译者注:
本部分内容节选自《Prompt Engineering》的 Prompting techniques 章节的内容。
《Prompt Engineering》是 Google 于 2025 年发布的一份系统性指南,由 Lee Boonstra 撰写,聚焦于大语言模型场景下的提示工程实践方法。该资料围绕提示设计原则、结构化写法与优化策略展开,结合实际案例,帮助开发者更高效地构建高质量 Prompt。内容兼具理论框架与实操指导,适用于希望深入理解并提升大模型应用效果的开发者与产品团队。
由于内容偏多,因此译文将会拆分为几个部分,本篇为系列第三篇。
翻译:谢杰
校对:谢杰
本文将探讨几种能引导大语言模型进行更深层次思考的提示工程技术。作为系列文章的第三部分,我们将专注于那些旨在提升模型推理、逻辑与决策能力的策略。如果你对技术文档的规范和撰写感兴趣,欢迎在云栈社区的相关板块深入交流。
Step-back prompting
Step-back prompting 是一种引导大语言模型(LLM)通过“退一步思考”来提升表现的技术。
它的核心思路是:先让 LLM 思考一个与当前具体任务相关的、更一般性或更宏观的问题。然后,把这个一般性问题的答案作为上下文信息,融入到后续解决具体任务的提示词中。这个“退一步”的过程,可以帮助模型在直面具体难题之前,先激活相关的背景知识和抽象的推理框架。
通过先思考更宏观或更底层的原理,LLM 往往能够生成更准确、更有洞察力的回答。这种方法鼓励模型进行更具批判性的思考,并以更灵活、更具创造性的方式运用已有知识。相比直接提问,它能调动模型参数中更多潜在的知识储备,从而改变最终执行任务时的效果。
此外,step-back prompting 还能在一定程度上缓解模型回答中的偏见问题。通过聚焦于一般性原则而非具体细节,可以减少由局部或片面信息带来的误导。
