原文作者:Google Cloud Tech (@GoogleCloudTech)
原文链接:https://x.com/GoogleCloudTech/status/2033953579824758855
说到 SKILL.md,很多开发者容易将注意力过度集中在格式细节上——YAML怎么写、目录怎么组织。但随着超过30个Agent工具(如Claude Code、Gemini CLI、Cursor等)统一采用相似的布局,格式问题已基本成为共识。
真正的挑战在于 内容设计。规范只教你如何打包一个Skill,但对其内部逻辑如何组织却鲜有提及。例如,一个封装了FastAPI最佳实践的Skill,与一个四步文档生成流水线,从外观看SKILL.md文件可能类似,但其内部运作逻辑却截然不同。
通过研究整个Agent生态中的Skill构建方式——从Anthropic的开源仓库到Vercel、Google的内部指南——我们总结了五种反复出现且行之有效的设计模式。这些模式能帮助开发者构建出更可靠、更高效的Agent。
本文将逐一解析这五种模式,并附上可直接运行的ADK代码示例。
- Tool Wrapper(工具包装器):让你的Agent瞬间成为某个技术栈的专家。
- Generator(生成器):使用可复用模板输出结构化文档。
- Reviewer(审查器):基于检查清单对代码进行结构化评审。
- Inversion(反转模式):让Agent通过结构化访谈收集需求,再采取行动。
- Pipeline(流水线):强制执行带明确检查点的多步骤工作流。
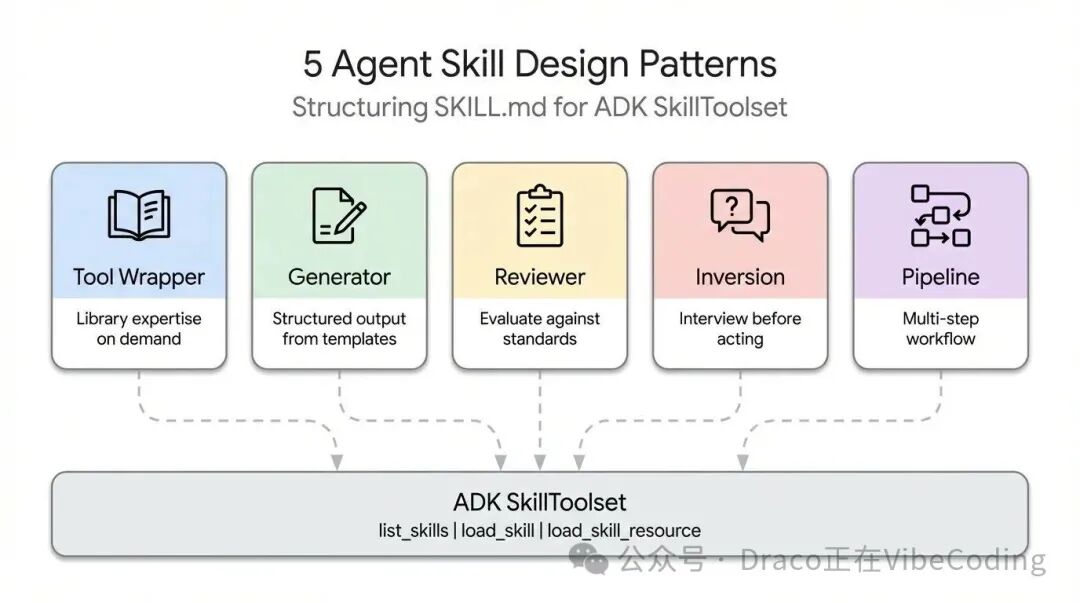
Tool Wrapper模式为你的Agent装上了“按需加载的专业知识”。与其将API规范或最佳实践硬编码进系统提示词,不如将其打包成一个独立的Skill。这样,Agent仅在需要运用特定技术时,才动态加载相关上下文。
这是五种模式中最易实现的一种。SKILL.md监听用户提示词中的特定关键词,动态从references/目录加载内部文档,并将这些规则视作行动准则。这是将团队内部编码规范、特定框架最佳实践直接融入开发者工作流的绝佳方式。
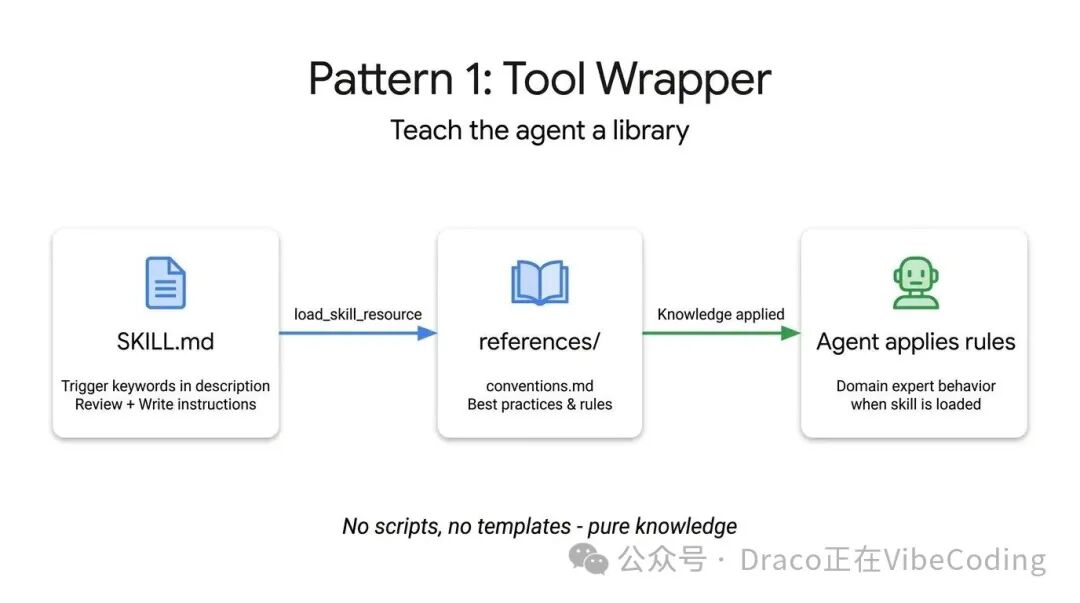
