Harness Engineering:能否破解智能体长期运行的困局?
我们正站在人工智能史上的一个关键时刻。过去几年,AI工程师们经历了大约每年一次的、持续且重大的技术地震。这些转变如此剧烈,以至于许多曾令开发者兴奋不已的技术如今已鲜少使用。
2025年11月,开源个人智能体Clawdbot(OpenClaw)的出现,引发了全球性的轰动。OpenClaw与Mario Zechner的pi-coding-agent等开源实战智能体工具包项目集成。虽然模型上下文协议(MCP)使智能体能够根据描述选择工具并在有限的执行范围内行动,但基于编码智能体的行动因其灵活性、即时性而存在风险:若其误解用户意图,则可能导致灾难性后果。

基于终端用户界面(TUI)的编码助手(如Codex CLI、Gemini CLI和Claude Code)于2025年初进入市场后,其演进速度超乎预期,迅速转变为基于AI的全功能IDE,例如Google Antigravity。到2025年底,许多大型科技公司已开始尝试完全自动化开发流程。这一转变对开发者角色的重塑,其深度与广度可能超出当前预期。根据The Information的报道,有观点指出,该转变更偏向苦涩,因为它彻底重新定义了开发者的工作方式,以及在这个生成式代码智能体时代,他们能做什么、不能做什么。
2025年8月,OpenAI启动了一项实验,旨在测试自动化代码智能体的能力。该实验的目标是,在无人类代码编写的情况下,创建一个测试版软件产品。研究团队在一个空仓库中,以一小套现有模板为指导,使用Codex CLI和GPT-5构建了开发脚手架。2026年2月11日,OpenAI公布了实验结果:在五个月内,编写了一百万行代码,开启了1500个拉取请求,而整个流程仅由三到七名工程师驱动Codex完成。该软件现已被数百名日常用户使用。
长时间运行智能体产生的核心问题:状态、环境与管理的三重挑战
图 1. 模拟城市 (1989)
当OpenAI的开发者启动空Git项目实验时,其目标并非构建简单的计数器应用,而是测试智能体能否构建健壮、大规模的代码项目。此类项目通常涉及数百万行代码,而代码量直接带来了功能复杂性:数百个变量和函数相互交织,必须协同工作以提供更高层次的抽象功能。验证此类大型项目的有效性,需确认其是否按预期工作,这往往需要整个公司投入数月甚至数年。
2026年2月,AI工程师Christopher Ehrlich成功利用Codex-GPT-5.3,将著名游戏《模拟城市》(1989)从纯C语言移植至TypeScript。他选择《模拟城市》的原因是,该游戏运行在Commodore 64等旧式电脑上,其所需资源甚至低于现代Chrome浏览器。值得注意的是,Ehrlich本人并不关心代码细节,仅通过自然语言引导OpenAI的Codex GPT-5.3,使其能够创建出预期成果。这一案例揭示了利用代码智能体的潜力。有分析认为,在不久的将来,开发者很可能在无需详细知识的情况下编写代码。然而,该任务即使对智能体而言也耗时4天。与人类相比,这无疑是显著的速度优势;但当智能体运行时间从一小时延长至数天时,一系列难以预见的问题随之浮现。
那么,长时间运行智能体究竟会引发哪些系统性挑战?