下面我们通过一个实例来看看 step-back prompting 如何提升输出结果的质量。首先,我们回顾一个传统的直接提示,如表 8 所示。

当你将 temperature 设置为 1 时,可能会得到各种充满创意的故事情节,但结果往往也会变得相对随机,甚至有些泛泛而谈。因此,我们不妨先“退一步”思考,问一个更基础的问题:

是的,这些主题确实很适合作为第一人称射击游戏的设定。接下来,我们回到最初的 prompt,不过这一次我们将 step-back 步骤得到的答案作为上下文一并加入,看看模型会生成怎样的结果。
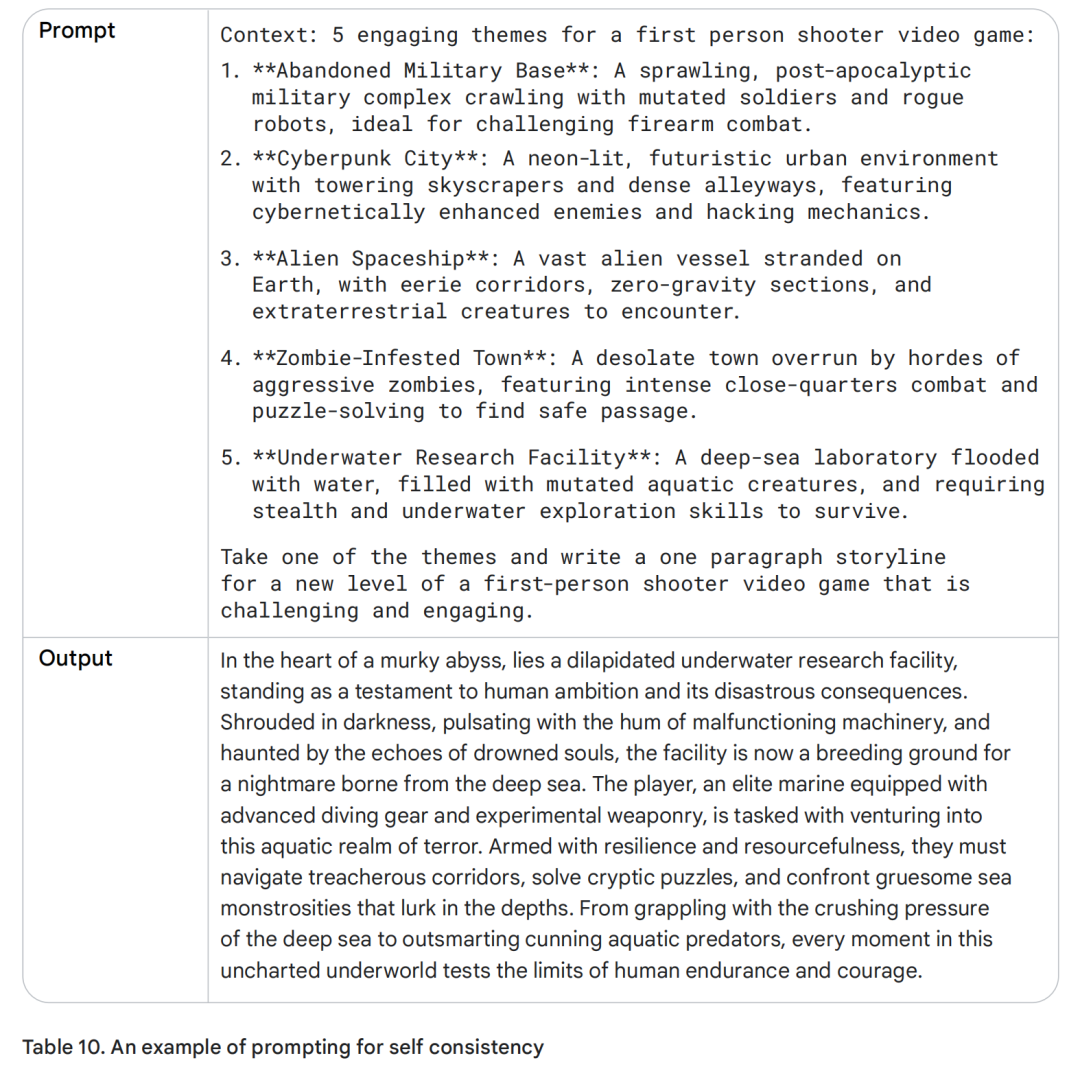
这看起来确实是一款很有意思的电子游戏!通过使用 step-back prompting 技术,我们有效提升了 prompt 的准确性和输出质量。
Chain of Thought
Chain of Thought prompting 是一种通过要求 LLM 生成中间推理步骤来增强其推理能力的技术,从而帮助模型给出更准确的最终答案。它也可以与 few-shot prompting 结合使用,在那些需要先推理再作答的复杂任务上取得更好的效果;而在 zero-shot 场景下直接使用 CoT 往往更具挑战性。
CoT 有不少优势。
- 首先,它几乎不需要额外成本,却非常有效,并且对现成的 LLM 就能很好地工作(无需进行模型微调)。
- 其次,CoT 提供了更强的可解释性:你可以从模型的回答中看到它采用的推理步骤,并据此进行学习或排查问题。一旦输出异常,你也更容易定位是在哪一步推理出了偏差。
- 此外,在不同 LLM 版本之间迁移使用 chain of thought 提示时,往往能提升鲁棒性——也就是说,相比不使用推理链的提示,你的提示在不同模型之间的表现波动会更小。
当然,它也有一些比较直观的缺点。
由于 LLM 的输出中包含了 chain of thought 推理过程,这意味着会产生更多的输出令牌,从而带来更高的推理成本,并且整体响应耗时也会更长。