以下是一个Tool Wrapper示例,它教导Agent如何遵循FastAPI开发规范。请注意,指令明确要求Agent仅在开始审查或编写代码时才去加载conventions.md:
# skills/api-expert/SKILL.md
---
name: api-expert
description: FastAPI development best practices and conventions. Use when building, reviewing, or debugging FastAPI applications, REST APIs, or Pydantic models.
metadata:
pattern: tool-wrapper
domain: fastapi
---
你是 FastAPI 开发专家。请将这些约定应用到用户的代码或问题中。
## 核心约定
加载 'references/conventions.md' 以获取完整的 FastAPI 最佳实践列表。
## 审查代码时
1. 加载约定参考文档
2. 用每一条约定检查用户的代码
3. 对于每一处违规,引用具体规则并给出修复建议
## 编写代码时
1. 加载约定参考文档
2. 严格遵循每一条约定
3. 为所有函数签名添加类型注解
4. 使用 Annotated 风格进行依赖注入
模式二:Generator(生成器)
如果说Tool Wrapper是“应用知识”,那么Generator模式则是“强制输出一致性”。如果你曾困扰于Agent每次生成的文档结构各异,Generator正是解决方案——它通过类似“填空题”的机制来保证输出格式。
它利用两个可选目录:assets/存放输出模板,references/存放风格指南。指令扮演项目经理的角色,指导Agent先加载模板,阅读风格指南,向用户询问缺失的变量,最后填充模板。这种模式非常适用于生成API文档、标准化提交信息或项目脚手架。
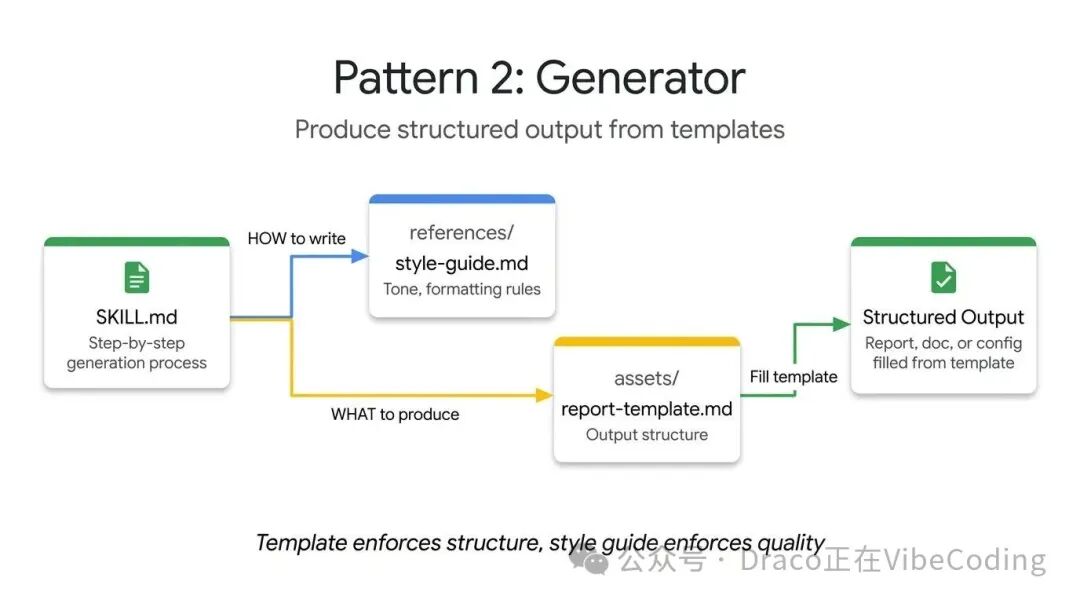
以下技术报告生成器的例子中,Skill文件本身不包含任何具体的布局或语法规则。它的核心作用是协调各类资源的调用,强制Agent按步骤执行:
# skills/report-generator/SKILL.md
---
name: report-generator
