当我们谈论一个系统是否“可靠”时,99.9%和99.99%的可用性之间,差的不只是一个小数点,更是对技术架构深度的考验。高可用性意味着系统需要具备在部分组件发生故障时,依然能持续对外提供服务的能力,从而最大限度地减少中断时间。
理解高可用,首先要厘清几个核心指标:
- RTO(恢复时间目标):从故障发生到系统恢复服务所需的时间。这个时间越短越好。
- RPO(恢复点目标):系统能容忍的数据丢失时间窗口。例如,RPO=5分钟意味着最多允许丢失故障发生前5分钟内的数据。
- MTBF(平均无故障时间):系统两次故障之间的平均时间,越长越稳定。
- MTTR(平均修复时间):从故障发生到修复完成的平均时间,越短越好。
明确了目标,高可用的设计通常遵循六大核心原则,它们构成了保障系统稳定运行的基石。
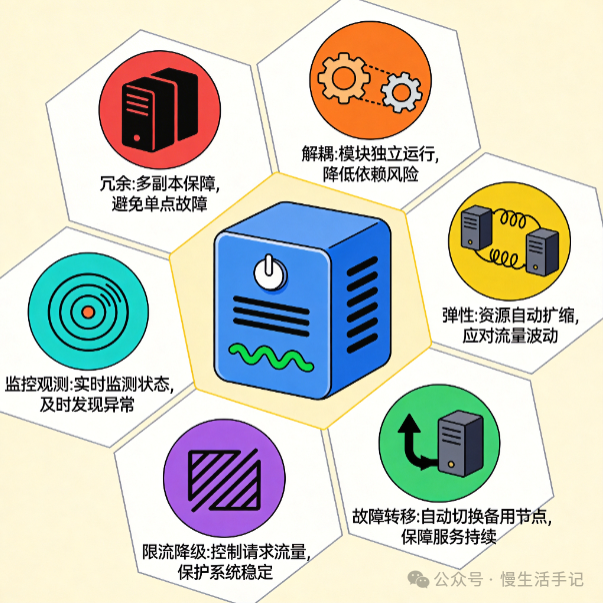
- 冗余设计:消除任何单点故障(SPOF),关键组件必须有备份。
- 解耦设计:模块间通过定义良好的接口(如API、消息队列)交互,降低耦合度,避免故障扩散。
- 弹性伸缩:支持水平扩展,能够根据流量压力动态增加或减少资源。
- 故障转移:当主节点故障时,能自动、快速地将流量和服务切换到备用节点,对用户无感知。
- 限流降级:在极端压力下,主动限制非核心流量或暂时关闭非核心功能,确保核心业务链路通畅,防止系统雪崩。
- 可观测性:建立完善的监控、日志、追踪体系,让系统内部状态透明化,便于快速定位问题。
将这些原则落地,就形成了几种经典的高可用架构模式。
常用高可用架构模式
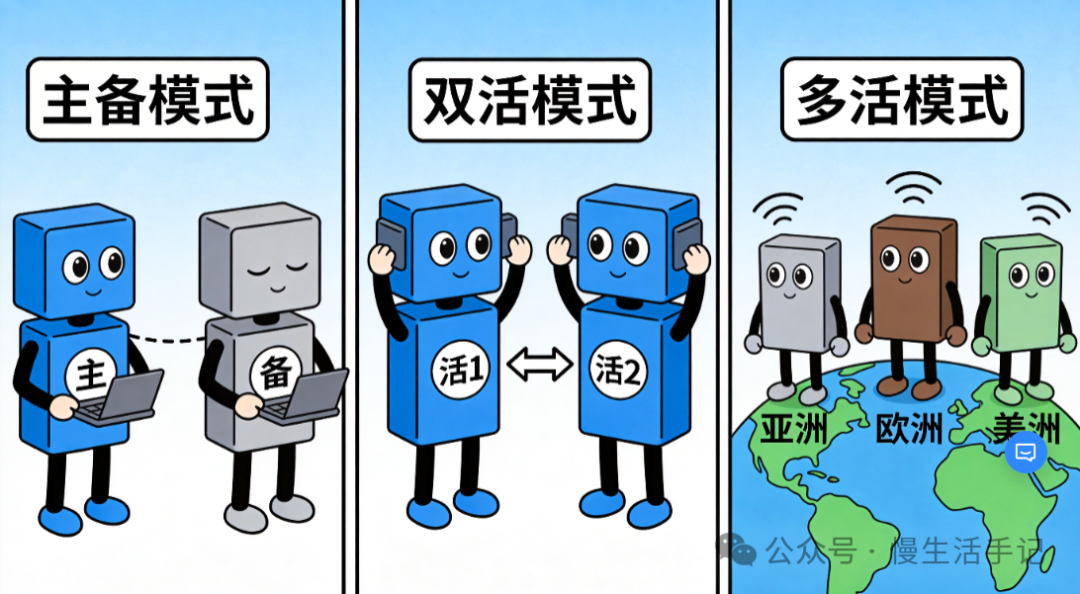
- 主备模式:一台主机(Active)对外服务,一台或多台备机(Standby)同步数据。主机故障时,备机接管。优点是实现简单,切换快;缺点是备机资源平时闲置,利用率低。
- 双活模式:多台节点同时对外提供服务,共同分担流量。任一节点故障,流量被自动导向其他存活节点。优点是资源利用率高,扩展性好;挑战在于数据一致性的维护,尤其是在跨机房场景下。
- 多活模式:双活模式的扩展,通常指分布在多个地理区域(如不同城市或国家)的数据中心同时提供服务,并互为灾备。这是全球性互联网公司的常见选择,最大挑战是跨地域的数据冲突解决和网络延迟。
一个健壮的高可用系统,需要从上到下、分层进行设计。
分层高可用设计实践
-
接入层高可用
