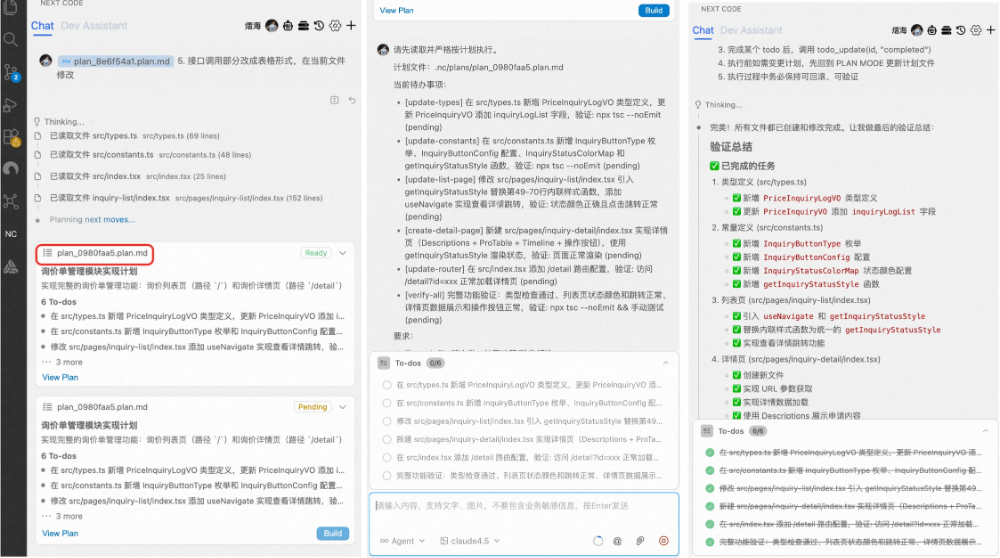
下图是同学 X 完成这个需求的实际操作过程:左侧是 Plan 生成阶段,Agent 根据 SPEC 自动拆解出任务列表和文件结构;中间是 Plan 文档的具体内容,包含每个任务的实现步骤和文件依赖;右侧是代码执行结果,所有文件创建和修改均一次完成,绿色标记表示通过。
最终产出: 代码的文件结构、组件层级、请求模式、状态管理全部来自样板间,同学 X 只需要在 SPEC 中定义询价单特有的字段、接口和业务规则。真正需要从零编写的逻辑——SKU 阶梯价格表、状态流转操作、操作记录时间线——是这个需求区别于其他列表页的差异点,也正是“胶水代码”所在。同学 X 的总结是:最终生码超出预期,完成度几乎 100%,页面按钮操作也没有问题。 同时也指出了改进方向:执行计划文档的编辑过程不够顺畅,部分 prompt 中提到的要求在 Plan 文档中被遗漏——这恰好说明了物料体系的两面:物料到位的地方,Agent 产出质量很高;物料缺失的地方,就会出现偏差。
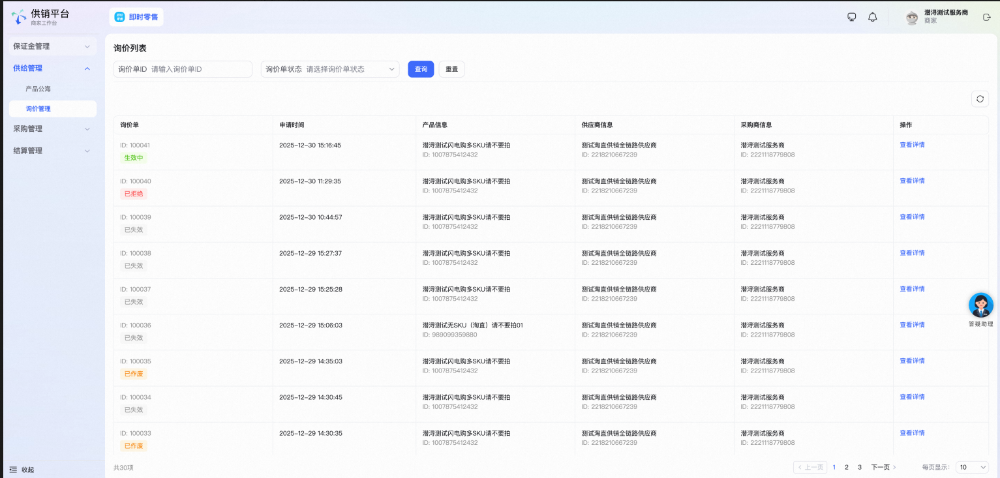
下图是最终交付的询价列表页成品,包含完整的筛选区、询价单数据列表和分页功能,直接部署上线:
把这个过程抽象一下,四层物料的协作流程是这样的:
新任务进来:开发业务域 B 询价单管理页
├─→ 加载开发规范 (自动,通过 AGENTS.md 文件)
│ “这个仓库的规矩是什么?”