- 状态管理问题:这不仅仅是上下文窗口溢出的问题(通常可通过上下文压缩缓解)。当智能体运行足够长时间以处理大型项目时,有必要动态分配上下文以维持对全局的把握。此处的挑战也并非多智能体系统(MAS)所强调的、由智能体数量引发的复杂性,而是如何将上下文和记忆与解决庞大复杂问题的任务目标对齐。
- 环境管理问题:OpenAI实验的教训表明,模糊的决策边界和不可预测的项目结构可能导致智能体无法完成任务。仅依赖文档无法完全解决此问题。在长期运行场景中,管理智能体工作的环境至关重要。
- 智能体管理问题:智能体倾向于在项目未完成时过早宣布胜利。然而,OpenAI的实验发现,对智能体进行微观管理同样无法解决问题。核心挑战在于如何以及何时对智能体进行有效管理。
Harness Engineering:智能体的导航与控制系统
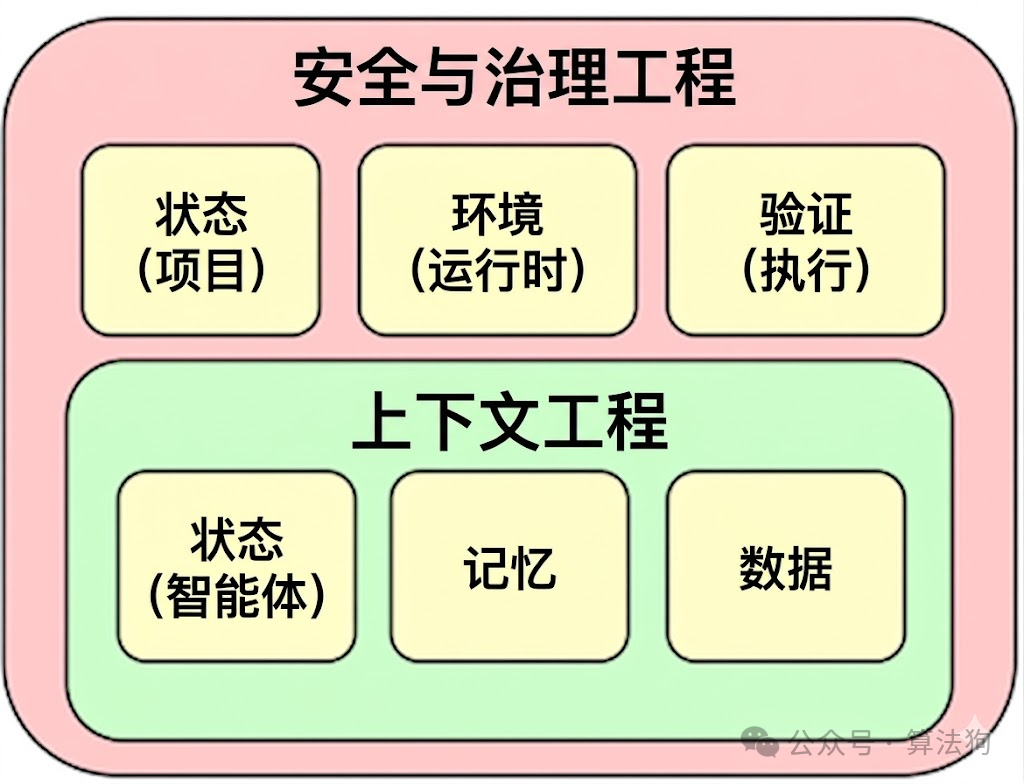
图 2. Harness Engineering 结构图
作为AI工程师,我们需要以系统化、工程化的方式管理状态、环境和智能体。在AI领域术语中,这一系列实践被称为Harness Engineering。Harness Engineering是一个比上下文工程更广泛的范畴,后者自2025年以来一直是AI领域的热门关键词之一。上下文工程聚焦于信息管理,受限于任何给定智能体的固定窗口大小。业界已投入大量努力探索最高效的方法:检索增强生成(RAG)和工具调用是管理输入数据的前沿技术;受有限状态自动机(FSA)启发的有状态智能体编排(如LangGraph)是动态管理智能体状态的一种方式;长期/短期记忆管理技术也是构建可靠智能体的核心主题之一。
从上下文工程的视角看,智能体与之交互的环境本质上是一个不可控变量,它更像一个根据智能体行为产生反馈的固定系统。为了突破智能体性能边界,许多开发者正尝试通过控制环境来提升智能体效能。Harness Engineering整合了上下文工程的现有元素,并引入了三个尚未被深入探讨、用于启动优化的独特概念:项目状态(或进度)的更抽象表示、运行时环境,以及通过智能体反馈循环进行的验证。
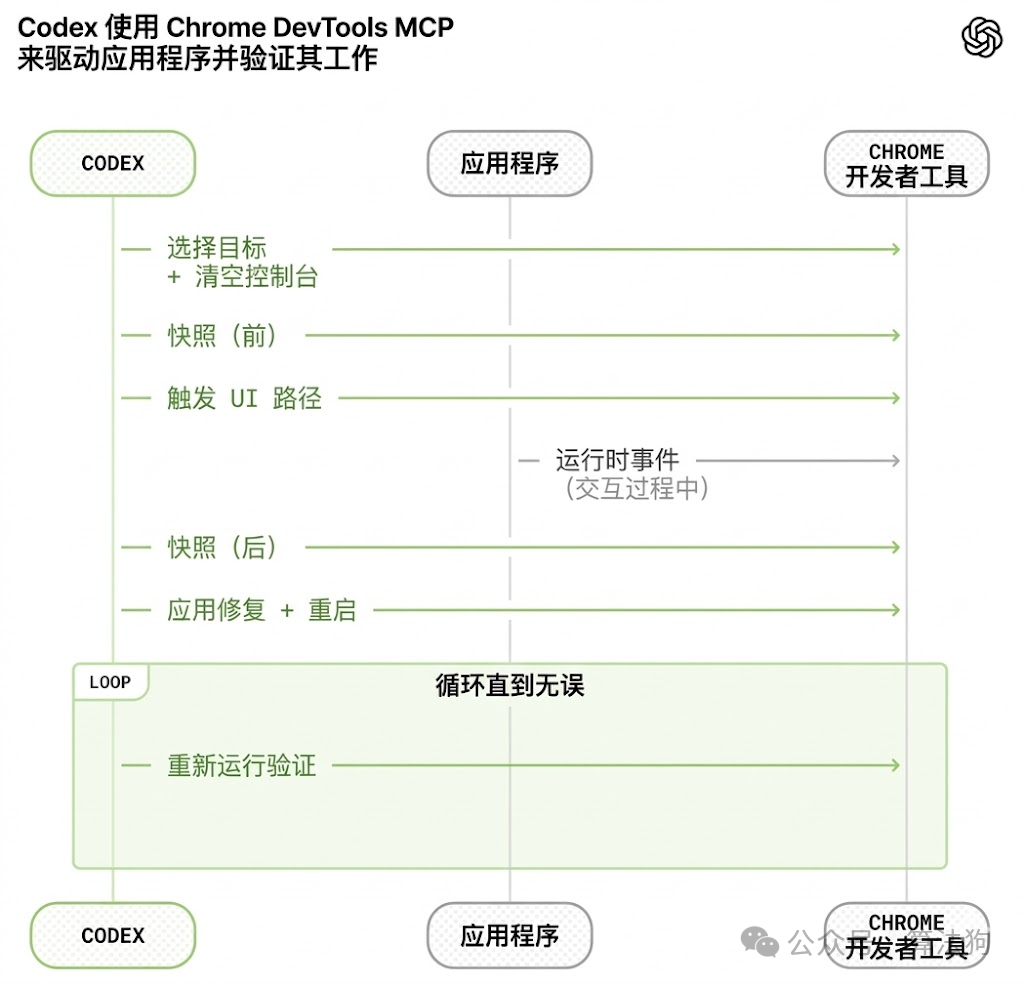
图 3. OpenAI 的Harness Engineering 实践流程图
智能体管理:编码智能体、双模式与反馈循环
编码智能体:粒度、可验证性与CodeAct方法论