为了说明问题,我们先尝试写一个不使用 CoT 的简单提示,用来展示大语言模型在处理某些问题时可能暴露的缺陷,如表 11 所示。
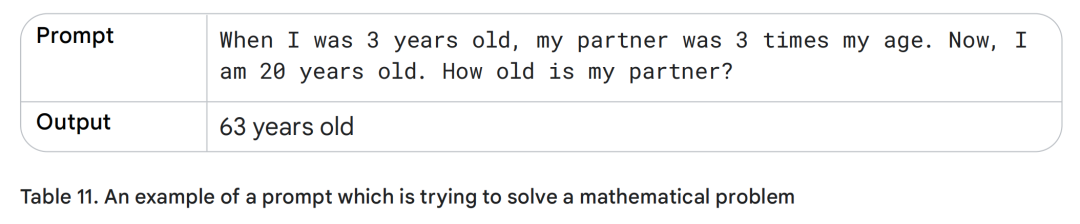
糟糕,这显然是个错误答案。事实上,LLM 往往不擅长数学任务,甚至在像“两个数相乘”这样简单的计算上,也可能给出不正确的结果。这是因为它们主要是在海量文本数据上训练的,而数学问题往往需要不同的处理方式。因此,我们来看看加入中间推理步骤,是否能改善输出效果。

好,现在最终答案是正确的。这是因为我们明确要求 LLM 解释每一步,而不是只返回一个答案。
有意思的是,模型把增加的 17 年直接累加了。在我看来,我会先计算我和伴侣之间的年份差,然后把这个差值加起来(20 + (9-3))。我们可以进一步引导模型,让它的思考方式更接近这种思路。
表 12 展示了一个 “zero-shot” Chain of Thought 示例。
当 Chain of Thought prompting 与 single-shot 或 few-shot 结合使用时,其效果会更加强大,正如表 13 中所展示的那样。

Chain of thought 在很多场景都很有用。
- 比如在代码生成中,可以先把需求拆解成几个逻辑步骤,再将这些步骤映射到具体的代码行;
- 又或者在生成合成数据时,当你有一个种子作为起点,例如:“该产品名为 XYZ,请根据给定的产品标题,引导模型逐步推导出你可能做出的假设,并撰写产品描述。” 这类需求,就可以通过引导模型逐步推导假设来完成。
总体来说,任何可以通过“把思路说出来”来解决的任务,都是 chain of thought 的良好应用场景。如果你能清晰地向他人解释解决问题的步骤,就可以尝试使用 chain of thought。
Self-consistency