description: Generates structured technical reports in Markdown. Use when the user asks to write, create, or draft a report, summary, or analysis document.
metadata:
pattern: generator
output-format: markdown
---
你是一个技术报告生成器。请严格按照以下步骤执行:
Step 1: 加载 'references/style-guide.md' 获取语气和格式规则。
Step 2: 加载 'assets/report-template.md' 获取所需的输出结构。
Step 3: 向用户询问填充模板所需但缺失的信息:
- 主题或话题
- 关键发现或数据点
- 目标读者(技术、管理层、普通读者)
Step 4: 按照风格指南规则填写模板。模板中的每个部分都必须出现在输出中。
Step 5: 将完成后的报告作为一份单独的 Markdown 文档返回。
模式三:Reviewer(审查器)
Reviewer模式将“审查什么”与“如何审查”清晰分离。无需在系统提示词中罗列所有代码规范,可以将模块化的审查标准存储在references/review-checklist.md中。
用户提交代码后,Agent加载该检查清单,逐条应用并打分,最后按严重程度归类输出结果。只需将Python风格检查清单替换为OWASP安全清单,就能使用完全相同的Skill基础设施,得到一个全新的专项安全审计工具。此模式非常适合自动化PR审查或在人工审查前进行初步筛查。
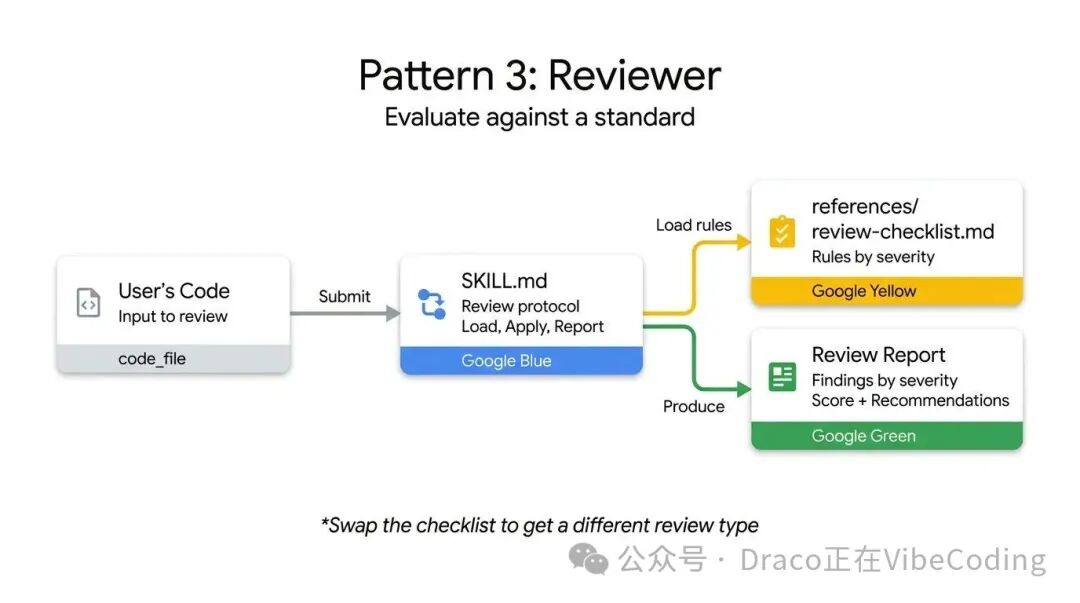
以下代码审查Skill展示了这种分离思想。指令本身是静态的通用流程,但Agent会动态加载外部清单中的具体评审规则,并强制输出结构化的、分级的结果:
# skills/code-reviewer/SKILL.md
---
name: code-reviewer
description: Reviews Python code for quality, style, and common bugs. Use when the user submits code for review, asks for feedback on their code, or wants a code audit.