模型上下文协议(MCP)被视为智能体的类API工具。尽管Anthropic引入了MCP,且工具调用自2025年以来一直是热门话题,但在许多Harness Engineering案例中,MCP并不适用。其关键问题之一在于粒度:MCP可处理需要通用工具的任务,但不适用于需细粒度控制的任务。工具调用对智能体而言仍是强大功能,但由于其可解释性要求,可能仅适合人在回路中的场景。当需要智能体自动解决复杂问题时,这构成了另一障碍。另一核心问题是可验证性:如何验证工具调用是否成功?即使MCP正常工作,其JSON体是否适应当前情境也难以保证。

图 4. CodeAct 代码即行动 与文本/JSON行动的对比
这正是由CodeAct方法论驱动的编码智能体成为Harness Engineering关键工具的原因。代码解决方案具有内在的逻辑结构,由原子代码逻辑构成,因此可为给定指令提供复杂且定制化的解决方案(高粒度)。此外,它们可通过自动化测试轻松验证(高可验证性):代码返回明确的退出码,零表示成功,非零则伴随异常及回溯;智能体可据此自我验证并解决问题。
双智能体模式:Anthropic的分解策略
2025年11月,Anthropic在自动化应用开发实验中也遭遇了长时间运行智能体问题。研究者将其识别为两类具有不同特征的问题:① 由单次运行中智能体无法解决的过大问题引起,即使耗尽上下文窗口也无法完成任务,上下文压缩亦难以顺畅传递进行中的进度,导致一致性问题;② 当项目接近完成时,智能体易过早断定项目已完工,找不到剩余任务。
这促使Anthropic创建了两种智能体类型以分别应对:
- 初始化智能体:专门负责构建项目脚手架和初始环境,为编码智能体高效完成任务奠定基础。
- 编码智能体:采用增量进度策略。每个会话通过Git提交留下结构化更新,在维护项目稳定功能的同时推进代码演进。
反馈循环:结构化更新与静默失败的风险
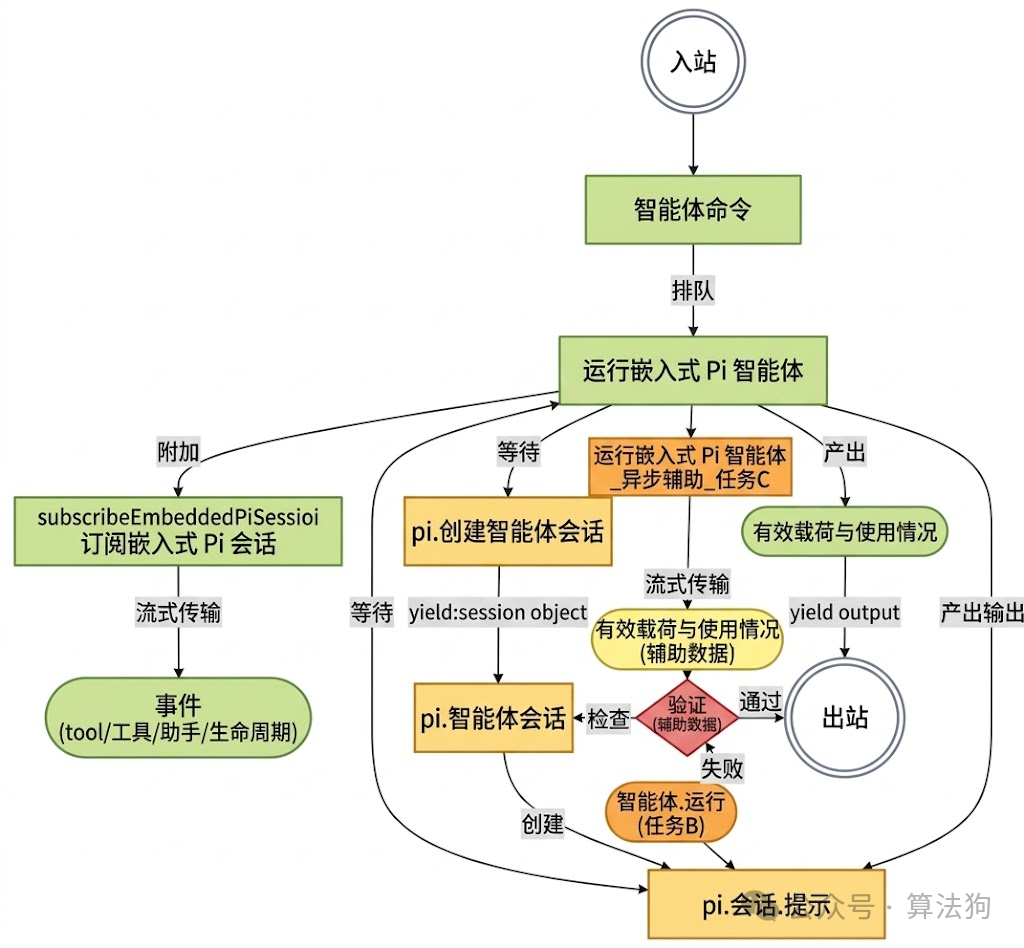
图 5. OpenClaw 的反馈循环流程图
Harness Engineering引入的最独特概念之一是智能体反馈循环。鉴于智能体的上下文限制,反馈循环已成为其核心架构。循环是实现结构化更新,同时为人类开发者维护功能可观测性的有效方法。然而,需注意编码智能体虽可验证,但仍存在易被忽略的陷阱:尽管代码结果检查可覆盖多数问题,但有时代码执行可能引发静默失败。
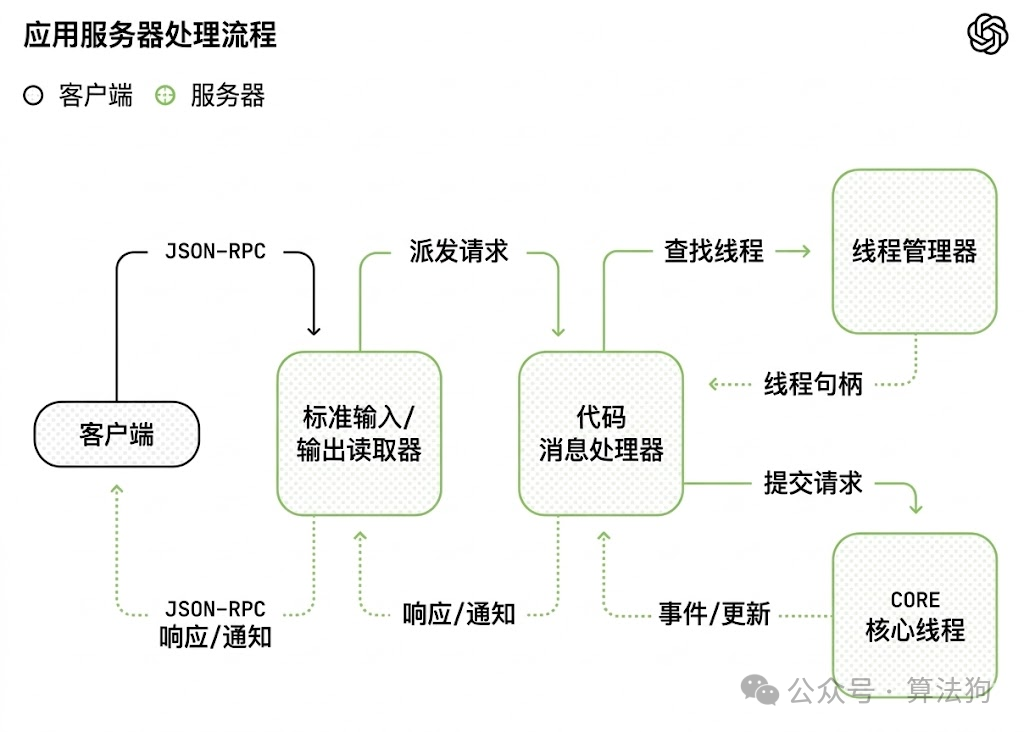
图 6. OpenAI Codex 线程循环
示例代码分析:Nanobot的智能体循环实现

图 7. Nanobot Logo
Nanobot是OpenClaw热潮中广为人知的变体之一,其代码库仅4000多行,对于希望透彻理解Harness Engineering的AI工程师而言,是合适的研究对象。以下是其智能体循环的核心代码片段:
async def _run_agent_loop(
self,
initial_messages: list[dict],