- 负载均衡器冗余:使用如 LVS/Nginx 配合 Keepalived 实现虚拟 IP(VIP)漂移,避免负载均衡器本身成为单点。
- 多链路接入:采用多运营商 BGP 线路,实现自动的链路切换。
- DDoS防护:部署流量清洗中心和 Web 应用防火墙,抵御外部攻击。
-
应用层高可用
- 无状态设计:将会话(Session)等状态信息外部化存储到如 Redis 集群中,使应用实例可随时被创建或销毁。
- 服务熔断与降级:集成 Hystrix、Sentinel 等组件,在依赖服务不稳定时快速失败或降级,防止级联故障。
- 平滑发布:采用蓝绿部署、金丝雀发布等策略,实现服务更新时的零停机。
-
数据层高可用
- 数据库主从复制:如 MySQL 主从架构,配合读写分离中间件,分摊读压力并提供读故障转移。
- 数据同步策略:根据业务对一致性的要求,选择同步、半同步或异步复制。半同步复制能在保证性能的同时,极大降低数据丢失风险(RPO≈0)。
- 分布式数据库与缓存:采用 TiDB、CockroachDB 等多副本分布式数据库,或使用 Redis Cluster 模式,实现数据分片和高可用。
关键技术实现要点
-
负载均衡算法
选择合适的算法是均衡流量的关键。
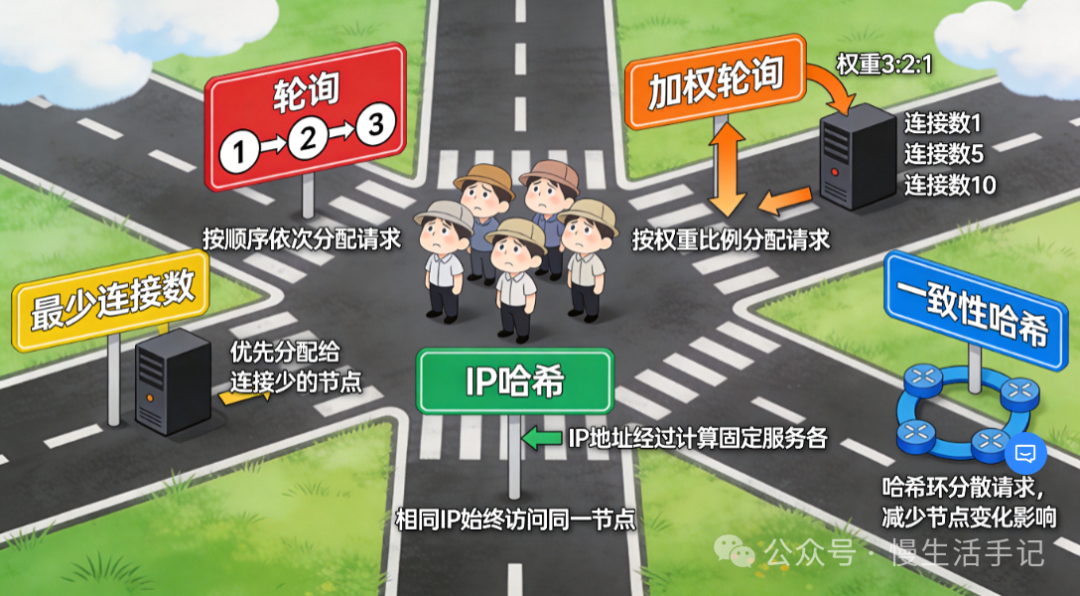
- 轮询:依次分发,简单公平。
- 加权轮询:根据服务器性能预设权重,按比例分配。
- 最少连接数:将新请求转发给当前连接数最少的服务器。
- IP哈希:根据客户端IP计算哈希值,固定映射到某台服务器,常用于会话保持。
- 一致性哈希:在节点增删时,能最小化需要重新映射的数据量,常用于缓存集群。
-
故障检测与自动切换
快速发现故障并切换是“高可用”的动词体现。
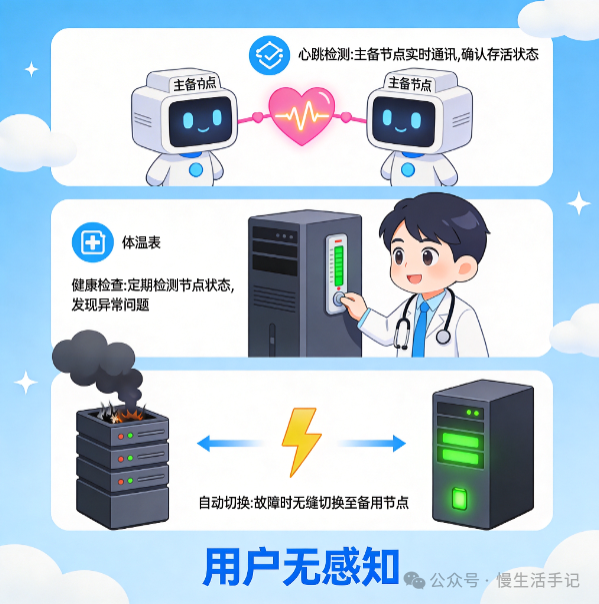
- 心跳机制:节点间定期发送心跳包,超时无响应则判定为故障。
- 健康检查:主动探测服务状态,包括端口检测、HTTP接口探测、自定义业务健康检查等。
- 自动故障转移:集成故障检测与切换逻辑,实现从故障判定到流量切换的全自动化,目标是用户无感知(RTO极小)。
-
数据同步策略
- 同步复制:主节点需等待所有从节点写入成功后才向客户端返回成功,保证强一致性和RPO=0,但延迟高。
- 异步复制:主节点写入成功后立即返回,数据异步复制到从节点,性能好,但故障时可能丢失最新数据。
- 半同步复制:折中方案,主节点只需等待至少一个从节点确认收到数据即可返回,在性能和可靠性间取得平衡。