metadata:
pattern: reviewer
severity-levels: error,warning,info
---
你是一名 Python 代码审查员。请严格遵循以下审查协议:
Step 1: 加载 'references/review-checklist.md' 获取完整的审查标准。
Step 2: 仔细阅读用户的代码。在提出批评前先理解它的用途。
Step 3: 将清单中的每条规则应用到代码上。对发现的每一处违规:
- 记录行号(或大致位置)
- 标注严重程度:error(必须修复)、warning(建议修复)、info(可考虑)
- 解释为什么这是个问题,而不只是指出哪里错了
- 给出带修正代码的具体修复建议
Step 4: 输出一份结构化审查,包含以下部分:
- **Summary**:代码做了什么,整体质量评估
- **Findings**:按严重程度分组(先 errors,再 warnings,最后 info)
- **Score**:按 1-10 打分,并给出简短理由
- **Top 3 Recommendations**:最有影响力的 3 条改进建议
模式四:Inversion(反转模式)
Agent天生倾向于立即猜测并生成内容。Inversion模式反转了这一动态。它不再是用户驱动Prompt、Agent执行,而是让Agent充当采访者。
该模式依赖于明确且不可绕过的“门控指令”(例如“在所有阶段完成前,不得开始构建”),强制Agent优先收集完整上下文。它会按顺序提问,必须得到当前问题的回答后才继续下一个。在获取你全部的需求和部署约束之前,Agent拒绝输出任何最终方案。
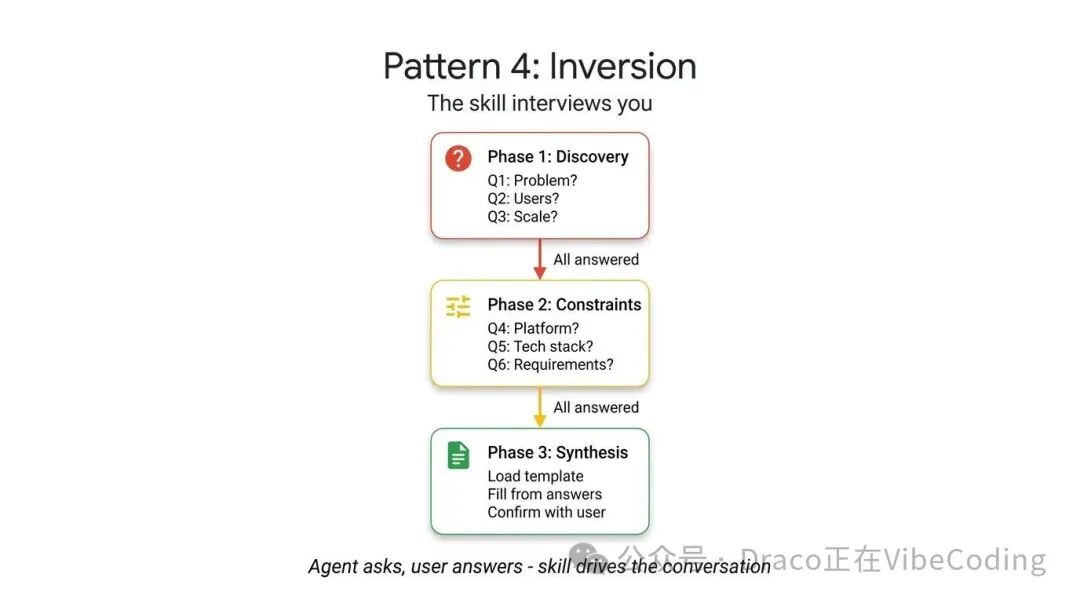
观察以下项目规划Skill。其关键在于严格的分阶段设计和明确的“门控提示”——它有效阻止了Agent在收集完所有用户信息前就仓促合成方案:
# skills/project-planner/SKILL.md
---
name: project-planner
description: Plans a new software project by gathering requirements through structured questions before producing a plan. Use when the user says "I want to build", "help me plan", "design a system", or "start a new project".