on_progress: Callable[..., Awaitable[None]] | None = None,
) -> tuple[str | None, list[str], list[dict]]:
"""运行智能体迭代循环。"""
messages = initial_messages
iteration = 0
final_content = None
tools_used: list[str] = []
while iteration < self.max_iterations:
iteration += 1
tool_defs = self.tools.get_definitions()
response = await self.provider.chat_with_retry(
messages=messages,
tools=tool_defs,
model=self.model,
)
usage = response.usage or {}
self._last_usage = {
"prompt_tokens": int(usage.get("prompt_tokens", 0) or 0),
"completion_tokens": int(usage.get("completion_tokens", 0) or 0),
}
if response.has_tool_calls:
if on_progress:
thought = self._strip_think(response.content)
if thought:
await on_progress(thought)
tool_hint = self._tool_hint(response.tool_calls)
tool_hint = self._strip_think(tool_hint)
await on_progress(tool_hint, tool_hint=True)
tool_call_dicts = [
tc.to_openai_tool_call()
for tc in response.tool_calls
]
messages = self.context.add_assistant_message(
messages, response.content, tool_call_dicts,
reasoning_content=response.reasoning_content,
thinking_blocks=response.thinking_blocks,
)
for tool_call in response.tool_calls:
tools_used.append(tool_call.name)
args_str = json.dumps(tool_call.arguments, ensure_ascii=False)
logger.info("工具调用: {}({})", tool_call.name, args_str[:200])
result = await self.tools.execute(tool_call.name, tool_call.arguments)
messages = self.context.add_tool_result(
messages, tool_call.id, tool_call.name, result
)
else:
clean = self._strip_think(response.content)
# 不要将错误响应持久化到会话历史中——它们可能会污染上下文并导致永久性400循环 (#1303)。
if response.finish_reason == "error":
logger.error("LLM 返回错误: {}", (clean or "")[:200])
final_content = clean or "抱歉,我在调用 AI 模型时遇到错误。"
break
messages = self.context.add_assistant_message(
messages, clean, reasoning_content=response.reasoning_content,
thinking_blocks=response.thinking_blocks,
)
final_content = clean
break
if final_content is None and iteration >= self.max_iterations:
logger.warning("达到最大迭代次数 ({})", self.max_iterations)
final_content = (
f"我达到了工具调用迭代的最大次数 ({self.max_iterations}),"
"没有完成任务。您可以尝试将任务分解为更小的步骤。"
)
return final_content, tools_used, messages
环境管理:生命周期、人在环上与安全授权
生命周期管理已成为实现流畅智能体循环的关键特性。如图5所示,OpenClaw生成异步运行时以运行pi编码智能体,期间每个事件被流式传输并转储至事件数据库。生命周期事件包括 start、end 和 error。当任务遭遇意外 error 状态时,Harness系统必须拦截循环并相应处理问题。其他系统功能如 healthcheck 也需整合,以检查异步任务是否返回 end 或 error 状态。