│ → 用 @internal/supply-chain-libs 的 createFetch
│ → 接口地址必须以 / 开头
│ → 导入导出需传 businessCode
│
├─→ 查代码模式 (自动注入样板间)
│ “有没有类似的骨架可以抄?”
│ → 命中工作台 A 列表页样板间
│ → 直接复制 index.tsx + Form.tsx + Table.tsx 结构
│
├─→ 查领域知识 (按需检索,通过 MCP 协议)
│ “ProTable 怎么用?有什么注意事项?”
│ → 物料文档:ProTable 的 Props 和 API
│ → 编码规范:业务域 B 的请求规范
│ → 经验知识:cacheKey 必须唯一否则数据串
│
└─→ 读任务规格 (SPEC/Plan 文件)
“这次具体做什么?”
→ 询价列表页 + 询价详情页
→ SKU 阶梯价格表、状态流转操作
→ 操作记录时间线
│
↓
最终产出:骨架来自样板间,胶水代码只在业务差异点
四层物料的效果不是简单相加,而是组合放大:


交付之后:物料飞轮与上下文延续
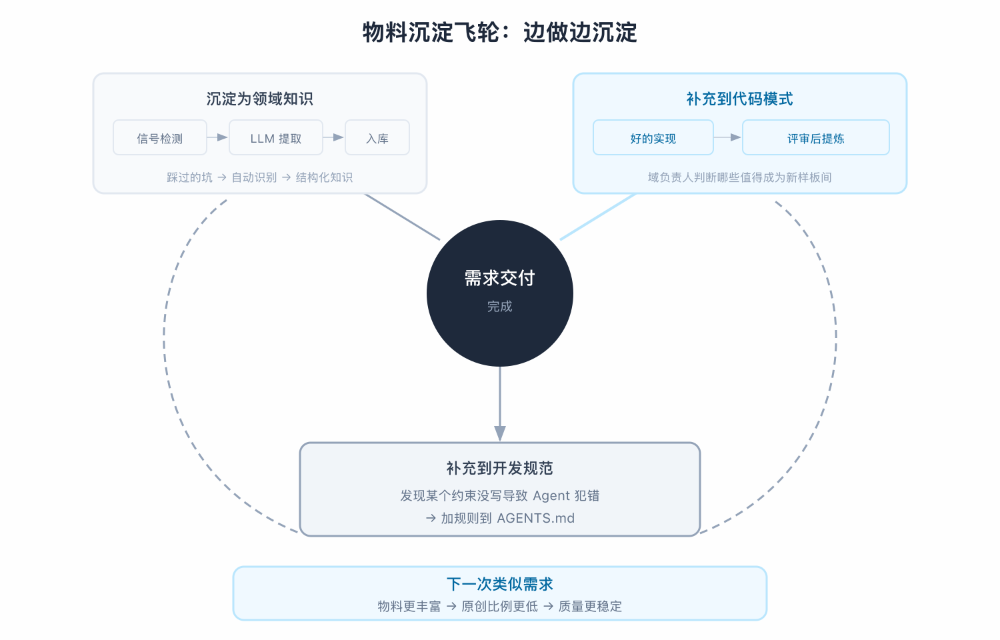
胶水编程不是一次性的重资产投入。它有一个内置的正循环:每次需求交付都在为物料体系补充新内容——踩过的坑沉淀为领域知识,好的实现提炼为代码模式,发现的规范缺失补充到开发规范。用得越多,物料越丰富,Agent 产出越可控。
每次交付都在补充物料
需求交付完成
│
├─→ 踩过的坑 → 信号检测自动识别 → LLM 提取 → 沉淀为领域知识
│ (系统检测会话中的错误信号、否定信号、反复修改行为)
│
├─→ 好的实现 → 评审后提炼 → 补充到代码模式样板间
│ (域负责人判断哪些实现值得成为新的样板间)
│
└─→ 发现的规范缺失 → 补充到开发规范
(发现某个约束没写导致 Agent 犯错 → 加规则)
│
↓
下一次类似需求:Agent 可用的物料更丰富 → 原创比例更低 → 质量更稳定
经验知识的沉淀已经实现自动化——信号检测 → LLM 提取 → 质量评分 ≥ 4 自动通过 → MCP 可检索。审核通过率 93.4%,覆盖 30 个仓库。
物料在积累,但每次需求的技术决策同样是团队资产。如果这些决策不持久化,下一次 AI 编码同一个模块时就是从零开始理解历史——行业数据印证了这个趋势:GitClear 报告显示 AI 辅助后代码重复率增长 8 倍,CMU 研究发现静态分析告警增加 30%。根因不是 AI “写不好代码”,而是缺乏全局上下文的 AI 只会无脑复制和局部修补。
每个需求留下一份 spec.md
解法是让任务规格归档但不遗忘。具体机制是 Track:每个需求在仓库的 .ai/tracks/ 目录下留下一份持久化记录。
.ai/tracks/<task_id>/
├── spec.md # SPEC 实例:做什么 + 怎么做 + 验收标准
└── meta.json # 状态元数据(需求 ID、创建时间、状态)
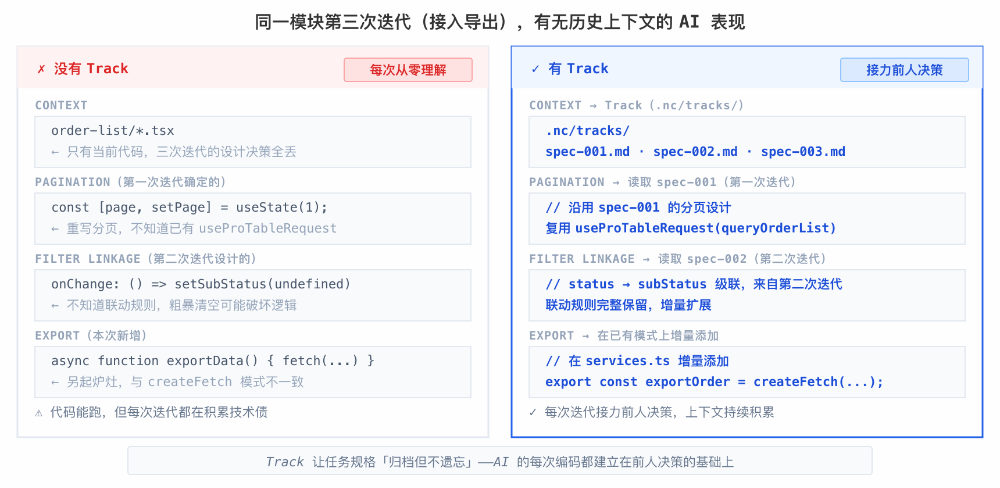