行业解决方案案例参考
- 金融支付系统:对一致性和可用性要求极高。常采用 同城双活+异地灾备 架构,结合分布式事务(如TCC模式)保障交易准确。指标要求常为99.99%可用性,分钟级RTO,近乎零数据丢失。
- 电商大促系统:面临瞬时超高流量。核心在于 弹性伸缩(如基于K8s HPA)和 多层次缓存与降级。通过DNS+CDN实现全局流量调度,通过熔断限流保护核心交易链路,通过秒级扩容应对流量洪峰。
实战推演:电商平台高可用架构设计
背景与目标:某平台日订单峰值50万,原架构存在单点故障风险。新架构设计目标:99.99%可用性,RTO≤5分钟,RPO≤1分钟。
架构分层设计:
- 接入层:使用云服务商的多可用区负载均衡器,结合智能DNS与CDN,实现流量分发、加速与安全防护。
- 应用层:采用Spring Cloud微服务架构,服务注册到Nacos。应用无状态化,Session存入Redis集群。集成Sentinel进行熔断降级,并部署在Kubernetes上以实现HPA自动伸缩和滚动更新。
- 数据层:
- 数据库:MySQL采用一主三从架构,配置半同步复制以确保主从数据强一致。
- 缓存:部署Redis Sentinel三节点集群,实现自动故障转移。
- 消息队列:使用Kafka三节点集群,通过多副本机制保证消息不丢失。
- 容灾层:实施同城双活,流量按比例分发至两个可用区;建立异地灾备中心,通过异步复制数据,作为最后防线。
关键流程与效果:
通过三层健康检查自动剔除异常节点;主数据库故障时,借助中间件与脚本实现从库提升和VIP漂移的自动切换;监控资源利用率实现自动扩缩容。该方案上线后,在重大促销活动中成功处理海量订单,实现了多次自动故障转移,系统可用性达到99.995%,超出设计目标。
核心要点回顾
高可用架构设计是一项系统工程,贯穿从理念到实现的每一个细节。我们可以用六字诀来概括其精髓:冗余、解耦、弹性、故障转移、限流降级、监控观测。掌握这些原则,深入理解不同架构模式的适用场景,并熟练运用负载均衡、故障检测、数据同步等关键技术,是构建能够抵御故障、稳定运行的系统架构的必备能力。这不仅是系统架构师考试的核心考点,更是保障数字时代业务连续性的生命线。如果你对构建此类稳健的系统架构有更多兴趣或疑问,欢迎到云栈社区与更多的开发者一同交流探讨。 |  发表于 2026-3-29 01:48:31
|
查看: 140|
回复: 0
发表于 2026-3-29 01:48:31
|
查看: 140|
回复: 0