人在环上正成为Harness Engineering中的重要概念。人类不再主动决定"在"环中,而是"在"环上,通过引导使智能体无缝完成工作。这使得线程生命周期管理至关重要:借助循环,可在任务进行中拦截以修改计划、挂钩操作;通过适当的任务队列管理,可并行创建作业以加速更新。队列机制的可靠性已成为Harness Engineering的核心组成部分。
授权对Harness系统也日益重要。当前OAuth 2.0提供委托和应用类型的身份验证:
- 委托:用户授权并允许使用特定应用程序(功能级别)。
- 应用:应用程序本身授予权限(应用范围)。
应用范围的权限因其可能授权访问每位员工的信息而存在较高风险。作为个性化智能体,OpenClaw原生支持委托OAuth 2.0授权。若无正确设置,授权的敏感密钥信息可能暴露给外部基础模型,因此该特性在隐私和安全层面极为关键。
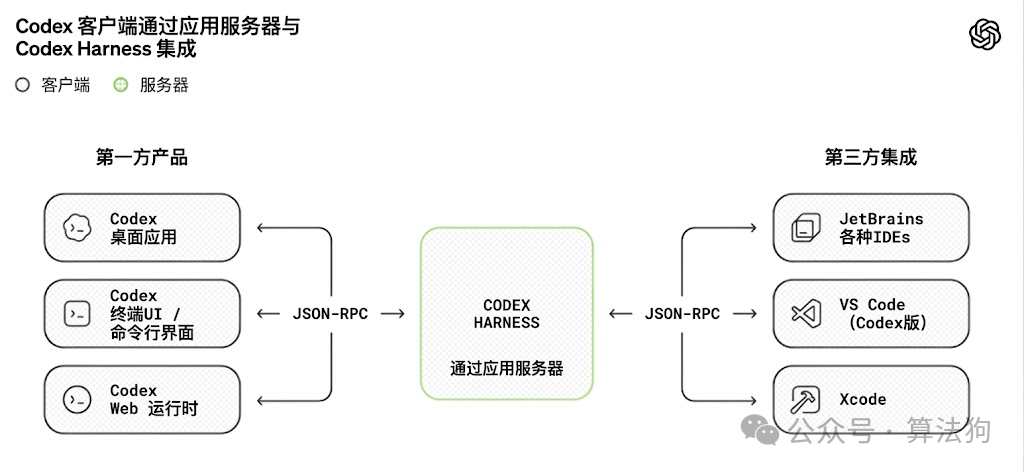
图 8. OpenAI Codex Harness 应用服务器集成架构图
可扩展性同样是环境工程的一部分。理论上,任何平台皆可将变量输入Harness应用服务器,基于当前资源和环境优化智能体循环效率。OpenAI Codex Harness通过JSON-RPC与各类平台通信(类似Jupyter应用程序)。OpenAI harness项目的研究者指出,智能体在具有严格边界和可预测结构的环境中效率最高,因此他们围绕严格的架构模型构建了应用程序。
状态管理:基于文件的持久化与提示模式
除了作为上下文工程一部分的智能体记忆管理,此处状态管理特指项目初始化和进度管理。对代码项目而言,基于内存或数据库的状态不稳定,需维护单独运行时。解决方案何在?Pankaj指出,基于文件的持久化是完成智能体循环首要维护的;知识与数据模块是下一步。Claude Code在文件系统中遗留claude-progress.txt文件,以便智能体读取当前实现情况及后续可贡献的进度。
提示模式:OpenClaw的引导文件结构
由GPT 5.4描述的OpenClaw引导提示结构包含以下关键文件:
AGENTS.md 是操作规则手册,包含智能体的操作指令及记忆使用方式,于每个会话开始时加载。它定义了“如何行动”的指令。SOUL.md 定义了角色、语气和边界,于每个会话中加载。如果说AGENTS.md是“做什么”,SOUL.md就是“你是谁”。IDENTITY.md 存储智能体的名称、审美氛围和表情符号,在引导仪式期间创建和更新。USER.md 捕获用户身份及称呼方式,于每个会话中加载,使智能体持久了解用户偏好。TOOLS.md 保存有关本地工具和约定的说明,为模型提供软性上下文。HEARTBEAT.md 是可选的心跳运行检查清单,应保持简短以避免消耗过多令牌。BOOTSTRAP.md 仅存在于全新工作区,驱动首次智能体运行的问答仪式,随后被删除。MEMORY.md 是精心策划的长期记忆,决策、偏好和持久事实存入其中,日常笔记则进入memory/YYYY-MM-DD.md。