spec.md 就是 /plan 命令产出的那份技术方案——无需额外撰写任何文档,只是多了一个持久化存放位置。后续 AI 编码同一模块时,自动读取历史 Track 中的 spec.md,理解“之前为什么选了方案 A 而不是方案 B”、“这个模块上次重构过哪些接口”。上下文不再断裂,AI 的每次编码都建立在前人决策的基础上。
一个实际场景: 仓库中某个模块先后经历了“新增列表页”、“增加筛选条件”、“接入导出功能”三个需求。没有 Track 时,第三个需求的 AI 只能看到当前代码,不知道列表页的分页逻辑是第一次需求确定的、筛选条件的联动规则是第二次需求设计的。有 Track 后,AI 读取前两份 spec.md,理解这些设计决策的来龙去脉,新增导出功能时自然遵循已有的数据获取模式,而不是另起炉灶。
规格保鲜:保持 spec 与代码的一致性
Track 解决了“过去的上下文在哪里”的问题,但还有一个时效性问题:编码过程中方案变更了——代码改了,spec.md 没更新。随着迭代次数增加,文档和代码之间的 gap 越积越大,AI 读到的 spec 反而会误导编码。
我们的做法是把规格同步封装为一个轻量级的 Skill,开发者通过 slash command 随时触发——读取 spec.md,对比 git diff,AI 识别差异后生成更新建议,人确认后写入。设计原则是手动触发、AI 辅助、人确认——不追求全自动双向同步,而是在流程中嵌入一个低成本的修正点。
维护成本与业界对比
四层物料的维护成本并不均等。开发规范和领域知识的维护成本都很低——前者是“发现 Agent 犯规时补一条规则”,后者靠信号驱动自动沉淀,几乎零人工。任务规格更简单,/plan产出的 spec.md 自动留存,零额外成本。唯一需要主动投入的是代码模式:架构组维护 5 个默认样板间,域按需 fork 扩展——但回报也最大,不维护的代价是 Agent 每次从零写,风格不统一,质量波动。
这不是“额外建设一套新系统”,而是“把本来就在做的事情结构化沉淀”——团队每天都在写列表页、表单页、详情页,只是之前写完就走了,现在多一步把好的实现提炼成样板间。
在上下文延续方面,我们选择了务实的中间路线。业界方案各有取舍:Google Conductor强制规划先行但完全手动;AWS Kiro 做到了 spec → 代码的单向同步,但反向同步未实现;Tessl 代码完全从 spec 生成,但非确定性问题可能重蹈 MDD 覆辙。我们选择 Track 留存 + Skill 触发同步——/plan 自动归档保证上下文不丢,手动触发规格同步保持一致。在完全自动化双向同步被证明可行之前,这是成本最低的务实选择。

效果与落地:从 50% 到 90%+ 的真实路径
从 ~50% 到 90%+:每一步都对应一次物料补全
三个阶段的采纳率变化,每一步都对应一次物料体系的关键补全:
- 初期 ~50%——有知识库,但没有开发规范、没有代码模式。Agent 能写出功能正确的代码,但风格随机、结构混乱,CR 大量打回。这个阶段的认知是“让 AI 写代码”。
- 中期 ~76%——引入 AGENTS.md 云端下发 + 知识库数据驱动运营。Agent 开始遵守项目规范,组件用对了、请求方式对了,但代码组织和文件结构还是跟团队习惯不一样。认知升级为“让 AI 按规矩写代码”。