尽管大型语言模型在各种 NLP 任务中表现出色,但其复杂推理能力仍然被认为是一个难以仅靠扩大模型规模来解决的局限。正如我们在前一节 Chain of Thought prompting 中提到的,模型可以被引导生成类似人类解题过程的推理步骤。不过,标准的 CoT 通常采用一种简单的“贪婪解码”策略,这在一定程度上限制了其探索不同解题思路的能力。
Self-consistency 则通过结合采样和多数投票机制,生成多条不同的推理路径,并选择其中最一致的答案,从而提升 LLM 输出的准确性和稳定性。
Self-consistency 能为某个答案提供一种“伪概率”意义上的正确性估计,但显然也会因为多次调用模型而带来更高的计算成本。
其基本流程如下:
- 生成多样化的推理路径:将同一个 prompt 多次提交给 LLM。通过设置较高的 temperature 参数,鼓励模型针对同一问题生成不同的推理路径和思考视角。
- 从每次生成的响应中提取答案。
- 选择出现频率最高的答案。
下面来看一个邮件分类系统的示例,该系统需要将邮件分类为 IMPORTANT 或 NOT IMPORTANT。
我们会将一个 zero-shot chain of thought prompt 多次发送给 LLM,观察每次提交后的响应是否有所不同。请注意邮件中的友好语气、用词方式以及其中可能包含的讽刺表达,这些因素都有可能误导 LLM 的判断。
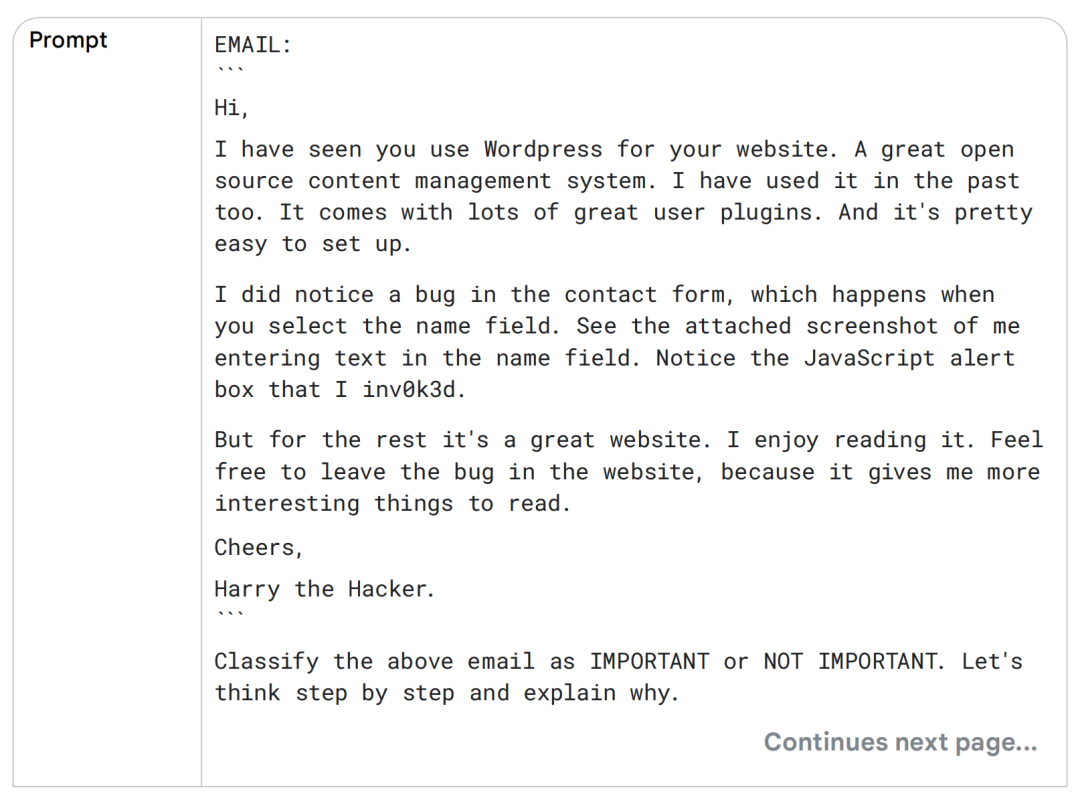
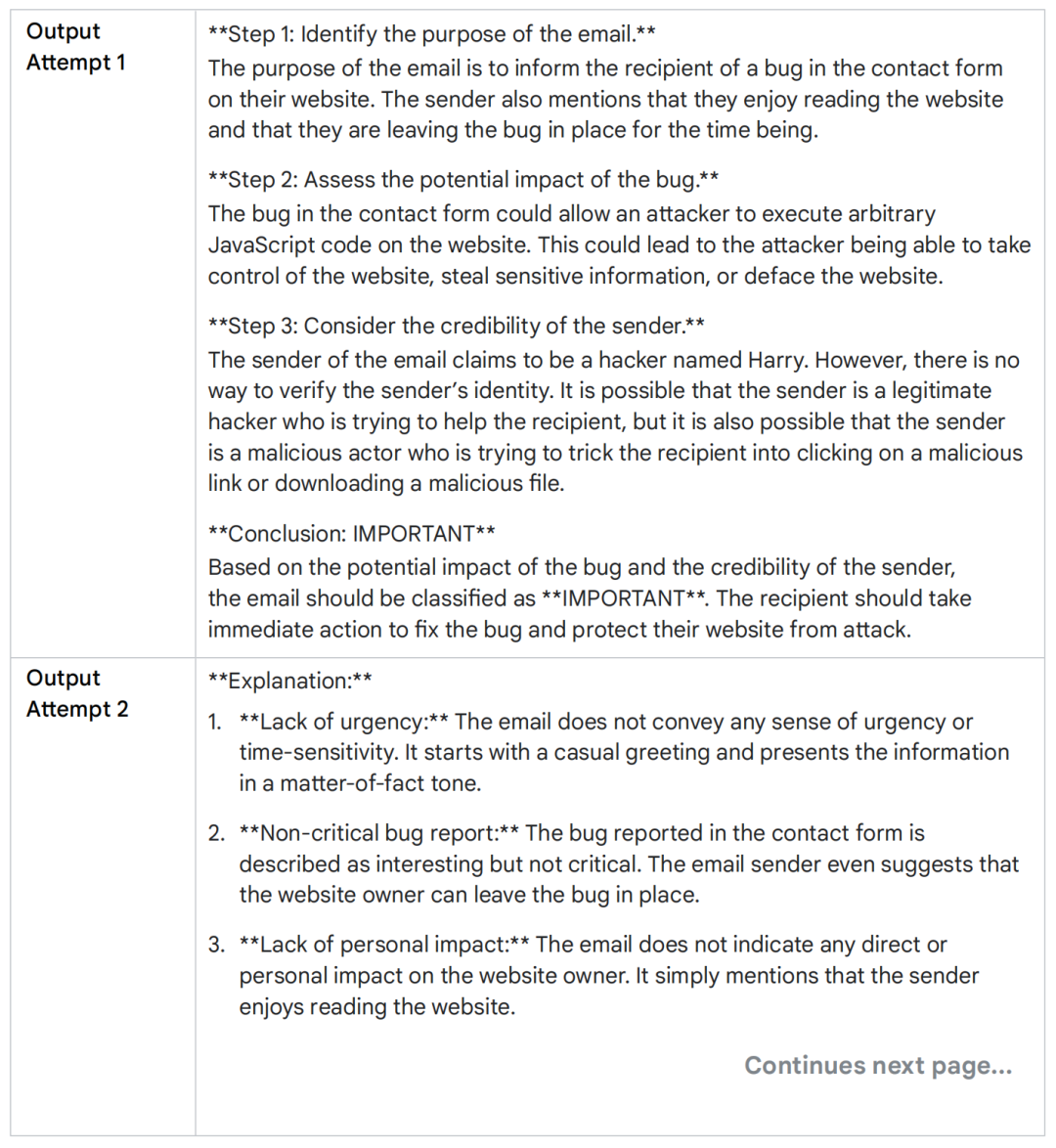

你可以使用上面的 prompt 进行尝试,观察它是否能够稳定地返回一致的分类结果。根据你所使用的模型以及 temperature 的配置不同,它可能会返回 “IMPORTANT”,也可能会返回 “NOT IMPORTANT”。