若研究OpenClaw项目结构,可发现这些具有不同名称的文件。通过基于文件的持久化,这些文件旨在超越智能体上下文发挥作用:它们被有条件地连接以形成系统提示,或由智能体在需要时打开。然而,这也意味着每轮对话可能消耗大量令牌,在某些场景下构成问题,因此部分开发者正致力减少令牌消耗。此外,OpenAI研究人员发现,单一的巨型AGENT.md不利于机械检查(覆盖率、新鲜度、所有权、交叉链接),导致漂移不可避免且验证困难。
项目结构管理:隔离、测试与防漂移
工作区隔离至关重要,无人希望多个智能体的代码混杂,这类似代码智能体间的竞争条件。若无适当计划与结构化更新,项目仓库将迅速混乱。因此,OpenClaw等带有Harness系统的个人智能体需拥有独立沙箱环境。
用于验证的结构化测试和确定性linter同样关键。若期望项目结构健全,其不仅应通过单元测试,还需通过复合的结构化测试。
Anthropic将功能列表保存为文件,以防智能体过早宣布胜利。初始化智能体编写此功能列表并保存,编码智能体基于此文件增量更新代码。示例如下:
{
"category": "functional",
"description": "新建聊天按钮创建一个全新的对话",
"steps": [
"导航到主界面",
"点击‘新建聊天’按钮",
"验证创建了一个新对话",
"检查聊天区域是否显示欢迎状态",
"验证对话是否出现在侧边栏"
],
"passes": false
}
来自初始化智能体的功能列表 — 来源 Anthropic
尽管创新想法不断涌现,实现智能体完全自主仍面临诸多挑战。OpenAI研究人员发现,Codex会复制仓库中已存在的模式——即使是不均匀或次优的。为防止漂移,他们每周执行一次垃圾回收。
开发者的未来角色:从编码者到系统架构师
nanobot/
├── agent/ # 🧠 核心智能体逻辑
│ ├── loop.py # 智能体循环(LLM ↔ 工具执行)
│ ├── context.py # 提示构建器
│ ├── memory.py # 持久记忆
│ ├── skills.py # 技能加载器
│ ├── subagent.py # 后台任务执行
│ └── tools/ # 内置工具(包括 spawn)
├── skills/ # 🎯 捆绑技能(github, weather, tmux...)