- 当前 90%+——完整四层物料体系到位。Agent 不仅遵守规范,还照着样板间的结构写代码,只在差异点写胶水。认知最终落到“让 AI 照着抄代码”。
累计提升超过 40 个百分点。

我们的场景还有一个独特之处:使用 AI 编码的主力不是前端工程师,而是近两百名后端工程师。他们对前端技术栈不熟悉,完全依赖 AI 来交付中后台前端需求——没有样板间可抄,就写不出符合团队规范的前端代码。推广过程中一个关键杠杆点是开发规范的云端下发:新人接入从 2 小时手动配置降到 30 秒自动生效。
踩过的坑:三个常见误区
半年实践下来,团队反复踩过三个坑,值得分享:
- 误区一:“物料越多越好”。 早期我们往知识库里灌了大量内容,结果 Agent 召回了一堆不相关的知识,反而干扰了编码质量。后来通过“调用率 × 采纳率”的四象限分析,逐一清理低效知识条目——被频繁召回但采纳率只有 20%~30% 的条目要么优化表述、要么直接删除。知识库关联采纳率从 18% 提升到 35%,近翻倍。物料的价值不在数量,在精准度。
- 误区二:“样板间写一次就够了”。 代码模式不是写完就不管了。随着团队架构升级(比如从旧版请求库迁移到新版),样板间如果不同步更新,Agent 会继续按旧模式生成代码。代码模式是唯一需要主动投入维护的物料层——但好消息是,团队每天都在写新页面,好的实现顺手提炼为样板间,维护成本并不高。
- 误区三:“有了物料就可以轻视 SPEC”。 恰恰相反。物料解决的是“怎么做”,SPEC 解决的是“做什么”。我们见过有同学在物料体系完善后草草写个 SPEC 就直接编码——Agent 确实写出了风格统一的代码,但做的不是产品要求的功能。SPEC 和物料是正交的两个维度,缺任何一个都不行。

总结:从“生成”到“组装”,AI 编码的范式转变
回到开头的数据:采纳率从 50% 到 90%+,核心变量不是模型升级,而是物料体系的完善——同一个基座模型,物料到位前后的产出质量判若两人。AI 编码的质量上限取决于你喂给它什么,而非它本身有多强。
这不只是方法论的改良,而是 AI 编码底层假设的转变。传统假设是把 AI 当作作者:给它足够好的需求描述,它就能写出好代码。胶水编程的假设是把 AI 当作装配工:它不应该“写”代码,而应该“抄+改”代码。当知识的消费者从人变成 Agent,“口头传递”这条路径断了——Agent 只能消费被显式外化的知识。当 AI 成为团队中最大的“新人”,所有隐性知识都必须变成显性资产。
任何为模型行为搭的工程脚手架,都有隐形的保质期——几个月后新一代模型可能原生就能做到,还比你实现得更干净。这跟传统软件工程追求复用、追求框架撑三年的直觉完全相反。但这恰恰印证了胶水编程的押注方向:我们投资的不是脚手架,而是知识资产。 加载物料的工程机制会变——今天是 AGENTS.md 静态注入,明天可能是模型原生支持长期记忆——但团队的代码模式、领域知识、开发规范不会因为模型升级而过时。代码可以随时推翻重来,但你用来判断代码好不好的标准得有人维护。模型会换代,脚手架会扔掉,但团队知识只会越积越厚。
90%抄,10%写。 这才是 AI 编码真正的护城河。
 发表于 2026-3-28 05:52:17
|
查看: 131|
回复: 0
发表于 2026-3-28 05:52:17
|
查看: 131|
回复: 0