metadata:
pattern: inversion
interaction: multi-turn
---
你正在进行一次结构化需求访谈。在所有阶段完成之前,不要开始构建或设计。
## Phase 1 — Problem Discovery(一次问一个问题,等回答)
按顺序问,一个都不能跳过:
- Q1: “这个项目为用户解决什么问题?”
- Q2: “主要用户是谁?他们的技术水平如何?”
- Q3: “预期规模是多少?(每天用户量、数据量、请求量)”
## Phase 2 — Technical Constraints(Phase 1 全部回答完之后)
- Q4: “你用什么部署环境?”
- Q5: “有没有技术栈要求或偏好?”
- Q6: “有哪些不可妥协的要求?(延迟、可用性、合规、预算)”
## Phase 3 — Synthesis(所有问题都回答完之后)
1. 加载 ‘assets/plan-template.md’ 获取输出格式
2. 用收集到的需求填写模板的每个部分
3. 把完成的方案呈现给用户
4. 问:“这个方案准确反映了你的需求吗?你想改哪里?”
5. 根据反馈迭代,直到用户确认
模式五:Pipeline(流水线)
当处理复杂任务时,不能容忍步骤被跳过或指令被忽略。Pipeline模式通过引入硬性检查点,来强制执行严格的顺序化工作流。
指令本身就是工作流的定义。通过实现明确的“菱形门控条件”(例如要求用户必须在进入最终组装阶段前进行确认),Pipeline确保Agent无法绕过复杂流程,直接抛出一个未经验证的最终结果。
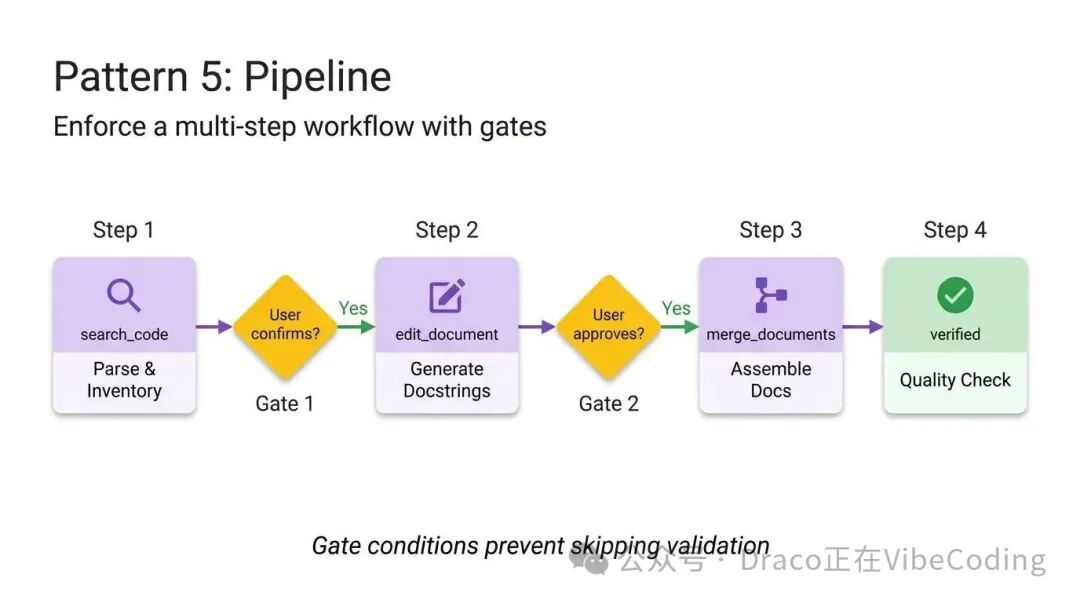
这种模式会用到所有可选目录,仅在每个步骤需要时才引入相应的参考文件和模板,从而保持上下文窗口的洁净。
以下文档生成流水线的例子中,请注意其明确的门控条件——Agent被明令禁止在用户确认上一步生成的文档注释之前,进入组装阶段:
# skills/doc-pipeline/SKILL.md
---
name: doc-pipeline
description: Generates API documentation from Python source code through a multi-step pipeline. Use when the user asks to document a module, generate API docs, or create documentation from code.
metadata:
pattern: pipeline
steps: “4”
---
你正在运行一个文档生成流水线。请按顺序执行每一步。不要跳过步骤,也不要在某一步失败时继续进行。
## Step 1 — Parse & Inventory
分析用户的 Python 代码,提取所有公开的类、函数和常量。以清单形式呈现。问:“这是你要文档化的完整公开 API 吗?”