├── channels/ # 📱 聊天渠道集成(支持插件)
├── bus/ # 🚌 消息路由
├── cron/ # ⏰ 计划任务
├── heartbeat/ # 💓 主动唤醒
├── providers/ # 🤖 LLM 提供商(OpenRouter 等)
├── session/ # 💬 对话会话
├── config/ # ⚙️ 配置
└── cli/ # 🖥️ 命令
Nanobot 项目结构 — 来源 Github
有观点指出,这并非开发者的终结,而是其角色的演变:许多任务只有具备智能体运行时系统基础知识和软件架构宏观视野的软件开发者才能实现。OpenAI指出软件工程师需具备三项新能力:
- 系统工程:整体理解计算机系统的能力。
- 面向智能体的项目脚手架:维护结构健全且可靠代码项目的能力。
- 代码智能体Harness:通过最优引导,充分发挥编码智能体性能的能力。
在另一份分析中,OpenAI还建议开发者需从以下维度理解应用:
- 一致性和可重复性,为每个智能体提供范围明确的上下文。
- 可扩展编排,协调单智能体和多智能体系统。
- 可观测性与可审计性,通过审查完整的智能体堆栈跟踪。
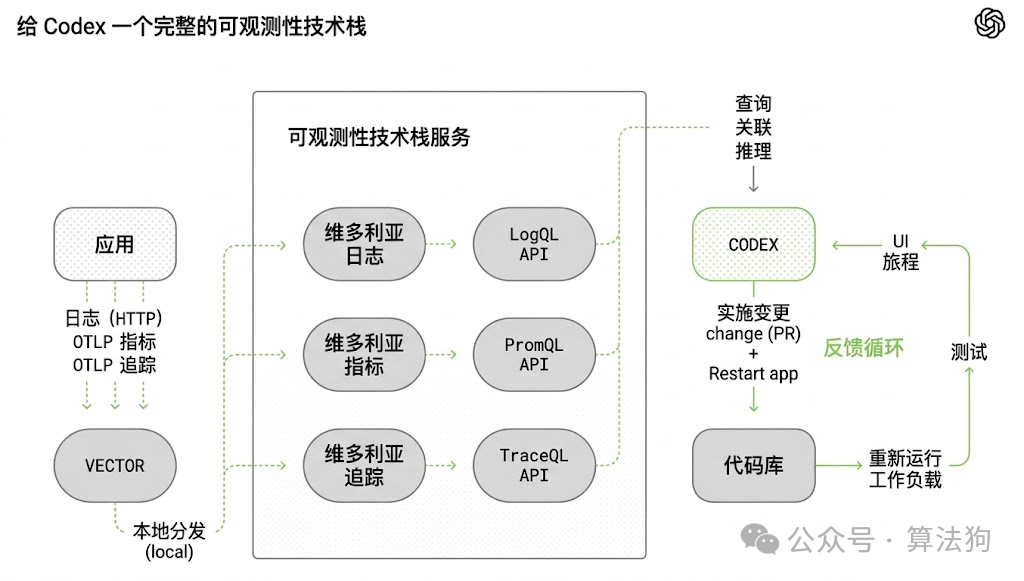
图 9. Codex 的完整可观测性堆栈架构图
最终结论是,可靠性必须与能力分开设计。更新、更强大的模型并不会自动产生更可靠、更一致、更可观测的智能体系统。多步骤执行的复合失效数学问题要求架构解决方案(如投票、断路器、验证层),这些是任何模型改进都无法单独提供的。此外,最成功的生产级智能体通常采用带有验证门的直接提示链,而非复杂的自主多智能体架构——简单性往往胜出。
对于希望深入实践Harness Engineering的开发者和技术管理者而言,云栈社区的技术讨论板块与技术文档专栏提供了丰富的学习资源和项目实践案例,有助于构建更健壮、可控的AI驱动开发系统。
 发表于 2026-3-29 03:25:53
|
查看: 101|
回复: 0
发表于 2026-3-29 03:25:53
|
查看: 101|
回复: 0