通过生成多条 Chain of Thought 推理路径,并统计选择出现频率最高的答案(在这个例子中,更可能是“IMPORTANT”),我们可以让 LLM 给出更加稳定、更加准确的结果。
这个示例清晰地展示了 self-consistency prompting 如何通过综合多种推理视角,并选取最一致的答案,来提升 LLM 在复杂或模糊任务中响应的准确性。这种技术是当前人工智能领域提升模型可靠性的重要方法之一。
写在最后
在这一篇中,我们从“如何让模型思考得更好”的角度,进一步探讨了 prompt engineering 的进阶策略。
从通过 step-back prompting 激活背景知识,到用 Chain of Thought 显式展开推理过程,再到借助 self-consistency 通过多路径采样与多数投票提升结果稳定性,这些方法本质上都在解决同一个问题:如何让模型在涉及抽象、计算或复杂决策的任务中,输出更可靠、更可复现的结果。
与之前讨论过的 system、role、contextual prompting 不同,这里的关注点已经从“如何设定任务与语境”,转向了“如何设计模型的思考过程本身”。当任务需要逻辑推演、数学计算、代码拆解或 nuanced 的决策时,一句直接的指令往往难以获得稳定的好结果。通过结构化地引导推理路径,我们不仅能提升答案的准确率,还能增强输出的可解释性以及在不同模型版本间的一致性。
从更宏观的视角来看,现代的 prompt engineering 早已不只是写出一句更清晰的指令,而是在设计一套可控的、可引导的推理机制。深入理解模型的能力边界与思维特性,并通过合理的提示策略进行引导、补偿与放大,才是构建高质量、高可靠性 AI 应用的核心能力。
 发表于 2026-3-28 07:42:33
|
查看: 128|
回复: 0
发表于 2026-3-28 07:42:33
|
查看: 128|
回复: 0