## Step 2 — Generate Docstrings
对每个缺少文档注释的函数:
- 加载 ‘references/docstring-style.md’ 获取所需格式
- 按风格指南逐字生成文档注释
- 逐条呈现给用户确认
**在用户确认之前,不得进入 Step 3。**
## Step 3 — Assemble Documentation
加载 ‘assets/api-doc-template.md’ 获取输出结构。把所有类、函数和文档注释编译成一份完整的 API 参考文档。
## Step 4 — Quality Check
对照 ‘references/quality-checklist.md’ 审查:
- 每个公开符号都有文档
- 每个参数都有类型和描述
- 每个函数至少有一个使用示例
报告结果,修完问题再呈现最终文档。
如何选择正确的模式?
每种模式旨在解决不同类型的问题。你可以借助下面的决策树,快速找到最适合你当前场景的模式:
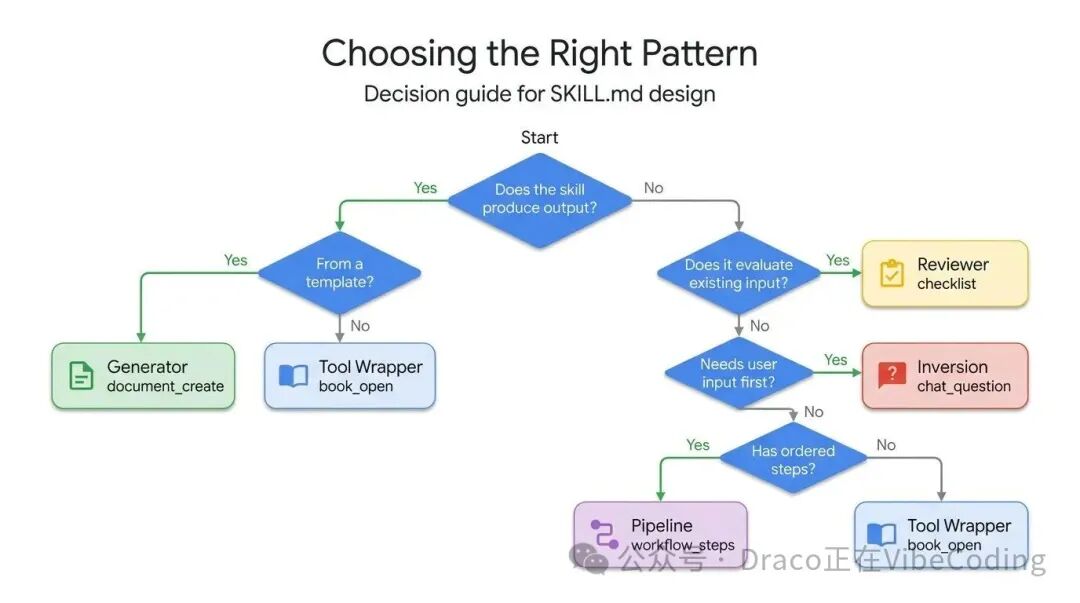
最后:模式可以组合使用
这五种模式并非互斥,它们可以叠加组合使用。
一个Pipeline Skill可以在最后增加一个Reviewer步骤进行自我审查。一个Generator可以在其开头套用一层Inversion,先收集必要的变量信息再填充模板。得益于ADK的SkillToolset和渐进式披露机制,你的Agent在运行时只会将上下文令牌消耗在它真正需要的模式逻辑上。
不要再将复杂且脆弱的指令全部塞进一个庞大的系统提示词中了。尝试拆分你的工作流,运用合适的设计模式,来构建更可靠、更易维护的Agent。若想深入了解每种模式的具体实现和最佳实践,可以参考更详细的技术文档或前往云栈社区与其他开发者交流探讨。
 发表于 2026-3-29 04:16:44
|
查看: 125|
回复: 0
发表于 2026-3-29 04:16:44
|
查看: 125|
回复: 0
